
Rumah >Peranti teknologi >AI >Bagaimana untuk menyelesaikan batasan latihan ketepatan campuran model besar
Bagaimana untuk menyelesaikan batasan latihan ketepatan campuran model besar

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-13 20:28:012233semak imbas
Ketepatan campuran telah menjadi keperluan untuk melatih model pembelajaran mendalam yang besar, tetapi ia juga membawa banyak cabaran. Menukar parameter dan kecerunan model kepada jenis data ketepatan yang lebih rendah (seperti FP16) boleh mempercepatkan latihan, tetapi juga memperkenalkan isu kestabilan berangka. Kecerunan yang digunakan untuk latihan FP16 lebih berkemungkinan melimpah atau tidak mencukupi, mengakibatkan pengiraan tidak tepat oleh pengoptimum dan masalah seperti penumpuk melebihi julat jenis data.

Dalam artikel ini, kita akan membincangkan isu kestabilan berangka latihan ketepatan hibrid. Pekerjaan latihan yang besar sering ditangguhkan selama beberapa hari untuk menangani ketidakstabilan berangka, menyebabkan kelewatan projek. Oleh itu, kami boleh memperkenalkan Tensor Collection Hook untuk memantau keadaan kecerunan semasa latihan, supaya kami dapat memahami dengan lebih baik keadaan dalaman model dan mengenal pasti ketidakstabilan berangka dengan lebih cepat.
Ia adalah cara yang sangat baik untuk memahami keadaan dalaman model dalam peringkat latihan awal untuk menentukan sama ada model terdedah kepada ketidakstabilan dalam latihan kemudiannya. Jika ketidakstabilan kecerunan dapat dikenal pasti dalam beberapa jam pertama latihan , boleh membantu kami meningkatkan banyak kecekapan. Jadi artikel ini menyediakan satu siri kaveat yang patut diberi perhatian, serta remedi untuk ketidakstabilan berangka.
Latihan Ketepatan Campuran
Memandangkan pembelajaran mendalam terus berkembang ke arah model asas yang lebih besar. Model bahasa yang besar seperti GPT dan T5 kini mendominasi NLP, dan model yang berbeza seperti CLIP digeneralisasikan lebih baik daripada model diselia tradisional dalam CV. Khususnya, keupayaan CLIP untuk mempelajari pembenaman teks bermakna ia boleh melakukan inferens sifar pukulan dan beberapa pukulan yang melebihi keupayaan model CV yang lalu, yang kedua-duanya merupakan satu cabaran untuk dilatih.
Model besar ini biasanya melibatkan rangkaian transformer yang mendalam, kedua-dua visual dan tekstual, dan mengandungi berbilion parameter. GPT3 mempunyai 175 bilion parameter, dan CLIP dilatih pada beratus-ratus terabait imej. Saiz model dan data bermakna model memerlukan berminggu-minggu atau bahkan berbulan-bulan untuk melatih kluster GPU yang besar. Untuk mempercepatkan latihan dan mengurangkan bilangan GPU yang diperlukan, model sering dilatih dengan ketepatan campuran.
Latihan Ketepatan Hibrid meletakkan beberapa operasi latihan dalam FP16 dan bukannya FP32. Operasi yang dilakukan dalam FP16 memerlukan kurang memori dan boleh diproses sehingga 8 kali lebih pantas daripada FP32 pada GPU moden. Walaupun kebanyakan model yang dilatih dalam FP16 mempunyai ketepatan yang lebih rendah, mereka tidak menunjukkan sebarang kemerosotan prestasi akibat penparameteran berlebihan.
Dengan pengenalan Tensor Cores oleh NVIDIA dalam seni bina Volta, latihan pecutan titik terapung ketepatan rendah adalah lebih pantas. Oleh kerana model pembelajaran mendalam mempunyai banyak parameter, nilai tepat mana-mana satu parameter biasanya tidak penting. Dengan mewakili nombor dengan 16 bit dan bukannya 32 bit, lebih banyak parameter boleh dimuatkan dalam daftar Teras Tensor sekaligus, meningkatkan keselarian untuk setiap operasi.

