
Rumah >Peranti teknologi >AI >Model teks tulen melatih perwakilan 'visual'! Penyelidikan terkini MIT: Model bahasa boleh melukis gambar menggunakan kod
Model teks tulen melatih perwakilan 'visual'! Penyelidikan terkini MIT: Model bahasa boleh melukis gambar menggunakan kod

- 王林ke hadapan
- 2024-02-01 21:12:121128semak imbas
Adakah model bahasa besar yang hanya boleh "membaca" mempunyai persepsi visual dunia sebenar? Dengan memodelkan hubungan antara rentetan, apakah sebenarnya yang boleh dipelajari oleh model bahasa tentang dunia visual?
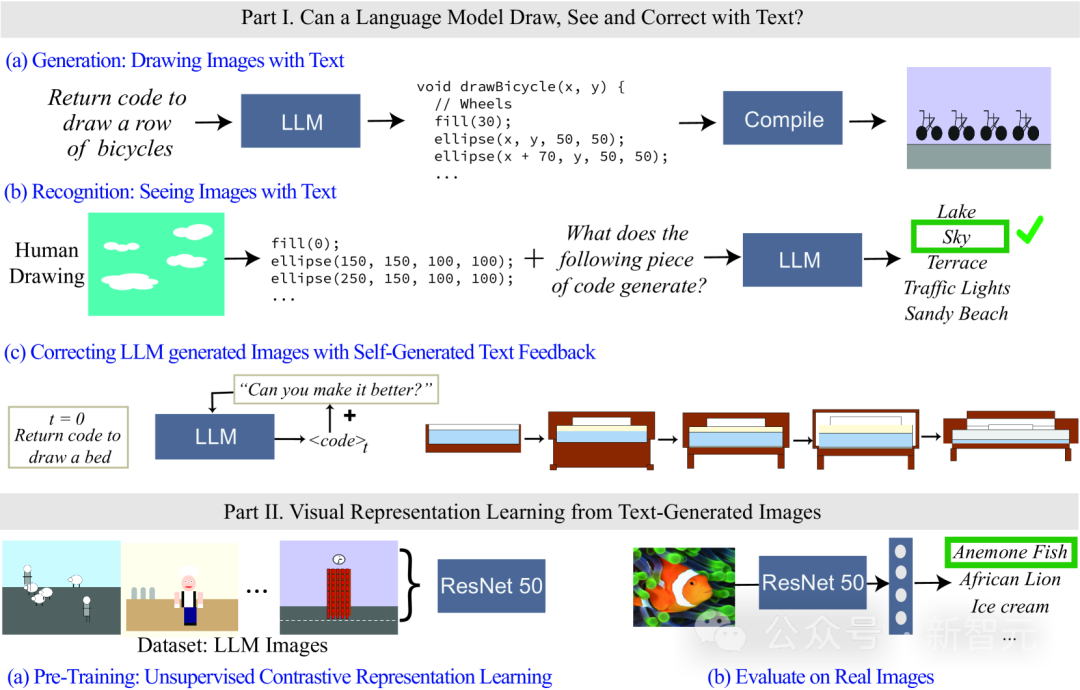
Baru-baru ini, penyelidik di MIT Computer Science and Artificial Intelligence Laboratory (MIT CSAIL) menilai model bahasa, memfokuskan pada keupayaan visual mereka. Mereka menguji kebolehan model dengan memintanya menjana dan mengenali konsep visual yang semakin kompleks, daripada bentuk dan objek mudah kepada adegan yang kompleks. Para penyelidik juga menunjukkan cara melatih sistem pembelajaran perwakilan visual awal menggunakan model teks sahaja. Dengan penyelidikan ini, mereka meletakkan asas untuk pembangunan lanjut dan penambahbaikan sistem pembelajaran perwakilan visual.

Pautan kertas: https://arxiv.org/abs/2401.01862
Memandangkan model bahasa tidak dapat memproses maklumat visual, kod digunakan untuk memaparkan imej dalam kajian.
Walaupun imej yang dihasilkan oleh LLM mungkin tidak realistik seperti imej semula jadi, daripada hasil penjanaan dan pembetulan kendiri model, ia mampu memodelkan rentetan/teks dengan tepat, yang membolehkan model bahasa belajar tentang dunia visual pelbagai konsep.
