
Rumah >Peranti teknologi >AI >Melatih versi Cina ChatGPT tidaklah begitu sukar: anda boleh melakukannya dengan sumber terbuka Alpaca-LoRA+RTX 4090 tanpa A100
Melatih versi Cina ChatGPT tidaklah begitu sukar: anda boleh melakukannya dengan sumber terbuka Alpaca-LoRA+RTX 4090 tanpa A100

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-16 23:43:011930semak imbas
Pada tahun 2023, nampaknya hanya tinggal dua kem dalam medan chatbot: "OpenAI's ChatGPT" dan "Others".
ChatGPT berkuasa, tetapi hampir mustahil untuk OpenAI membuka sumbernya. Kem "lain" menunjukkan prestasi yang buruk, tetapi ramai orang mengusahakan sumber terbuka, seperti LLaMA, yang sumber terbuka oleh Meta suatu ketika dahulu.
LLaMA ialah nama umum untuk siri model dengan kuantiti parameter antara 7 bilion hingga 65 bilion Antaranya, model LLaMA 13 bilion boleh mengatasi parameter "pada kebanyakan penanda aras " GPT-3 dengan jumlah 175 bilion. Walau bagaimanapun, model tersebut belum menjalani penalaan arahan (instruct tuning), jadi kesan penjanaan adalah lemah.
Untuk meningkatkan prestasi model, penyelidik dari Stanford membantunya menyelesaikan kerja penalaan halus arahan dan melatih model baharu 7 bilion parameter yang dipanggil Alpaca (berdasarkan LLaMA 7B) . Secara khusus, mereka meminta model teks-davinci-003 OpenAI untuk menjana 52K sampel mengikut arahan dengan cara arahan kendiri sebagai data latihan untuk Alpaca. Keputusan eksperimen menunjukkan bahawa banyak gelagat Alpaca serupa dengan text-davinci-003. Dalam erti kata lain, prestasi model ringan Alpaca dengan hanya parameter 7B adalah setanding dengan model bahasa berskala sangat besar seperti GPT-3.5.

Bagi penyelidik biasa, ini adalah cara yang praktikal dan murah untuk memperhalusi, tetapi jumlah pengiraan masih memerlukan banyak (kata penulis Mereka memperhalusinya selama 3 jam pada lapan 80GB A100s). Selain itu, tugas benih Alpaca semuanya dalam bahasa Inggeris, dan data yang dikumpul juga dalam bahasa Inggeris, jadi model terlatih tidak dioptimumkan untuk bahasa Cina.
Untuk mengurangkan lagi kos penalaan halus, penyelidik lain dari Stanford, Eric J. Wang, menggunakan teknologi LoRA (penyesuaian peringkat rendah) untuk menghasilkan semula hasil Alpaca . Secara khusus, Eric J. Wang menggunakan kad grafik RTX 4090 untuk melatih model yang setara dengan Alpaca dalam masa 5 jam sahaja, mengurangkan keperluan kuasa pengkomputeran model sedemikian kepada tahap pengguna. Selain itu, model ini boleh dijalankan pada Raspberry Pi (untuk penyelidikan).
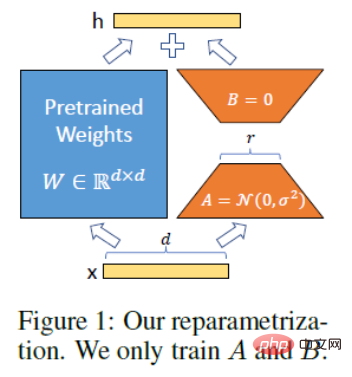
Prinsip teknikal LoRA. Idea LoRA adalah untuk menambah pintasan di sebelah PLM asal dan melakukan pengurangan dimensi dan kemudian operasi dimensi untuk mensimulasikan kedudukan intrinsik yang dipanggil. Semasa latihan, parameter PLM ditetapkan, dan hanya matriks pengurangan dimensi A dan matriks peningkatan dimensi B dilatih. Dimensi input dan output model kekal tidak berubah, dan parameter BA dan PLM ditindih semasa output. Mulakan A dengan taburan Gaussian rawak dan mulakan B dengan matriks 0 untuk memastikan matriks pintasan masih matriks 0 pada permulaan latihan (dipetik daripada: https://finisky.github.io/lora/). Kelebihan terbesar LoRA ialah ia lebih pantas dan menggunakan kurang memori, jadi ia boleh dijalankan pada perkakasan gred pengguna.

