
Rumah >Peranti teknologi >AI >Tongyi Qianwen adalah sumber terbuka sekali lagi, Qwen1.5 membawakan enam model volum, dan prestasinya melebihi GPT3.5
Tongyi Qianwen adalah sumber terbuka sekali lagi, Qwen1.5 membawakan enam model volum, dan prestasinya melebihi GPT3.5

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-02-07 22:15:021661semak imbas
Sebelum Festival Musim Bunga, versi 1.5 Tongyi Qianwen Large Model (Qwen) ada dalam talian. Pagi ini, berita versi baharu mencetuskan kebimbangan dalam komuniti AI.
Versi baharu model besar termasuk enam saiz model: 0.5B, 1.8B, 4B, 7B, 14B dan 72B. Antaranya, prestasi versi terkuat mengatasi GPT 3.5 dan Mistral-Medium. Versi ini termasuk model Base dan model Sembang, dan menyediakan sokongan berbilang bahasa.
Pasukan Alibaba Tongyi Qianwen menyatakan bahawa teknologi yang berkaitan juga telah dilancarkan di laman web rasmi Tongyi Qianwen dan Apl Tongyi Qianwen.
Selain itu, keluaran Qwen 1.5 hari ini juga mempunyai sorotan berikut:
- menyokong panjang konteks 32K
- dibuka dengan model ;
- ; Transformers Berjalan secara tempatan;
- GPTQ Int-4/Int8, AWQ dan berat GGUF dikeluarkan serentak.
Dengan menggunakan model berskala besar yang lebih maju sebagai hakim, pasukan Tongyi Qianwen menjalankan penilaian awal Qwen1.5 pada dua penanda aras yang digunakan secara meluas, MT-Bench dan Alpaca-Eval. Keputusan penilaian adalah seperti berikut:
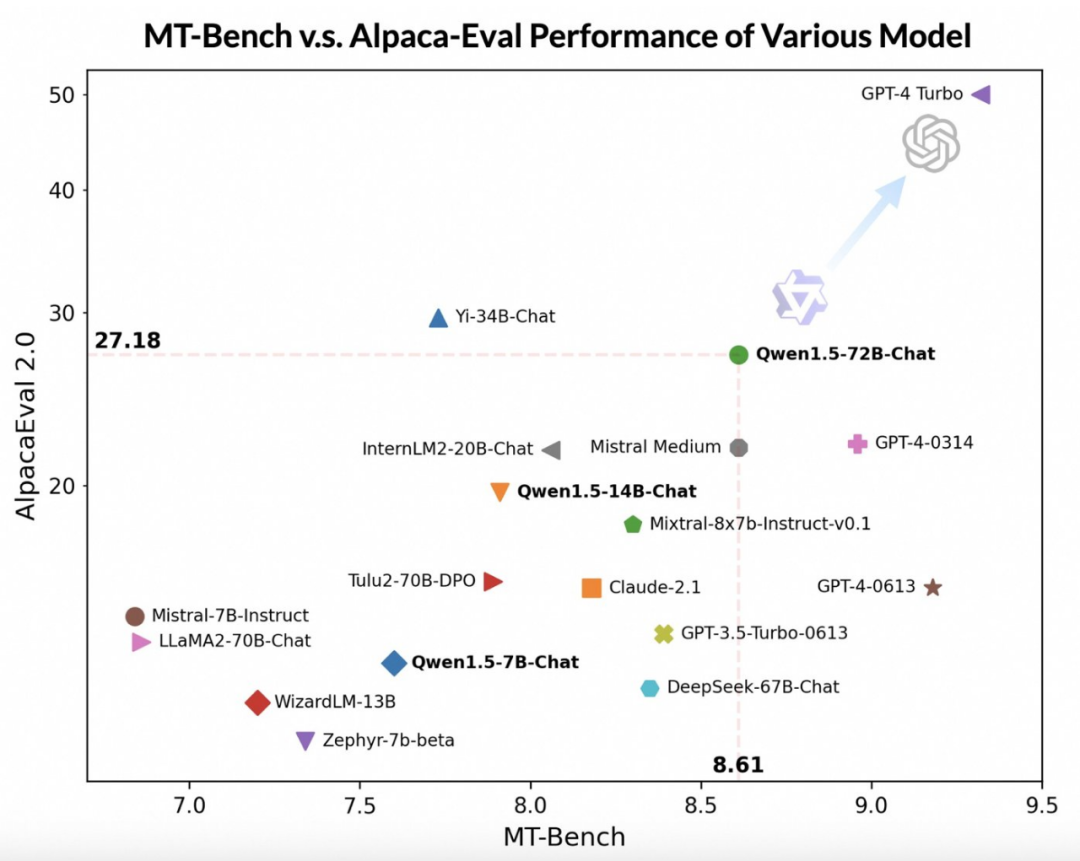
Walaupun model Qwen1.5-72B-Chat ketinggalan di belakang GPT-4-Turbo, dalam ujian pada MT-Bench dan Alpaca-Eval v2, ia menunjukkan prestasi yang mengagumkan Eye- prestasi menangkap. Malah, Qwen1.5-72B-Chat mengatasi Claude-2.1, GPT-3.5-Turbo-0613, Mixtral-8x7b-instruct dan TULU 2 DPO 70B dalam prestasi, dan setanding dengan model Mistral Medium yang telah menarik perhatian ramai baru-baru ini Setanding. Ini menunjukkan bahawa model Qwen1.5-72B-Chat mempunyai kekuatan yang besar dalam pemprosesan bahasa semula jadi.