Tetapi latihan untuk FP16 memang mencabar. Kerana FP16 tidak boleh mewakili nombor yang nilai mutlaknya lebih besar daripada 65,504 atau kurang daripada 5.96e-8. Rangka kerja pembelajaran mendalam seperti PyTorch disertakan dengan alatan terbina dalam untuk mengendalikan had FP16 (penskalaan kecerunan dan ketepatan campuran automatik). Tetapi walaupun dengan pemeriksaan keselamatan ini dilaksanakan, kerja latihan besar gagal kerana parameter atau kecerunan berada di luar julat yang tersedia. Sesetengah komponen pembelajaran mendalam bermain dengan baik dalam FP32, tetapi BN, sebagai contoh, sering memerlukan penalaan yang sangat halus yang boleh menyebabkan ketidakstabilan berangka dalam had FP16, atau tidak menghasilkan ketepatan yang mencukupi untuk model menumpu dengan betul. Ini bermakna model tidak boleh ditukar secara membuta tuli kepada FP16.
Jadi rangka kerja pembelajaran mendalam menggunakan Automatic Mixed Precision (AMP), yang dilatih dengan senarai pratakrif operasi selamat untuk FP16. AMP hanya menukar bahagian model yang dianggap selamat, sambil mengekalkan operasi yang memerlukan ketepatan yang lebih tinggi dalam FP32. Di samping itu, dalam model latihan ketepatan campuran, kecerunan yang lebih besar diperoleh dengan mendarabkan beberapa kerugian yang hampir kepada kecerunan sifar (di bawah julat minimum FP16) dengan nilai tertentu, dan kemudian apabila pengoptimum digunakan untuk mengemas kini berat model, ia akan berkadar ke bawah Pelarasan untuk menyelesaikan masalah kecerunan yang terlalu kecil dipanggil penskalaan kecerunan.
Berikut ialah contoh gelung latihan AMP biasa dalam PyTorch.

