
Rumah >Peranti teknologi >AI >Google mencadangkan kaedah RLHF baharu: menghapuskan model ganjaran dan menghapuskan keperluan untuk latihan lawan
Google mencadangkan kaedah RLHF baharu: menghapuskan model ganjaran dan menghapuskan keperluan untuk latihan lawan

- PHPzke hadapan
- 2024-02-15 19:00:191412semak imbas
Kesannya lebih stabil dan pelaksanaannya lebih mudah.

SPO Yang kaedah terutamanya merangkumi Dua aspek. Pertama, kajian ini benar-benar menghapuskan model ganjaran dengan membina RLHF sebagai permainan jumlah sifar, menjadikannya lebih berkemampuan untuk mengendalikan pilihan bising, bukan Markovian yang sering muncul dalam amalan. Kedua, dengan mengeksploitasi simetri permainan, kajian ini menunjukkan bahawa ejen tunggal hanya boleh dilatih dengan cara permainan sendiri, dengan itu menghapuskan keperluan untuk latihan lawan yang tidak stabil.
 Dalam amalan, ini adalah bersamaan dengan pensampelan berbilang trajektori daripada ejen, meminta penilai atau model keutamaan untuk membandingkan setiap pasangan trajektori, dan menetapkan ganjaran kepada kadar kemenangan trajektori.
Dalam amalan, ini adalah bersamaan dengan pensampelan berbilang trajektori daripada ejen, meminta penilai atau model keutamaan untuk membandingkan setiap pasangan trajektori, dan menetapkan ganjaran kepada kadar kemenangan trajektori.  SPO mengelakkan pemodelan ganjaran, ralat kompaun dan latihan lawan. Dengan mewujudkan konsep pemenang minmax daripada teori pilihan sosial, kajian ini membina RLHF sebagai permainan jumlah sifar dua orang dan mengeksploitasi simetri matriks hasil permainan untuk menunjukkan bahawa ejen tunggal boleh dilatih dengan mudah untuk melawan dirinya sendiri.
