
Rumah >Peranti teknologi >AI >Meningkatkan prestasi GPT-4/Llama2 dengan ketara tanpa RLHF, pasukan Universiti Peking mencadangkan paradigma baharu penjajaran Aligner
Meningkatkan prestasi GPT-4/Llama2 dengan ketara tanpa RLHF, pasukan Universiti Peking mencadangkan paradigma baharu penjajaran Aligner

- PHPzke hadapan
- 2024-02-07 22:06:371249semak imbas
Latar Belakang
Walaupun model bahasa besar (LLM) telah menunjukkan keupayaan yang hebat, mereka juga mungkin menghasilkan output yang tidak dapat diramalkan dan berbahaya, seperti tindak balas yang menyinggung perasaan, maklumat palsu dan data peribadi yang bocor, menyebabkan kemudaratan kepada pengguna dan masyarakat . Memastikan tingkah laku model ini selari dengan niat dan nilai manusia adalah cabaran yang mendesak.
Walaupun pembelajaran pengukuhan berdasarkan maklum balas manusia (RLHF) menyediakan penyelesaian, ia menghadapi seni bina latihan yang kompleks, kepekaan yang tinggi terhadap parameter dan ketidakstabilan model ganjaran pada pelbagai cabaran. Faktor-faktor ini menjadikan teknologi RLHF sukar untuk dilaksanakan, berkesan dan boleh dihasilkan semula. Untuk mengatasi cabaran ini, pasukan Universiti Peking mencadangkan paradigma penjajaran cekap baharu -
Aligner, terasnya terletak pada mempelajari baki yang diubah suai antara jawapan sejajar dan tidak sejajar proses RLHF yang menyusahkan. Dengan menggunakan idea baki pembelajaran dan penyeliaan boleh skala, Aligner memudahkan proses penjajaran. Ia menggunakan model Seq2Seq untuk mempelajari baki tersirat dan mengoptimumkan penjajaran melalui langkah replikasi dan pembetulan baki.
Berbanding dengan kerumitan RLHF, yang memerlukan latihan berbilang model, kelebihan Aligner ialah penjajaran boleh dicapai hanya dengan menambah modul selepas model yang hendak dijajarkan. Tambahan pula, sumber pengiraan yang diperlukan bergantung terutamanya pada kesan penjajaran yang diingini dan bukannya saiz model huluan. Eksperimen telah membuktikan bahawa menggunakan Aligner-7B boleh meningkatkan kebermanfaatan dan keselamatan GPT-4 dengan ketara, dengan bantuan meningkat sebanyak 17.5% dan keselamatan meningkat sebanyak 26.9%. Keputusan ini menunjukkan bahawa Aligner ialah kaedah penjajaran yang cekap dan berkesan, menyediakan penyelesaian yang boleh dilaksanakan untuk peningkatan prestasi model.Selain itu, menggunakan rangka kerja Aligner, pengarang meningkatkan prestasi model kuat (Llama-70B) melalui isyarat penyeliaan model lemah (Aligner-13B), mencapai
lemah-ke-kuat generalisasi dan menyediakan penyelesaian praktikal untuk penjajaran super.
Alamat kertas: https://arxiv.org/abs/2402.02416
- Laman utama projek & alamat sumber terbuka: https://arxiv.org/abs/2402.02416🎚 Tajuk: Penjajaran: Mencapai Penjajaran Cekap Melalui Pembetulan Kuat LEMAH
- Apakah Jawapan GNED g
- Lebih mudah untuk membetulkan jawapan yang tidak sejajar.
Sebagai model Seq2Seq autoregresif, Aligner melakukan pada Query-Answer-Correction (Q-A-C) data Latih antara penjajaran pada set dan jawapan tidak sejajar, dengan itu mencapai penjajaran model yang lebih tepat. Sebagai contoh, apabila menjajarkan 70B LLM, Aligner-7B secara besar-besaran mengurangkan jumlah parameter latihan, iaitu 16.67 kali lebih kecil daripada DPO dan 30.7 kali lebih kecil daripada RLHF. 
