
Rumah >Peranti teknologi >AI >Kertas tanpa nama menghasilkan idea yang mengejutkan! Ini sebenarnya boleh dilakukan untuk meningkatkan keupayaan teks panjang model besar
Kertas tanpa nama menghasilkan idea yang mengejutkan! Ini sebenarnya boleh dilakukan untuk meningkatkan keupayaan teks panjang model besar

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-02-02 18:21:15651semak imbas
Dalam mempertingkatkan keupayaan teks panjang bagi model besar, adakah anda memikirkan ekstrapolasi panjang atau pengembangan tetingkap konteks?
Tidak, ini menggunakan terlalu banyak sumber perkakasan.
Mari kita lihat penyelesaian baharu yang hebat:
pada asasnya berbeza daripada cache KV yang digunakan oleh kaedah seperti ekstrapolasi panjang Ia menggunakan parameter model untuk menyimpan sejumlah besar maklumat konteks. .
Kaedah khusus adalah untuk membina modul Lora sementara, supaya hanya akan "strim kemas kini" semasa proses penjanaan teks panjang, iaitu, ia akan terus menggunakan kandungan yang dijana sebelum ini sebagai input untuk berfungsi sebagai data latihan, dengan itu memastikan Pengetahuan disimpan dalam parameter model.
Kemudian setelah inferens selesai, buang untuk memastikan tiada kesan jangka panjang pada parameter model.
Kaedah ini membolehkan kami menyimpan maklumat konteks seberapa banyak yang kami mahu tanpa mengembangkan tetingkap konteks Simpan seberapa banyak yang anda mahu.
Percubaan telah membuktikan bahawa kaedah ini:
- boleh meningkatkan kualiti tugasan teks panjang model dengan ketara, mencapai pengurangan 29.6% dalam kebingungan dan peningkatan 53.2% dalam kualiti terjemahan teks panjang (skor BIRU) ;
- juga boleh Serasi dengan dan meningkatkan kebanyakan kaedah penjanaan teks panjang sedia ada.
- Perkara yang paling penting ialah ia dapat mengurangkan kos pengkomputeran.
Sambil memastikan sedikit peningkatan dalam kualiti penjanaan (kebingungan dikurangkan sebanyak 3.8%), FLOP yang diperlukan untuk inferens dikurangkan sebanyak 70.5% dan kelewatan dikurangkan sebanyak 51.5%!
Untuk situasi khusus, mari buka kertas dan lihat.
Buat modul Lora sementara dan buang selepas digunakan
Kaedahnya dipanggil Temp-Lora Gambar rajah seni bina adalah seperti berikut:
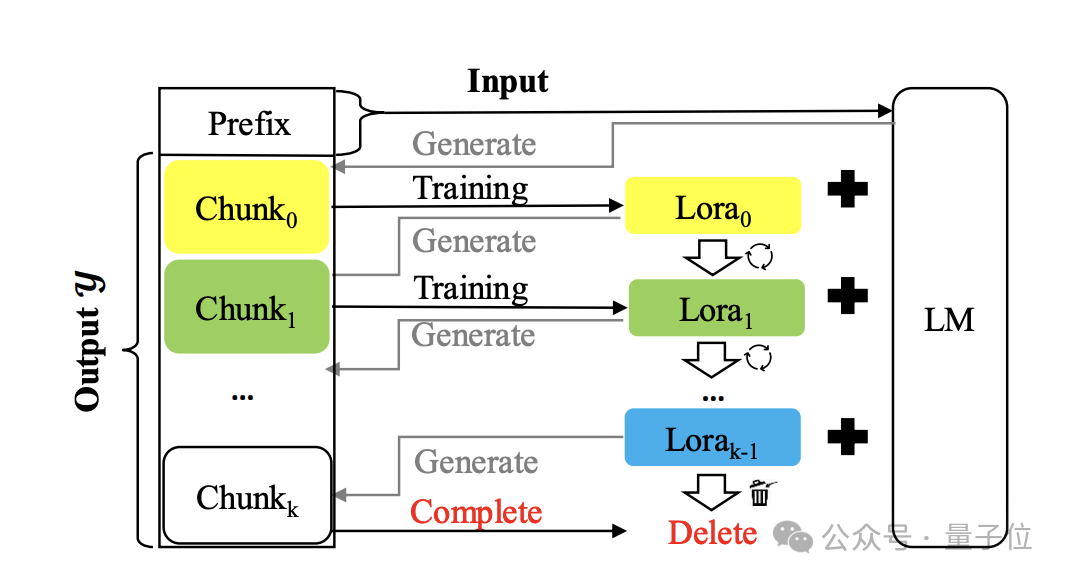
Intinya adalah untuk menggunakan teks yang dihasilkan secara beransur-ansur. berlatih dengan cara autoregresif Modul Lora Sementara.
