
Rumah >Peranti teknologi >AI >Mengalahkan OpenAI, pemberat, data dan kod semuanya adalah sumber terbuka, dan model pembenaman Nomic Embed yang boleh dihasilkan semula dengan sempurna ada di sini.
Mengalahkan OpenAI, pemberat, data dan kod semuanya adalah sumber terbuka, dan model pembenaman Nomic Embed yang boleh dihasilkan semula dengan sempurna ada di sini.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-02-04 09:54:151222semak imbas
Seminggu yang lalu, OpenAI memberikan manfaat kepada pengguna. Mereka menyelesaikan masalah GPT-4 menjadi malas dan memperkenalkan 5 model baharu, termasuk model pembenaman teks-3-kecil, yang lebih kecil dan cekap.
Pembenaman ialah jujukan nombor yang digunakan untuk mewakili konsep dalam bahasa semula jadi, kod dan banyak lagi. Mereka membantu model pembelajaran mesin dan algoritma lain lebih memahami cara kandungan berkaitan dan memudahkan untuk melaksanakan tugas seperti pengelompokan atau pengambilan semula. Dalam bidang NLP, embedding memainkan peranan yang sangat penting.
Walau bagaimanapun, model pembenaman OpenAI bukan percuma untuk digunakan oleh semua orang Contohnya, text-embedding-3-small caj $0.00002 setiap 1k token.
Kini, model pembenaman yang lebih baik daripada pembenaman teks-3-kecil ada di sini dan ia percuma.
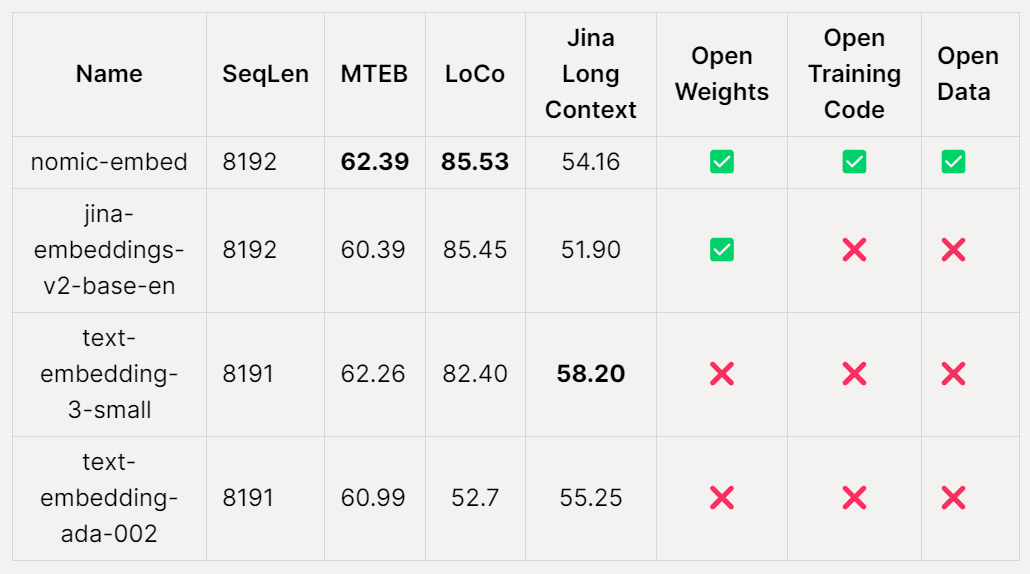
Nomic AI, pemula AI, baru-baru ini mengeluarkan model pembenaman pertama yang sumber terbuka, data terbuka, pemberat terbuka dan kod latihan terbuka - Nomic Embed. Model ini boleh dihasilkan semula sepenuhnya dan boleh diaudit, dengan panjang konteks 8192. Nomic Embed mengalahkan model text-embeding-3-small dan text-embedding-ada-002 OpenAI dalam kedua-dua penanda aras konteks pendek dan panjang. Pencapaian ini menandakan kemajuan penting Nomic AI dalam bidang model terbenam.

