Model Bahasa Visual Skala Besar (LVLM) boleh meningkatkan prestasi dengan menskalakan model. Walau bagaimanapun, meningkatkan saiz parameter meningkatkan kos latihan dan inferens kerana pengiraan setiap token mengaktifkan semua parameter model.
Penyelidik dari Universiti Peking, Universiti Sun Yat-sen dan institusi lain bersama-sama mencadangkan strategi latihan baharu yang dipanggil MoE-Tuning untuk menyelesaikan masalah kemerosotan prestasi yang berkaitan dengan pembelajaran pelbagai mod dan jarang model. MoE-Tuning mampu membina model jarang dengan bilangan parameter yang mengejutkan tetapi kos pengiraan yang berterusan. Di samping itu, penyelidik juga mencadangkan seni bina LVLM jarang baharu berdasarkan MoE, yang dipanggil rangka kerja MoE-LLaVA. Dalam rangka kerja ini, hanya pakar k teratas diaktifkan melalui algoritma penghalaan, dan pakar selebihnya kekal tidak aktif. Dengan cara ini, rangka kerja MoE-LLaVA boleh menggunakan sumber rangkaian pakar dengan lebih cekap semasa proses penempatan. Hasil penyelidikan ini menyediakan penyelesaian baharu untuk menyelesaikan cabaran pembelajaran pelbagai mod dan jarang model model LVLM.

MoE-LLaVArse hanya mempunyai parameter pengaktifan 3B Walau bagaimanapun, ia bersamaan dengan LLaVA-1.5-7B pada pelbagai set data pemahaman visual, malah mengatasi LLaVA-1.5-13B dalam ujian penanda aras ilusi objek. Melalui MoE-LLaVA, kajian ini bertujuan untuk mewujudkan penanda aras bagi LVLM yang jarang dan memberikan pandangan berharga untuk penyelidikan masa depan bagi membangunkan sistem pembelajaran pelbagai mod yang lebih cekap dan berkesan. Pasukan MoE-LLaVA telah membuka semua data, kod dan model. . mengamalkan strategi latihan tiga peringkat. Seperti yang ditunjukkan dalam Rajah 2, pengekod penglihatan memproses imej input untuk mendapatkan urutan token visual. Lapisan unjuran digunakan untuk memetakan token visual ke dalam dimensi yang boleh diterima oleh LLM. Begitu juga, teks yang dipasangkan dengan imej ditayangkan melalui lapisan pembenaman perkataan untuk mendapatkan token teks urutan.
Fasa 1: Seperti yang ditunjukkan dalam Rajah 2, matlamat Fasa 1 adalah untuk menyesuaikan token visual kepada LLM dan memberi LLM keupayaan untuk memahami entiti dalam gambar. MoE-LLaVA menggunakan MLP untuk menayangkan token imej ke dalam domain input LLM, yang bermaksud bahawa tampung imej kecil dianggap sebagai token teks pseudo oleh LLM. Pada peringkat ini, LLM dilatih untuk menerangkan imej dan memahami semantik imej peringkat lebih tinggi. Lapisan MoE tidak akan digunakan pada LVLM pada peringkat ini.
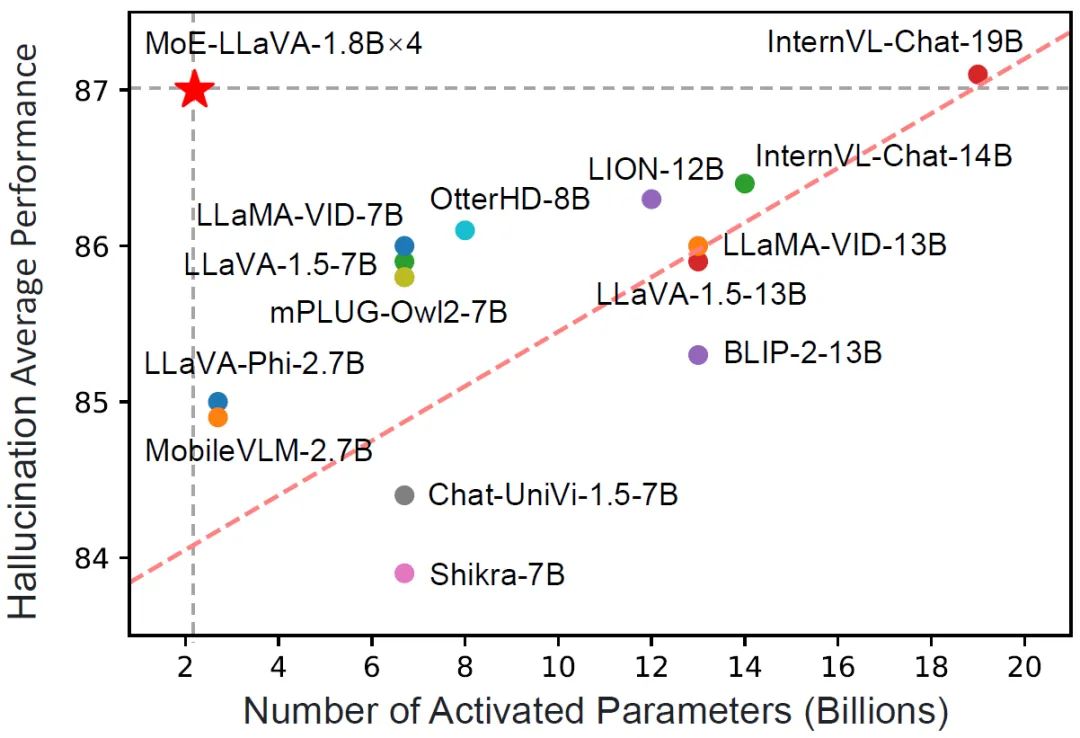
. LLM LVLM ditala untuk pemahaman pelbagai modal. Pada peringkat ini, penyelidikan menambah arahan yang lebih kompleks, termasuk tugas lanjutan seperti penaakulan logik gambar dan pengecaman teks, yang memerlukan model untuk mempunyai keupayaan pemahaman pelbagai mod yang lebih kukuh. Secara umumnya, LVLM model padat dilatih pada ketika ini Walau bagaimanapun, pasukan penyelidik mendapati bahawa ia adalah mencabar untuk menukar LLM kepada LVLM dan jarang model pada masa yang sama. Oleh itu, MoE-LLaVA akan menggunakan pemberat peringkat kedua sebagai permulaan peringkat ketiga untuk mengurangkan kesukaran pembelajaran model jarang. Fasa 3: MoE-LLaVA menyalin berbilang salinan FFN sebagai pemberat permulaan set pakar. Apabila token visual dan token teks dimasukkan ke dalam lapisan MoE, penghala akan mengira berat sepadan bagi setiap token dan pakar, dan kemudian setiap token akan dihantar kepada pakar paling sepadan teratas untuk diproses, dan akhirnya berdasarkan berat penghala Penjumlahan wajaran diagregatkan ke dalam output. Apabila pakar top-k diaktifkan, pakar yang selebihnya kekal tidak aktif, dan model ini membentuk MoE-LLaVA dengan kemungkinan laluan jarang yang tidak terhingga. EksperimenSeperti yang ditunjukkan dalam Rajah 4, memandangkan MoE-LLaVA ialah model jarang pertama berdasarkan LVLM yang dilengkapi dengan penghala lembut, model sebelumnya ini. Pasukan penyelidik mengesahkan prestasi MoE-LLaVA pada 5 tanda aras soalan dan jawapan imej, dan melaporkan jumlah parameter yang diaktifkan dan resolusi imej. Berbanding dengan kaedah SOTA LLaVA-1.5, MoE-LLaVA-2.7B×4 menunjukkan keupayaan pemahaman imej yang kukuh, dan prestasinya sangat hampir dengan LLaVA-1.5 pada 5 penanda aras. Antaranya, MoE-LLaVA menggunakan parameter pengaktifan jarang 3.6B dan melebihi LLaVA-1.5-7B pada SQAI sebanyak 1.9%. Perlu diingat bahawa disebabkan oleh struktur jarang MoE-LLaVA, hanya parameter pengaktifan 2.6B diperlukan untuk mengatasi sepenuhnya IDEFICS-80B.