Penskala kecerunan Penskala mendarabkan kerugian dengan jumlah berubah-ubah. Jika nan diperhatikan dalam kecerunan, pengganda dikurangkan separuh sehingga nan hilang, kemudian secara beransur-ansur meningkatkan pengganda setiap 2000 langkah secara lalai jika tiada nan berlaku. Ini akan mengekalkan kecerunan dalam julat FP16 sambil juga menghalang kecerunan daripada menjadi sifar.
Kes ketidakstabilan latihan
Walaupun usaha terbaik kedua-dua rangka kerja, alatan yang terbina dalam PyTorch dan TensorFlow tidak dapat menghalang ketidakstabilan berangka yang berlaku dalam FP16.
Dalam pelaksanaan T5 HuggingFace, varian model menghasilkan nilai INF walaupun selepas latihan. Dalam model T5 yang sangat dalam, nilai perhatian terkumpul merentas lapisan dan akhirnya mencapai di luar julat FP16, yang menghasilkan nilai tak terhingga, seperti nan dalam lapisan BN. Mereka menyelesaikan masalah ini dengan menukar nilai INF kepada nilai maksimum pada FP16 dan mendapati bahawa ini mempunyai kesan yang boleh diabaikan pada inferens.
Satu lagi masalah biasa ialah pengehadan pengoptimum ADAM. Sebagai kemas kini kecil, ADAM menggunakan purata bergerak momen pertama dan kedua kecerunan untuk menyesuaikan kadar pembelajaran setiap parameter dalam model.
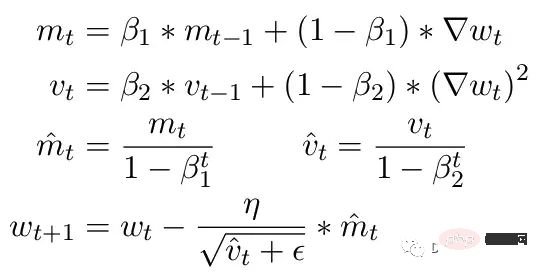
Di sini Beta1 dan Beta2 ialah parameter purata bergerak pada setiap saat, biasanya ditetapkan masing-masing kepada .9 dan .999. Membahagikan parameter beta dengan kuasa bilangan langkah mengalih keluar bias awal dalam kemas kini. Semasa langkah kemas kini, epsilon kecil ditambahkan pada parameter momen kedua untuk mengelakkan pembahagian dengan ralat sifar. Nilai lalai biasa untuk epsilon ialah 1e-8. Tetapi minimum untuk FP16 ialah 5.96e-8. Ini bermakna jika momen kedua terlalu kecil, kemas kini akan dibahagikan dengan sifar. Jadi dalam PyTorch supaya latihan tidak menyimpang, kemas kini akan melangkau perubahan dalam langkah ini. Tetapi masalahnya masih wujud. Terutamanya dalam kes Beta2=.999, sebarang kecerunan yang lebih kecil daripada 5.96e-8 boleh menghentikan kemas kini berat parameter untuk masa yang lama, dan pengoptimum akan memasuki keadaan tidak stabil.
Kelebihan ADAM ialah dengan menggunakan dua detik ini, kadar pembelajaran setiap parameter boleh dilaraskan. Untuk parameter pembelajaran yang lebih perlahan, kelajuan pembelajaran boleh dipercepatkan, dan untuk parameter pembelajaran pantas, kelajuan pembelajaran boleh diperlahankan. Tetapi jika kecerunan dikira menjadi sifar untuk berbilang langkah, walaupun nilai positif yang kecil akan menyebabkan model menyimpang sebelum kadar pembelajaran mempunyai masa untuk melaraskan ke bawah.
Juga PyTorch pada masa ini menghadapi masalah di mana ia secara automatik menukar epsilon kepada 1e-7 apabila menggunakan ketepatan campuran, yang boleh membantu menghalang kecerunan daripada menyimpang apabila beralih kembali kepada nilai positif. Tetapi berbuat demikian membawa masalah baharu Apabila kita tahu bahawa kecerunan berada dalam julat yang sama, meningkatkan ε mengurangkan keupayaan pengoptimum untuk menyesuaikan diri dengan kadar pembelajaran. Oleh itu, epsilon yang meningkat secara membuta tuli tidak dapat menyelesaikan masalah genangan latihan akibat kecerunan sifar.
Penskalaan Kecerunan dalam Latihan CLIP
Untuk menunjukkan lagi ketidakstabilan yang mungkin berlaku dalam latihan, kami membina satu siri eksperimen pada model imej CLIP. CLIP ialah model berasaskan pembelajaran kontras yang mempelajari imej secara serentak melalui pengubah visual dan pembenaman teks yang menerangkan imej tersebut. Komponen perbandingan cuba memadankan imej kembali kepada perihalan asal dalam setiap kumpulan data. Memandangkan kerugian dikira dalam kelompok, latihan pada kelompok yang lebih besar telah ditunjukkan untuk memberikan hasil yang lebih baik.
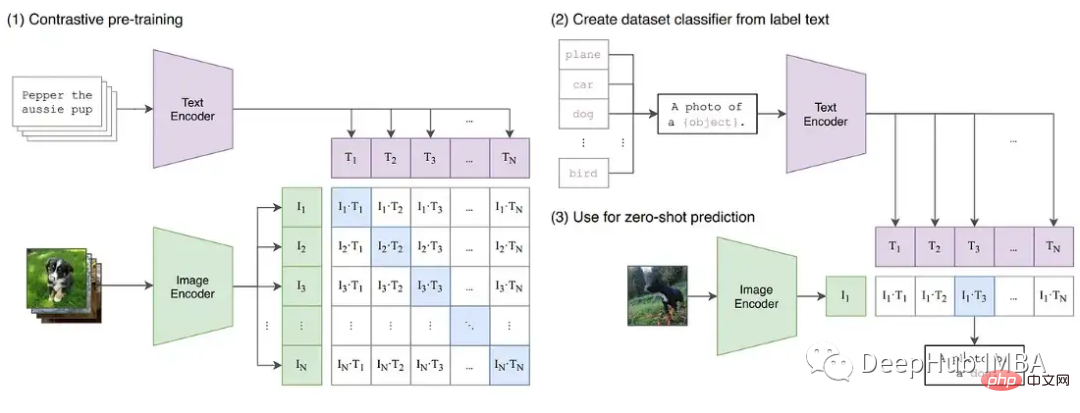
CLIP secara serentak melatih dua model transformer, model bahasa seperti GPT dan model imej ViT. Kedalaman kedua-dua model mewujudkan peluang untuk pertumbuhan kecerunan melebihi had FP16. Pelaksanaan OpenClip (arxiv 2212.07143) menerangkan ketidakstabilan latihan apabila menggunakan FP16.
Tensor Collection Hook
Untuk lebih memahami keadaan model dalaman semasa latihan, kami membangunkan Tensor Collection Hook (TCH). TCH boleh membungkus model dan secara berkala mengumpul maklumat ringkasan tentang berat, kecerunan, kerugian, input, output dan status pengoptimum.
Sebagai contoh, dalam eksperimen ini, kami ingin mencari dan merekodkan keadaan kecerunan semasa latihan. Sebagai contoh, anda mungkin ingin mengumpul norma kecerunan, minimum, maksimum, nilai mutlak, min dan sisihan piawai daripada setiap lapisan setiap 10 langkah dan memvisualisasikan keputusan dalam TensorBoard.