Projek Alpaca-LoRA disiarkan oleh Eric J. Wang.
Alamat projek: https://github.com/tloen/alpaca-lora
Untuk kelas yang ingin melatih diri Ini sudah pasti satu kejutan besar bagi penyelidik yang menggunakan model ChatGPT (termasuk versi Cina ChatGPT) tetapi tidak mempunyai sumber pengkomputeran peringkat atas. Oleh itu, selepas kemunculan projek Alpaca-LoRA, tutorial dan hasil latihan di sekitar projek itu terus muncul, dan artikel ini akan memperkenalkan beberapa daripadanya.
Cara menggunakan Alpaca-LoRA untuk memperhalusi LLaMA
Dalam projek Alpaca-LoRA, penulis menyebut bahawa untuk menyesuaikan dengan murah dan cekap, mereka menggunakan PEFT Hugging Face . PEFT ialah perpustakaan (LoRA ialah salah satu teknologi yang disokongnya) yang membolehkan anda mengambil pelbagai model bahasa berasaskan Transformer dan memperhalusinya menggunakan LoRA. Faedahnya ialah ia membolehkan anda memperhalusi model anda dengan murah dan cekap pada perkakasan sederhana, dengan output yang lebih kecil (mungkin boleh digubah).
Dalam blog baru-baru ini, beberapa penyelidik memperkenalkan cara menggunakan Alpaca-LoRA untuk memperhalusi LLaMA.
Terdapat beberapa prasyarat sebelum menggunakan Alpaca-LoRA. Yang pertama ialah pilihan GPU Terima kasih kepada LoRA, anda kini boleh melengkapkan penalaan halus pada GPU spesifikasi rendah seperti NVIDIA T4 atau 4090 GPU pengguna selain itu, anda juga perlu memohon pemberat LLaMA kerana pemberatnya tidak terbuka.
Sekarang prasyarat dipenuhi, langkah seterusnya ialah cara menggunakan Alpaca-LoRA. Mula-mula anda perlu mengklon repositori Alpaca-LoRA, kodnya adalah seperti berikut:
git clone https://github.com/daanelson/alpaca-lora cd alpaca-lora
Kedua, dapatkan pemberat LLaMA. Simpan nilai berat yang dimuat turun dalam folder bernama unconverted-weights Hierarki folder adalah seperti berikut:
unconverted-weights ├── 7B │ ├── checklist.chk │ ├── consolidated.00.pth │ └── params.json ├── tokenizer.model └── tokenizer_checklist.chk
Selepas pemberat disimpan, gunakan arahan berikut Tukar PyTorch. pemberat pusat pemeriksaan ke dalam format yang serasi dengan pengubah:
cog run python -m transformers.models.llama.convert_llama_weights_to_hf --input_dir unconverted-weights --model_size 7B --output_dir weights
Struktur direktori akhir hendaklah seperti ini:
weights ├── llama-7b └── tokenizermdki
Selepas pengendalian dua langkah di atas, datang ke langkah ketiga dan pasang Cog:
sudo curl -o /usr/local/bin/cog -L "https://github.com/replicate/cog/releases/latest/download/cog_$(uname -s)_$(uname -m)" sudo chmod +x /usr/local/bin/cog
Langkah keempat ialah memperhalusi model Secara lalai, GPU dikonfigurasikan pada fine-. skrip penalaan Kurang berkuasa, tetapi jika anda mempunyai GPU yang lebih baik, anda boleh meningkatkan MICRO_BATCH_SIZE dalam finetune.py kepada 32 atau 64. Selain itu, jika anda mempunyai arahan untuk menala set data, anda boleh mengedit DATA_PATH dalam finetune.py untuk menghala ke set data anda sendiri. Perlu diingatkan bahawa operasi ini harus memastikan bahawa format data adalah sama dengan alpaca_data_cleaned.json. Seterusnya jalankan skrip penalaan halus:
cog run python finetune.py
Proses penalaan halus mengambil masa 3.5 jam pada GPU A100 40GB dan lebih banyak masa pada GPU yang kurang berkuasa.
