
Rumah >Peranti teknologi >AI >Model besar sumber terbuka 100% pertama dalam sejarah ada di sini! Pendedahan pecah rekod kod/berat/set data/keseluruhan proses latihan, AMD boleh melatihnya
Model besar sumber terbuka 100% pertama dalam sejarah ada di sini! Pendedahan pecah rekod kod/berat/set data/keseluruhan proses latihan, AMD boleh melatihnya

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-02-04 10:03:271022semak imbas
Model bahasa telah menjadi teras teknologi pemprosesan bahasa semula jadi (NLP) selama bertahun-tahun. Memandangkan nilai komersil yang besar di sebalik model itu, butiran teknikal model yang paling maju belum didedahkan kepada umum.
Kini, model besar sumber terbuka sepenuhnya ada di sini!
Para penyelidik dari Allen Institute for Artificial Intelligence, University of Washington, Yale University, New York University, dan Carnegie Mellon University baru-baru ini bekerjasama untuk menerbitkan karya penting yang akan menjadi penting kepada pencapaian komuniti sumber terbuka AI.
Mereka telah membuat hampir semua data dan maklumat dalam proses melatih model besar dari awal sumber terbuka!
Kertas: https://allenai.org/olmo/olmo-paper.pdf
Berat: https://huggingface.co/allenai/OLMo-7B
://github.com/allenai/OLMo
Data: https://huggingface.co/datasets/allenai/dolma
Penilaian: https://github.com/allenai/OLMo-Eval
Penyesuaian: https://github.com/allenai/open-instruct

Khususnya, eksperimen Model Bahasa Terbuka (OLMo) yang dilancarkan oleh Institut Kepintaran Buatan Allen dan platform latihan, yang menyediakan sumber terbuka sepenuhnya model besar, serta semua data dan butiran teknikal yang berkaitan dengan latihan dan membangunkan model ini -
Latihan dan pemodelan: Ia termasuk berat model lengkap, Kod latihan, log latihan, kajian ablasi, metrik latihan, dan kod inferens.
Korpus pra-latihan: Korpus sumber terbuka pra-latihan yang mengandungi sehingga token 3T, serta kod untuk menjana data latihan ini. . .
 Pada masa yang sama, kod yang digunakan untuk inferens model, pelbagai penunjuk proses latihan, dan log latihan juga disediakan.
Pada masa yang sama, kod yang digunakan untuk inferens model, pelbagai penunjuk proses latihan, dan log latihan juga disediakan.
7B: OLMo 7B, OLMo 7B (tidak anil), OLMo 7B-2T, OLMo-7B-Twin-2T
alat penilaian
penilaian pembangunan: Suite ini termasuk lebih 500 pusat pemeriksaan dan kod penilaian untuk setiap 1000 langkah dalam setiap proses latihan model.
Semua data dilesenkan untuk digunakan di bawah apache 2.0 (percuma untuk kegunaan komersial).
Sumber terbuka yang begitu teliti seolah-olah menetapkan corak untuk komuniti sumber terbuka - pada masa hadapan, jika anda bukan sumber terbuka seperti saya, jangan katakan bahawa anda adalah model sumber terbuka.
Penilaian Prestasi
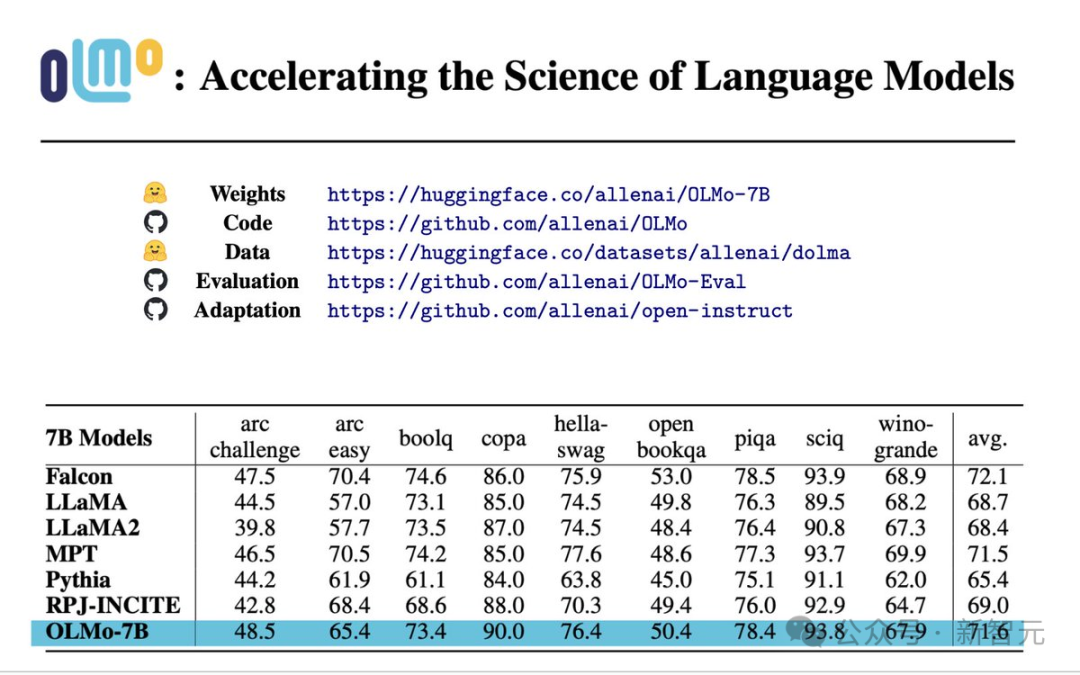
Antara 9 penilaian pertama, OLMo-7B menduduki tempat tiga teratas dalam 8 daripadanya, dan 2 daripadanya mengatasi semua model lain.