Rajah 4 Prestasi MoE-LLaVA pada 9 penanda aras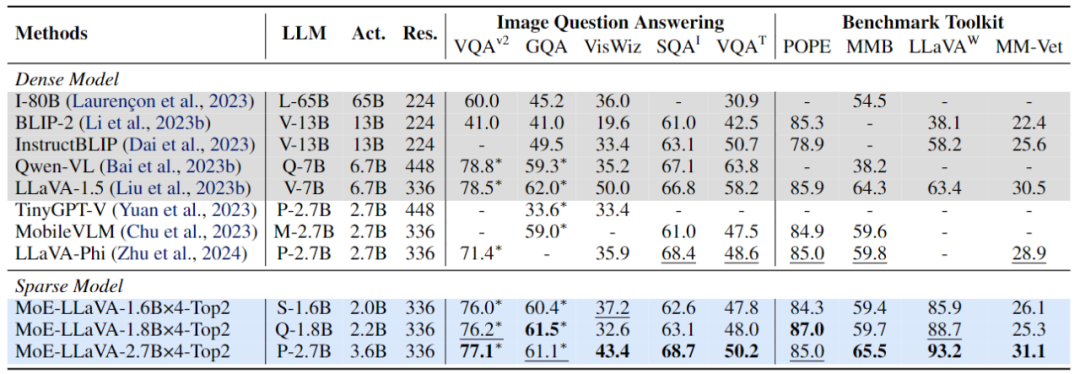
Selain itu, pasukan penyelidik juga memberi perhatian kepada model bahasa visual kecil yang baru-baru ini, Tiny.GPBBLaV × 4 melebihi TinyGPT-V masing-masing sebanyak 27.5% dan 10% dalam GQA dan VisWiz di bawah parameter pengaktifan yang setanding, yang menandakan keupayaan pemahaman kuat MoE-LLaVA dalam penglihatan semula jadi. Untuk mengesahkan keupayaan pemahaman pelbagai mod MoE-LLaVA secara lebih komprehensif, kajian ini menilai prestasi model pada 4 kit alat penanda aras. Kit alat penanda aras ialah kit alat untuk mengesahkan sama ada model boleh menjawab soalan dalam bahasa semula jadi Biasanya jawapannya terbuka dan tidak mempunyai templat tetap. Seperti yang ditunjukkan dalam Rajah 4, MoE-LLaVA-1.8B×4 mengatasi Qwen-VL, yang menggunakan resolusi imej yang lebih besar. Keputusan ini menunjukkan bahawa MoE-LLaVA, model yang jarang, boleh mencapai prestasi yang setanding atau bahkan melebihi model padat dengan parameter pengaktifan yang lebih sedikit. Figure 5 Prestasi Penilaian MOE-Llava mengenai Pengesanan Objek Halusinasi Kajian ini menggunakan saluran paip penilaian Paus untuk mengesahkan halusinasi objek MOE-Llava. . MoE -LLaVA mempamerkan prestasi terbaik, bermakna MoE-LLaVA cenderung menjana objek yang konsisten dengan imej yang diberikan. Khususnya, MoE-LLaVA-1.8B×4 mengatasi LLaVA dengan parameter pengaktifan 2.2B. Di samping itu, pasukan penyelidik mendapati bahawa nisbah ya bagi MoE-LLaVA berada dalam keadaan yang agak seimbang, yang menunjukkan bahawa model jarang MoE-LLaVA boleh membuat maklum balas yang betul berdasarkan masalah.
