
Rumah >Peranti teknologi >AI >Tinjauan NeurIPS 2023: Tsinghua ToT mendorong model besar menjadi fokus
Tinjauan NeurIPS 2023: Tsinghua ToT mendorong model besar menjadi fokus

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-26 16:27:321407semak imbas
Baru-baru ini, sebagai salah satu daripada sepuluh blog teknologi terbaik di Amerika Syarikat, Latent Space telah menjalankan semakan dan ringkasan terpilih bagi persidangan NeurIPS 2023 yang lalu.
Dalam persidangan NeurIPS, sebanyak 3586 kertas kerja telah diterima, 6 daripadanya memenangi anugerah. Walaupun kertas-kertas yang memenangi anugerah ini mendapat banyak perhatian, kertas-kertas lain juga mempunyai kualiti dan potensi yang luar biasa. Malah, kertas-kertas ini mungkin meramalkan kejayaan besar seterusnya dalam AI.
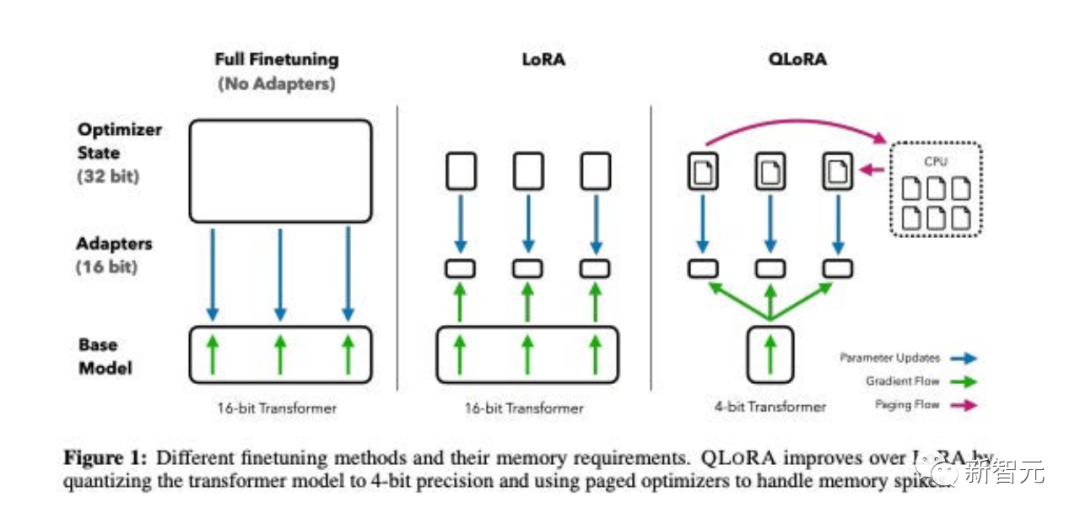
Kalau begitu mari kita lihat bersama-sama! . Kertas kerja ini mencadangkan QLoRA , versi LoRA yang lebih cekap memori tetapi lebih perlahan yang menggunakan beberapa helah pengoptimuman untuk menjimatkan memori.

Mereka memperhalusi model baharu, bernama Guanaco, dan melatihnya selama 24 jam pada hanya satu GPU, dan hasilnya mengatasi model sebelumnya pada penanda aras Vicuna.
 Pada masa yang sama, penyelidik juga telah membangunkan kaedah lain, seperti kuantifikasi LoRA 4-bit, dengan kesan yang sama. .
Pada masa yang sama, penyelidik juga telah membangunkan kaedah lain, seperti kuantifikasi LoRA 4-bit, dengan kesan yang sama. .
Dataset berbilang mod memainkan peranan penting dalam penemuan terbaru seperti CLIP, Stable Diffusion dan GPT-4, tetapi reka bentuknya tidak mendapat perhatian penyelidikan yang sama seperti seni bina model atau algoritma latihan.
Untuk menangani kekurangan ini dalam ekosistem pembelajaran mesin, penyelidik memperkenalkan DataComp, tempat ujian untuk eksperimen set data sekitar 12.8 bilion pasangan teks imej daripada kumpulan calon baharu Common Crawl.
Pengguna boleh bereksperimen dengan DataComp, mereka bentuk teknik penapisan baharu atau memilih sumber data baharu dan menilainya dengan menjalankan kod latihan CLIP piawai dan menguji model yang terhasil pada 38 set ujian hiliran set data baharu.
Hasilnya menunjukkan bahawa penanda aras terbaik DataComp-1B, yang membolehkan melatih model CLIP ViT-L/14 dari awal, mencapai ketepatan sampel sifar sebanyak 79.2% pada ImageNet, yang lebih baik daripada CLIP ViT-L OpenAI /14 Model ini mengatasi prestasi sebanyak 3.7 mata peratusan, membuktikan bahawa aliran kerja DataComp menghasilkan set latihan yang lebih baik. . e 01868827a9af
dalam kertas ini , penyelidik membentangkan percubaan pertama untuk menjana data mengikut arahan imej-bahasa multimodal menggunakan GPT-4, yang bergantung sepenuhnya pada bahasa.