Pembenaman teks ialah komponen utama dalam aplikasi NLP moden, menyediakan keupayaan Retrieval Augmented Generation (RAG) untuk menggerakkan LLM dan carian semantik. Teknologi ini membolehkan pemprosesan yang lebih cekap dengan mengekodkan maklumat semantik ayat atau dokumen ke dalam vektor berdimensi rendah dan menerapkannya pada aplikasi hiliran seperti pengelompokan untuk visualisasi data, pengelasan dan perolehan maklumat. Pada masa ini, text-embedding-ada-002 OpenAI ialah salah satu model pembenaman teks konteks panjang yang paling popular, menyokong sehingga 8192 panjang konteks. Malangnya, bagaimanapun, Ada adalah sumber tertutup dan data latihannya tidak boleh diaudit, yang mengehadkan kredibilitinya. Walaupun begitu, model ini masih digunakan secara meluas dan berfungsi dengan baik dalam banyak tugas NLP. Pada masa hadapan, kami berharap untuk membangunkan model pembenaman teks yang lebih telus dan boleh diaudit untuk meningkatkan kredibiliti dan kebolehpercayaan mereka. Ini akan membantu menggalakkan pembangunan bidang NLP dan menyediakan keupayaan pemprosesan teks yang lebih cekap dan tepat untuk pelbagai aplikasi.
Model pembenaman teks konteks panjang sumber terbuka berprestasi terbaik, seperti E5-Mistral dan jina-embeddings-v2-base-en, mungkin mempunyai beberapa pengehadan. Di satu pihak, disebabkan saiz model yang besar, ia mungkin tidak sesuai untuk kegunaan umum. Sebaliknya, model ini mungkin tidak dapat melepasi tahap prestasi rakan sejawat OpenAI mereka. Oleh itu, faktor-faktor ini perlu dipertimbangkan semasa memilih model yang sesuai untuk tugas tertentu. Keluaran
Nomic-embed mengubahnya. Model ini hanya mempunyai 137M parameter, yang sangat mudah untuk digunakan dan boleh dilatih dalam 5 hari. .
 Projek Alamat: https://github.com/nomic-ai/contrastors
Projek Alamat: https://github.com/nomic-ai/contrastors
Cara membina nomic-embed
Salah satu kelemahan utama pengekod teks sedia ada ialah ia terhad kepada jujukan yang terhad kepada 512 token. Untuk melatih model untuk jujukan yang lebih panjang, perkara pertama yang perlu dilakukan ialah melaraskan BERT supaya dapat menampung panjang jujukan yang panjang, panjang jujukan sasaran untuk kajian ini ialah 8192.
Melatih BERT dengan panjang konteks 2048
Kajian ini mengikuti saluran pembelajaran kontrastif berbilang peringkat untuk melatih benam nomik. Pertama, kajian ini melakukan pemulaan BERT Memandangkan bert-base hanya boleh mengendalikan panjang konteks sehingga 512 token, kajian itu memutuskan untuk melatih BERTnya sendiri dengan panjang konteks 2048 token - nomic-bert-2048.
Diinspirasikan oleh MosaicBERT, pasukan penyelidik membuat beberapa pengubahsuaian pada proses latihan BERT, termasuk:
- Gunakan benam kedudukan diputar untuk membenarkan ekstrapolasi panjang konteks;
- Gunakan pengaktifan SwiGLU kerana ia telah ditunjukkan untuk meningkatkan prestasi model
- Tetapkan keciciran kepada 0. . kepada gandaan 64 ; Saiz kumpulan untuk latihan ialah 4096;
Semasa latihan, kajian ini melatih semua peringkat dengan panjang jujukan maksimum 2048, dan menggunakan interpolasi NTK dinamik untuk melanjutkan kepada panjang jujukan 8192 semasa inferens.
- Eksperimen
- Kajian ini menilai kualiti nomic-bert-2048 pada penanda aras GLUE standard dan mendapati prestasinya setanding dengan model BERT lain, tetapi dengan kelebihan panjang konteks yang jauh lebih panjang.
- Latihan perbandingan nomic-embed
- Kajian ini menggunakan nomic-bert-2048 untuk memulakan latihan nomic-embed. Dataset perbandingan terdiri daripada kira-kira 235 juta pasangan teks, dan kualitinya telah disahkan secara meluas menggunakan Nomic Atlas semasa pengumpulan.
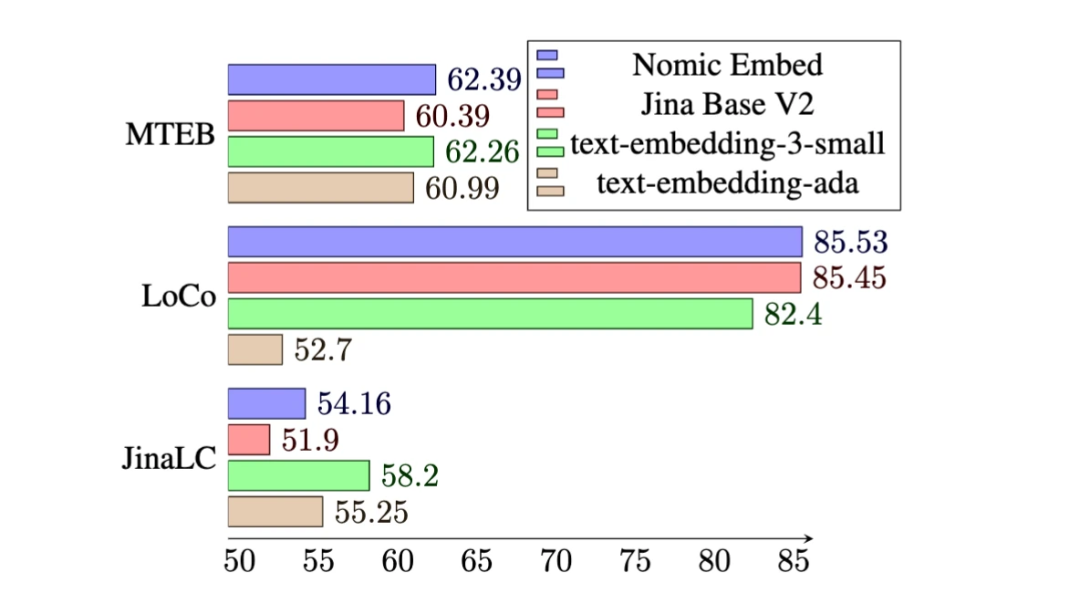
- Pada penanda aras MTEB, nomic-embedding mengatasi text-embeddings-ada-002 dan jina-embeddings-v2-base-en.
Walau bagaimanapun, MTEB tidak boleh menilai tugas konteks yang panjang. Oleh itu, kajian ini menilai benam nomik pada penanda aras LoCo yang dikeluarkan baru-baru ini serta penanda aras Jina Long Context.
Untuk penanda aras LoCo, kajian dinilai secara berasingan mengikut kategori parameter dan sama ada penilaian dilakukan dalam persekitaran yang diselia atau tidak diselia.
Seperti yang ditunjukkan dalam jadual di bawah, Nomic Embed ialah model tanpa pengawasan parameter 100M yang berprestasi terbaik. Terutamanya, Nomic Embed adalah setanding dengan model berprestasi terbaik dalam kategori parameter 7B serta model yang dilatih dalam persekitaran yang diselia khusus untuk penanda aras LoCo: 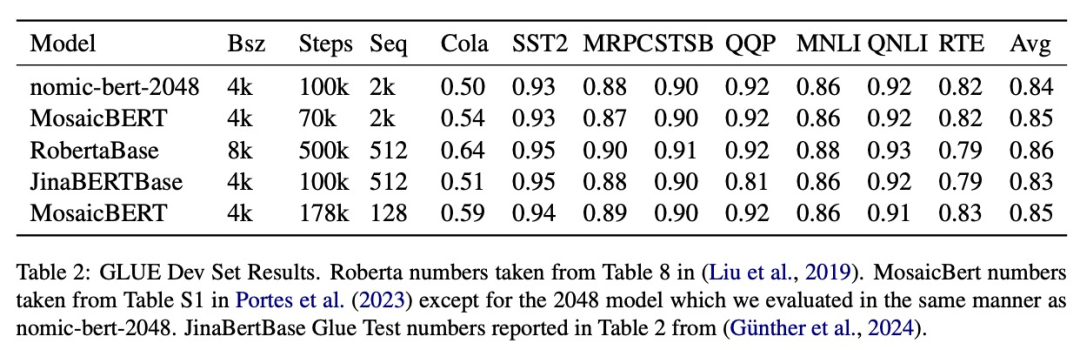
Keseluruhan prestasi Nomic Embed pada penanda aras Konteks Jangka Panjang Jina lebih baik daripada jina-embeddings-v2-base-en, tetapi Nomic Embed tidak berprestasi lebih baik daripada OpenAI ada-002 atau text-embedding-3-small pada penanda aras ini:
Secara keseluruhan Dalam erti kata lain, Nomic Embed mengatasi prestasi OpenAI Ada-002 dan text-embedding-3-small pada penanda aras 2/3.