TensorBoard kemudiannya boleh dimulakan dengan out_dir sebagai input --logdir.

Eksperimen
Untuk menghasilkan semula ketidakstabilan latihan dalam CLIP, dataset imej Laion 5 bilion yang digunakan untuk latihan OpenCLIP subset. Kami membalut model dengan TCH dan sentiasa menyimpan kecerunan model, berat dan keadaan momen pengoptimum, supaya kami dapat memerhatikan perkara yang berlaku di dalam model apabila ketidakstabilan berlaku.
Bermula dengan varian vvi-h-14, pengarang OpenCLIP menerangkan isu kestabilan semasa latihan. Bermula dari pusat pemeriksaan pra-latihan, tingkatkan kadar pembelajaran kepada 1-e4, sama seperti kadar pembelajaran pada separuh kedua latihan CLIP. Apabila latihan mencapai 300 langkah, 10 kelompok latihan yang lebih sukar sengaja diperkenalkan berturut-turut.
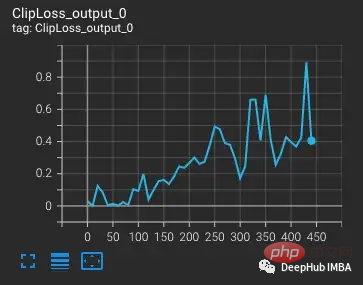
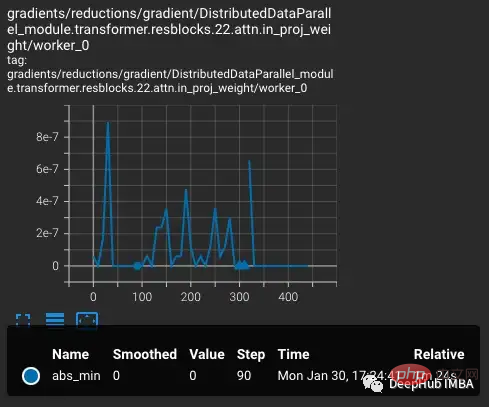
Dijangka kerugian akan meningkat apabila kadar pembelajaran meningkat. Apabila situasi yang lebih sukar diperkenalkan pada langkah 300, terdapat peningkatan kecil, tetapi tidak besar, dalam kerugian. Model menemui kes yang sukar tetapi tidak mengemas kini kebanyakan pemberat dalam langkah ini kerana nan muncul dalam kecerunan (ditunjukkan sebagai segi tiga dalam plot kedua). Selepas melepasi set kes yang sukar ini, kecerunan turun kepada sifar.
Penskalaan Kecerunan PyTorch
Apa yang berlaku di sini? Mengapakah kecerunan sifar? Penskalaan kecerunan ialah alat penting dalam latihan ketepatan campuran. Kerana dalam model dengan berjuta-juta atau berbilion-bilion parameter, kecerunan mana-mana satu parameter adalah kecil dan selalunya di bawah julat minimum FP16.
Apabila latihan ketepatan hibrid pertama kali dicadangkan, saintis pembelajaran mendalam mendapati bahawa model mereka sering dilatih seperti yang dijangkakan pada awal latihan, tetapi akhirnya menyimpang. Semasa latihan berlangsung, kecerunan cenderung menjadi lebih kecil, dan beberapa aliran bawah FP16 menjadi sifar, menjadikan latihan tidak stabil.