Paradigma Aligner mencapai generalisasi daripada lemah kepada kuat, dan menggunakan model Aligner dengan kuantiti parameter tinggi dan kecil untuk menyelia isyarat untuk memperhalusi LLM dengan kuantiti parameter yang besar, meningkatkan prestasi model kukuh dengan ketara. Sebagai contoh, penalaan halus Llama2-70B di bawah penyeliaan Aligner-13B telah meningkatkan keberkesanan dan keselamatannya masing-masing sebanyak 8.2% dan 61.6%.
Disebabkan sifat plug-and-play Aligner dan ketidakpekaannya terhadap parameter model, ia boleh menjajarkan model seperti GPT3.5, GPT4 dan Claude2 yang tidak dapat memperoleh parameter. Dengan hanya satu sesi latihan, Aligner-7B menjajarkan dan mempertingkatkan kemanfaatan dan keselamatan 11 model, termasuk model dijajarkan sumber tertutup, sumber terbuka dan selamat/tidak terjamin. Antaranya, Aligner-7B meningkatkan dengan ketara kemanfaatan dan keselamatan GPT-4 masing-masing sebanyak 17.5% dan 26.9%.
Penjajaran prestasi keseluruhan
- Pengarang menunjukkan bahawa Penjajaran pelbagai saiz (7B, 13B, 70B) boleh digunakan dalam model berasaskan API dan model sumber terbuka (termasuk penjajaran tanpa penjajaran selamat ) Meningkatkan prestasi. Secara umum, apabila model menjadi lebih besar, prestasi Aligner bertambah baik secara beransur-ansur, dan ketumpatan maklumat yang boleh diberikannya semasa pembetulan meningkat secara beransur-ansur, yang juga menjadikan jawapan yang diperbetulkan lebih selamat dan lebih membantu.
Bagaimana untuk melatih model Aligner?
1. Pengumpulan Data Pertanyaan-Jawapan (Q-A)
Pengarang memperoleh Pertanyaan daripada pelbagai set data sumber terbuka, termasuk Stanford Alpaca, ShareGPT, HH-RLHF dan perbualan yang dikongsi pengguna lain. Soalan-soalan ini menjalani proses penyingkiran corak pendua dan penapisan kualiti untuk jawapan seterusnya dan penjanaan jawapan yang diperbetulkan. Jawapan yang tidak dibetulkan telah dijana menggunakan pelbagai model sumber terbuka seperti Alpaca-7B, Vicuna-(7B,13B,33B), Llama2-(7B,13B)-Chat dan Alpaca2-(7B,13B). . Jawapan pekat.
Untuk jawapan yang sudah memenuhi kriteria, biarkan ia seadanya. Proses pengubahsuaian adalah berdasarkan satu set prinsip yang ditakrifkan dengan baik yang mewujudkan kekangan untuk latihan model Seq2Seq, dengan tumpuan untuk menjadikan jawapan lebih membantu dan lebih selamat. Taburan jawapan berubah dengan ketara sebelum dan selepas pembetulan Rajah berikut jelas menunjukkan kesan pengubahsuaian pada set data:
3. pengarang membina set data baharu yang diperbetulkan
, di mana
mewakili soalan pengguna,
ialah jawapan yang diperbetulkan berdasarkan prinsip yang ditetapkan.