 Kajian mengatakan bahawa pilihan terbaik untuk menggunakan Nomic Embed ialah Nomic Embedding API, dan cara untuk mendapatkan API adalah seperti berikut:
Kajian mengatakan bahawa pilihan terbaik untuk menggunakan Nomic Embed ialah Nomic Embedding API, dan cara untuk mendapatkan API adalah seperti berikut:
Fina akses data:
Untuk mengakses data lengkap , kajian itu menyediakan kunci akses Cloudflare R2 (perkhidmatan storan objek yang serupa dengan AWS S3) kepada pengguna. Untuk mendapatkan akses, pengguna perlu membuat akaun Nomic Atlas dahulu dan mengikut arahan dalam repositori kontrastor.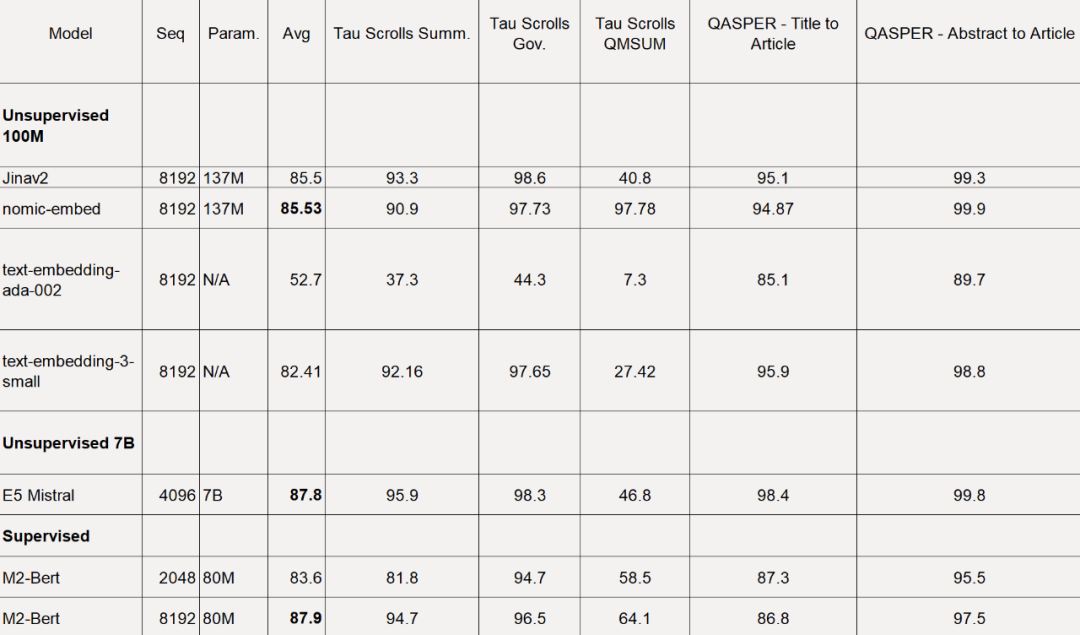
alamat kontrastor: https://github.com/nomic-ai/contrastors?tab=readme-ov-file#data-access
Atas ialah kandungan terperinci Mengalahkan OpenAI, pemberat, data dan kod semuanya adalah sumber terbuka, dan model pembenaman Nomic Embed yang boleh dihasilkan semula dengan sempurna ada di sini.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!