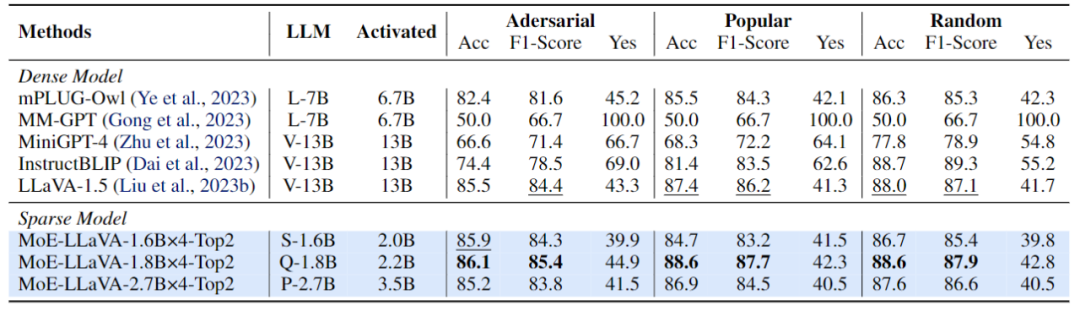
Rajah 6 Visualisasi beban pakar Rajah 6 menunjukkan beban pakar MoE-LLaVA-2.7B×4-A.Top2 Secara keseluruhan, semasa permulaan latihan, beban pakar dalam semua lapisan KPM adalah agak seimbang. Walau bagaimanapun, apabila model secara beransur-ansur menjadi jarang, beban pakar pada lapisan 17 hingga 27 tiba-tiba meningkat, malah meliputi hampir semua token. Untuk lapisan cetek 5-11, pakar 2, 3, dan 4 terutamanya bekerjasama. Perlu diingat bahawa Pakar 1 berfungsi hampir secara eksklusif pada lapisan 1-3 dan secara beransur-ansur berhenti daripada kerja apabila model semakin mendalam. Oleh itu, pakar MoE-LLaVA telah mempelajari corak tertentu yang membolehkan pembahagian kerja pakar mengikut peraturan tertentu.
Rajah 7 Visualisasi pengedaran modal Rajah 7 menunjukkan pengedaran modal pakar yang berbeza. Kajian mendapati bahawa taburan penghalaan teks dan imej adalah sangat serupa. Contohnya, apabila pakar 3 bekerja keras pada lapisan 17-27, perkadaran teks dan imej yang diproses olehnya adalah serupa. Ini menunjukkan bahawa MoE-LLaVA tidak mempunyai keutamaan yang jelas untuk modaliti. Kajian ini juga memerhatikan tingkah laku pakar pada tahap token dan menjejaki trajektori semua token dalam rangkaian jarang pada tugas hiliran. Untuk semua laluan teks dan imej yang diaktifkan, kajian ini menggunakan pengurangan dimensi PCA untuk mendapatkan 10 laluan utama, seperti yang ditunjukkan dalam Rajah 8. Pasukan penyelidik mendapati bahawa untuk token teks atau token imej yang tidak kelihatan, MoE-LLaVA sentiasa memilih untuk menghantar pakar 2 dan 3 untuk mengendalikan kedalaman model. Pakar 1 dan 4 cenderung berurusan dengan token yang dimulakan. Keputusan ini boleh membantu kami lebih memahami tingkah laku model jarang dalam pembelajaran pelbagai mod dan meneroka kemungkinan yang tidak diketahui. 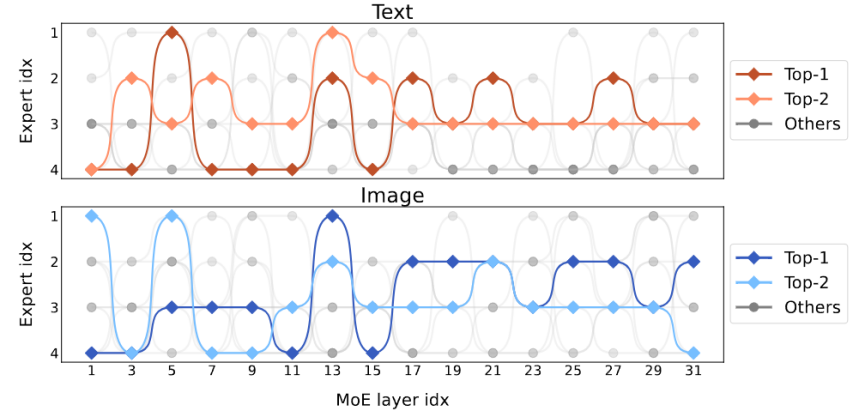
Rajah 8 Visualisasi laluan pengaktifanAtas ialah kandungan terperinci Jarang model besar berbilang modal, dan model 3B MoE-LLaVA adalah setanding dengan LLaVA-1.5-7B. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