Langkah terakhir ialah menjalankan model dengan Cog:
$ cog predict -i prompt="Tell me something about alpacas." Alpacas are domesticated animals from South America. They are closely related to llamas and guanacos and have a long, dense, woolly fleece that is used to make textiles. They are herd animals and live in small groups in the Andes mountains. They have a wide variety of sounds, including whistles, snorts, and barks. They are intelligent and social animals and can be trained to perform certain tasks.
Pengarang tutorial mengatakan bahawa selepas melengkapkan langkah di atas , anda boleh terus mencuba pelbagai Cara bermain, termasuk tetapi tidak terhad kepada:
- Bawa set data anda sendiri dan perhalusi LoRA anda sendiri, seperti penalaan halus LLaMA untuk menjadikannya bercakap seperti watak anime. Lihat: https://replicate.com/blog/fine-tune-llama-to-speak-like-homer-simpson
- Sebarkan model ke platform awan;
- Gabungkan dengan LoRA lain, seperti Stable Diffusion LoRA, dan gunakan ini pada medan imej
- Gunakan set data Alpaca (atau set data lain; ) untuk memperhalusi kemas kini model LLaMA yang besar dan melihat prestasinya. Ini boleh dilakukan dengan PEFT dan LoRA, walaupun ia memerlukan GPU yang lebih besar.
Projek terbitan Alpaca-LoRA
Walaupun prestasi Alpaca setanding dengan GPT 3.5, tugas benihnya semuanya dalam bahasa Inggeris dan data yang dikumpul juga dalam bahasa Inggeris , jadi model terlatih tidak mesra Cina. Untuk meningkatkan keberkesanan model dialog dalam bahasa Cina, mari kita lihat beberapa projek yang lebih baik.
Yang pertama ialah model bahasa Cina sumber terbuka Luotuo (Luotuo) oleh tiga pembangun individu dari Central China Normal University dan institusi lain Projek ini berdasarkan LLaMA, Stanford Alpaca, Alpaca LoRA , Japanese-Alpaca -Apabila LoRA selesai, penggunaan latihan boleh diselesaikan dengan satu kad. Menariknya, mereka menamakan model unta kerana kedua-dua LLaMA (llama) dan alpaca (alpaca) tergolong dalam ordo Artiodactyla - keluarga Camelidae. Dari sudut ini, nama ini juga diharapkan.
Model ini berdasarkan LLaMA sumber terbuka Meta dan dilatih dalam bahasa Cina dengan merujuk kepada projek Alpaca dan Alpaca-LoRA.