Untuk menyelesaikan aliran bawah kecerunan, teknik awal hanya mendarabkan kerugian dengan jumlah tetap, mengira kecerunan yang lebih besar, dan kemudian kemas kini Berat dilaraskan kepada jumlah tetap yang sama (semasa latihan ketepatan campuran, pemberat masih disimpan dalam FP32). Tetapi kadangkala jumlah tetap ini masih tidak mencukupi. Dan teknik yang lebih baharu, seperti penskalaan kecerunan PyTorch, bermula dengan pengganda yang lebih besar, biasanya 65536. Tetapi kerana ini boleh menjadi sangat tinggi sehingga kecerunan besar akan melimpahi nilai FP16, penimbang kecerunan memantau kecerunan nan yang akan melimpah. Jika nan diperhatikan, langkau kemas kini berat pada langkah ini untuk mengurangkan pengganda dan teruskan ke langkah seterusnya. Ini berterusan sehingga tiada nan diperhatikan dalam kecerunan. Jika penimbang kecerunan tidak mengesan nan dalam langkah 2000, ia akan cuba menggandakan pengganda.
Dalam contoh di atas, penimbang kecerunan berfungsi tepat seperti yang diharapkan. Kami memberikannya satu set kes di mana kerugian lebih besar daripada yang dijangkakan, yang mewujudkan kecerunan yang lebih besar yang membawa kepada limpahan. Tetapi masalahnya ialah pengganda kini rendah, kecerunan yang lebih kecil jatuh kepada sifar, dan penimbang kecerunan tidak memantau kecerunan sifar sahaja.
Contoh di atas pada mulanya mungkin kelihatan agak disengajakan, kerana kami sengaja mengumpulkan contoh yang sukar. Tetapi selepas beberapa hari latihan, dalam kes kumpulan besar, kebarangkalian untuk menghasilkan anomali nan pasti akan meningkat. Jadi peluang untuk menemui nan yang cukup untuk menolak kecerunan kepada sifar adalah sangat tinggi. Malah, walaupun sampel sukar tidak diperkenalkan, ia sering didapati bahawa kecerunan sentiasa sifar selepas beribu-ribu langkah latihan.
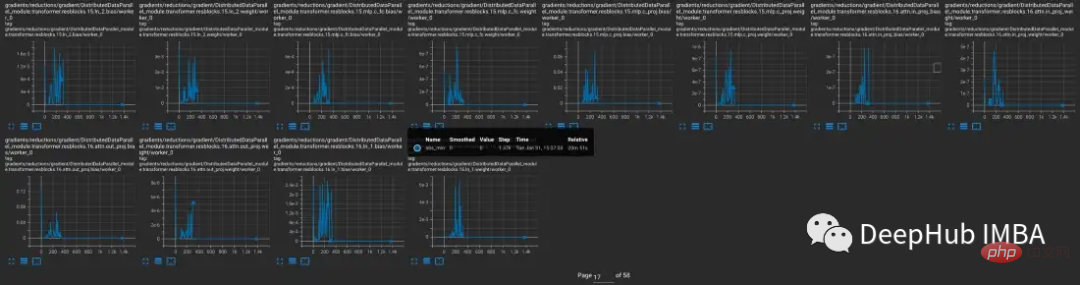
Model yang menghasilkan aliran bawah kecerunan
Untuk meneroka lebih lanjut apabila masalah itu berlaku dan apabila ia tidak berlaku, CLIP dibandingkan dengan CLIP yang biasanya dilatih di bawah ketepatan campuran. model CV yang lebih kecil YOLOV5 dibandingkan. Kekerapan kecerunan sifar dalam setiap lapisan telah dijejaki semasa latihan dalam kedua-dua kes.