SPO mengelakkan pemodelan ganjaran, ralat kompaun dan latihan lawan. Dengan mewujudkan konsep pemenang minmax daripada teori pilihan sosial, kajian ini membina RLHF sebagai permainan jumlah sifar dua orang dan mengeksploitasi simetri matriks hasil permainan untuk menunjukkan bahawa ejen tunggal boleh dilatih dengan mudah untuk melawan dirinya sendiri.

Kajian ini juga menganalisis ciri penumpuan SPO dan membuktikan bahawa apabila fungsi ganjaran berpotensi wujud, SPO boleh menumpu kepada polisi optimum pada kelajuan pantas setanding dengan kaedah standard.
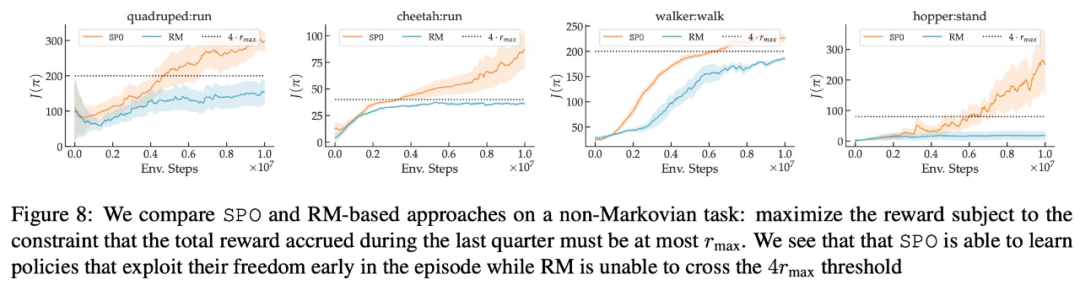
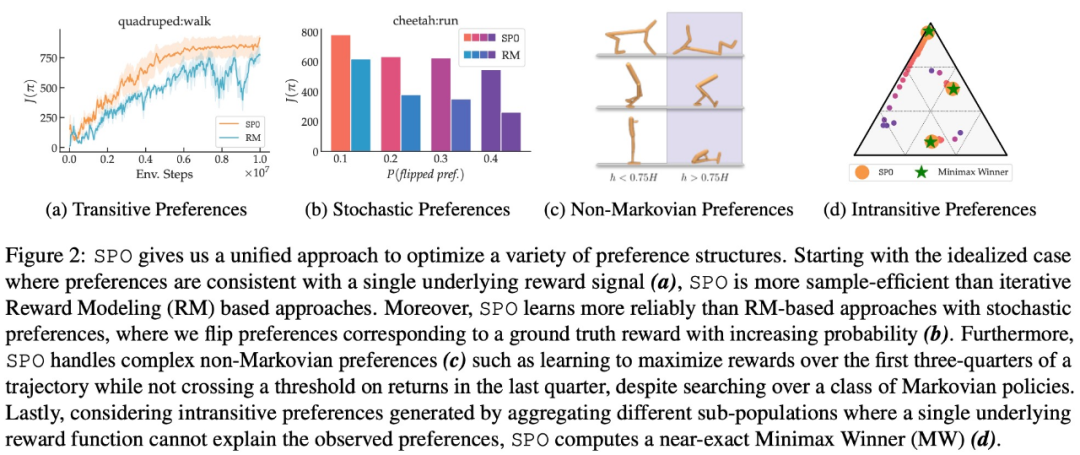 Kajian ini menunjukkan bahawa SPO berprestasi lebih baik daripada kaedah berasaskan model ganjaran pada satu siri tugas kawalan berterusan dengan fungsi keutamaan yang realistik. SPO dapat mempelajari sampel dengan lebih cekap daripada kaedah berasaskan model ganjaran dalam pelbagai tetapan keutamaan, seperti ditunjukkan dalam Rajah 2 di bawah.
Kajian ini menunjukkan bahawa SPO berprestasi lebih baik daripada kaedah berasaskan model ganjaran pada satu siri tugas kawalan berterusan dengan fungsi keutamaan yang realistik. SPO dapat mempelajari sampel dengan lebih cekap daripada kaedah berasaskan model ganjaran dalam pelbagai tetapan keutamaan, seperti ditunjukkan dalam Rajah 2 di bawah.
Kajian ini membandingkan SPO dengan kaedah pemodelan ganjaran berulang (RM) daripada pelbagai dimensi, bertujuan untuk menjawab 4 soalan:
-
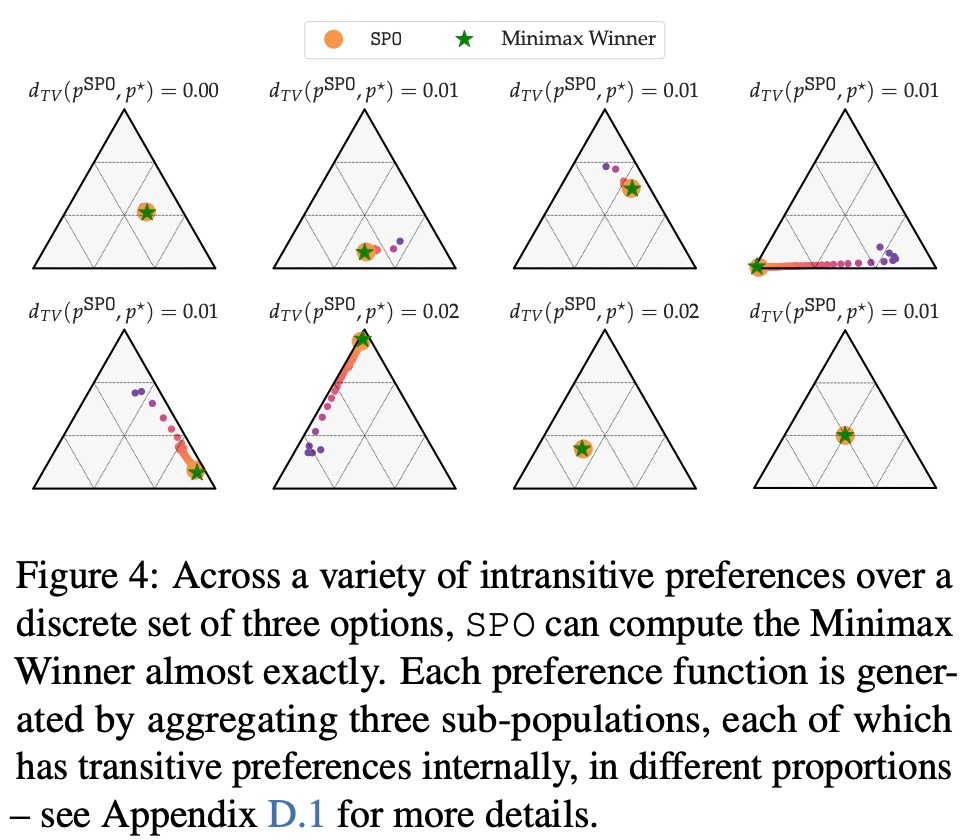
W intransitive boleh dikira, SPO intransitive MW? - Bolehkah SPO memadankan atau melebihi kecekapan sampel RM pada masalah dengan Pemenang Copeland yang unik/strategi optimum?
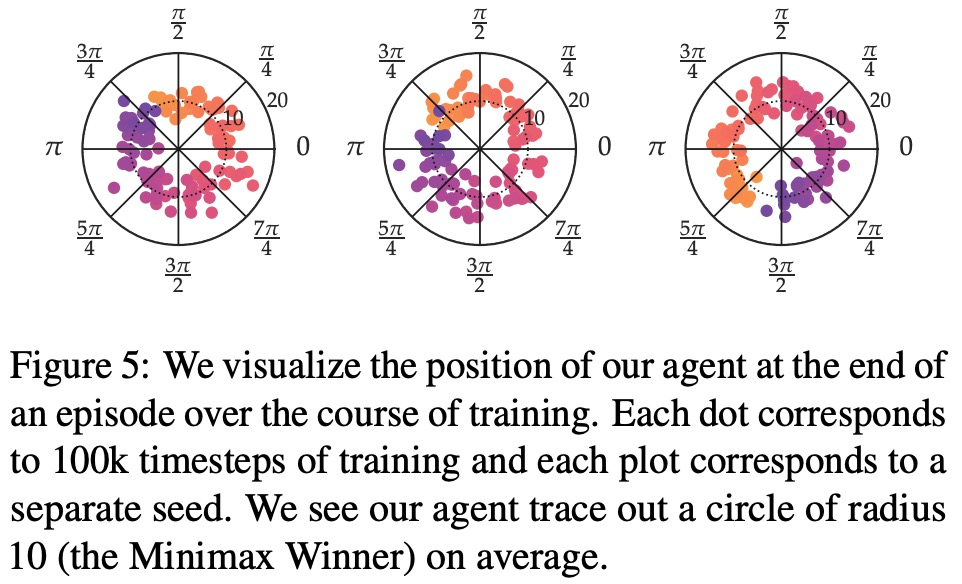
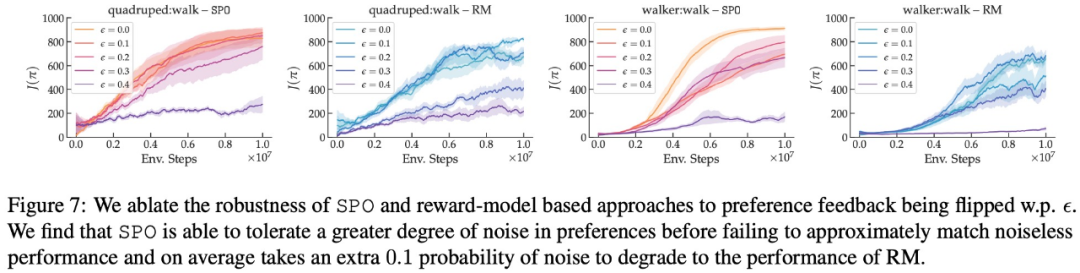
- Sejauh manakah SPO teguh kepada pilihan rawak?
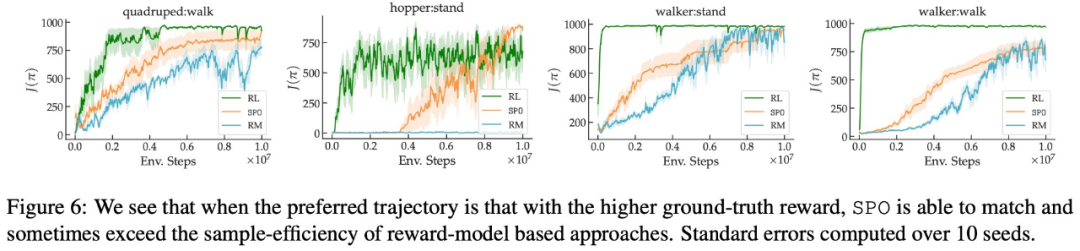
- Bolehkah SPO mengendalikan pilihan bukan Markovian?

Atas ialah kandungan terperinci Google mencadangkan kaedah RLHF baharu: menghapuskan model ganjaran dan menghapuskan keperluan untuk latihan lawan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!