Proses latihan model agak mudah. Pengarang melatih model Seq2Seq bersyarat  diparameterkan oleh
diparameterkan oleh  , supaya jawapan asal
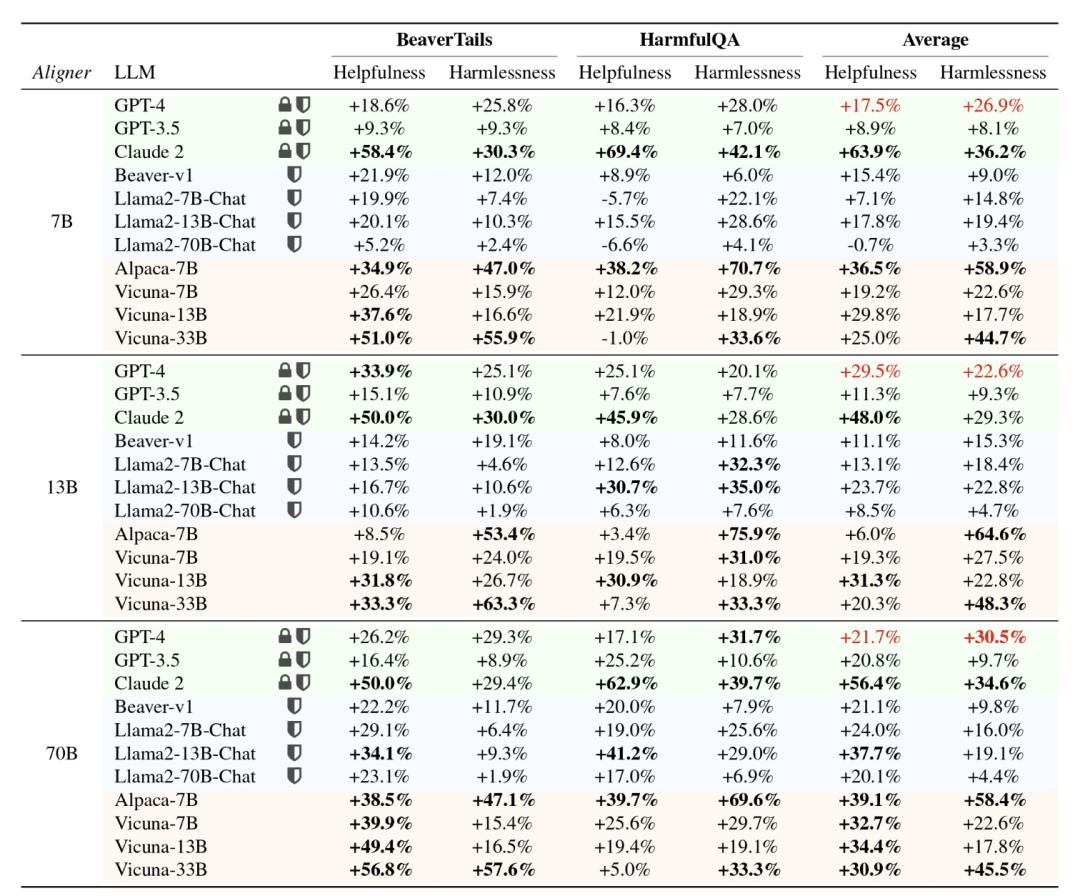
, supaya jawapan asal 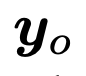 diedarkan semula kepada jawapan sejajar.
diedarkan semula kepada jawapan sejajar.  Proses penjanaan jawapan penjajaran berdasarkan model bahasa besar huluan ialah:
Proses penjanaan jawapan penjajaran berdasarkan model bahasa besar huluan ialah:
 Kehilangan latihan adalah seperti berikut:
Kehilangan latihan adalah seperti berikut: 
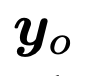

tiada apa-apa parameter yang perlu dilakukan , dan objektif latihan Aligner boleh diperolehi Untuk:

Angka berikut secara dinamik menunjukkan proses perantaraan Aligner:

Amatlah penting untuk tidak mengambil kira akses Aligner. model huluan semasa kedua-dua fasa latihan dan inferens. Proses penaakulan Aligner hanya perlu mendapatkan soalan pengguna dan jawapan awal yang dihasilkan oleh model bahasa besar huluan, dan kemudian menjana jawapan yang lebih konsisten dengan nilai kemanusiaan.