Semasa 9000 langkah pertama latihan, 5-20% daripada lapisan dalam CLIP menunjukkan aliran bawah kecerunan, manakala lapisan dalam Yolo hanya menunjukkan aliran bawah sekali-sekala . Kadar aliran bawah dalam CLIP juga meningkat dari semasa ke semasa, menjadikan latihan kurang stabil.
Menggunakan penskalaan kecerunan tidak menyelesaikan masalah ini kerana magnitud kecerunan dalam julat CLIP jauh lebih besar daripada magnitud kecerunan dalam julat YOLO. Dalam kes CLIP, sementara penimbang kecerunan mengalihkan kecerunan yang lebih besar mendekati maksimum dalam FP16, kecerunan terkecil kekal di bawah minimum.
Cara menyelesaikan ketidakstabilan kecerunan dalam menyelesaikan CLIP
Dalam sesetengah kes, melaraskan parameter penimbang kecerunan boleh membantu mengelakkan aliran bawah. Dalam kes CLIP, seseorang boleh mencuba pengubahsuaian untuk bermula dengan pengganda yang lebih besar dan memendekkan selang peningkatan.

Tetapi kami mendapati bahawa pengganda turun serta-merta untuk mengelakkan limpahan dan memaksa kecerunan kecil kembali kepada sifar.

Satu penyelesaian untuk menambah baik penskalaan ialah menjadikannya lebih mudah disesuaikan dengan julat parameter. Sebagai contoh, makalah Adaptive Loss Scaling for Mixed Precision Training mengesyorkan melakukan penskalaan kerugian mengikut lapisan dan bukannya keseluruhan model, yang boleh menghalang aliran bawah. Dan eksperimen kami menunjukkan keperluan untuk pendekatan yang lebih adaptif. Memandangkan kecerunan dalam lapisan CLIP masih meliputi keseluruhan julat FP16, penskalaan perlu disesuaikan dengan setiap parameter individu untuk memastikan kestabilan latihan. Tetapi penskalaan terperinci itu memerlukan banyak memori yang mengurangkan saiz kumpulan latihan.
Perkakasan yang lebih baharu menawarkan penyelesaian yang lebih cekap. Sebagai contoh, BFloat16 (BF16) ialah satu lagi jenis data 16-bit yang memperdagangkan ketepatan untuk julat yang lebih besar. FP16 mengendalikan 5.96e-8 hingga 65,504, manakala BF16 boleh mengendalikan 1.17e-38 hingga 3.39e38, julat yang sama seperti FP32. Walau bagaimanapun, ketepatan BF16 adalah lebih rendah daripada FP16, yang akan menyebabkan sesetengah model tidak menumpu. Tetapi untuk model transformer besar, BF16 tidak ditunjukkan untuk mengurangkan penumpuan.
Kami menjalankan ujian yang sama dengan memasukkan kumpulan pemerhatian yang sukar Dalam BF16 kecerunan meningkat apabila kes keras diperkenalkan dan kemudian kembali ke latihan biasa kerana perubahan skala kecerunan daripada NaN tidak diperhatikan dalam kecerunan.

Membandingkan KLIP FP16 dan BF16, kami mendapati bahawa terdapat aliran bawah kecerunan sekali-sekala dalam BF16.