Alamat projek: https://github.com/LC1332/Chinese-alpaca-lora
Pada masa ini, projek itu telah mengeluarkan dua model, luotuo-lora-7b-0.1 dan luotuo-lora-7b-0.3, dan satu lagi model dirancang:
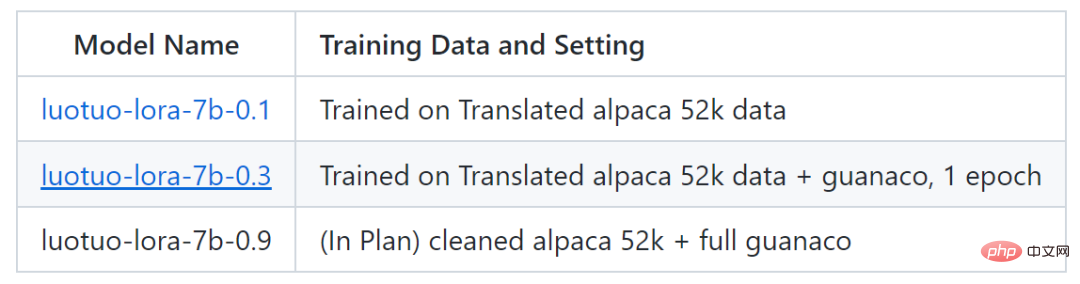
Berikut ialah paparan kesan:


Tetapi luotuo-lora-7b-0.1 (0.1 ) , luotuo-lora-7b-0.3 (0.3) masih mempunyai jurang Apabila pengguna meminta alamat Central China Normal University, 0.1 menjawab salah:

Selain perbualan ringkas, terdapat juga orang yang telah melakukan pengoptimuman model dalam bidang berkaitan insurans. Menurut pengguna Twitter ini, dengan bantuan projek Alpaca-LoRA, dia memasukkan beberapa data soal jawab insurans Cina, dan keputusan akhir adalah baik.