Membetulkan jawapan sedia ada dan bukannya menjawab terus membolehkan Aligner menyelaraskan dengan mudah dengan nilai kemanusiaan, dengan ketara mengurangkan keperluan pada keupayaan model.
Penjajaran berbanding dengan paradigma penjajaran sedia ada
Penjajaran vs SFT
Bertentangan dengan Penjajaran, SFT secara langsung mewujudkan proses semantik merentas domain ini daripada ruang semantik Query pada Model huluan untuk membuat kesimpulan dan mensimulasikan pelbagai konteks dalam ruang semantik adalah lebih sukar daripada belajar untuk membetulkan isyarat.
Paradigma latihan aligner boleh dianggap sebagai satu bentuk pembelajaran sisa (residual correction) Penulis mencipta paradigma pembelajaran "copy + correct" dalam Aligner. Oleh itu, Aligner pada asasnya mencipta pemetaan sisa daripada ruang semantik jawapan kepada ruang semantik jawapan yang disemak semula, di mana kedua-dua ruang semantik adalah lebih dekat secara taburan.
Untuk tujuan ini, pengarang membina data Q-A-A dalam perkadaran berbeza daripada set data latihan Q-A-C, dan melatih Aligner untuk melaksanakan pembelajaran pemetaan identiti (juga dipanggil pemetaan salinan) (dipanggil langkah memanaskan badan). Atas dasar ini, keseluruhan set data latihan Q-A-C digunakan untuk latihan Paradigma pembelajaran sisa ini juga digunakan dalam ResNet untuk menyelesaikan masalah kehilangan kecerunan yang disebabkan oleh susunan rangkaian saraf yang terlalu dalam. Keputusan eksperimen menunjukkan bahawa model boleh mencapai prestasi terbaik apabila nisbah prapemanasan ialah 20%.
Aligner vs RLHF
RLHF melatih model ganjaran (RM) pada set data keutamaan manusia dan menggunakan model ganjaran ini untuk memperhalusi LLM algoritma PPO untuk menjadikan LLM konsisten dengan tingkah laku daripada keutamaan manusia.
Secara khusus, model ganjaran perlu memetakan data keutamaan manusia daripada ruang berangka diskret kepada berterusan untuk pengoptimuman, tetapi berbanding dengan model Seq2Seq dengan keupayaan generalisasi yang kuat dalam ruang teks, model ganjaran berangka jenis ini mempunyai Keupayaan generalisasi teks ruang adalah lemah, yang membawa kepada kesan tidak stabil RLHF pada model yang berbeza.
Aligner mempelajari perbezaan (sisa) antara jawapan sejajar dan tidak sejajar dengan melatih model Seq2Seq, dengan itu berkesan mengelakkan proses RLHF dan mencapai prestasi generalisasi yang lebih baik daripada RLHF.
Aligner vs. Kejuruteraan Prompt
Prompt Kejuruteraan adalah kaedah yang sama untuk merangsang keupayaan LLMS. disasarkan pada berbeza Model direka secara berbeza, dan kesan akhir bergantung pada keupayaan model Apabila keupayaan model tidak mencukupi untuk menyelesaikan tugas, berbilang lelaran mungkin diperlukan, yang membazir tetingkap konteks terhad model kecil akan menjejaskan kesan projek perkataan segera, dan untuk Untuk model besar, mengambil konteks terlalu lama meningkatkan kos latihan dengan ketara.
Aligner sendiri boleh menyokong penjajaran mana-mana model Selepas satu latihan, ia boleh menjajarkan 11 jenis model yang berbeza tanpa menduduki tetingkap konteks model asal. Perlu diingat bahawa Aligner boleh digabungkan dengan lancar dengan kaedah kejuruteraan kata segera sedia ada untuk mencapai kesan 1+1>2.