OLMo-7B mengatasi Llama 2 pada banyak tugas generasi atau tugas pemahaman bacaan (seperti truthfulQA), tetapi berprestasi lebih teruk pada beberapa tugasan soalan dan jawapan yang popular (seperti MMLU atau Big-bench Hard).
9 tugasan pertama ialah kriteria penilaian dalaman penyelidik untuk model pra-latihan, manakala tiga tugasan berikut telah ditambah untuk meningkatkan kedudukan LLM Terbuka HuggingFace
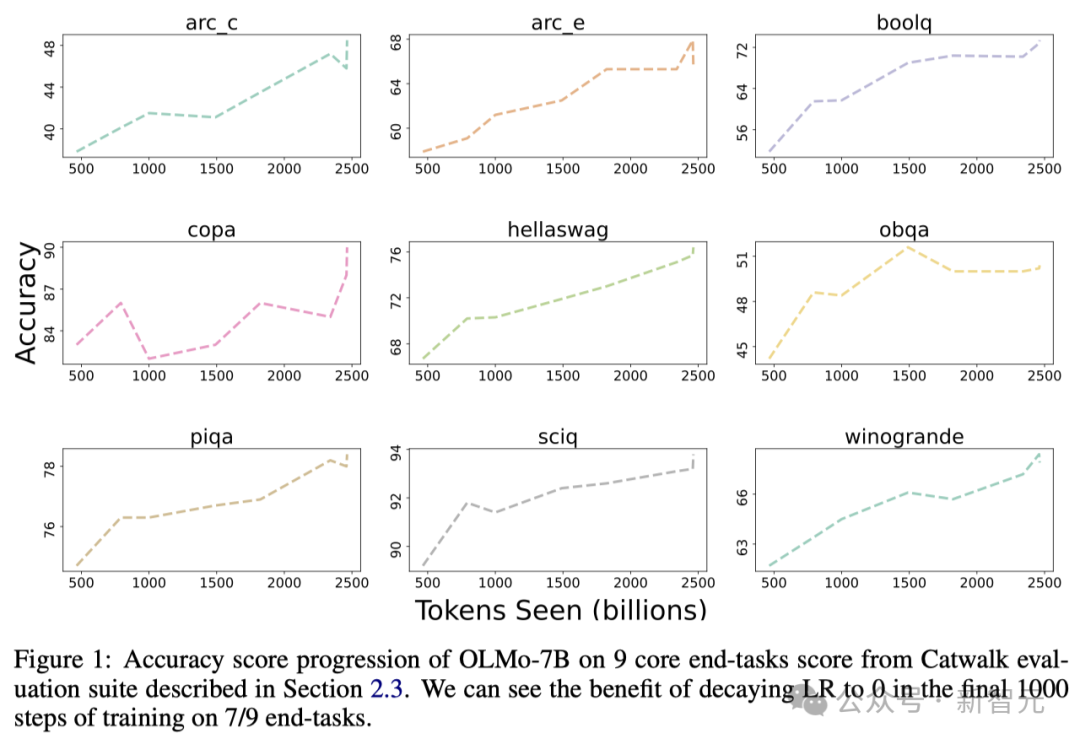
Rajah di bawah menunjukkan ketepatan 9 tugas teras Berubah trend.
Kecuali OBQA, memandangkan OLMo-7B menerima lebih banyak data untuk latihan, ketepatan hampir semua tugasan menunjukkan arah aliran menaik.
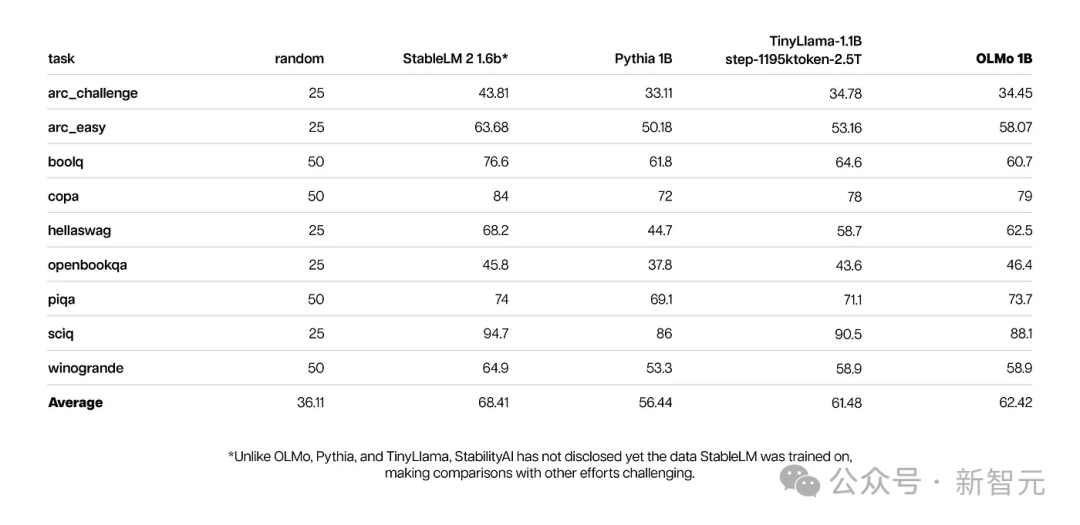
Pada masa yang sama, keputusan penilaian teras OLMo 1B dan model serupanya menunjukkan bahawa OLMo berada pada tahap yang sama dengan mereka.