Secara khusus, penulis menggunakan lebih daripada 3K korpus insurans soal jawab bahasa Cina untuk melatih versi Cina Alpaca LoRa Proses pelaksanaan menggunakan kaedah LoRa dan memperhalusi model Alpaca 7B , yang mengambil masa 240 minit Kehilangan Akhir 0.87.

Sumber imej: https://twitter.com/nash_su/status/1639273900222586882
Berikut ialah proses dan keputusan latihan:
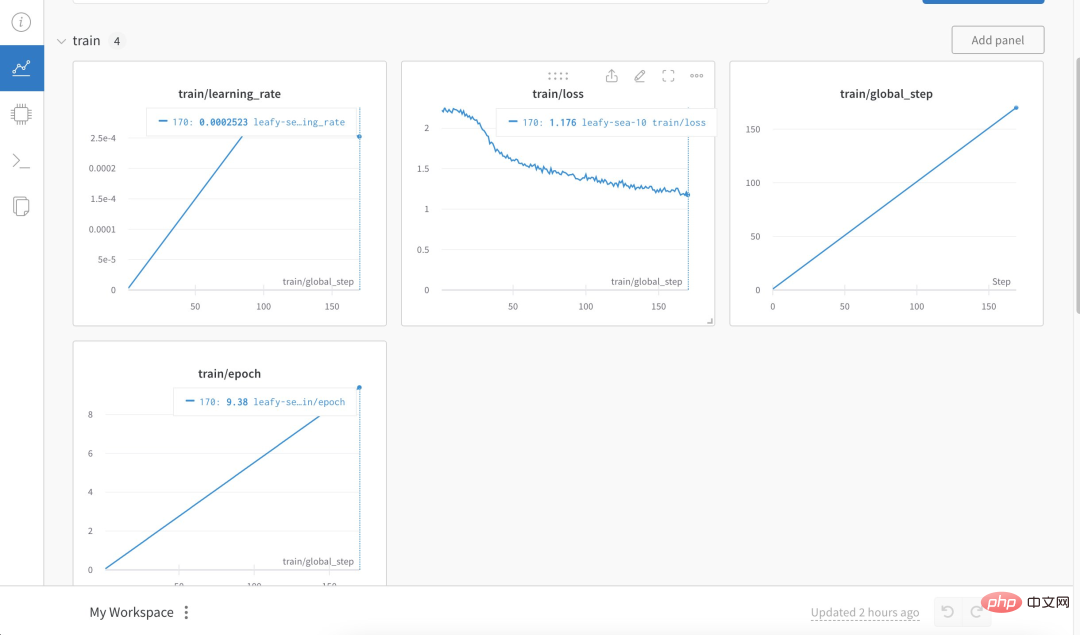
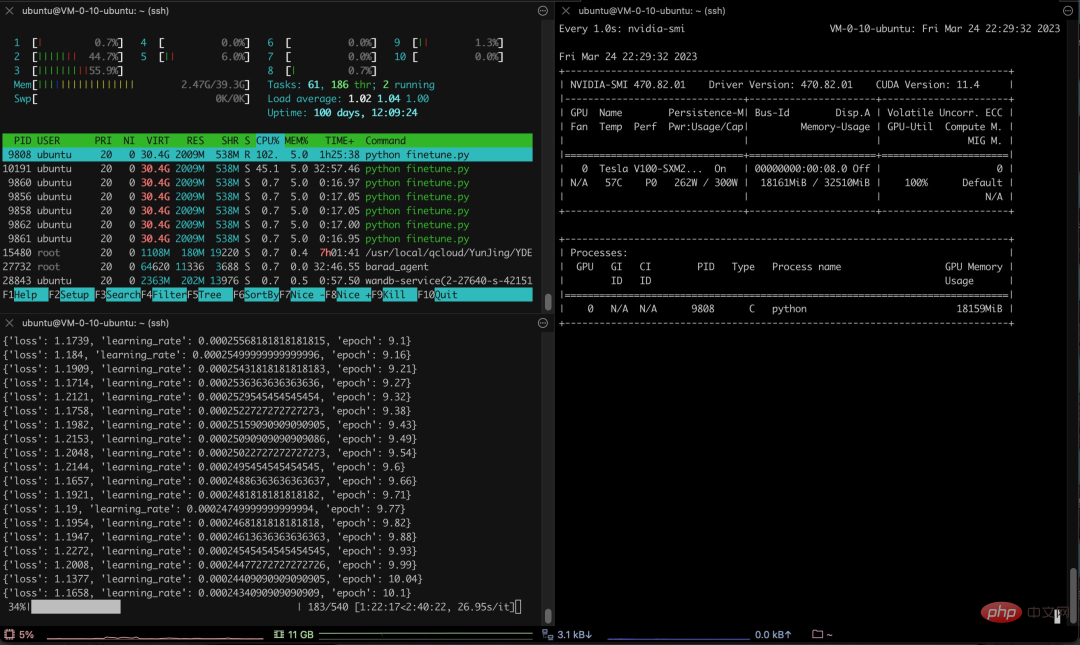
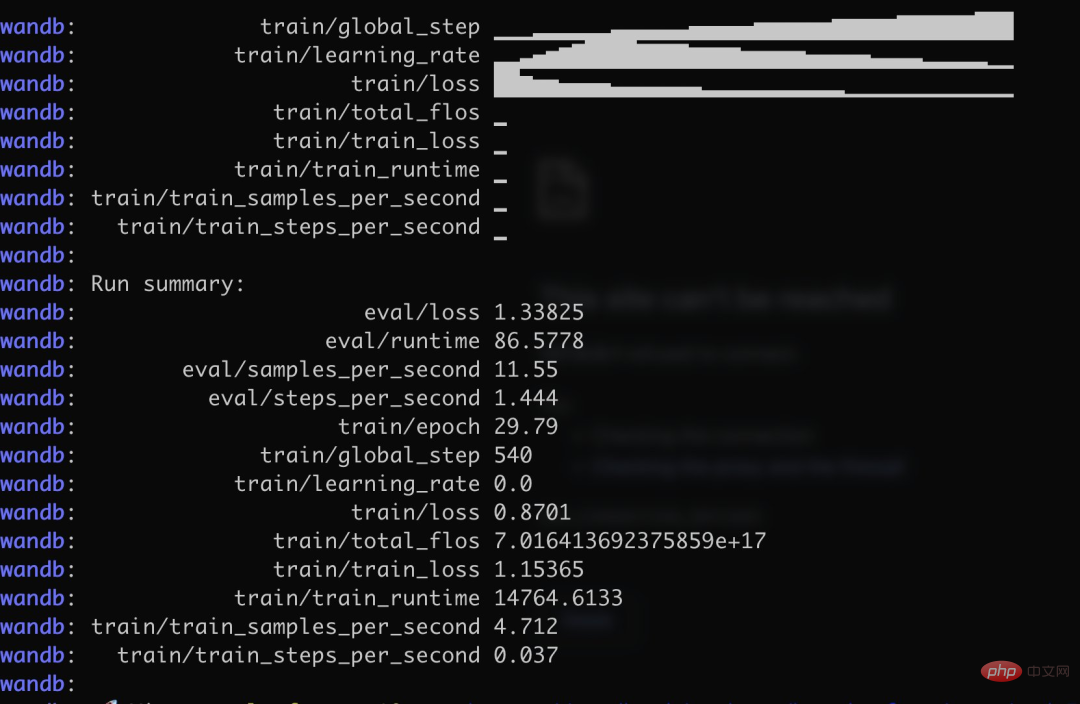
Keputusan ujian menunjukkan bahawa: 1. Kandungan yang berkaitan dengan korpus latihan boleh dijawab secara kasar dan munasabah, tetapi hanya jika ia bukan karut 2. Kandungan yang berkaitan dengan bukan korpus akan membalas secara paksa data dalam korpus tertentu 3. Penaakulan logik dan pengiraan matematik tidak mempunyai keupayaan ini.