Pasukan Tongyi Qianwen menegaskan bahawa walaupun markah model besar mungkin berkaitan dengan panjang jawapan, pemerhatian manusia menunjukkan bahawa Qwen1.5 tidak menjejaskan markah dengan menghasilkan jawapan yang terlalu panjang. Menurut data AlpacaEval 2.0, purata panjang Qwen1.5-Chat ialah 1618, iaitu sama panjang dengan GPT-4 dan lebih pendek daripada GPT-4-Turbo.
Pembangun Tongyi Qianwen berkata dalam beberapa bulan kebelakangan ini, mereka telah bekerja keras untuk membina model yang cemerlang dan terus meningkatkan pengalaman pembangun.

Berbanding dengan versi sebelumnya, kemas kini ini memfokuskan pada penambahbaikan penjajaran model Sembang dengan keutamaan manusia dan dengan ketara meningkatkan keupayaan pemprosesan berbilang bahasa model. Dari segi panjang jujukan, semua model skala telah melaksanakan sokongan julat panjang konteks sebanyak 32768 token. Pada masa yang sama, kualiti model Pangkalan pra-latihan juga telah dioptimumkan secara utama, yang dijangka memberikan pengalaman yang lebih baik kepada orang ramai semasa proses penalaan halus.
Keupayaan asas
Berkenaan penilaian keupayaan asas model, pasukan Tongyi Qianwen menjalankan Qwen1.5 pada set data penanda aras seperti MMLU (5-shot), C-Eval, Humaneval, dan B. .
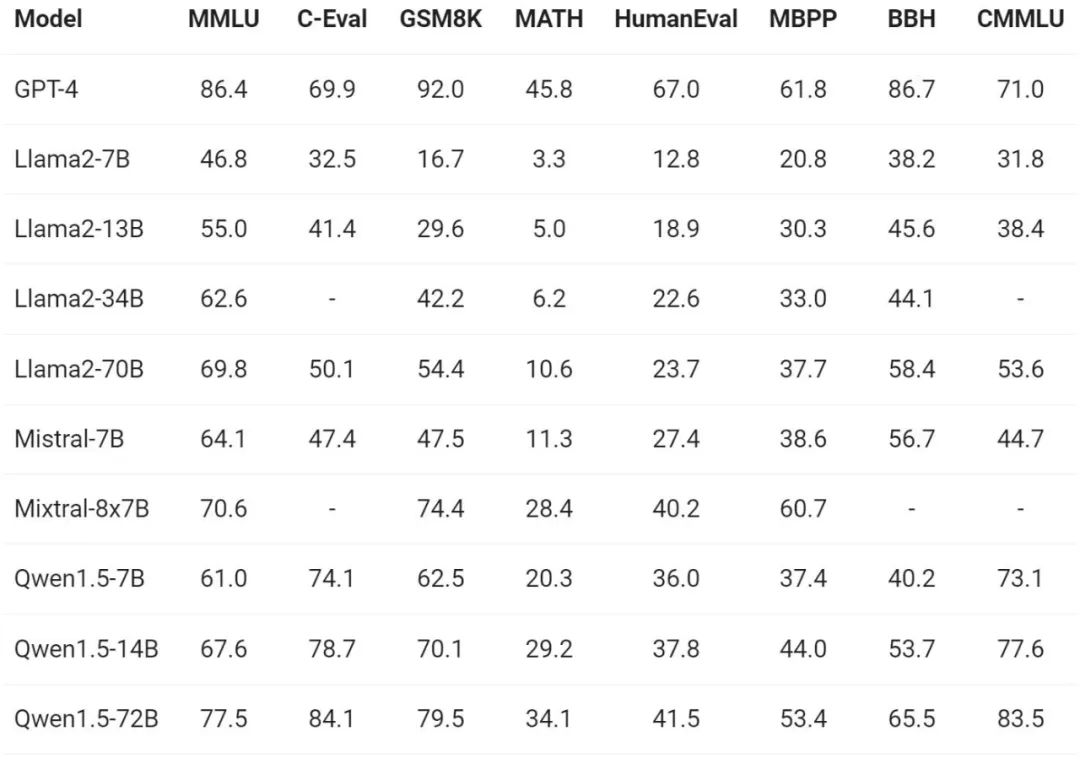
Di bawah saiz model yang berbeza, Qwen1.5 telah menunjukkan prestasi kukuh dalam penanda aras penilaian.
Sejak kebelakangan ini, pembinaan model kecil telah menjadi salah satu tempat hangat dalam industri Pasukan Tongyi Qianwen membandingkan model Qwen1.5 dengan parameter model kurang daripada 7 bilion dengan model kecil yang penting dalam komuniti:
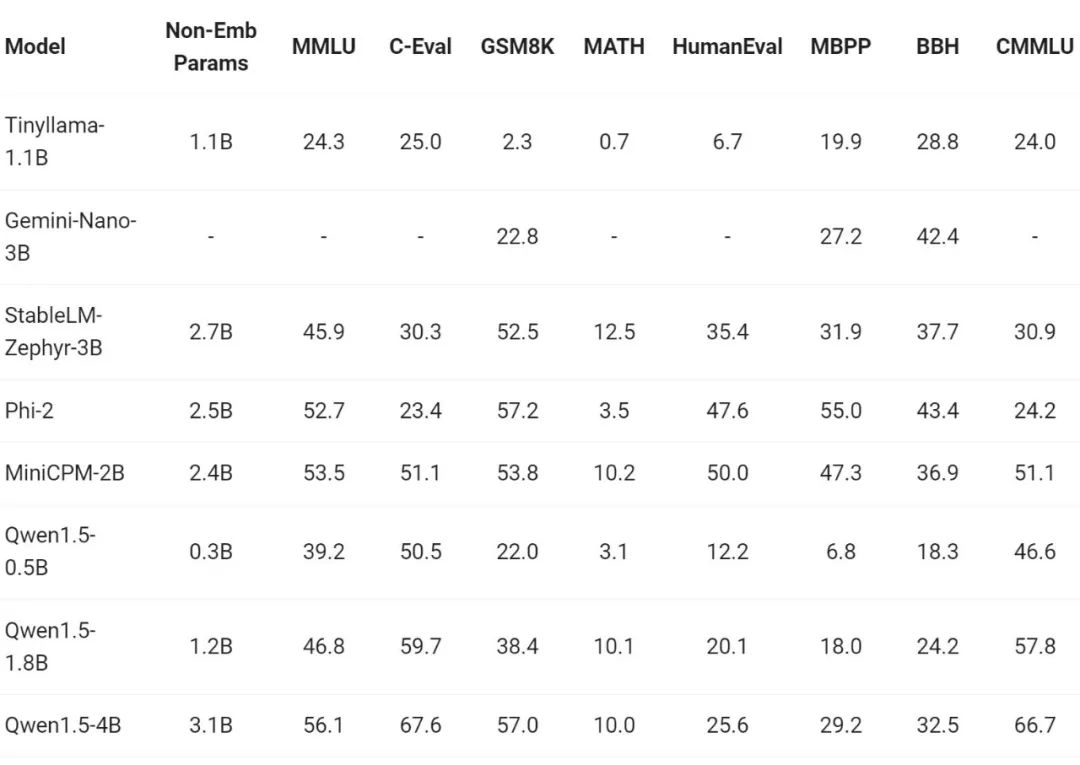
Qwen1.5 sangat berdaya saing dengan model kecil yang terkemuka dalam industri dalam julat saiz parameter di bawah 7 bilion.
Keupayaan berbilang bahasa
Pasukan Tongyi Qianwen menilai keupayaan berbilang bahasa model Base pada 12 bahasa berbeza dari Eropah, Asia Timur dan Asia Tenggara. Daripada set data awam komuniti sumber terbuka, penyelidik Alibaba membina set penilaian yang ditunjukkan dalam jadual berikut, meliputi empat dimensi berbeza: peperiksaan, pemahaman, terjemahan dan matematik. Jadual di bawah memberikan butiran tentang setiap set ujian, termasuk konfigurasi penilaiannya, metrik penilaian dan bahasa khusus yang terlibat.
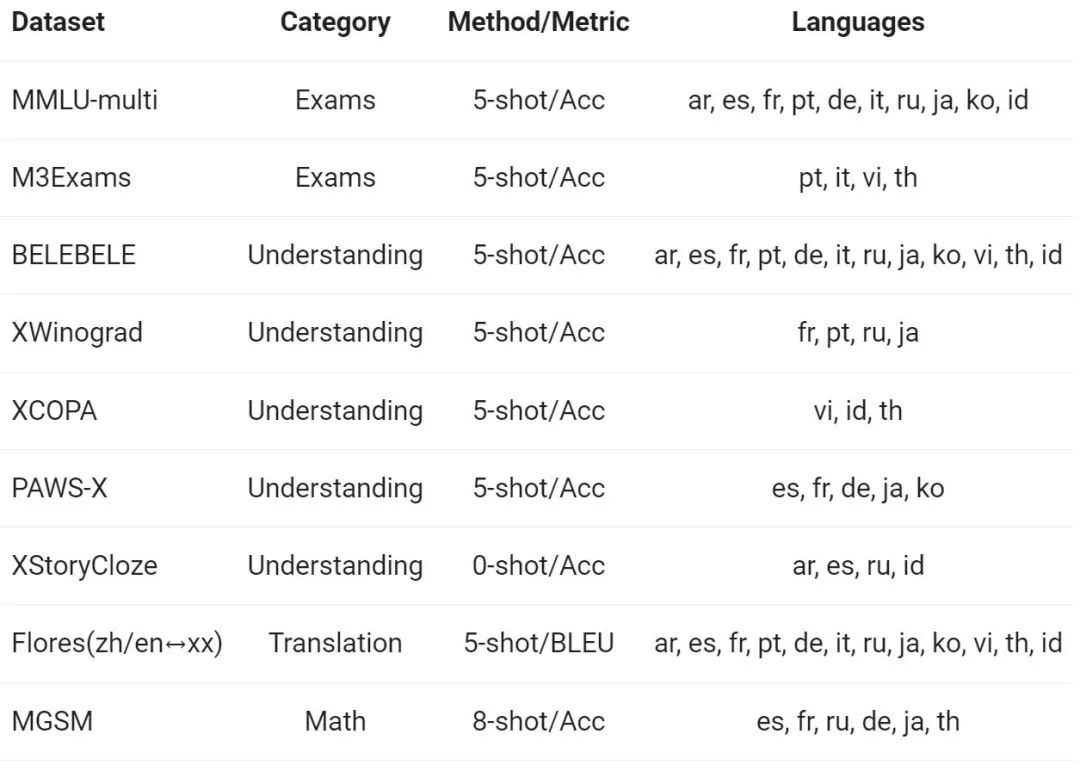
Keputusan terperinci adalah seperti berikut:
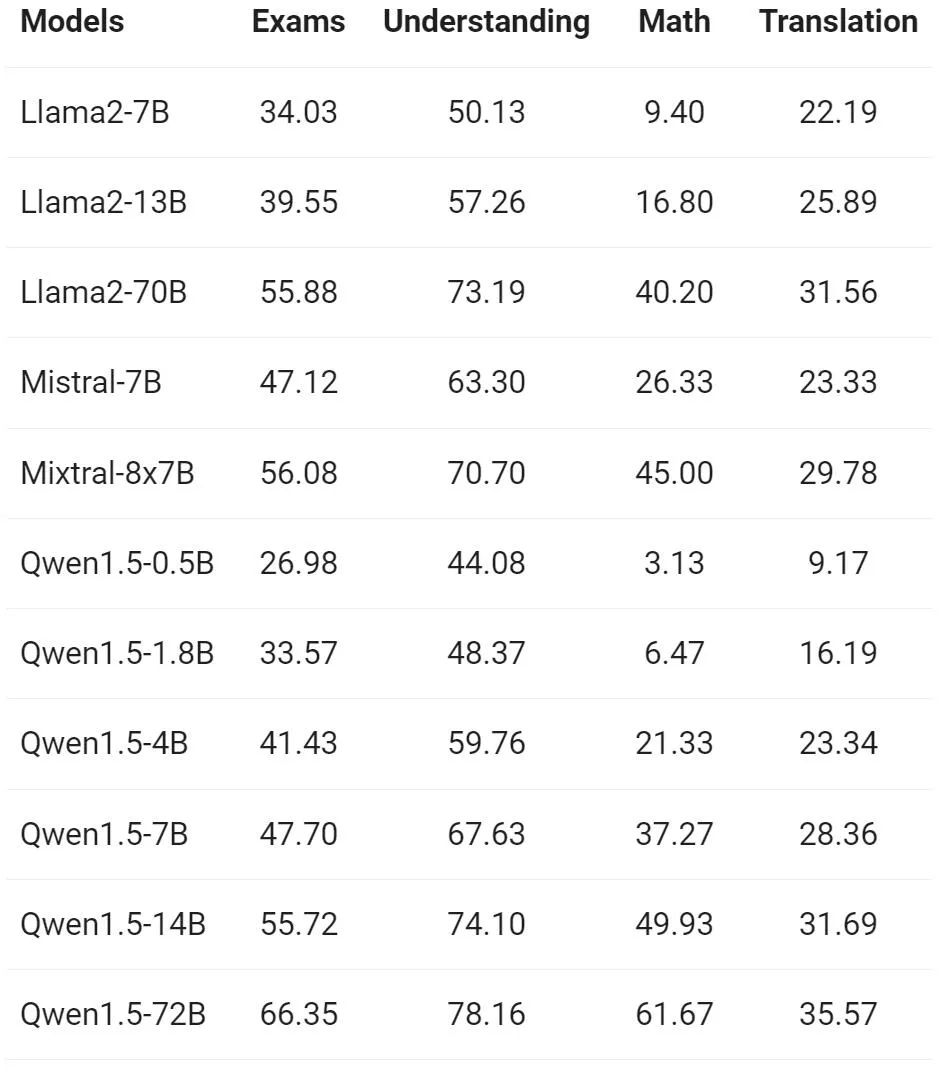
