


Cara meneroka dan menggambarkan data ML untuk pengesanan objek dalam imej

Dalam beberapa tahun kebelakangan ini, orang ramai telah mendapat pemahaman yang lebih mendalam tentang kepentingan pemahaman mendalam tentang data pembelajaran mesin (ML-data). Walau bagaimanapun, memandangkan pengesanan set data yang besar biasanya memerlukan banyak pelaburan manusia dan material, aplikasinya yang meluas dalam bidang penglihatan komputer masih memerlukan pembangunan lanjut.
Biasanya, dalam pengesanan objek (subset penglihatan komputer), objek dalam imej diposisikan dengan menentukan kotak sempadan Bukan sahaja objek boleh dikenal pasti, tetapi konteks, saiz dan konteks objek juga boleh difahami. Hubungan dengan elemen lain dalam adegan. Pada masa yang sama, pemahaman yang menyeluruh tentang pengedaran kelas, kepelbagaian saiz objek dan persekitaran biasa di mana kelas muncul juga akan membantu menemui corak ralat dalam model latihan semasa penilaian dan penyahpepijatan, supaya data latihan tambahan boleh dipilih lebih disasarkan.
Dalam amalan, saya cenderung untuk mengambil pendekatan berikut:
- Gunakan model terlatih atau peningkatan pada model asas untuk menambah struktur pada data. Contohnya: mencipta pelbagai benam imej dan menggunakan teknik pengurangan dimensi seperti t-SNE atau UMAP. Ini boleh menjana peta persamaan untuk memudahkan penyemakan imbas data. Di samping itu, menggunakan model pra-latihan untuk pengesanan juga boleh memudahkan pengekstrakan konteks.
- Gunakan alat visualisasi yang boleh menyepadukan struktur sedemikian dengan statistik dan fungsi semakan data mentah.
Di bawah, saya akan memperkenalkan cara menggunakan Renomics Spotlight untuk mencipta visualisasi pengesanan objek interaktif. Sebagai contoh, saya akan cuba:
- Membina visualisasi untuk pengesan orang dalam imej.
- Visualisasi termasuk peta persamaan, penapis dan statistik untuk penerokaan data anda dengan mudah.
- Lihat setiap imej secara terperinci dengan pengesanan Ground Truth dan Ultralytics YOLOv8.
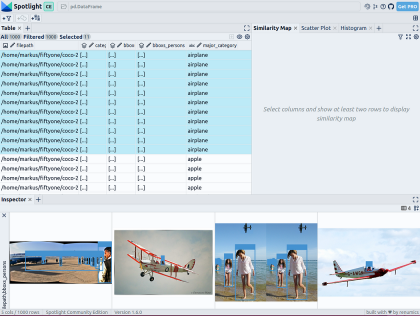
Muat turun imej orang dalam dataset COCO
Mula-mula, pasang pakej yang diperlukan melalui arahan:
!pip install fiftyone ultralytics renumics-spotlightMengambil kesempatan daripada ciri muat turun yang boleh disambung semula
Fifty boleh Muat turun pelbagai imej daripada dataset COCO. Dengan tetapan parameter mudah, kami boleh memuat turun 1,000 imej yang mengandungi satu atau lebih orang. Kod khusus adalah seperti berikut:
importpandasaspdimportnumpyasnpimportfiftyone.zooasfoz# 从 COCO 数据集中下载 1000 张带人的图像dataset = foz.load_zoo_dataset( "coco-2017"、split="validation"、label_types=[ "detections"、],classes=["person"]、 max_samples=1000、dataset_name="coco-2017-person-1k-validations"、)Kemudian, anda boleh menggunakan kod berikut:
def xywh_too_xyxyn(bbox): "" convert from xywh to xyxyn format """ return[bbox[0], bbox[1], bbox[0] + bbox[2], bbox[1] + bbox[3]].行 = []fori, samplein enumerate(dataset):labels = [detection.labelfordetectioninsample.ground_truth.detections] bboxs = [...bboxs = [xywh_too_xyxyn(detection.bounding_box) fordetectioninsample.ground_truth.detections]bboxs_persons = [bboxforbbox, labelin zip(bboxs, labels)iflabel =="person"] 行。row.append([sample.filepath, labels, bboxs, bboxs_persons])df = pd.DataFrame(row, columns=["filepath","categories", "bboxs", "bboxs_persons"])df["major_category"] = df["categories"].apply( lambdax:max(set(x) -set(["person"]), key=x.count) if len(set(x)) >1 else "only person"。)untuk menyediakan data sebagai Pandas DataFrame, lajur termasuk: laluan fail, kategori kotak sempadan, kotak, orang yang terkandung dalam kotak sempadan dan kategori utama (walaupun terdapat orang) untuk menentukan konteks orang dalam imej:

From renumics import spotlightspotlight.show(df)Anda Anda boleh menggunakan butang tambah paparan dalam paparan inspektor dan pilih bboxs_persons dan laluan fail dalam paparan sempadan untuk memaparkan sempadan yang sepadan dengan imej:
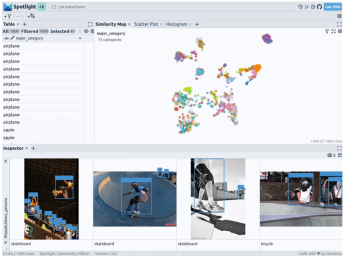
kepada data, kita boleh menerima pakai pembenaman imej pelbagai model asas (iaitu perwakilan vektor padat). Untuk melakukan ini, anda boleh menggunakan teknik pengurangan dimensi selanjutnya seperti UMAP atau t-SNE untuk menggunakan pembenaman Pengubah Penglihatan (ViT) keseluruhan imej pada penstrukturan set data, sekali gus menyediakan peta persamaan 2D bagi imej. Selain itu, anda boleh menggunakan output pengesan objek terlatih untuk menstruktur data anda dengan mengelaskannya mengikut saiz atau bilangan objek yang terkandung di dalamnya. Memandangkan set data COCO sudah menyediakan maklumat ini, kami boleh menggunakannya secara langsung.
Memandangkan Spotl
ight menyepadukan sokongan untuk model google/vit-base-patch16-224-in21k(ViT) dan UMAP , apabila anda mencipta pelbagai benaman menggunakan laluan fail, ia akan digunakan secara automatik: spotlight.show(df, embed=["filepath"])
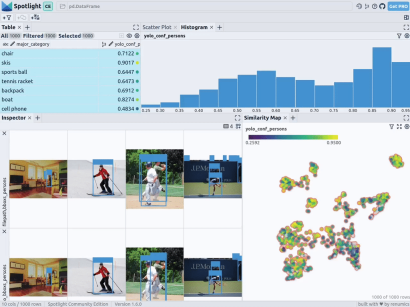
通过上述代码,Spotlight 将各种嵌入进行计算,并应用 UMAP 在相似性地图中显示结果。其中,不同的颜色代表了主要的类别。据此,您可以使用相似性地图来浏览数据:
预训练YOLOv8的结果
可用于快速识别物体的Ultralytics YOLOv8,是一套先进的物体检测模型。它专为快速图像处理而设计,适用于各种实时检测任务,特别是在被应用于大量数据时,用户无需浪费太多的等待时间。
为此,您可以首先加载预训练模型:
From ultralytics import YOLOdetection_model = YOLO("yolov8n.pt")并执行各种检测:
detections = []forfilepathindf["filepath"].tolist():detection = detection_model(filepath)[0]detections.append({ "yolo_bboxs":[np.array(box.xyxyn.tolist())[0]forboxindetection.boxes]、 "yolo_conf_persons": np.mean([np.array(box.conf.tolist())[0]. forboxindetection.boxes ifdetection.names[int(box.cls)] =="person"]), np.mean(]), "yolo_bboxs_persons":[np.array(box.xyxyn.tolist())[0] forboxindetection.boxes ifdetection.names[int(box.cls)] =="person],"yolo_categories": np.array([np.array(detection.names[int(box.cls)])forboxindetection.boxes], "yolo_categories": np.array(),})df_yolo = pd.DataFrame(detections)在12gb的GeForce RTX 4070 Ti上,上述过程在不到20秒的时间内便可完成。接着,您可以将结果包含在DataFrame中,并使用Spotlight将其可视化。请参考如下代码:
df_merged = pd.concat([df, df_yolo], axis=1)spotlight.show(df_merged, embed=["filepath"])
下一步,Spotlight将再次计算各种嵌入,并应用UMAP到相似度图中显示结果。不过这一次,您可以为检测到的对象选择模型的置信度,并使用相似度图在置信度较低的集群中导航检索。毕竟,鉴于这些图像的模型是不确定的,因此它们通常有一定的相似度。
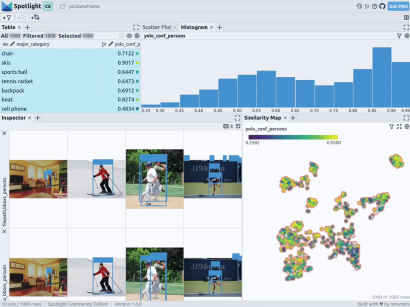
当然,上述简短的分析也表明了,此类模型在如下场景中会遇到系统性的问题:
- 由于列车体积庞大,站在车厢外的人显得非常渺小
- 对于巴士和其他大型车辆而言,车内的人员几乎看不到
- 有人站在飞机的外面
- 食物的特写图片上有人的手或手指
您可以判断这些问题是否真的会影响您的人员检测目标,如果是的话,则应考虑使用额外的训练数据,来增强数据集,以优化模型在这些特定场景中的性能。
小结
综上所述,预训练模型和 Spotlight 等工具的使用,可以让我们的对象检测可视化过程变得更加容易,进而增强数据科学的工作流程。您可以使用自己的数据去尝试和体验上述代码。
译者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:How to Explore and Visualize ML-Data for Object Detection in Images,作者:Markus Stoll
链接:https://itnext.io/how-to-explore-and-visualize-ml-data-for-object-detection-in-images-88e074f46361。
Atas ialah kandungan terperinci Cara meneroka dan menggambarkan data ML untuk pengesanan objek dalam imej. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Skop Gemma: Mikroskop Google ' s untuk mengintip ke proses pemikiran AI 'Apr 17, 2025 am 11:55 AM
Skop Gemma: Mikroskop Google ' s untuk mengintip ke proses pemikiran AI 'Apr 17, 2025 am 11:55 AMMeneroka kerja -kerja dalam model bahasa dengan skop Gemma Memahami kerumitan model bahasa AI adalah satu cabaran penting. Pelepasan Google Gemma Skop, Toolkit Komprehensif, menawarkan penyelidik cara yang kuat untuk menyelidiki
 Siapa penganalisis perisikan perniagaan dan bagaimana menjadi satu?Apr 17, 2025 am 11:44 AM
Siapa penganalisis perisikan perniagaan dan bagaimana menjadi satu?Apr 17, 2025 am 11:44 AMMembuka Kejayaan Perniagaan: Panduan untuk Menjadi Penganalisis Perisikan Perniagaan Bayangkan mengubah data mentah ke dalam pandangan yang boleh dilakukan yang mendorong pertumbuhan organisasi. Ini adalah kuasa penganalisis Perniagaan Perniagaan (BI) - peranan penting dalam GU
 Bagaimana untuk menambah lajur dalam SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AM
Bagaimana untuk menambah lajur dalam SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AMPernyataan Jadual Alter SQL: Menambah lajur secara dinamik ke pangkalan data anda Dalam pengurusan data, kebolehsuaian SQL adalah penting. Perlu menyesuaikan struktur pangkalan data anda dengan cepat? Pernyataan Jadual ALTER adalah penyelesaian anda. Butiran panduan ini menambah colu
 Penganalisis Perniagaan vs Penganalisis DataApr 17, 2025 am 11:38 AM
Penganalisis Perniagaan vs Penganalisis DataApr 17, 2025 am 11:38 AMPengenalan Bayangkan pejabat yang sibuk di mana dua profesional bekerjasama dalam projek kritikal. Penganalisis perniagaan memberi tumpuan kepada objektif syarikat, mengenal pasti bidang penambahbaikan, dan memastikan penjajaran strategik dengan trend pasaran. Simu
 Apakah Count dan Counta dalam Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
Apakah Count dan Counta dalam Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMPengiraan dan Analisis Data Excel: Penjelasan terperinci mengenai fungsi Count dan Counta Pengiraan dan analisis data yang tepat adalah kritikal dalam Excel, terutamanya apabila bekerja dengan set data yang besar. Excel menyediakan pelbagai fungsi untuk mencapai matlamat ini, dengan fungsi Count dan CountA menjadi alat utama untuk mengira bilangan sel di bawah keadaan yang berbeza. Walaupun kedua -dua fungsi digunakan untuk mengira sel, sasaran reka bentuk mereka disasarkan pada jenis data yang berbeza. Mari menggali butiran khusus fungsi Count dan Counta, menyerlahkan ciri dan perbezaan unik mereka, dan belajar cara menerapkannya dalam analisis data. Gambaran keseluruhan perkara utama Memahami kiraan dan cou
 Chrome ada di sini dengan AI: mengalami sesuatu yang baru setiap hari !!Apr 17, 2025 am 11:29 AM
Chrome ada di sini dengan AI: mengalami sesuatu yang baru setiap hari !!Apr 17, 2025 am 11:29 AMRevolusi AI Google Chrome: Pengalaman melayari yang diperibadikan dan cekap Kecerdasan Buatan (AI) dengan cepat mengubah kehidupan seharian kita, dan Google Chrome mengetuai pertuduhan di arena pelayaran web. Artikel ini meneroka exciti
 Sisi Manusia Ai ' s: Kesejahteraan dan garis bawah empat kali gandaApr 17, 2025 am 11:28 AM
Sisi Manusia Ai ' s: Kesejahteraan dan garis bawah empat kali gandaApr 17, 2025 am 11:28 AMImpak Reimagining: garis bawah empat kali ganda Selama terlalu lama, perbualan telah dikuasai oleh pandangan sempit kesan AI, terutama memberi tumpuan kepada keuntungan bawah. Walau bagaimanapun, pendekatan yang lebih holistik mengiktiraf kesalinghubungan BU
 5 Kes Pengkomputeran Kuantum Mengubah Permainan Yang Harus Anda KetahuiApr 17, 2025 am 11:24 AM
5 Kes Pengkomputeran Kuantum Mengubah Permainan Yang Harus Anda KetahuiApr 17, 2025 am 11:24 AMPerkara bergerak terus ke arah itu. Pelaburan yang dicurahkan ke dalam penyedia perkhidmatan kuantum dan permulaan menunjukkan bahawa industri memahami kepentingannya. Dan semakin banyak kes penggunaan dunia nyata muncul untuk menunjukkan nilainya


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

Penyesuai Pelayan SAP NetWeaver untuk Eclipse
Integrasikan Eclipse dengan pelayan aplikasi SAP NetWeaver.

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

VSCode Windows 64-bit Muat Turun
Editor IDE percuma dan berkuasa yang dilancarkan oleh Microsoft