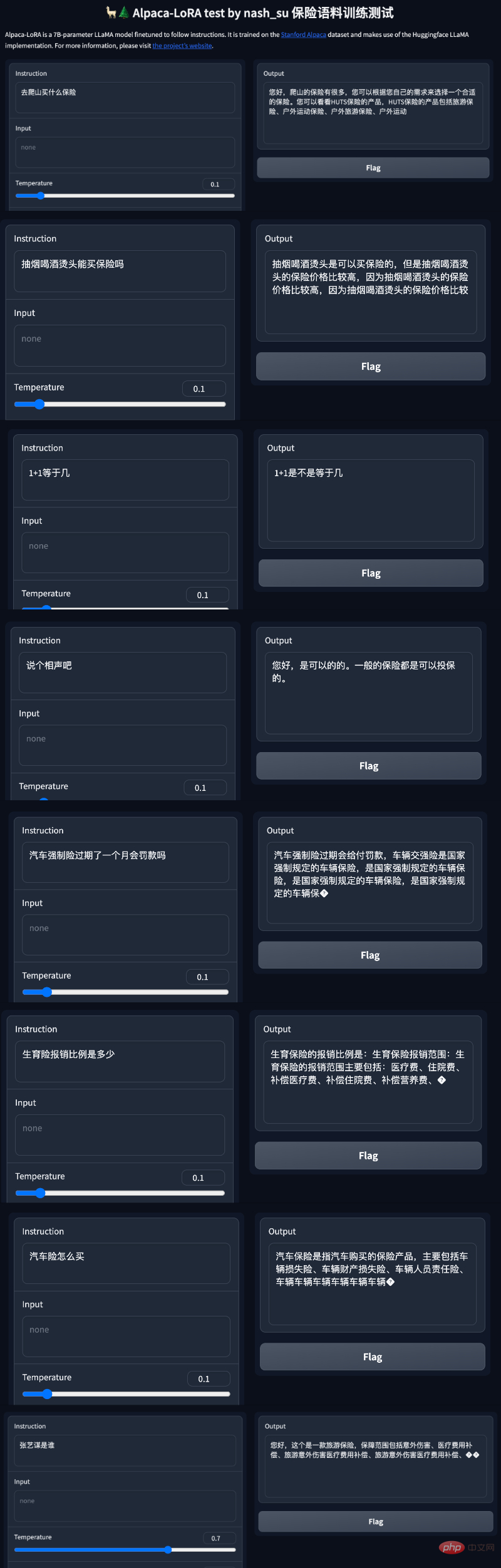
Selepas melihat keputusan ini, netizen menjerit bahawa mereka akan kehilangan pekerjaan:

Akhir sekali, kami menantikan lebih banyak model dialog Cina ditambah.
Atas ialah kandungan terperinci Melatih versi Cina ChatGPT tidaklah begitu sukar: anda boleh melakukannya dengan sumber terbuka Alpaca-LoRA+RTX 4090 tanpa A100. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI