
Rumah >Peranti teknologi >AI >NextEvo Kumpulan Ant membuka sepenuhnya teknologi AI Infra untuk membolehkan 'pemandu autonomi' dalam latihan model besar
NextEvo Kumpulan Ant membuka sepenuhnya teknologi AI Infra untuk membolehkan 'pemandu autonomi' dalam latihan model besar

- 王林ke hadapan
- 2024-02-02 08:39:021215semak imbas
Baru-baru ini, NextEvo, jabatan R&D inovasi AI bagi Ant Group, mengumumkan teknologi AI Infra sumber terbuka yang komprehensif, yang boleh meningkatkan kecekapan latihan model berskala besar. Menurut data, teknologi ini boleh meningkatkan perkadaran berkesan masa latihan kepada lebih daripada 95% dan merealisasikan automasi proses latihan. Kemajuan kejayaan ini telah menggalakkan kecekapan penyelidikan dan pembangunan AI dengan ketara.
Gambar: Sistem pembelajaran mendalam teragih automatik Kumpulan Ant DLRover kini sumber terbuka sepenuhnya
DLRover ialah rangka kerja teknikal yang direka untuk latihan teragih berskala besar. Dalam kebanyakan perusahaan hari ini, pekerjaan latihan sering dijalankan dalam kelompok penggunaan hibrid yang kompleks dan pelbagai. Tidak kira betapa kompleksnya persekitaran, DLRover boleh mengendalikannya dengan mudah, sama seperti memandu di kawasan yang sukar.
Perkembangan pesat teknologi model besar pada tahun 2023 telah menimbulkan pertumbuhan pesat dalam amalan kejuruteraan. Cara mengurus data dengan cekap, mengoptimumkan latihan dan kecekapan inferens, dan menggunakan sepenuhnya kuasa pengkomputeran sedia ada telah menjadi isu utama.
Untuk melengkapkan model besar dengan tahap parameter 100 bilion, seperti GPT-3, ia akan mengambil masa 32 tahun untuk berlatih sekali dengan satu kad. Oleh itu, adalah sangat penting untuk menggunakan sepenuhnya kuasa pengkomputeran semasa proses latihan. Untuk mencapai matlamat ini, terdapat dua pendekatan yang boleh diambil. Pertama, prestasi GPU yang dibeli boleh dipertingkatkan lagi untuk mencapai potensi penuhnya. Kedua, sumber pengkomputeran yang tidak tersedia sebelum ini seperti CPU dan memori boleh digunakan. Untuk mencapai matlamat ini, masalah ini boleh diselesaikan melalui platform pengkomputeran heterogen.
DLRover baru-baru ini telah menyepadukan penyelesaian Flash Checkpoint (FCP) untuk pengurusan checkpoint semasa latihan model. Kaedah pengurusan pusat pemeriksaan tradisional mempunyai masalah seperti penggunaan masa yang lama, pusat pemeriksaan frekuensi tinggi mengurangkan masa latihan yang ada, dan kerugian yang berlebihan semasa pemulihan pusat pemeriksaan frekuensi rendah. Dengan menggunakan penyelesaian baharu FCP, selepas melatih model parameter 100 bilion, masa latihan terbuang yang disebabkan oleh Checkpoint dikurangkan sebanyak kira-kira 5 kali, dan masa kegigihan dikurangkan sebanyak kira-kira 70 kali. Penambahbaikan ini meningkatkan masa latihan berkesan daripada 90% kepada 95%. Ini bermakna kecekapan latihan model DLRover telah dipertingkatkan dengan ketara.
Kami juga telah menyepadukan tiga teknologi pengoptimum baharu. Pengoptimum ialah komponen teras pembelajaran mesin dan digunakan untuk mengemas kini parameter rangkaian saraf untuk meminimumkan fungsi kehilangan. Antaranya, pengoptimum Ant's AGD (Auto-switchable optimizer with Gradient Difference of adjacent steps) adalah 1.5 kali lebih pantas daripada teknologi AdamW tradisional dalam tugasan pra-latihan model besar. AGD telah digunakan dalam pelbagai senario dalam semut dan mencapai hasil yang luar biasa, dan kertas berkaitan telah dimasukkan dalam NeurIPS '23.
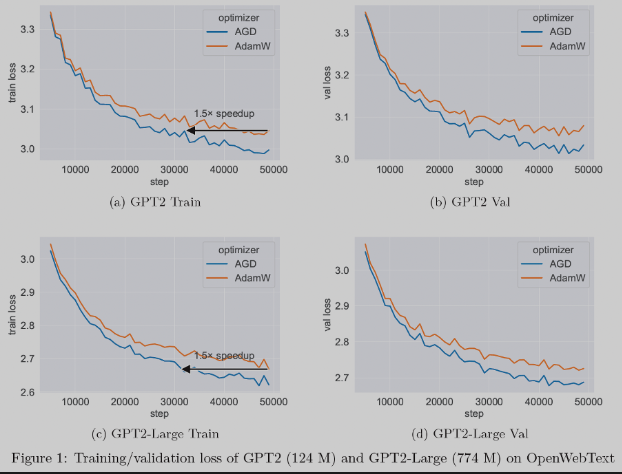
Gambar: Dalam tugasan pra-latihan model besar, AGD boleh memecut 1.5 kali ganda berbanding AdamW
Sebagai sistem pembelajaran mendalam teragih automatik, DLRover "autonomous driving" modul fungsi Atorch, juga termasuk modul fungsi Atorch autonomi. perpustakaan sambungan latihan teragih boleh mencapai kadar penggunaan kuasa pengkomputeran sebanyak 60% dalam latihan pada tahap kilokalori ratusan bilion model parameter, membantu pembangun memerah lagi kuasa pengkomputeran perkakasan.
DLRover menggunakan konsep "ML untuk Sistem" untuk meningkatkan kecerdasan latihan teragih Ia bertujuan untuk menggunakan sistem untuk membolehkan pembangun menyingkirkan sepenuhnya kekangan peruntukan sumber dan memberi tumpuan kepada latihan model itu sendiri. Tanpa sebarang input konfigurasi sumber, DLRover masih boleh menyediakan konfigurasi sumber yang optimum untuk setiap kerja latihan.
Difahamkan bahawa Ant Group terus melabur dalam teknologi dalam bidang kecerdasan buatan Baru-baru ini, Ant Group menubuhkan jabatan penyelidikan dan pembangunan inovasi AI dalaman NextEvo, yang bertanggungjawab untuk semua penyelidikan dan pembangunan teknologi teras Ant AI, termasuk. semua kerja penyelidikan dan pembangunan model besar Bailing, yang melibatkan teknologi Teras seperti algoritma AI, kejuruteraan AI, NLP, dan AIGC, serta penyelidikan dan pembangunan teknologi serta inovasi produk dalam bidang seperti susun atur model besar berbilang modal dan digital manusia.
Pada masa yang sama, Kumpulan Ant juga telah mempercepatkan kadar sumber terbuka, mengisi jurang teknologi domestik yang berkaitan, dan menggalakkan perkembangan pesat industri kecerdasan buatan.
DLR atas alamat sumber terbuka: https://www.php.cn/link/cf372cbe6eae54c6a6dfb3ebbcdc3404
Atas ialah kandungan terperinci NextEvo Kumpulan Ant membuka sepenuhnya teknologi AI Infra untuk membolehkan 'pemandu autonomi' dalam latihan model besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Universiti Wisconsin-Madison dan lain-lain bersama-sama mengeluarkan artikel! Model besar berbilang modal terkini LLaVA dikeluarkan, dan tahapnya hampir dengan GPT-4
- Penemuan tiga model Python utama dan sepuluh contoh algoritma yang biasa digunakan
- Mari kita bina Guangxi digital bersama-sama dan pergi ke masa depan digital bersama-sama! Persidangan Ekologi Industri Kepintaran Buatan Guangxi Kunpeng Shengteng 2023 telah berjaya diadakan
- Piawaian membentuk kehidupan yang lebih baik, Persidangan Promosi Piawaian Industri Robot Suzhou dan Alat Mesin CNC telah diadakan
- Robin Li: Sistem pengiklanan Wenxin Big Model yang dibina semula akan membawa ratusan juta yuan dalam pendapatan tambahan kepada Baidu pada suku keempat