Secara amnya: Aligner menunjukkan kelebihan ketara berikut:
1 Latihan penjajar adalah lebih mudah. Berbanding dengan pembelajaran model ganjaran kompleks RLHF dan proses penalaan halus pembelajaran (RL) berdasarkan model ini, proses pelaksanaan Aligner adalah lebih langsung dan mudah dikendalikan. Melihat kembali butiran pelarasan parameter kejuruteraan berbilang yang terlibat dalam RLHF dan ketidakstabilan yang wujud serta kepekaan hiperparameter algoritma RL, Aligner sangat memudahkan kerumitan kejuruteraan.
2.Aligner mempunyai kurang data latihan dan kesan penjajaran yang jelas. Melatih model Aligner-7B berdasarkan data 20K boleh meningkatkan kemanfaatan GPT-4 sebanyak 12% dan keselamatan sebanyak 26%, serta meningkatkan kemanfaatan model Vicuna 33B sebanyak 29% dan keselamatan sebanyak 45.3%. pelarasan parameter yang diperhalusi untuk mencapai kesan ini.
3.Penjajar tidak perlu menyentuh berat model. Walaupun RLHF terbukti berkesan dalam penjajaran model, ia bergantung pada latihan langsung model. Kebolehgunaan RLHF adalah terhad dalam menghadapi model berasaskan API bukan sumber terbuka seperti GPT-4 dan keperluan penalaan halusnya dalam tugas hiliran. Sebaliknya, Aligner tidak memerlukan manipulasi langsung parameter asal model dan mencapai penjajaran fleksibel dengan menyuarakan keperluan penjajaran dalam modul penjajaran bebas.
4.Aligner tidak peduli dengan jenis model. Di bawah rangka kerja RLHF, penalaan halus untuk model berbeza (seperti Llama2, Alpaca) bukan sahaja memerlukan pengumpulan semula data keutamaan, tetapi juga memerlukan pelarasan parameter latihan dalam latihan model ganjaran dan peringkat RL. Penjajar boleh menyokong penjajaran mana-mana model melalui latihan sekali sahaja. Contohnya, dengan melatih sekali sahaja pada set data yang diperbetulkan, Aligner-7B boleh menjajarkan 11 model berbeza (termasuk model sumber terbuka, model API seperti GPT) dan meningkatkan prestasi masing-masing sebanyak 21.9% dan 23.8% dari segi bantuan dan keselamatan.
5.Permintaan Aligner untuk sumber latihan adalah lebih fleksibel. RLHF Penalaan halus model 70B masih sangat menuntut sumber pengkomputeran, memerlukan ratusan kad GPU untuk berprestasi. Kerana kaedah RLHF juga memerlukan pemuatan tambahan model ganjaran, model pelakon dan model pengkritik yang setara dengan bilangan parameter model. Oleh itu, dari segi penggunaan sumber latihan setiap unit masa, RLHF sebenarnya memerlukan lebih banyak sumber pengkomputeran daripada pra-latihan.
Sebagai perbandingan, Aligner menyediakan strategi latihan yang lebih fleksibel, membolehkan pengguna memilih skala latihan Aligner secara fleksibel berdasarkan sumber pengkomputeran sebenar mereka. Sebagai contoh, untuk keperluan penjajaran model 70B, pengguna boleh memilih model Penjajaran dengan saiz yang berbeza (7B, 13B, 70B, dsb.) berdasarkan sumber sebenar yang tersedia untuk mencapai penjajaran berkesan model sasaran.
Fleksibiliti ini bukan sahaja mengurangkan permintaan mutlak untuk sumber pengkomputeran, tetapi juga menyediakan pengguna dengan kemungkinan penjajaran yang cekap di bawah sumber terhad. Generalisasi lemah-ke-kuat. model yang kukuh boleh meningkatkan prestasinya. OpenAI menggunakan analogi ini untuk menyelesaikan masalah SuperAlignment Secara khusus, mereka menggunakan label kebenaran tanah untuk melatih model yang lemah.
Penyelidik OpenAI menjalankan beberapa eksperimen awal Sebagai contoh, pada tugas klasifikasi teks, set data latihan dibahagikan kepada dua bahagian Input dan label kebenaran asas pada separuh pertama digunakan untuk melatih model yang lemah separuh daripada data latihan hanya mengekalkan input, dan label dihasilkan oleh model yang lemah. Hanya label lemah yang dihasilkan oleh model lemah digunakan untuk menyediakan isyarat penyeliaan untuk model kuat apabila melatih model kuat.
Tujuan melatih model yang lemah menggunakan label nilai sebenar adalah untuk membolehkan model yang lemah memperoleh keupayaan untuk menyelesaikan tugas yang sepadan, tetapi input yang digunakan untuk menjana label yang lemah dan input yang digunakan untuk melatih model yang lemah tidak yang sama. Paradigma ini sama dengan konsep “pengajaran”, iaitu menggunakan model yang lemah untuk membimbing model yang kuat. 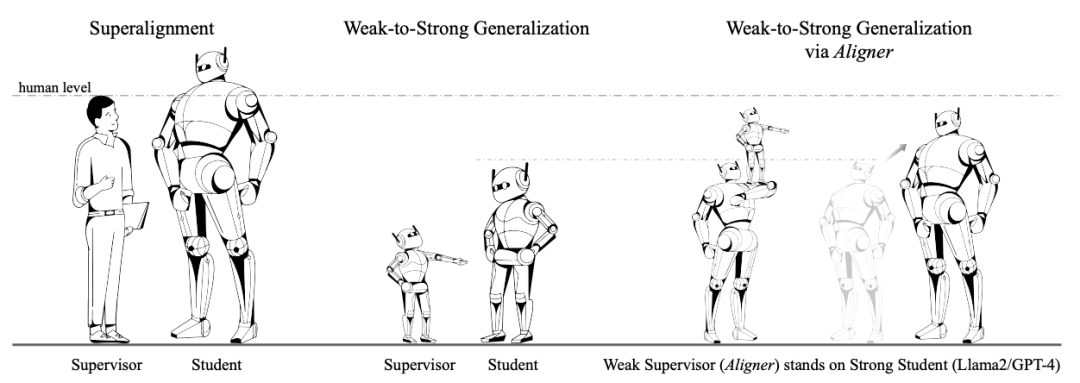 Pengarang mencadangkan paradigma generalisasi novel lemah-ke-kuat berdasarkan sifat-sifat Aligner.
Pengarang mencadangkan paradigma generalisasi novel lemah-ke-kuat berdasarkan sifat-sifat Aligner.
Inti utama pengarang adalah untuk membiarkan Aligner bertindak sebagai "penyelia yang berdiri di atas bahu gergasi". Tidak seperti kaedah OpenAI yang menyelia secara langsung "gergasi", Aligner akan membetulkan model yang lebih kuat melalui pembetulan yang lemah kepada yang kuat untuk menyediakan label yang lebih tepat dalam proses itu.
Secara khusus, semasa proses latihan Aligner, data yang diperbetulkan mengandungi GPT-4, anotasi manusia dan anotasi model yang lebih besar. Selepas itu, pengarang menggunakan Aligner untuk menghasilkan label yang lemah (iaitu pembetulan) pada set data Q-A baharu dan kemudian menggunakan label yang lemah untuk memperhalusi model asal.
Hasil eksperimen menunjukkan bahawa paradigma ini boleh meningkatkan lagi prestasi penjajaran model.