Keputusan di atas menunjukkan bahawa model Qwen1.5 Base berprestasi baik dalam keupayaan berbilang bahasa dalam 12 bahasa berbeza, dan menunjukkan hasil yang baik dalam penilaian pelbagai dimensi seperti pengetahuan subjek, pemahaman bahasa, terjemahan dan matematik. Tambahan pula, dari segi keupayaan berbilang bahasa model Sembang, keputusan berikut boleh diperhatikan:
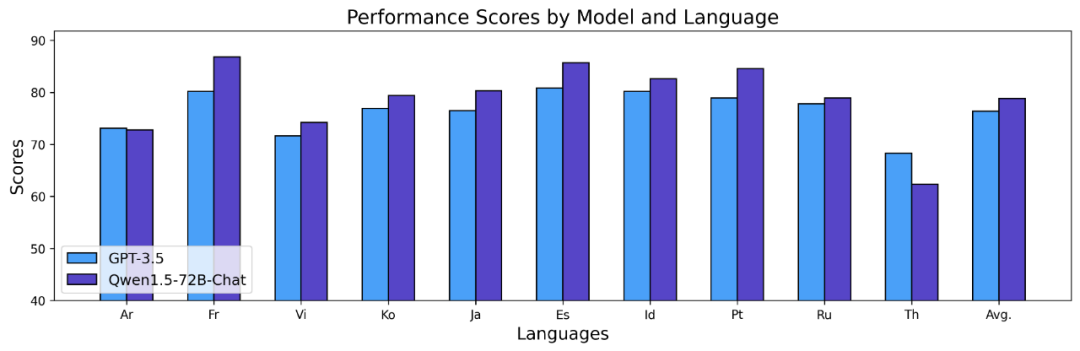
Long Sequences
Apabila permintaan untuk pemahaman jujukan panjang terus meningkat, Alibaba telah meningkat. beribu-ribu dalam versi baharu Apabila ditanya tentang keupayaan model yang sepadan, siri penuh model Qwen1.5 menyokong konteks token 32K. Pasukan Tongyi Qianwen menilai prestasi model Qwen1.5 pada penanda aras L-Eval, yang mengukur keupayaan model untuk menjana respons berdasarkan konteks yang panjang. Hasilnya adalah seperti berikut:
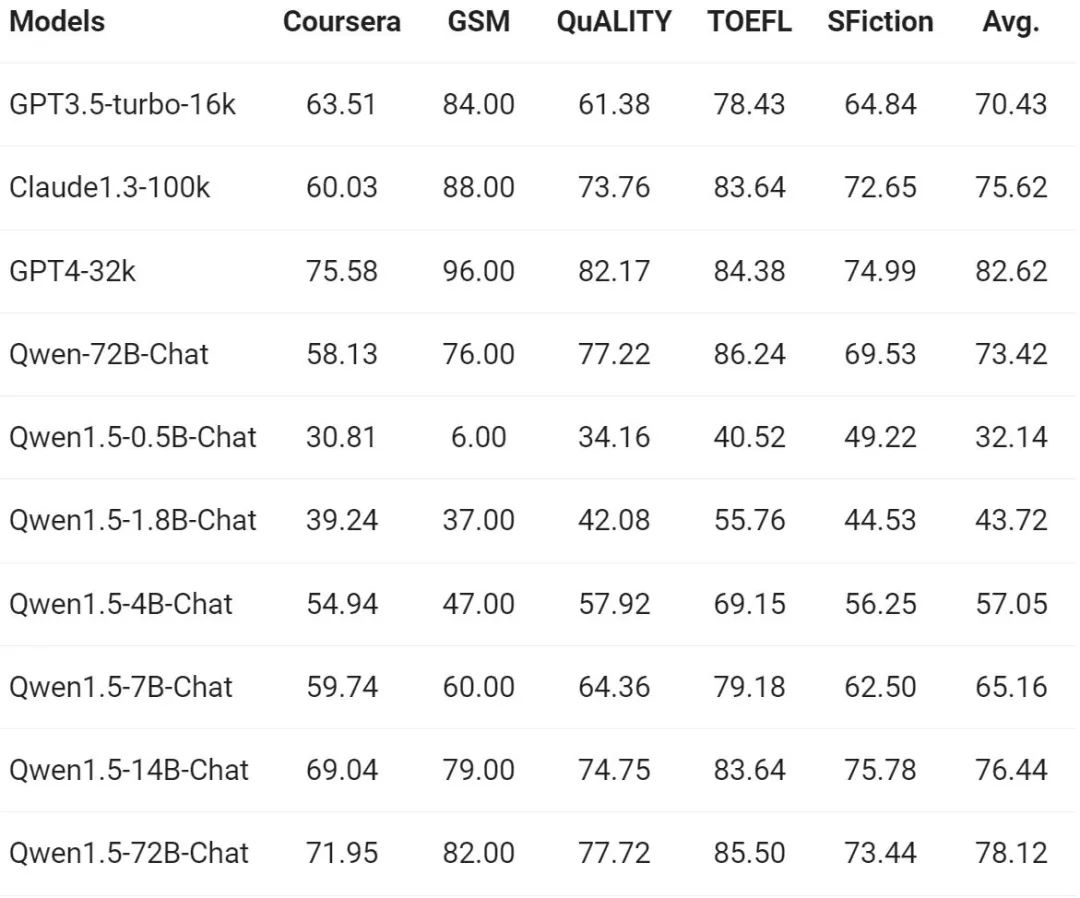
Daripada hasilnya, model berskala kecil seperti Qwen1.5-7B-Chat boleh menunjukkan prestasi yang setanding dengan GPT-3.5, manakala model terbesar Qwen1.5 -72B- Sembang hanya ketinggalan sedikit daripada GPT4-32k.
Perlu dinyatakan bahawa keputusan di atas hanya menunjukkan kesan Qwen 1.5 di bawah panjang token 32K, dan ini tidak bermakna model itu hanya boleh menyokong panjang maksimum 32K. Pembangun boleh cuba mengubah suai max_position_embedding dalam config.json kepada nilai yang lebih besar untuk melihat sama ada model boleh mencapai hasil yang memuaskan dalam senario pemahaman konteks yang lebih panjang.
Menghubungkan kepada sistem luaran
Kini, salah satu daya tarikan model bahasa umum terletak pada potensi keupayaannya untuk bersambung dengan sistem luaran. RAG, sebagai tugas yang berkembang pesat dalam komuniti, menangani beberapa cabaran tipikal yang dihadapi oleh model bahasa yang besar, seperti halusinasi, ketidakupayaan untuk mendapatkan kemas kini masa nyata atau data peribadi dengan berkesan. Selain itu, model bahasa menunjukkan kuasanya dalam menggunakan API dan menulis kod berdasarkan arahan dan contoh. Model besar boleh menggunakan jurubahasa kod atau bertindak sebagai ejen AI untuk mencapai nilai yang lebih luas.
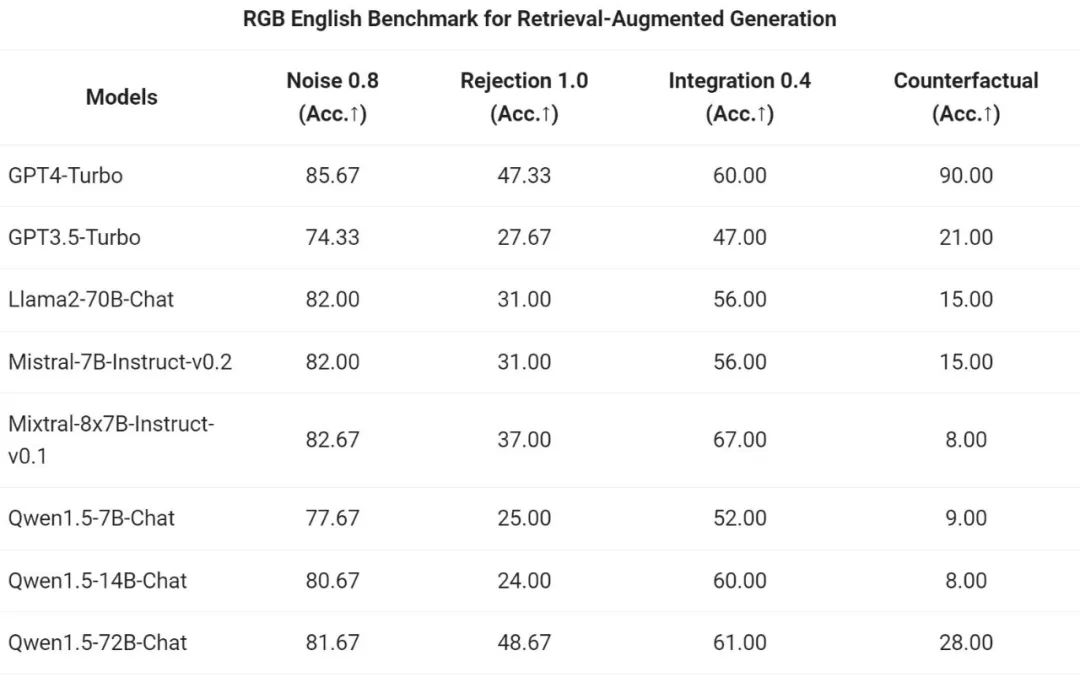
Pasukan Tongyi Qianwen menilai kesan hujung ke hujung model Sembang siri Qwen1.5 pada tugas RAG. Penilaian adalah berdasarkan set ujian RGB, iaitu set yang digunakan untuk penilaian RAG Bahasa Cina dan Inggeris:
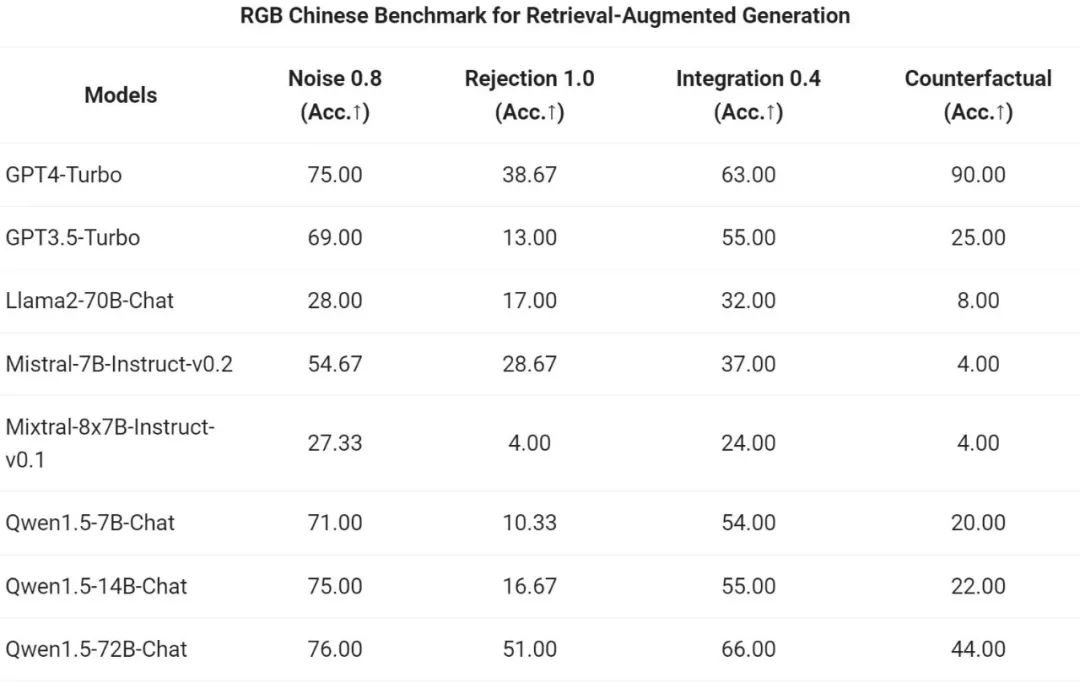
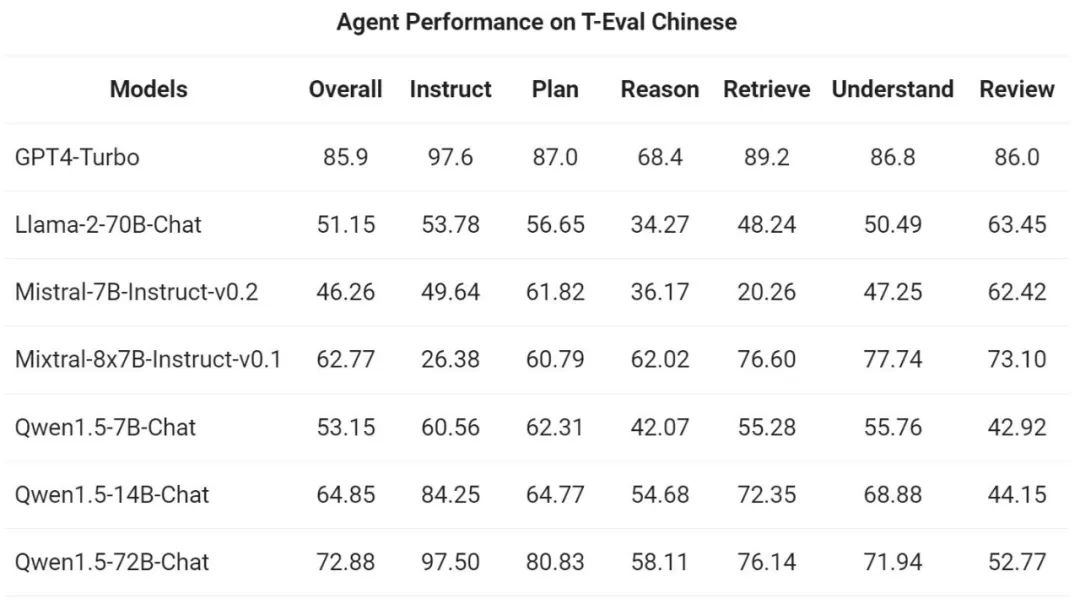
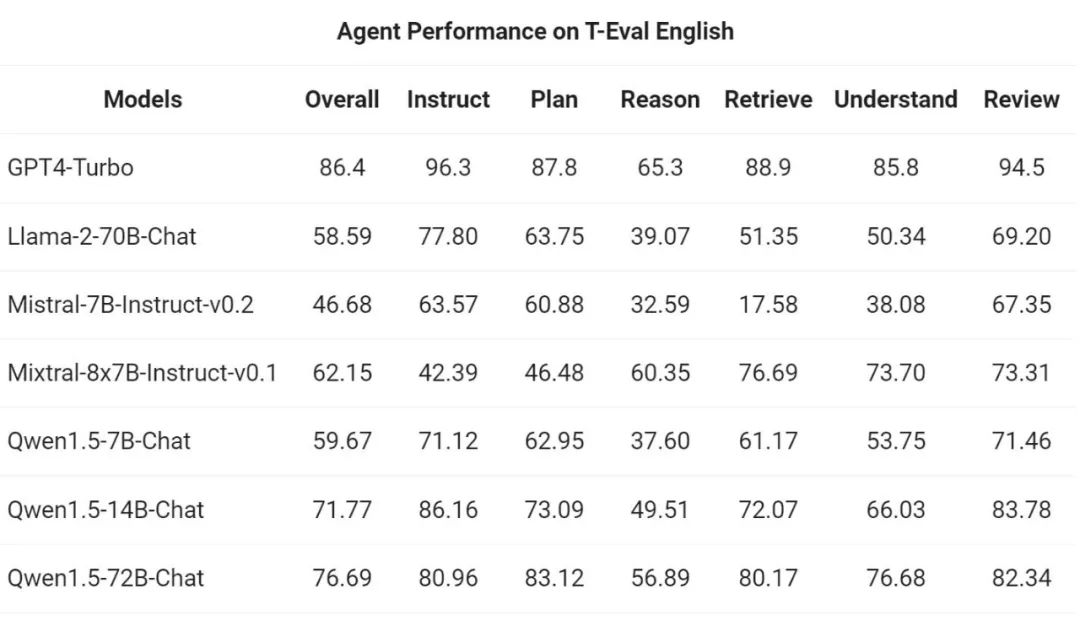
Kemudian, pasukan Tongyi Qianwen menilai Qwen1.5 sebagai ejen am dalam T- Ujian penanda aras Eval Keupayaan untuk berlari. Semua model Qwen1.5 tidak dioptimumkan khusus untuk penanda aras:
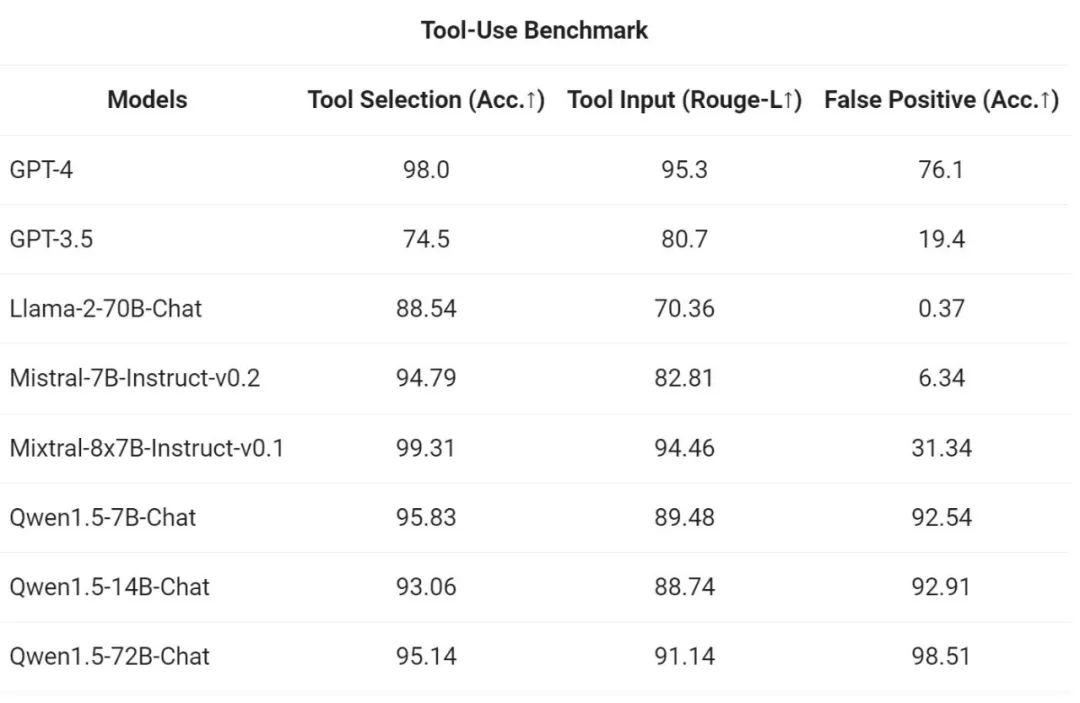
Untuk menguji keupayaan panggilan alat, Alibaba menggunakan penanda aras penilaian sumber terbukanya sendiri untuk menguji keupayaan model untuk memilih dan memanggil alat dengan betul . Hasilnya adalah seperti berikut:
Akhirnya, kerana penterjemah kod Python telah menjadi alat yang semakin berkuasa untuk LLM lanjutan, pasukan Tongyi Qianwen juga menilai keupayaan model baharu untuk menggunakan alat ini berdasarkan sumber terbuka sebelumnya penanda aras penilaian:
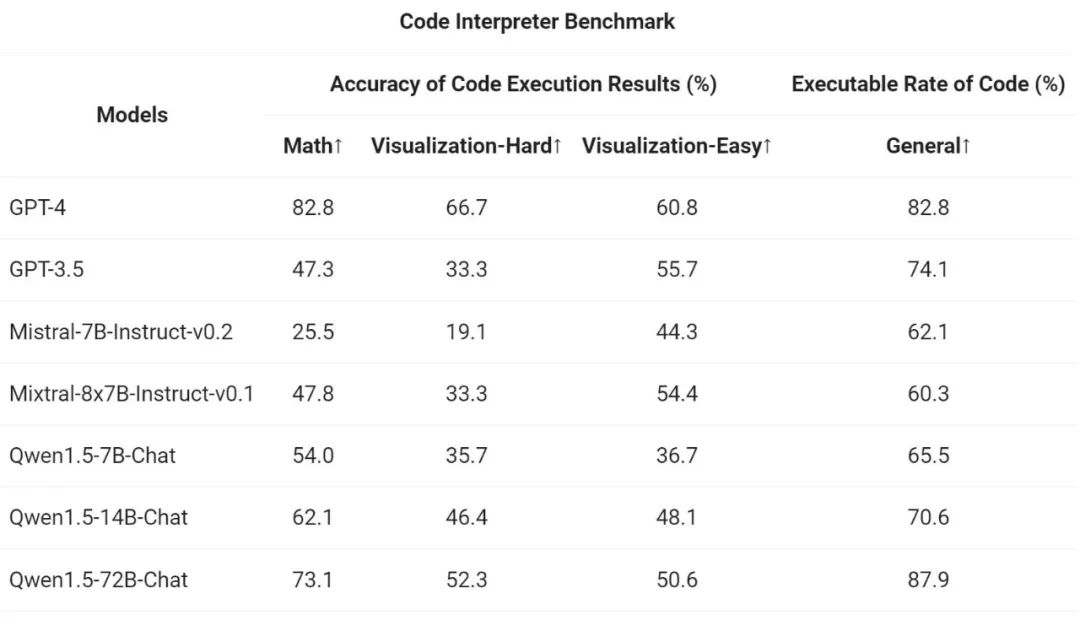
Hasilnya menunjukkan bahawa model Qwen1.5-Chat yang lebih besar secara amnya mengatasi model yang lebih kecil, dengan Qwen1.5-72B-Chat menghampiri prestasi penggunaan alat GPT-4. Walau bagaimanapun, dalam tugas penterjemah kod seperti penyelesaian masalah matematik dan visualisasi, malah model Qwen1.5-72B-Chat yang terbesar ketinggalan dengan ketara di belakang GPT-4 dari segi keupayaan pengekodan. Ali menyatakan bahawa ia akan meningkatkan keupayaan pengekodan semua model Qwen semasa proses pra-latihan dan penjajaran dalam versi akan datang.
Qwen1.5 disepadukan dengan asas kod transformer HuggingFace. Bermula dari versi 4.37.0, pembangun boleh terus menggunakan kod asli pustaka transformer tanpa memuatkan sebarang kod tersuai (menentukan pilihan trust_remote_code) untuk menggunakan Qwen1.5.
Dalam ekosistem sumber terbuka, Alibaba telah bekerjasama dengan vLLM, SGLang (untuk penggunaan), AutoAWQ, AutoGPTQ (untuk kuantifikasi), Axolotl, LLaMA-Factory (untuk penalaan halus) dan llama.cpp (untuk inferens LLM tempatan), dll. Kerjasama rangka kerja, semua rangka kerja ini kini menyokong Qwen1.5. Siri Qwen1.5 juga kini tersedia pada platform seperti Ollama dan LMStudio.
Atas ialah kandungan terperinci Tongyi Qianwen adalah sumber terbuka sekali lagi, Qwen1.5 membawakan enam model volum, dan prestasinya melebihi GPT3.5. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- php《7天魔鬼训练营》免费直播课程报名通知!!!!!!
- ai文件能用ps打开么
- ai将图片描出轮廓的基本步骤
- Google juga melakukannya? Bard didedahkan menggunakan data ChatGPT untuk latihan Model besar itu benar-benar ketinggalan langkah demi langkah.
- Melatih versi Cina ChatGPT tidaklah begitu sukar: anda boleh melakukannya dengan sumber terbuka Alpaca-LoRA+RTX 4090 tanpa A100