Dengan menggunakan Paloma (penanda aras) Institut Allen AI dan pusat pemeriksaan yang tersedia, para penyelidik menganalisis hubungan antara keupayaan model untuk meramalkan bahasa dan faktor saiz model (seperti bilangan token yang dilatih).
Dapat dilihat bahawa OLMo-7B setanding dengan model arus perdana dalam prestasi. Antaranya, semakin rendah bilangan bit per bait (Bit per Byte), lebih baik.
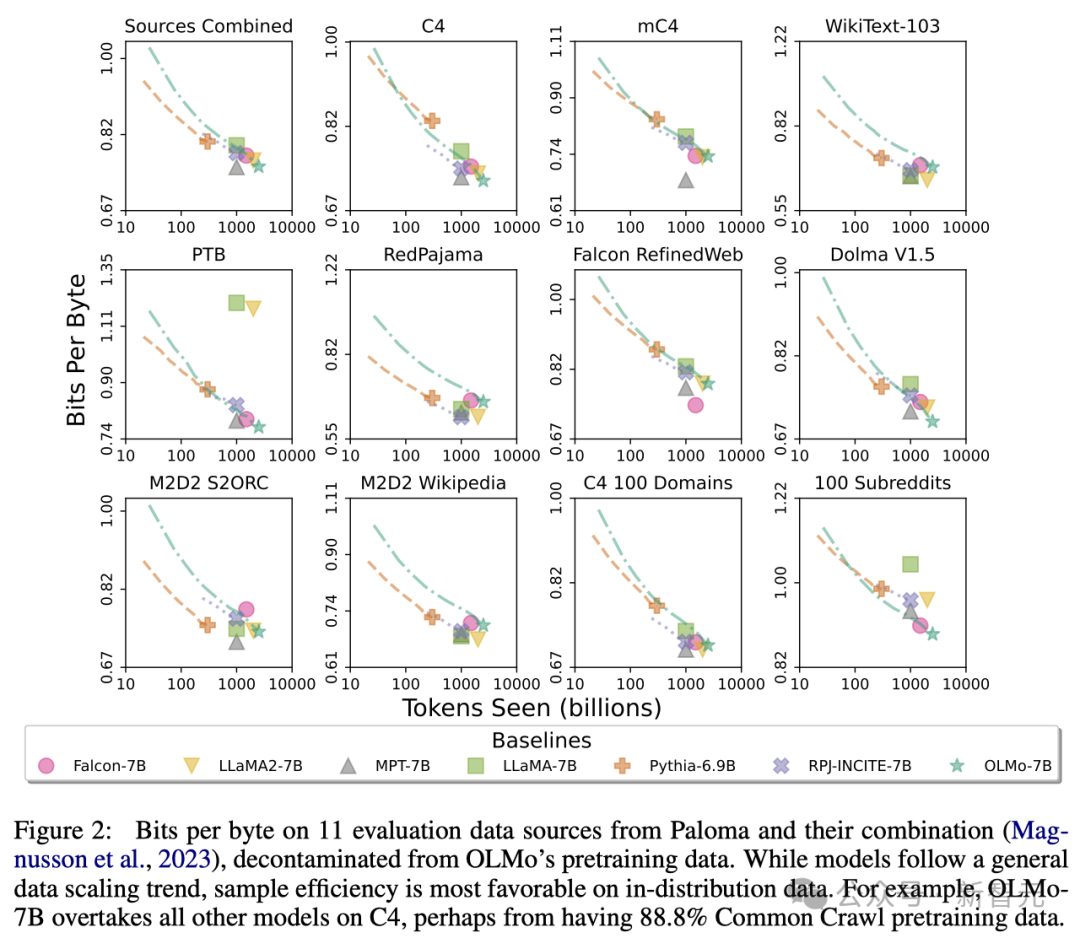
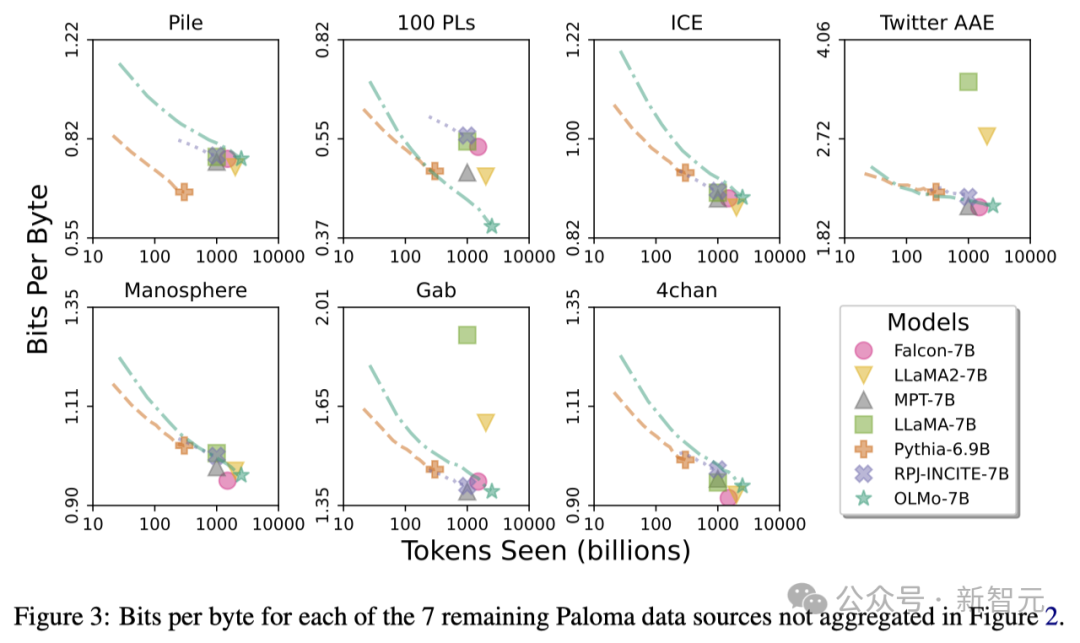
Melalui analisis ini, para penyelidik mendapati bahawa kecekapan model dalam memproses sumber data yang berbeza sangat berbeza, yang bergantung terutamanya pada persamaan antara data latihan model dan data penilaian.
Khususnya, OLMo-7B berprestasi baik pada sumber data terutamanya berdasarkan Common Crawl (seperti C4).
Walau bagaimanapun, OLMo-7B kurang cekap berbanding model lain pada sumber data yang mempunyai sedikit kaitan dengan teks mengikis web, seperti WikiText-103, M2D2 S2ORC dan M2D2 Wikipedia.
Penilaian RedPajama menunjukkan arah aliran yang sama, mungkin kerana hanya 2 daripada 7 medannya datang daripada Common Crawl, dan Paloma memberikan pemberat yang sama kepada setiap medan dalam setiap sumber data.
Memandangkan sumber data yang dipilih susun seperti kertas Wikipedia dan arXiv menyediakan data yang jauh lebih tidak heterogen berbanding teks yang dikikis web, adalah lebih cekap untuk mengekalkan kecekapan tinggi terhadap pengedaran bahasa ini apabila set data pra-latihan terus berkembang.
Seni bina OLMo
Dari segi seni bina model, pasukan ini berdasarkan seni bina Transformer penyahkod sahaja, mengguna pakai fungsi pengaktifan SwiGLU yang digunakan oleh PaLM dan Llama, dan memperkenalkan teknologi benam kedudukan putaran (RoPE). dan tokenizer berasaskan Pengekodan Pasangan Byte (BPE) GPT-NeoX-20B yang lebih baik untuk mengurangkan maklumat yang boleh dikenal pasti secara peribadi dalam output model.
Selain itu, untuk memastikan kestabilan model, penyelidik tidak menggunakan istilah bias (ini sama seperti PaLM).
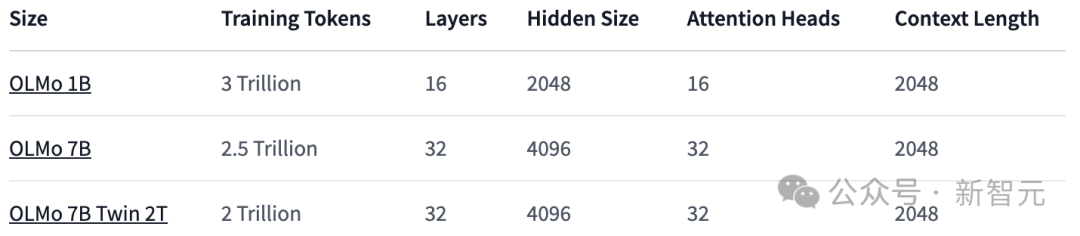
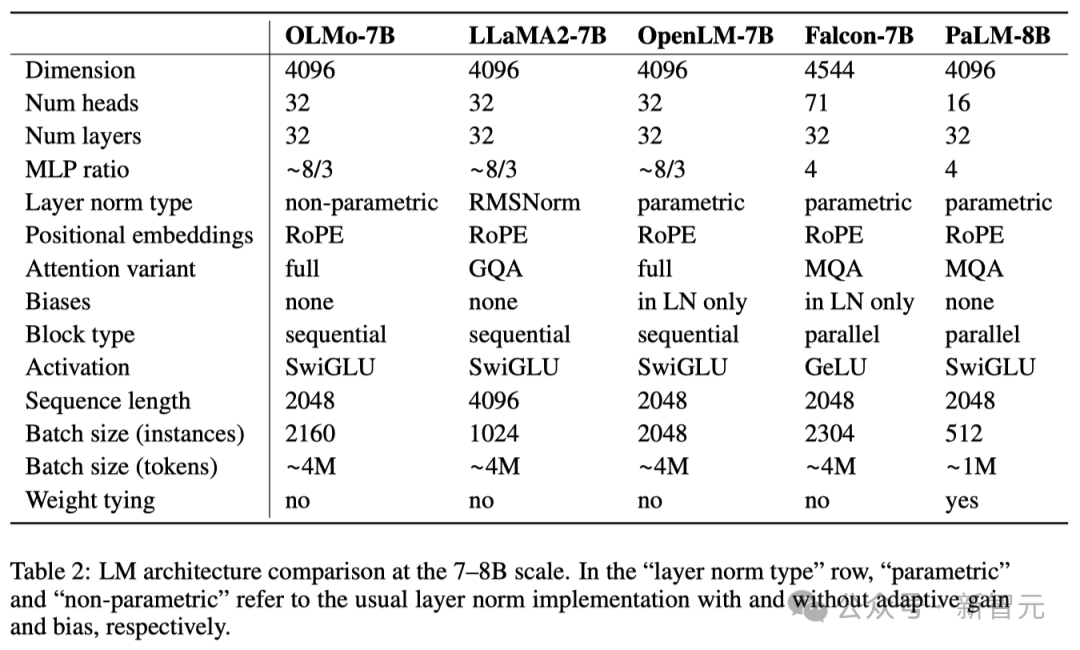
Seperti yang ditunjukkan dalam jadual di bawah, para penyelidik telah mengeluarkan dua versi, 1B dan 7B, dan juga merancang untuk melancarkan versi 65B tidak lama lagi.
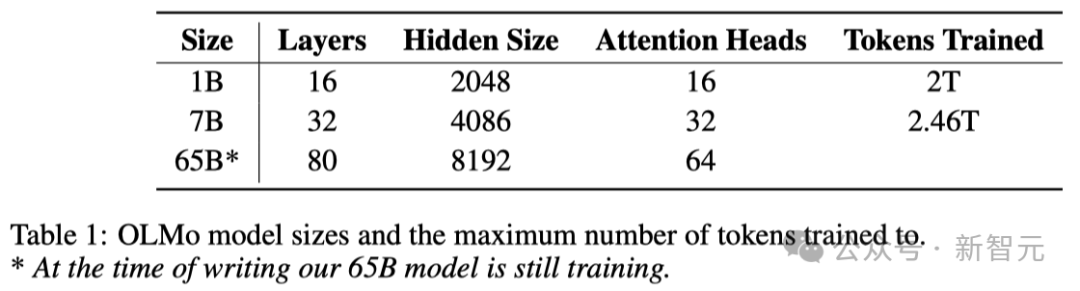
Jadual di bawah memberikan perbandingan terperinci prestasi seni bina 7B dengan model lain ini pada skala yang sama.
Dataset pra-latihan: Dolma
Walaupun penyelidik telah mencapai beberapa kemajuan dalam mendapatkan parameter model, tahap keterbukaan set data pralatihan semasa dalam komuniti sumber terbuka masih jauh dari mencukupi.
Data pra-latihan sebelum ini selalunya tidak didedahkan kepada umum dengan sumber terbuka model (apatah lagi model sumber tertutup).
Dan dokumentasi tentang data ini selalunya tidak mempunyai butiran yang mencukupi, tetapi butiran ini penting untuk mereplikasi penyelidikan atau memahami sepenuhnya kerja berkaitan.
Situasi ini menjadikan penyelidikan model bahasa lebih sukar - contohnya, memahami cara data latihan mempengaruhi keupayaan model dan batasannya.
Untuk mempromosikan penyelidikan terbuka dalam bidang pra-latihan model bahasa, penyelidik membina dan mendedahkan set data pra-latihan Dolma kepada umum.
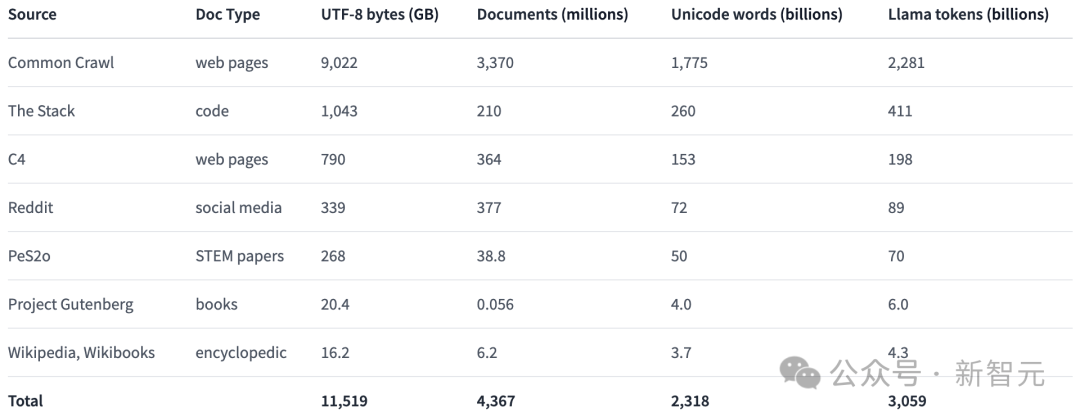
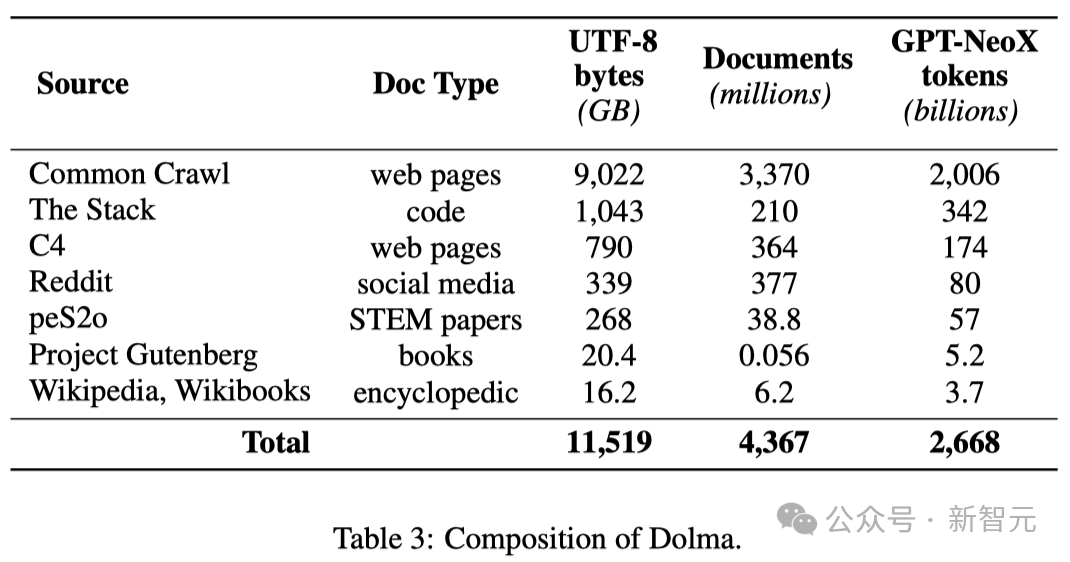
Ini adalah korpus pelbagai sumber yang mengandungi 3 trilion token yang diperoleh daripada 7 sumber data yang berbeza.
Dalam satu pihak, sumber data ini adalah perkara biasa dalam pra-latihan model bahasa berskala besar, dan sebaliknya, ia juga boleh diakses oleh orang awam.
Jadual di bawah memberikan gambaran keseluruhan volum data daripada pelbagai sumber data.
Proses pembinaan Dolma merangkumi enam langkah: penapisan bahasa, penapisan kualiti, penapisan kandungan, penyahduplikasian, pencampuran berbilang sumber dan tokenisasi.
Semasa proses penyusunan dan penerbitan akhir Dolma, penyelidik memastikan bahawa dokumen setiap sumber data kekal bebas.
Mereka juga membuka satu set alat organisasi data yang cekap, yang boleh membantu mengkaji lebih lanjut Dolma, mereplikasi keputusan dan memudahkan organisasi korpus pra-latihan.
Selain itu, penyelidik juga telah membuka sumber alat WIMBD untuk memudahkan analisis set data. Proses pemprosesan data rangkaian Rangka kerja FS DP Torch dan strategi pengoptimuman ZeRO datang Latih model . Pendekatan ini mengurangkan penggunaan memori dengan berkesan dengan membahagikan berat model dan keadaan pengoptimum yang sepadan merentas berbilang GPU.
 Apabila memproses model sehingga saiz 7B, teknologi ini membolehkan penyelidik memproses saiz kumpulan mikro sebanyak 4096 token setiap GPU untuk latihan yang lebih cekap.
Apabila memproses model sehingga saiz 7B, teknologi ini membolehkan penyelidik memproses saiz kumpulan mikro sebanyak 4096 token setiap GPU untuk latihan yang lebih cekap.
Untuk model OLMo-1B dan 7B, penyelidik menetapkan saiz kelompok global kira-kira 4M token (2048 tika data, setiap tika mengandungi jujukan 2048 token).

Untuk mempercepatkan latihan model, penyelidik menggunakan teknologi latihan ketepatan campuran, yang dilaksanakan melalui konfigurasi dalaman FSDP dan modul amp PyTorch.
Kaedah ini direka khas untuk memastikan beberapa langkah pengiraan utama (seperti fungsi softmax) sentiasa dilakukan dengan ketepatan tertinggi untuk memastikan kestabilan proses latihan.
Sementara itu, kebanyakan pengiraan lain menggunakan format separuh ketepatan yang dipanggil bfloat16 untuk mengurangkan penggunaan memori dan meningkatkan kecekapan pengiraan.
Dalam konfigurasi khusus, berat model dan keadaan pengoptimum disimpan dengan ketepatan maksimum pada setiap GPU.
Hanya apabila melakukan perambatan ke hadapan dan perambatan belakang model, iaitu, mengira output model dan mengemas kini pemberat, pemberat dalam setiap modul Transformer akan ditukar buat sementara waktu kepada format bfloat16.
Selain itu, apabila kemas kini kecerunan disegerakkan antara GPU, ia juga akan dilakukan dengan ketepatan tertinggi untuk memastikan kualiti latihan. 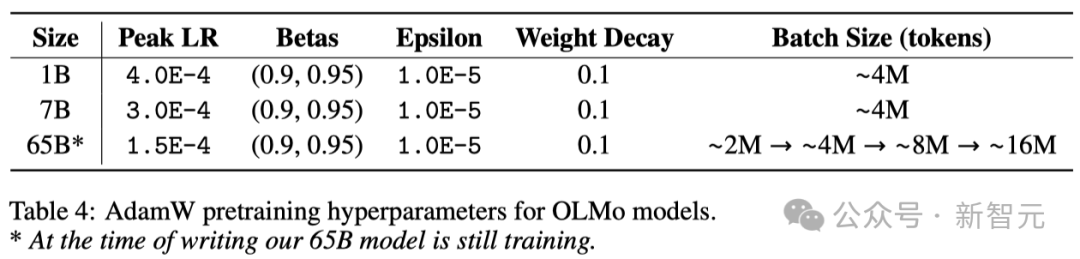
Optimizer
Para penyelidik menggunakan pengoptimum AdamW untuk melaraskan parameter model.
Tidak kira saiz model, penyelidik akan meningkatkan kadar pembelajaran secara beransur-ansur dalam 5000 langkah pertama latihan (kira-kira memproses 21B token Proses ini dipanggil pemanasan kadar pembelajaran).
Selepas memanaskan badan selesai, kadar pembelajaran akan beransur-ansur menurun secara linear sehingga ia turun kepada satu persepuluh daripada kadar pembelajaran maksimum.
Selain itu, penyelidik juga akan memotong kecerunan parameter model untuk memastikan jumlah norma L1 mereka tidak melebihi 1.0.
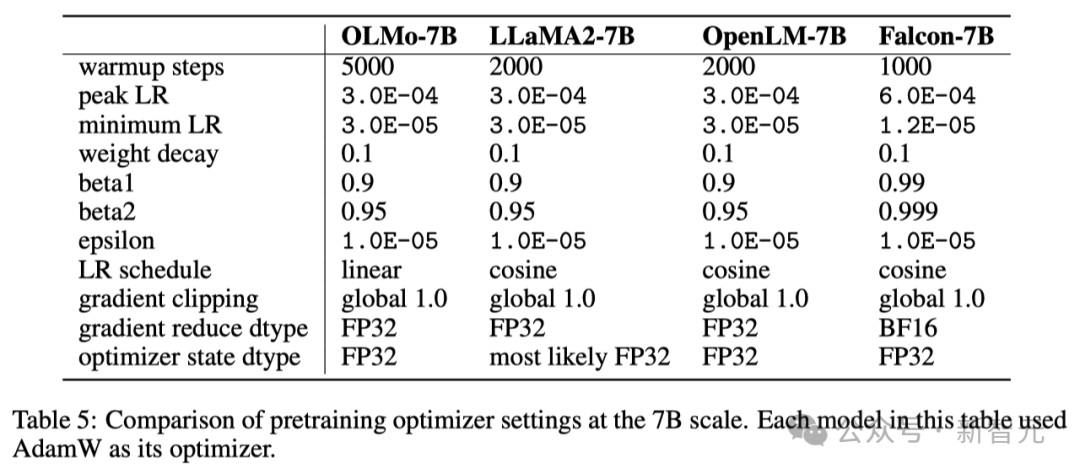
Dalam jadual di bawah, penyelidik membandingkan konfigurasi pengoptimum mereka pada skala model 7B dengan model bahasa besar terkini yang lain menggunakan pengoptimum AdamW.
Dataset
Para penyelidik menggunakan sampel token 2T dalam set data terbuka Dolma untuk membina set data latihan mereka.
Para penyelidik menyambungkan token setiap dokumen, menambahkan token EOS khas pada penghujung setiap dokumen, dan kemudian membahagikan token ini kepada kumpulan 2048 untuk membentuk sampel latihan.
Sampel latihan ini akan dikocok secara rawak dengan cara yang sama semasa setiap latihan. Para penyelidik juga menyediakan alat yang membolehkan sesiapa sahaja memulihkan susunan data dan komposisi khusus setiap kumpulan latihan.
Semua model yang dikeluarkan oleh penyelidik telah dilatih untuk sekurang-kurangnya satu pusingan (token 2T). Beberapa model ini juga dilatih dengan menjalankan pusingan kedua latihan pada data, tetapi dengan susunan shuffling rawak yang berbeza.
Menurut kajian terdahulu, kesan penggunaan semula sejumlah kecil data adalah minimum.
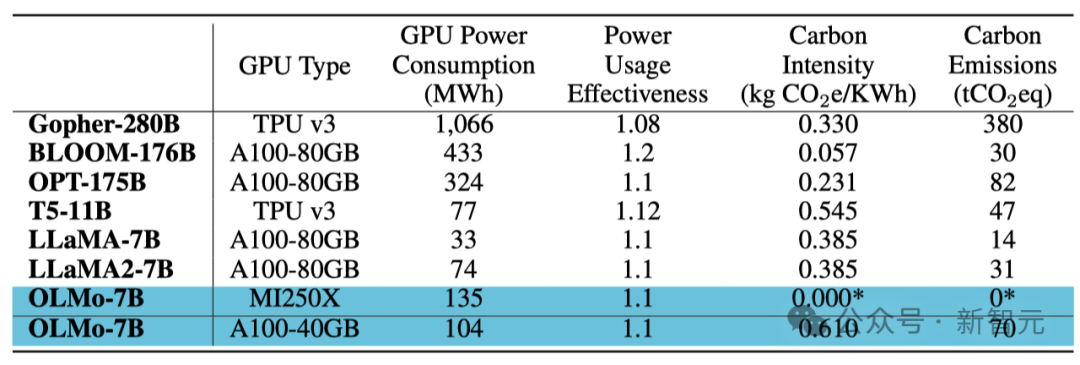
Kedua-dua NVIDIA dan AMD mahukan YA!
Untuk memastikan asas kod boleh berjalan dengan cekap pada kedua-dua GPU NVIDIA dan AMD, penyelidik memilih dua kluster berbeza untuk ujian latihan model:
Menggunakan superkomputer LUMI, para penyelidik menggunakan Sehingga 256 nod, setiap nod dilengkapi dengan 4 GPU AMD MI250X, setiap GPU mempunyai memori 128GB dan kadar pemindahan data 800Gbps.
Dengan sokongan MosaicML (Databricks), penyelidik menggunakan 27 nod, setiap nod dilengkapi dengan 8 NVIDIA A100 GPU, setiap GPU mempunyai memori 40GB dan kadar pemindahan data 800Gbps.
Walaupun penyelidik memperhalusi saiz kelompok untuk meningkatkan kecekapan latihan, selepas menyelesaikan penilaian token 2T, hampir tiada perbezaan dalam prestasi kedua-dua kelompok. . Serta log latihan, keputusan percubaan, penemuan penting, rekod Berat & Pisahkan, dsb.
 Selain itu, pasukan sedang mengkaji cara menambah baik OLMo melalui pengoptimuman arahan dan pelbagai jenis pembelajaran pengukuhan (RLHF). Kod, data dan model yang diperhalusi ini juga akan menjadi sumber terbuka.
Selain itu, pasukan sedang mengkaji cara menambah baik OLMo melalui pengoptimuman arahan dan pelbagai jenis pembelajaran pengukuhan (RLHF). Kod, data dan model yang diperhalusi ini juga akan menjadi sumber terbuka.
Penyelidik komited untuk terus menyokong dan membangunkan OLMo dan rangka kerjanya, menggalakkan pembangunan model bahasa terbuka (LM), dan membantu pembangunan komuniti penyelidikan terbuka. Untuk tujuan ini, penyelidik merancang untuk memperkenalkan lebih banyak model skala yang berbeza, pelbagai modaliti, set data, langkah keselamatan dan kaedah penilaian untuk memperkayakan keluarga OLMo.
Mereka berharap dapat mengukuhkan kuasa komuniti penyelidikan sumber terbuka dan mencetuskan gelombang inovasi baharu melalui kerja sumber terbuka menyeluruh yang berterusan pada masa hadapan.
Pengenalan pasukanYizhong Wang (王义中)
Yizhong Wang ialah pelajar kedoktoran di Paul G. Allen School of Computer Science and Engineering and nehhahred di Universiti Sains Komputer dan Kejuruteraan Komputer Washington, nehhahred Paul G. Allen di Universiti Hanzinahhir Hanzirah. Smith. Pada masa yang sama, beliau juga merupakan pelatih penyelidikan sambilan di Institut Allen untuk Kepintaran Buatan.
Sebelum ini, beliau pernah berkhidmat di Meta AI, Microsoft Research dan Baidu NLP. Sebelum ini, beliau menerima ijazah sarjana dari Universiti Peking dan ijazah sarjana muda dari Universiti Shanghai Jiao Tong.
Arahan penyelidikannya ialah Pemprosesan Bahasa Semulajadi, Pembelajaran Mesin dan Model Bahasa Besar (LLM).
- Kebolehsuaian LLM: Bagaimana untuk membina dan menilai model yang boleh mengikut arahan dengan lebih cekap? Apakah faktor yang perlu kita pertimbangkan semasa memperhalusi model ini, dan bagaimana ia mempengaruhi kebolehgeneralisasian model? Jenis penyeliaan yang manakah berkesan dan boleh berskala?
- Pembelajaran Berterusan untuk LLM: Di manakah garis antara pra-latihan dan penalaan halus? Apakah seni bina dan strategi pembelajaran yang boleh membolehkan LLM terus berkembang selepas pra-latihan? Bagaimanakah pengetahuan sedia ada dalam model berinteraksi dengan pengetahuan yang baru dipelajari?
- Aplikasi data sintetik berskala besar: Hari ini, apabila model generatif menjana data dengan pantas, apakah kesan data ini terhadap pembangunan model kami dan juga seluruh Internet dan masyarakat? Bagaimanakah kami memastikan kami boleh menjana data yang pelbagai dan berkualiti tinggi pada skala? Bolehkah kita membezakan data ini daripada data yang dijana oleh manusia?
Yuling Gu

Yuling Gu ialah penyelidik pasukan Aristo di Allen Institute for Artificial Intelligence (AI2).
Pada tahun 2020, dia menerima ijazah sarjana muda dari Universiti New York (NYU). Selain jurusan sains komputernya, dia juga mengambil jurusan antara disiplin, Bahasa dan Minda, yang menggabungkan linguistik, psikologi dan falsafah. Beliau kemudiannya memperoleh ijazah sarjana dari Universiti Washington (UW).
Dia penuh dengan semangat untuk penyepaduan dan aplikasi teknologi pembelajaran mesin dan teori sains kognitif.
Atas ialah kandungan terperinci Model besar sumber terbuka 100% pertama dalam sejarah ada di sini! Pendedahan pecah rekod kod/berat/set data/keseluruhan proses latihan, AMD boleh melatihnya. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 什么叫数据?
- Bagaimana untuk mencari nombor perdana dalam tatasusunan dalam JavaScript
- Bagaimana untuk menambah dan menyesuaikan label data dalam carta Microsoft Excel?
- Penyelesaian yang menarik ialah mendapatkan semua nombor perdana kurang daripada n?
- Selepas menukar nombor perduaan yang diberi kepada asas antara L dan R, hitung bilangan nombor perdana