Penyelidik juga mengkaji kaedah untuk pembelajaran perwakilan visual yang diselia sendiri menggunakan imej yang dihasilkan oleh model teks. Keputusan menunjukkan bahawa kaedah ini berpotensi untuk digunakan untuk melatih model penglihatan dan melakukan penilaian semantik imej semula jadi hanya menggunakan LLM.
Konsep visual model bahasa
Mula-mula tanya soalan: Apakah maksud orang ramai memahami konsep visual "katak"?
Adakah cukup untuk mengetahui warna kulitnya, berapa banyak kakinya, kedudukan matanya, bagaimana rupanya ketika melompat dan sebagainya?
Orang ramai sering berfikir bahawa untuk memahami konsep katak, seseorang perlu melihat imej katak dan memerhatinya dari pelbagai sudut dan senario kehidupan sebenar.
Sejauh manakah kita dapat memahami makna visual bagi konsep yang berbeza jika kita hanya memerhati teks?
Dari perspektif latihan model, input latihan model bahasa besar (LLM) hanyalah data teks, tetapi model tersebut telah terbukti memahami maklumat tentang konsep seperti bentuk dan warna, malah boleh menukarkannya kepada penglihatan. melalui transformasi linear dalam perwakilan model.
Dalam erti kata lain, model visual dan model bahasa adalah sangat serupa dari segi perwakilan dunia.
Walau bagaimanapun, kebanyakan kaedah sedia ada untuk pencirian model adalah berdasarkan set atribut yang telah dipilih untuk meneroka maklumat yang dikodkan oleh model ini Kaedah ini tidak boleh mengembangkan atribut secara dinamik, dan juga memerlukan akses kepada parameter dalaman model .
Jadi para penyelidik mengemukakan dua soalan:
1.
2. Adakah mungkin untuk melatih sistem visual yang boleh digunakan untuk imej semula jadi "hanya menggunakan model teks"?
Untuk mengetahui, penyelidik mencapai pengukuran dengan menguji model bahasa yang berbeza dalam merender (melukis) dan mengenali (lihat) konsep visual dunia sebenar untuk menilai maklumat yang disertakan dalam model tersebut melatih pengelas ciri secara individu untuk setiap atribut.
Walaupun model bahasa tidak boleh menjana imej, model besar seperti GPT-4 boleh menjana kod untuk memaparkan objek Artikel ini menggunakan proses gesaan teks -> kod -> imej untuk meningkatkan secara beransur-ansur kesukaran memaparkan objek untuk diukur. keupayaan model.
Penyelidik mendapati bahawa LLM sangat baik dalam menghasilkan pemandangan visual kompleks yang terdiri daripada berbilang objek, dan boleh memodelkan hubungan ruang dengan cekap, tetapi tidak dapat menangkap dunia visual dengan baik, termasuk sifat objek, seperti tekstur , bentuk tepat dan sentuhan permukaan dengan objek lain dalam imej.
Artikel itu juga menilai keupayaan LLM untuk mengenal pasti konsep persepsi, memasukkan lukisan yang diwakili oleh kod, dan kod tersebut termasuk urutan, kedudukan dan warna bentuk, dan kemudian meminta model bahasa menjawab kandungan visual yang diterangkan dalam kod-kod tersebut.

Hasil eksperimen mendapati bahawa LLM adalah bertentangan dengan manusia: bagi manusia, proses menulis kod adalah sukar, tetapi mudah untuk mengesahkan kandungan imej manakala model sukar untuk dilakukan mentafsir/mengiktiraf kandungan kod tetapi ia boleh menghasilkan adegan yang kompleks.
Selain itu, hasil kajian juga membuktikan bahawa keupayaan penjanaan visual model bahasa boleh dipertingkatkan lagi melalui pembetulan berasaskan teks.
Penyelidik mula-mula menggunakan model bahasa untuk menjana kod yang menggambarkan konsep, dan kemudian terus memasukkan gesaan "memperbaiki kod yang dijana" (memperbaiki kod yang dijana) sebagai syarat untuk mengubah suai kod ditambah baik melalui pendekatan berulang ini kesan visual.