Dalam PyTorch 1.12 dan ke atas, adalah mungkin untuk mendayakan BF16 dengan perubahan kecil kepada AMP.

Jika anda memerlukan ketepatan yang lebih tinggi, anda boleh mencuba jenis data Tensorfloat32 (TF32). TF32, yang diperkenalkan oleh Nvidia dalam GPU Ampere, ialah titik terapung 19-bit yang menambah bit julat tambahan BF16 sambil mengekalkan ketepatan FP16. Tidak seperti FP16 dan BF16, ia direka untuk menggantikan FP32 secara langsung, dan bukannya didayakan dalam ketepatan campuran. Untuk mendayakan TF32 dalam PyTorch, tambah dua baris pada permulaan latihan.

Perlu diperhatikan di sini: sebelum PyTorch 1.11, TF32 didayakan secara lalai pada GPU yang menyokong jenis data ini. Bermula dengan PyTorch 1.11, ia mesti didayakan secara manual. Kelajuan latihan TF32 adalah lebih perlahan daripada BF16 dan FP16 FLOPS teori hanya separuh daripada FP16, tetapi ia masih jauh lebih pantas daripada kelajuan latihan FP32.
Jika anda menggunakan Amazon AWS: BF16 dan TF32 tersedia pada tika P4d, P4de, G5, Trn1 dan DL1.
Selesaikan masalah sebelum ia berlaku
Contoh di atas menggambarkan cara mengenal pasti dan membetulkan had seluruh FP16. Tetapi masalah ini sering muncul kemudian dalam latihan. Pada awal latihan, apabila model menghasilkan kerugian yang lebih tinggi dan kurang sensitif terhadap outlier, seperti yang berlaku dalam latihan OpenCLIP, ia boleh mengambil masa beberapa hari sebelum masalah timbul, membuang masa pengiraan yang mahal.
Kedua-dua FP16 dan BF16 mempunyai kelebihan dan kekurangan. Had FP16 boleh membawa kepada latihan yang tidak stabil dan terhenti. Walau bagaimanapun, BF16 memberikan ketepatan yang lebih rendah dan mungkin mempunyai penumpuan yang lebih lemah. Jadi kami pasti ingin mengenal pasti model yang terdedah kepada ketidakstabilan FP16 pada awal latihan supaya kami boleh membuat keputusan termaklum sebelum ketidakstabilan berlaku. Jadi sekali lagi membandingkan model-model yang melakukan dan tidak mempamerkan ketidakstabilan latihan berikutnya, dua trend boleh didapati.

Kedua-dua model YOLO yang dilatih dalam FP16 dan model CLIP yang dilatih dalam BF16 menunjukkan bahawa kadar aliran bawah kecerunan biasanya kurang daripada 1%, dan dengan Ia stabil dari semasa ke semasa.

Model CLIP yang dilatih dalam FP16 mempunyai kadar aliran bawah 5-10% dalam 1000 langkah pertama latihan dan dari semasa ke semasa Menunjukkan trend menaik .
Jadi dengan menggunakan TCH untuk menjejak kadar aliran bawah kecerunan, kami boleh mengenal pasti arah aliran ketidakstabilan kecerunan yang lebih tinggi dalam tempoh 4-6 jam pertama latihan. Tukar kepada BF16 apabila trend ini diperhatikan.
Ringkasan
Latihan ketepatan hibrid ialah bahagian penting dalam melatih model asas berskala besar sedia ada, tetapi memerlukan perhatian khusus terhadap kestabilan berangka. Memahami keadaan dalaman model adalah penting untuk mendiagnosis apabila model menghadapi had jenis data ketepatan campuran. Dengan membalut model dengan TCH, adalah mungkin untuk menjejaki sama ada parameter atau kecerunan menghampiri had berangka dan melakukan perubahan latihan sebelum ketidakstabilan berlaku, yang berpotensi mengurangkan bilangan hari latihan yang tidak berjaya dijalankan.
Atas ialah kandungan terperinci Bagaimana untuk menyelesaikan batasan latihan ketepatan campuran model besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI