

 Peranti teknologiAIUniversiti Wisconsin-Madison dan lain-lain bersama-sama mengeluarkan artikel! Model besar berbilang modal terkini LLaVA dikeluarkan, dan tahapnya hampir dengan GPT-4
Peranti teknologiAIUniversiti Wisconsin-Madison dan lain-lain bersama-sama mengeluarkan artikel! Model besar berbilang modal terkini LLaVA dikeluarkan, dan tahapnya hampir dengan GPT-4
Penalaan halus perintah visual adalah popular.
Kertas kerja ini dipanggil Penalaan Arahan Visual dan dihasilkan bersama oleh Universiti Wisconsin-Madison, Penyelidikan Microsoft dan Universiti Columbia.
Pengarang termasuk Haotian Liu, Chunyuan Li, Qingyang Wu dan Yong Jae Lee.

Pada masa yang sama, penyelidik juga membuka sumber kod, model dan set data mereka pada GitHub. Kertas itu juga disiarkan di Arxiv.
Penjelasan
Jadi apakah sebenarnya fungsi LLaVA? Jika anda menyelami kertas itu, mungkin agak pelik bagi mereka yang tidak biasa dengannya.
Mari kita lihat apa yang dikatakan oleh LLaVA sendiri dahulu.
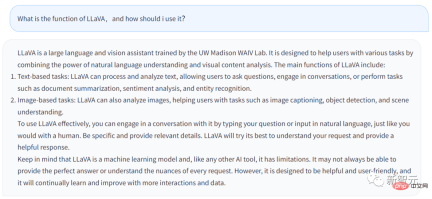
Jawapan di atas dijana daripada Chatbot LLaVA Soalan yang saya masukkan ialah, apakah fungsi LLaVA dan apakah patutkah pengguna memanfaatkannya?
Jawapannya adalah seperti berikut:
LLaVA ialah pembantu bahasa dan visual yang terlatih di makmal WAIV UW Madison. LLaVA direka untuk membantu pengguna mengendalikan pelbagai tugas dengan memanfaatkan keupayaan pemahaman bahasa semula jadi dan keupayaan analisis kandungan visualnya.
Ciri utama LLaVA termasuk:
· Tugas berasaskan teks: LLaVA boleh memproses dan menganalisis teks , membenarkan pengguna untuk bertanya soalan, LLaVA boleh bersembang dengan pengguna, atau menyelesaikan tugasan yang dimasukkan oleh pengguna, seperti menapis ringkasan dokumen, analisis sentimen, pengecaman entiti, dsb.
· Tugas berasaskan imej: LLaVA boleh menganalisis imej, menerangkan imej, melakukan pengecaman objek dan menganalisis serta memahami pemandangan.
Jika pengguna ingin menggunakan LLaVA dengan lebih baik, mereka boleh bercakap terus dengan LLaVA, sama seperti bercakap dengan manusia. Berikan butiran sebanyak mungkin dan LLaVA akan menjana jawapan yang lebih lengkap.
Pada masa yang sama, anda harus ingat bahawa selepas semua, LLaVA ialah model pembelajaran mesin dan alat AI. Selagi ia adalah alat, ia mempunyai batasannya. LLaVA mungkin tidak menjawab dengan sempurna soalan yang dimasukkan oleh pengguna setiap kali.
Sudah tentu, LLaVA sentiasa belajar dan bertambah baik, dan fungsinya akan menjadi lebih dan lebih berkuasa.
Secara umumnya, dapat dilihat daripada jawapan LLaVA bahawa fungsi Chatbot tidak jauh berbeza dengan GPT. Tetapi LLaVA boleh mengendalikan beberapa tugas yang berkaitan dengan imej.
Pameran Warna
Para penyelidik memperincikan butiran teknikal LLaVA dalam kertas Arxiv.
Adalah penting untuk mengetahui bahawa menggunakan arahan yang dijana mesin untuk mengikuti data untuk memperhalusi arahan untuk model bahasa besar (LLM) meningkatkan keupayaan titik sifar tugas baharu, tetapi ini idea tidak diterokai dalam bidang multi-modal kurang.
Dalam kertas kerja, penyelidik mula-mula cuba menggunakan GPT-4 bahasa sahaja untuk menjana data mengikut arahan untuk imej bahasa berbilang mod.
Dengan menundukkan data yang dijana ini kepada pelarasan pengajaran, para penyelidik memperkenalkan LLaVA: bahasa berskala besar dan pembantu penglihatan yang merupakan stateful berskala besar terlatih hujung-ke-hujung model, yang menghubungkan pengekod visual dan LLM untuk penglihatan umum dan pemahaman bahasa.
Eksperimen awal menunjukkan bahawa LLaVA menunjukkan keupayaan sembang berbilang mod yang mengagumkan, kadangkala mengeluarkan prestasi GPT-4 berbilang mod pada imej/arahan ghaib, dan pada banyak sintetik Berbanding dengan GPT-4 pada arahan modal berikut set data , ia mencapai skor relatif 85.1%.
Apabila diperhalusi untuk majalah Sains, sinergi LLaVA dan GPT-4 mencapai ketepatan terkini 92.53%.
Penyelidik telah mendedahkan data, model dan asas kod untuk pelarasan arahan visual yang dijana oleh GPT-4.
Model berbilang mod
Pertama-tama jelaskan definisi.
Model multimodal berskala besar merujuk kepada model berdasarkan teknologi pembelajaran mesin yang boleh memproses dan menganalisis berbilang jenis input, seperti teks dan imej.
Model ini direka bentuk untuk mengendalikan pelbagai tugasan yang lebih luas dan dapat memahami pelbagai bentuk data. Dengan mengambil teks dan imej sebagai input, model ini meningkatkan keupayaan mereka untuk memahami dan menyusun penjelasan untuk menjana jawapan yang lebih tepat dan relevan.
Manusia berinteraksi dengan dunia melalui pelbagai saluran seperti penglihatan dan bahasa, kerana setiap saluran individu mempunyai kelebihan unik dalam mewakili dan menyampaikan konsep dunia tertentu, dengan itu memudahkan Memahami dunia dengan baik .
Salah satu aspirasi teras kecerdasan buatan adalah untuk membangunkan pembantu sejagat yang boleh mengikut arahan visual dan bahasa pelbagai mod secara berkesan, konsisten dengan niat manusia, dan melengkapkan pelbagai kehidupan sebenar tugasan.
Hasilnya, komuniti pembangun telah menyaksikan minat yang diperbaharui dalam membangunkan model penglihatan asas yang ditambah bahasa dengan keupayaan berkuasa dalam pemahaman visual dunia terbuka seperti klasifikasi, pengesanan, segmentasi, penerangan , dan penjanaan dan penyuntingan visual.
Dalam ciri ini, setiap tugasan diselesaikan secara bebas oleh satu model visual besar, dengan arahan tugas secara tersirat dipertimbangkan dalam reka bentuk model.
Selain itu, bahasa hanya digunakan untuk menerangkan kandungan imej. Walaupun ini membolehkan bahasa memainkan peranan penting dalam memetakan isyarat visual kepada semantik linguistik - saluran biasa untuk komunikasi manusia. Walau bagaimanapun, ini menghasilkan model yang selalunya mempunyai antara muka tetap dengan interaktiviti terhad dan kebolehsuaian kepada arahan pengguna.
Dan model bahasa besar (LLM) menunjukkan bahawa bahasa boleh memainkan peranan yang lebih luas: antara muka biasa untuk pembantu am, pelbagai arahan tugas boleh dinyatakan secara eksplisit dalam bahasa dan membimbing penghujungnya -to-end Pembantu saraf terlatih akhir beralih kepada tugas yang diminati untuk menyelesaikannya.
Sebagai contoh, kejayaan ChatGPT dan GPT-4 baru-baru ini telah membuktikan keupayaan LLM ini untuk mengikut arahan manusia dan merangsang minat yang besar dalam membangunkan LLM sumber terbuka.
LLaMA ialah LLM sumber terbuka yang prestasinya setanding dengan GPT-3. Kerja yang berterusan memanfaatkan pelbagai arahan berkualiti tinggi yang dijana mesin berikutan sampel untuk meningkatkan keupayaan penjajaran LLM, melaporkan prestasi yang mengagumkan berbanding LLM proprietari. Yang penting, barisan kerja ini adalah teks sahaja.
Dalam kertas ini, penyelidik mencadangkan penalaan arahan visual, yang merupakan percubaan pertama untuk memanjangkan penalaan arahan ke dalam ruang berbilang mod dan membuka jalan untuk membina pembantu visual universal . Khususnya, kandungan utama kertas itu termasuk:
Arahan berbilang modal berikutan data. Cabaran utama ialah kekurangan arahan bahasa visual untuk mengikuti data. Kami membentangkan perspektif pembaharuan data dan saluran paip yang menggunakan ChatGPT/GPT-4 untuk menukar pasangan teks imej kepada format mengikut arahan yang sesuai.
Model berbilang modal besar. Para penyelidik membangunkan model multimodal besar (LMM) dengan menyambungkan pengekod visual set terbuka CLIP dan penyahkod bahasa LaMA, dan memperhalusinya dari hujung ke hujung pada data visual-verbal pengajaran yang dijana. Kajian empirikal mengesahkan keberkesanan penalaan arahan LMM menggunakan data yang dijana dan memberikan cadangan praktikal untuk membina agen visual mengikut arahan am. Dengan GPT 4, pasukan penyelidik mencapai prestasi terkini pada set data inferens berbilang mod Sains QA.
Sumber terbuka. Pasukan penyelidik mengeluarkan perkara berikut kepada orang ramai: data arahan multimodal yang dijana, perpustakaan kod untuk penjanaan data dan latihan model, pusat pemeriksaan model dan demonstrasi sembang visual.
Paparan Keputusan

Dapat dilihat bahawa LLaVA boleh menangani semua jenis masalah, dan jawapan yang dihasilkan adalah komprehensif dan logik.
LLaVA menunjukkan beberapa keupayaan berbilang modal yang hampir dengan tahap GPT-4, dengan skor relatif GPT-4 sebanyak 85% dari segi sembang visual.
Dari segi penaakulan soal jawab, LLaVA malah mencapai SoTA baharu - 92.53%, mengalahkan rantaian pemikiran pelbagai mod.
Atas ialah kandungan terperinci Universiti Wisconsin-Madison dan lain-lain bersama-sama mengeluarkan artikel! Model besar berbilang modal terkini LLaVA dikeluarkan, dan tahapnya hampir dengan GPT-4. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Pembangunan permainan AI memasuki era agentiknya dengan portal pemimpi UphealMay 02, 2025 am 11:17 AM
Pembangunan permainan AI memasuki era agentiknya dengan portal pemimpi UphealMay 02, 2025 am 11:17 AMPermainan Upheaval: Merevolusi Pembangunan Permainan Dengan Ejen AI Upheaval, sebuah studio pembangunan permainan yang terdiri daripada veteran dari gergasi industri seperti Blizzard dan Obsidian, bersedia untuk merevolusikan penciptaan permainan dengan platfor AI yang inovatif
 Uber mahu menjadi kedai Robotaxi anda, adakah pembekal membiarkan mereka?May 02, 2025 am 11:16 AM
Uber mahu menjadi kedai Robotaxi anda, adakah pembekal membiarkan mereka?May 02, 2025 am 11:16 AMStrategi Robotaxi Uber: ekosistem perjalanan untuk kenderaan autonomi Pada persidangan Curbivore baru-baru ini, Uber's Richard Willder melancarkan strategi mereka untuk menjadi platform perjalanan untuk penyedia Robotaxi. Memanfaatkan kedudukan dominan mereka di
 Ejen AI bermain permainan video akan mengubah robot masa depanMay 02, 2025 am 11:15 AM
Ejen AI bermain permainan video akan mengubah robot masa depanMay 02, 2025 am 11:15 AMPermainan video terbukti menjadi alasan ujian yang tidak ternilai untuk penyelidikan AI canggih, terutamanya dalam pembangunan agen autonomi dan robot dunia nyata, malah berpotensi menyumbang kepada pencarian kecerdasan umum buatan (AGI). A
 Kompleks Perindustrian Permulaan, VC 3.0, dan Manifesto James CurrierMay 02, 2025 am 11:14 AM
Kompleks Perindustrian Permulaan, VC 3.0, dan Manifesto James CurrierMay 02, 2025 am 11:14 AMKesan landskap modal teroka yang berkembang jelas dalam media, laporan kewangan, dan perbualan setiap hari. Walau bagaimanapun, akibat khusus untuk pelabur, permulaan, dan dana sering diabaikan. Venture Capital 3.0: Paradigma
 Adobe mengemas kini Cloud Creative dan Firefly di Adobe Max London 2025May 02, 2025 am 11:13 AM
Adobe mengemas kini Cloud Creative dan Firefly di Adobe Max London 2025May 02, 2025 am 11:13 AMAdobe Max London 2025 menyampaikan kemas kini penting kepada Awan Kreatif dan Firefly, mencerminkan peralihan strategik ke arah aksesibiliti dan AI generatif. Analisis ini menggabungkan pandangan dari taklimat pra-peristiwa dengan kepimpinan Adobe. (Nota: Adob
 Segala -galanya Meta diumumkan di LlamaconMay 02, 2025 am 11:12 AM
Segala -galanya Meta diumumkan di LlamaconMay 02, 2025 am 11:12 AMPengumuman Llamacon Meta mempamerkan strategi AI yang komprehensif yang direka untuk bersaing secara langsung dengan sistem AI yang tertutup seperti OpenAI, sementara pada masa yang sama mencipta aliran pendapatan baru untuk model sumber terbuka. Pendekatan beragam ini mensasarkan bo
 Kontroversi pembuatan bir atas cadangan bahawa AI tidak lebih dari sekadar teknologi biasaMay 02, 2025 am 11:10 AM
Kontroversi pembuatan bir atas cadangan bahawa AI tidak lebih dari sekadar teknologi biasaMay 02, 2025 am 11:10 AMTerdapat perbezaan yang serius dalam bidang kecerdasan buatan pada kesimpulan ini. Ada yang menegaskan bahawa sudah tiba masanya untuk mendedahkan "pakaian baru Maharaja", sementara yang lain menentang idea bahawa kecerdasan buatan hanyalah teknologi biasa. Mari kita bincangkannya. Analisis terobosan AI yang inovatif ini adalah sebahagian daripada lajur Forbes yang berterusan yang meliputi kemajuan terkini dalam bidang AI, termasuk mengenal pasti dan menjelaskan pelbagai kerumitan AI yang berpengaruh (klik di sini untuk melihat pautan). Kecerdasan Buatan sebagai Teknologi Biasa Pertama, beberapa pengetahuan asas diperlukan untuk meletakkan asas untuk perbincangan penting ini. Pada masa ini terdapat banyak penyelidikan yang didedikasikan untuk terus membangunkan kecerdasan buatan. Matlamat keseluruhan adalah untuk mencapai kecerdasan umum buatan (AGI) dan juga kecerdasan super buatan (AS)
 Model warga, mengapa nilai AI adalah ukuran perniagaan seterusnyaMay 02, 2025 am 11:09 AM
Model warga, mengapa nilai AI adalah ukuran perniagaan seterusnyaMay 02, 2025 am 11:09 AMKeberkesanan model AI syarikat kini merupakan penunjuk prestasi utama. Sejak ledakan AI, AI generatif telah digunakan untuk segala -galanya daripada menyusun jemputan ulang tahun untuk menulis kod perisian. Ini telah membawa kepada percambahan mod bahasa


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

VSCode Windows 64-bit Muat Turun
Editor IDE percuma dan berkuasa yang dilancarkan oleh Microsoft

Dreamweaver CS6
Alat pembangunan web visual

Dreamweaver Mac版
Alat pembangunan web visual

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