Hasil eksperimen
Aligner lwn SFT/RLHF/DPO
Pengarang menggunakan set data latihan Pertanyaan-Jawapan-Pembetulan Aligner untuk memperhalusi Alpaca-ORLHF melalui kaedah Alpaca-RLH/7B masing-masing
Apabila melakukan penilaian prestasi, set data gesaan ujian BeaverTails dan HarmfulQA sumber terbuka digunakan untuk membandingkan jawapan yang dijana oleh model diperhalusi dengan jawapan yang dijana oleh model Alpaca-7B asal menggunakan Aligner untuk membetulkan jawapan. Dari segi membantu dan Perbandingan dari segi keselamatan, keputusan adalah seperti berikut:
Hasil eksperimen menunjukkan bahawa Aligner mempunyai kelebihan yang jelas berbanding paradigma penjajaran LLM yang matang seperti SFT/RLHF/DPO, dari segi bantuan. dan keselamatan berada di hadapan.
Menganalisis kes eksperimen tertentu, didapati bahawa model penjajaran yang diperhalusi menggunakan paradigma RLHF/DPO mungkin lebih cenderung untuk menghasilkan jawapan konservatif untuk meningkatkan keselamatan, tetapi dalam proses meningkatkan sifat membantu, keselamatan tidak boleh diambil. mengambil kira, mengakibatkan jawapan Maklumat berbahaya dalam peningkatan.
Aligner vs Prompt Engineering
Compare Penambahbaikan prestasi Aligner-13b dan CAI / Kaedah Kritikan Sendiri pada model hulu yang sama. kepada GPT-4 Peningkatan dalam kedua-dua keselamatan dan keselamatan adalah lebih tinggi daripada kaedah CAI/Kritik Kendiri, yang menunjukkan bahawa paradigma Aligner mempunyai kelebihan yang jelas berbanding kaedah kejuruteraan segera yang biasa digunakan.
Perlu diingat bahawa gesaan CAI hanya digunakan semasa penaakulan dalam eksperimen untuk menggalakkan mereka mengubah suai sendiri jawapan mereka, yang juga merupakan salah satu bentuk Penapisan Diri.

Selain itu, penulis juga menjalankan kajian lanjutan Mereka membetulkan jawapan menggunakan kaedah CAI melalui Aaligner, dan secara langsung membandingkan jawapan sebelum dan selepas Aligner .

Method A: CAI + Aligner Kaedah B: CAI Only
Sether menggunakan Aligner untuk membetulkan Jawapan CAI yang diperbetulkan dua kali, jawapannya membantu dari segi keselamatan tanpa kehilangan keselamatan. telah dicapai. Ini menunjukkan bahawa Aligner bukan sahaja sangat berdaya saing apabila digunakan secara bersendirian, tetapi juga boleh digabungkan dengan kaedah penjajaran sedia ada lain untuk meningkatkan lagi prestasinya. . Set - 50K soalan, a mewakili jawapan yang dijana oleh model Alpaca-7B, dan a′ mewakili jawapan sejajar (q, a) yang diberikan oleh Aaligner-7B. Tidak seperti SFT, yang hanya menggunakan a′ sebagai label kebenaran asas, dalam latihan RLHF dan DPO, a′ dianggap lebih baik daripada a.
Pengarang menggunakan Aligner untuk membetulkan jawapan asal pada set data Q-A baharu, menggunakan jawapan yang diperbetulkan sebagai label lemah dan menggunakan label lemah ini sebagai isyarat penyeliaan untuk melatih model yang lebih besar. Proses ini serupa dengan paradigma latihan OpenAI.
Pengarang melatih model yang kukuh berdasarkan label yang lemah melalui tiga kaedah: SFT, RLHF dan DPO. Keputusan eksperimen dalam jadual di atas menunjukkan bahawa apabila model huluan diperhalusi melalui SFT, label lemah Aligner-7B dan Aligner-13B meningkatkan prestasi siri Llama2 model kuat dalam semua senario.
Outlook: Arah penyelidikan berpotensi bagi Aligner
Aligner, sebagai kaedah penjajaran yang inovatif, mempunyai potensi penyelidikan yang besar. Dalam kertas kerja, penulis mencadangkan beberapa senario aplikasi Aligner, termasuk:
1. Aplikasi senario dialog berbilang pusingan.
Dalam perbualan berbilang pusingan, cabaran untuk menghadapi ganjaran yang jarang adalah amat ketara. Dalam perbualan soal jawab (QA), isyarat pengawasan dalam bentuk skalar biasanya hanya tersedia pada penghujung perbualan.
Masalah jarang ini akan dipertingkatkan lagi dalam pelbagai pusingan dialog (seperti senario QA berterusan), menyukarkan maklum balas manusia berasaskan pembelajaran pengukuhan (RLHF) untuk berkesan. Menyiasat potensi Aligner untuk menambah baik penjajaran dialog merentas berbilang pusingan ialah bidang yang patut diterokai lebih lanjut.
2. Penjajaran nilai manusia kepada model ganjaran. Dalam proses berbilang peringkat membina model ganjaran berdasarkan keutamaan manusia dan memperhalusi model bahasa besar (LLM), terdapat cabaran besar dalam memastikan LLM diselaraskan dengan nilai kemanusiaan tertentu (cth. keadilan, empati, dll.).
Dengan menyerahkan tugas penjajaran nilai kepada modul penjajaran Penjajaran di luar model, dan menggunakan korpus khusus untuk melatih Penjajaran, ia bukan sahaja menyediakan idea baharu untuk penjajaran nilai, tetapi juga membolehkan Penjajaran mengubah suai output bahagian hadapan- model akhir untuk mencerminkan nilai tertentu.
3. Penstriman dan pemprosesan selari MoE-Aligner. Dengan mengkhusus dan menyepadukan Penjajar, anda boleh mencipta Penjajar Pakar Hibrid (KPM) yang lebih berkuasa dan komprehensif yang boleh memenuhi pelbagai keperluan keselamatan hibrid dan penjajaran nilai. Pada masa yang sama, meningkatkan lagi keupayaan pemprosesan selari Aligner untuk mengurangkan kehilangan masa inferens adalah arah pembangunan yang boleh dilaksanakan.
4. Gabungan semasa latihan model. Dengan menyepadukan lapisan Aligner selepas lapisan berat tertentu, campur tangan masa nyata dalam output semasa latihan model boleh dicapai. Kaedah ini bukan sahaja meningkatkan kecekapan penjajaran, tetapi juga membantu mengoptimumkan proses latihan model dan mencapai penjajaran model yang lebih cekap.
Pengenalan Pasukan
Kerja ini telah disiapkan secara bebas oleh pasukan penyelidik Yang Yaodong di Pusat Keselamatan dan Tadbir Urus AI Institut Kecerdasan Buatan Universiti Peking. Pasukan ini terlibat secara mendalam dalam teknologi penjajaran model bahasa besar, termasuk set data keutamaan penjajaran selamat peringkat juta sumber terbuka BeaverTails (NeurIPS 2023) dan algoritma penjajaran selamat SafeRLHF (ICLR 2024 Spotlight) untuk model bahasa besar yang ada telah diterima pakai oleh pelbagai model sumber terbuka. Menulis ulasan komprehensif pertama industri tentang penjajaran kecerdasan buatan dan memasangkannya dengan tapak web sumber www.alignmentsurvey.com (klik pada teks asal untuk melompat terus), secara sistematik menghuraikan empat perspektif Belajar daripada Maklum Balas, Pembelajaran di bawah Anjakan Pengedaran, Jaminan , dan masalah penjajaran AI di bawah. Pandangan pasukan tentang penjajaran dan penjajaran super telah dipaparkan pada kulit muka depan terbitan 5 Sanlian Life Weekly 2024.
Atas ialah kandungan terperinci Meningkatkan prestasi GPT-4/Llama2 dengan ketara tanpa RLHF, pasukan Universiti Peking mencadangkan paradigma baharu penjajaran Aligner. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!