Set Data Keupayaan Visual: Menunjuk kepada Adegan
Para penyelidik membina tiga set data perihalan teks untuk mengukur keupayaan model untuk mencipta, mengecam dan mengubah suai kod pemaparan imej, dengan kerumitan antara bentuk dan gabungan yang mudah , objek dan adegan yang kompleks.

1. Bentuk dan gubahannya
mengandungi komposisi bentuk daripada kategori yang berbeza, seperti titik, garisan, bentuk 3D dan bentuk 2D yang berbeza. tekstur, kedudukan dan susunan ruang.
Set data lengkap mengandungi lebih daripada 400,000 contoh, yang mana 1500 sampel digunakan untuk ujian percubaan.
2. Objek
Mengandungi 1000 objek paling biasa dalam set data ADE 20K, yang lebih sukar untuk dijana dan dikenali kerana ia mengandungi gabungan bentuk yang lebih kompleks.
3. Adegan
terdiri daripada huraian adegan yang kompleks, termasuk berbilang objek dan lokasi yang berbeza, dan diperoleh dengan mengambil 1000 huraian adegan secara rawak dan seragam daripada set data MS-COCO.
Konsep visual dalam set data diterangkan dalam bahasa Contohnya, huraian pemandangan ialah "hari musim panas yang cerah di pantai, dengan langit biru dan lautan yang tenang."
Semasa proses ujian, LLM diminta menjana kod dan menyusun imej yang diberikan berdasarkan adegan yang digambarkan.
Hasil eksperimen
Tugas menilai model terutamanya terdiri daripada tiga:
1 Jana/lukis teks: Menilai keupayaan LLM dalam menghasilkan kod pemaparan imej yang sepadan dengan konsep tertentu.
2. Kenali/lihat teks: Uji prestasi LLM dalam mengenali konsep visual dan adegan yang diwakili dalam kod. Kami menguji perwakilan kod lukisan manusia pada setiap model.
3 Membetulkan lukisan menggunakan maklum balas teks: Nilaikan keupayaan LLM untuk mengubah suai kod terjananya secara berulang menggunakan maklum balas bahasa semula jadi yang dijananya.
Gesaan untuk input model dalam ujian ialah: tulis kod dalam bahasa pengaturcaraan [nama bahasa pengaturcaraan] yang melukis [konsep]
Kemudian susun dan buat mengikut kod output model, dan secara visual menjana imej Kualiti dan kepelbagaian dinilai:
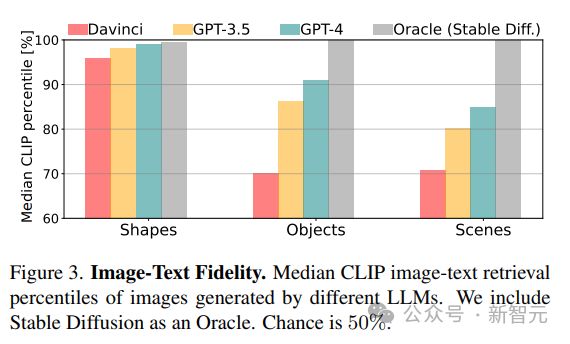
1. Kesetiaan
Kira kesetiaan antara imej yang dijana dan penerangan sebenar dengan mendapatkan penerangan terbaik bagi imej. Skor CLIP mula-mula digunakan untuk mengira persetujuan antara setiap imej dan semua perihalan berpotensi dalam kategori yang sama (bentuk/objek/adegan), dan kemudian kedudukan perihalan sebenar dilaporkan sebagai peratusan (cth. skor 100% bermakna bahawa konsep yang benar berada pada kedudukan pertama) .
2. Kepelbagaian
Untuk menilai keupayaan model untuk menghasilkan kandungan yang berbeza, skor kepelbagaian LPIPS digunakan pada pasangan imej yang mewakili konsep visual yang sama.
3. Realisme
Untuk koleksi sampel imej 1K daripada ImageNet, gunakan Fréchet Inception Distance (FID ) untuk mengukur perbezaan taburan antara imej semula jadi dan imej yang dijana LLM.
Dalam eksperimen perbandingan, model yang diperoleh oleh Stable Diffusion digunakan sebagai garis dasar.
Apakah yang boleh LLM gambarkan?
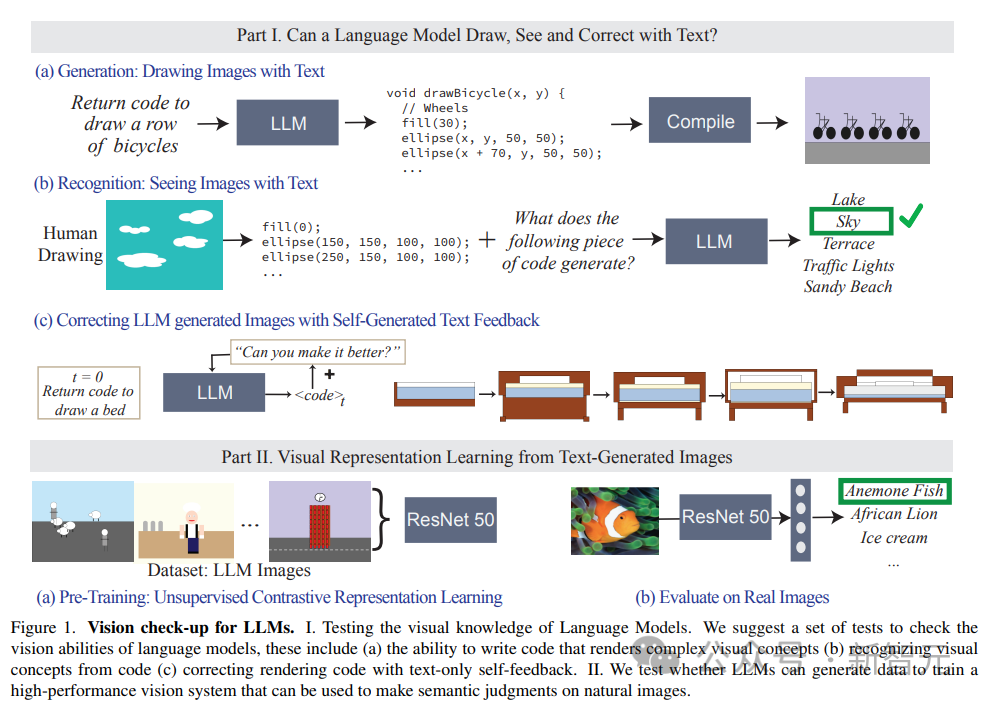
Hasil penyelidikan mendapati LLM boleh menggambarkan konsep dunia sebenar daripada keseluruhan hierarki visual, menggabungkan dua konsep yang tidak berkaitan (seperti kek berbentuk kereta), menjana fenomena visual (seperti imej kabur) dan berjaya mentafsir ruang dengan betul Perhubungan (seperti "deretan basikal" yang disusun secara melintang).
Seperti yang dijangka, daripada keputusan skor CLIP Lihat, keupayaan model berkurangan apabila kerumitan konsep meningkat daripada bentuk kepada adegan.
Untuk konsep visual yang lebih kompleks, seperti melukis pemandangan yang mengandungi berbilang objek, GPT-3.5 dan GPT-4 adalah lebih baik daripada python-matplotlib dan python-turtle apabila melukis pemandangan dengan penerangan kompleks menggunakan pemprosesan dan tikz Lebih tepat .
Apa yang tidak dapat dibayangkan oleh LLM?
Dalam sesetengah kes, model sukar untuk dilukis walaupun untuk konsep yang agak mudah, dan penyelidik merumuskan tiga mod kegagalan biasa:
1. Model bahasa tidak boleh mengendalikan satu set bentuk dan konsep tertentu organisasi ruang;2. Lukisan kasar dan kurang terperinci, paling kerap dilihat dalam Davinci, terutamanya apabila menggunakan matplotlib dan pengekodan penyu
3 konsep (kategori tipikal senario).
4. Semua model tidak boleh melukis angka.
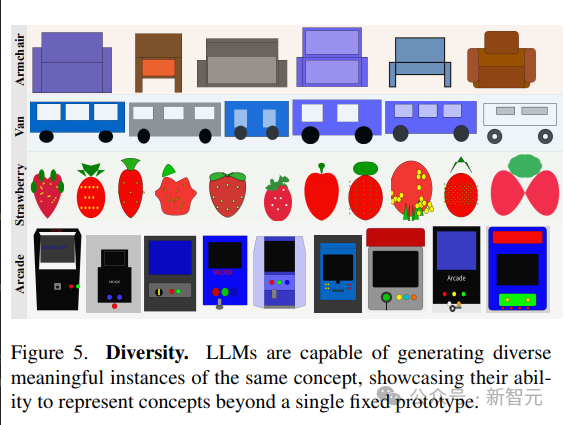
Kepelbagaian dan Realisme
Model bahasa menunjukkan keupayaan untuk menjana visualisasi yang berbeza bagi konsep yang sama.
Untuk menghasilkan sampel yang berbeza dari pemandangan yang sama, artikel membandingkan dua strategi:1 Pensampelan berulang daripada model
2 plot baru konsep.
Keupayaan model untuk mewakili pelbagai pelaksanaan konsep visual dicerminkan dalam skor kepelbagaian LPIPS yang tinggi, keupayaan untuk menghasilkan imej yang pelbagai menunjukkan bahawa LLM mampu mewakili konsep visual dalam pelbagai cara, tanpa terhad kepada sesuatu; prototaip set terhad.

Mempelajari sistem visual daripada teks
Latihan dan penilaian
Para penyelidik menggunakan model visual pra-latihan yang diperoleh daripada pembelajaran tanpa pengawasan sebagai tulang belakang rangkaian, menggunakan kaedah MoCo-v23 juta 384× dalam LLM Model ResNet-50 dilatih pada set data imej 384 untuk jumlah 200 zaman selepas latihan, dua kaedah digunakan untuk menilai prestasi model yang dilatih pada setiap set data:
1 Klasifikasi ImageNet-1 k Latih lapisan linear pada tulang belakang selama 100 zaman,2 Gunakan pengambilan semula 5 jiran terdekat (kNN) pada ImageNet-100.
Seperti yang dapat dilihat daripada keputusan, model yang dilatih hanya menggunakan data yang dijana oleh LLM boleh memberikan keupayaan perwakilan yang berkuasa untuk imej semula jadi tanpa perlu melatih lapisan linear.

Analisis Keputusan
Para penyelidik membandingkan imej yang dijana oleh LLM dengan yang dijana oleh program sedia ada, termasuk program generatif mudah seperti dead-levaves, fraktal dan StyleGAN, untuk menghasilkan imej yang sangat pelbagai. Daripada keputusan, kaedah LLM adalah lebih baik daripada dead-levaves dan fraktal, tetapi bukan sota selepas pemeriksaan manual terhadap data, penyelidik mengaitkan rendah diri ini Terdapat kekurangan tekstur dalam kebanyakan imej yang dihasilkan LLM; . Untuk menangani isu ini, penyelidik menggabungkan set data Shaders-21k dengan sampel yang diperoleh daripada LLM untuk menjana imej kaya tekstur. Seperti yang dapat dilihat daripada keputusan, penyelesaian ini boleh meningkatkan prestasi dengan ketara dan mengatasi penyelesaian yang dihasilkan oleh program lain. 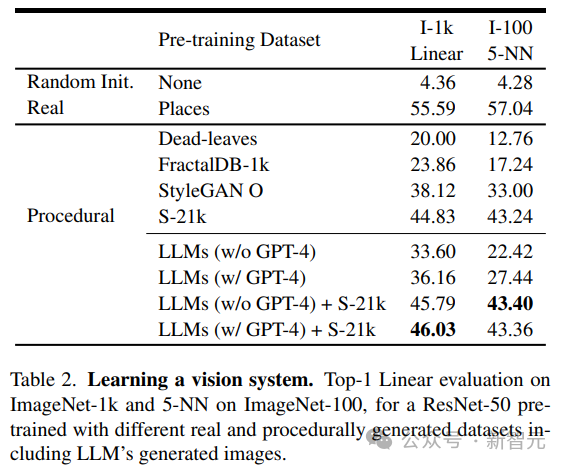
Atas ialah kandungan terperinci Model teks tulen melatih perwakilan 'visual'! Penyelidikan terkini MIT: Model bahasa boleh melukis gambar menggunakan kod. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!