Modul ini sangat mudah disesuaikan dan boleh dilaraskan secara berterusan, jadi ia boleh mempunyai pemahaman mendalam tentang konteks jarak yang berbeza.
Algoritma khusus adalah seperti berikut:
Semasa proses penjanaan, token dijana blok demi blok. Setiap kali blok dijana, token Lx terbaharu digunakan sebagai input X untuk menjana token seterusnya.
Setelah bilangan token yang dijana mencapai saiz blok yang dipratentukan Δ, mulakan latihan modul Temp-Lora menggunakan blok terkini, dan kemudian mulakan generasi blok seterusnya.

Dalam percubaan, pengarang menetapkan Δ+Lx kepada W untuk menggunakan sepenuhnya saiz tetingkap konteks model.
Untuk latihan modul Temp-Lora, pembelajaran untuk menjana blok baharu tanpa sebarang syarat mungkin tidak membentuk sasaran latihan yang berkesan dan membawa kepada overfitting yang serius.
Untuk menyelesaikan masalah ini, penulis memasukkan tag LT di hadapan setiap blok ke dalam proses latihan, menggunakannya sebagai input dan blok sebagai output.
Akhir sekali, penulis juga mencadangkan strategi yang dipanggil Cache Reuse (Cache Reuse) untuk mencapai inferens yang lebih cekap.
Secara umumnya, selepas mengemas kini modul Temp-Loramo dalam rangka kerja standard, kita perlu mengira semula keadaan KV dengan parameter yang dikemas kini.
Sebagai alternatif, gunakan semula keadaan KV tembolok sedia ada semasa menggunakan model yang dikemas kini untuk penjanaan teks seterusnya.
Secara khusus, kami menggunakan modul Temp-Lora terkini untuk mengira semula keadaan KV hanya apabila model menjana panjang maksimum (saiz tetingkap konteks W).
Kaedah penggunaan semula cache sebegini boleh mempercepatkan penjanaan tanpa menjejaskan kualiti penjanaan dengan ketara.
Itu sahaja pengenalan kepada kaedah Temp-Lora Mari kita lihat ujian di bawah.
Semakin panjang teks, semakin baik kesannya
Pengarang menilai rangka kerja Temp-Lora pada model Llama2-7B-4K, Llama2-13B-4K, Llama2-7B-32K dan Yi-Chat-6B dan merangkumi kedua-dua model ini jenis tugasan teks panjang ialah penjanaan dan terjemahan.
Set data ujian ialah subset penanda aras pemodelan bahasa teks panjang PG19, yang mana 40 buku dipilih secara rawak.
Yang lain ialah subset sampel rawak set data Guofeng daripada WMT 2023, yang mengandungi 20 novel dalam talian Cina yang diterjemahkan ke dalam bahasa Inggeris oleh profesional.
Mula-mula mari kita lihat keputusan pada PG19.
Jadual di bawah menunjukkan PPL (kebingungan, mencerminkan ketidakpastian model untuk input yang diberikan, lebih rendah lebih baik) perbandingan pelbagai model pada PG19 dengan dan tanpa modul Temp-Lora. Bahagikan setiap dokumen kepada segmen daripada 0-100K hingga 500K+token.
Adalah dapat dilihat bahawa PPL semua model menurun dengan ketara selepas Temp-Lora, dan apabila klip menjadi lebih panjang dan lebih panjang, kesan Temp-Lora lebih jelas (1-100K hanya menurun sebanyak 3.6%, 500K+ menurun sebanyak 13.2%) .
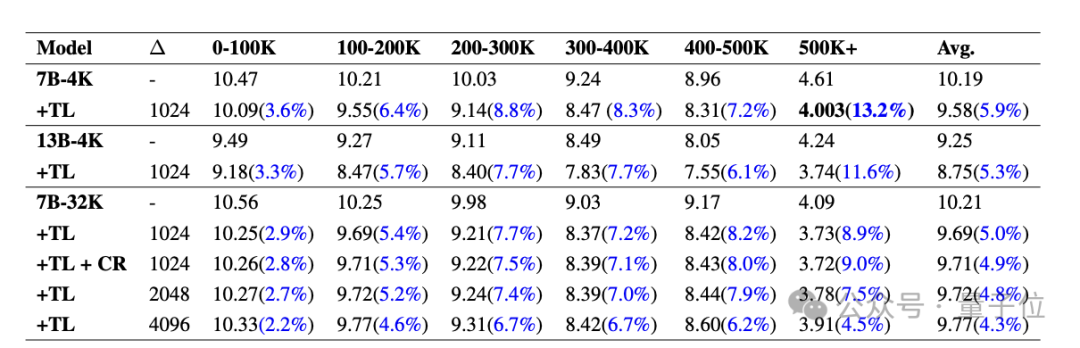
Oleh itu, kita boleh membuat kesimpulan ringkas: Semakin banyak teks, semakin kuat keperluan untuk menggunakan Temp-Lora.
Selain itu, kita dapati bahawa melaraskan saiz blok dari 1024 kepada 2048 dan 4096 menghasilkan sedikit peningkatan dalam PPL.
Ini tidak menghairankan, lagipun, modul Temp-Lora dilatih pada data blok sebelumnya.
Data ini terutamanya memberitahu kita bahawa pilihan saiz blok ialah pertukaran utama antara kualiti penjanaan dan kecekapan pengiraan (analisis lanjut boleh didapati dalam kertas) .
Akhir sekali, kami juga dapati bahawa penggunaan semula cache tidak akan menyebabkan kehilangan prestasi. Penulis berkata: Ini berita yang sangat menggalakkan.Berikut ialah keputusan pada dataset Guofeng.
Adalah dapat dilihat bahawa Temp-Lora juga mempunyai kesan yang signifikan terhadap tugas terjemahan sastera teks panjang. Peningkatan ketara dalam semua metrik berbanding model asas: -29.6% pengurangan dalam PPL, +53.2% peningkatan dalam skor BLEU(persamaan teks terjemahan mesin dengan terjemahan rujukan berkualiti tinggi), +53.2% peningkatan dalam skor COMET ( Juga penunjuk kualiti) meningkat sebanyak +8.4%.
 Akhir sekali, terdapat penerokaan kecekapan dan kualiti pengiraan.
Akhir sekali, terdapat penerokaan kecekapan dan kualiti pengiraan.
Pengarang mendapati melalui eksperimen bahawa menggunakan konfigurasi
paling "ekonomi" Temp-Lora (Δ=2K, W=4K) boleh mengurangkan PPL sebanyak 3.8% sambil menjimatkan 70.5% daripada FLOP dan 51.5% kelewatan Sebaliknya, jika kita mengabaikan sepenuhnya kos pengiraan dan menggunakan konfigurasi
yang paling "mewah" (Δ=1K dan W=24K), kita juga boleh mencapai pengurangan PPL sebanyak 5.0% dan tambahan 17 % peningkatan FLOP dan kependaman 19.6%. Cadangan Penggunaan
Untuk meringkaskan keputusan di atas, penulis juga memberikan tiga cadangan untuk aplikasi praktikal Temp-Lora:
1 Untuk aplikasi yang memerlukan penjanaan teks panjang tahap tertinggi, integrasikan Temp tanpa mengubah sebarang parameter. -Lora boleh ditambah kepada model sedia ada untuk meningkatkan prestasi dengan ketara pada kos yang agak sederhana.
2 Untuk aplikasi yang menghargai kependaman minimum atau penggunaan memori, kos pengiraan boleh dikurangkan dengan ketara dengan mengurangkan panjang input dan maklumat kontekstual yang disimpan dalam Temp-Lora.
Dalam tetapan ini, kita boleh menggunakan saiz tetingkap pendek tetap
(seperti 2K atau 4K)untuk mengendalikan teks panjang yang hampir tak terhingga (500K+ dalam eksperimen pengarang) . 3 Akhir sekali, sila ambil perhatian bahawa dalam senario yang tidak mengandungi sejumlah besar teks, seperti apabila konteks dalam pra-latihan lebih kecil daripada saiz tetingkap model, Temp-Lora tidak berguna.
Penulis adalah daripada organisasi sulit
Perlu disebut bahawa untuk mencipta kaedah yang mudah dan inovatif, penulis tidak meninggalkan banyak maklumat sumber:
Nama organisasi ditandatangani terus sebagai "Organisasi Setiausaha", dan nama ketiga-tiga penulis hanyalah nama keluarga Lengkap.
 Tetapi jika dilihat dari maklumat e-mel, ia mungkin dari sekolah seperti City University of Hong Kong dan Hong Kong Chinese Language School.
Tetapi jika dilihat dari maklumat e-mel, ia mungkin dari sekolah seperti City University of Hong Kong dan Hong Kong Chinese Language School.
Akhir sekali, apa pendapat anda tentang kaedah ini?
Kertas:Atas ialah kandungan terperinci Kertas tanpa nama menghasilkan idea yang mengejutkan! Ini sebenarnya boleh dilakukan untuk meningkatkan keupayaan teks panjang model besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 常用的数据模型有哪些
- 数据库的数据模型可分为哪三种
- 四种常见的软件开发模型是什么
- Satu lagi revolusi dalam pembelajaran pengukuhan! DeepMind mencadangkan 'penyulingan algoritma': Transformer pembelajaran tetulang pra-latihan yang boleh diterokai
- Yunshenchen dan Shengteng CANN bekerjasama untuk membuka kem latihan pembangunan anjing robot berkaki empat ROS