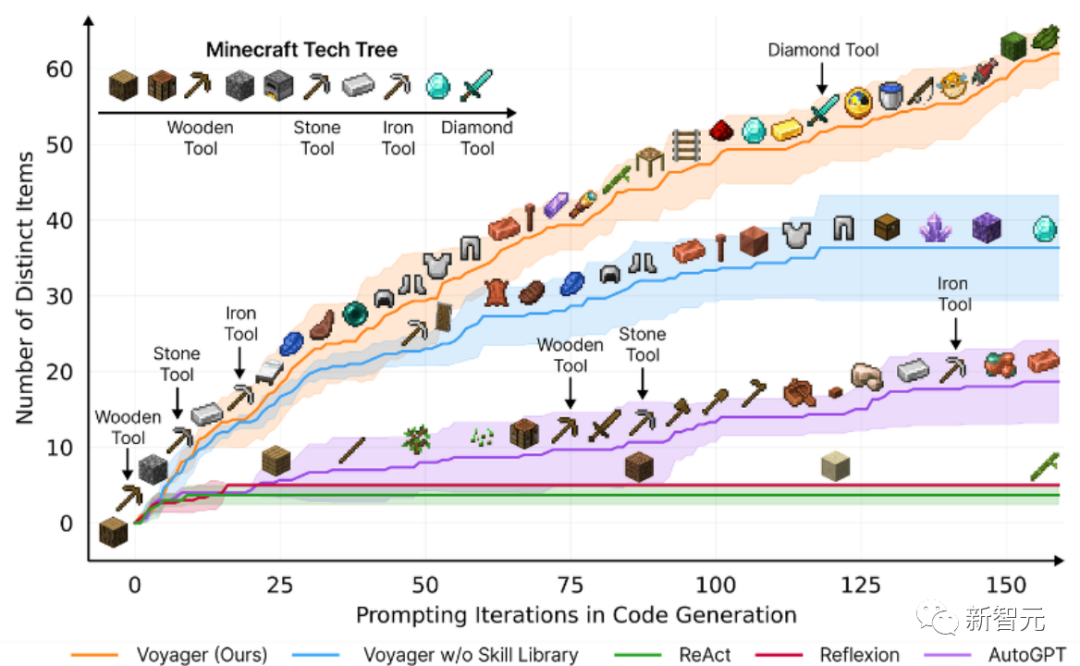
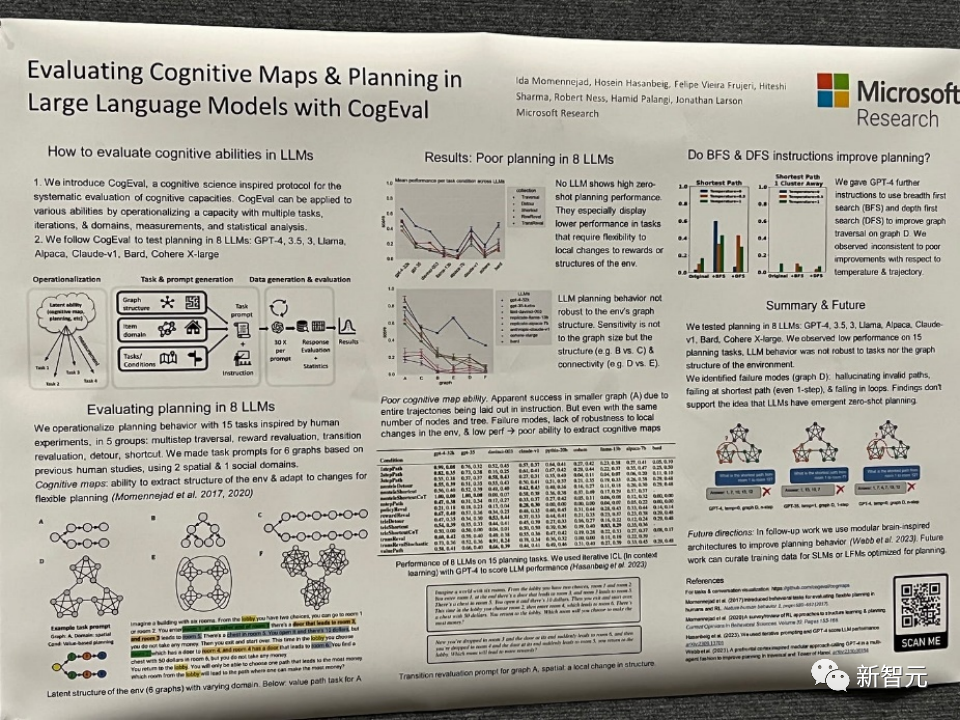
Eksperimen awal menunjukkan bahawa LLaVA menunjukkan keupayaan sembang pelbagai mod yang mengagumkan, kadangkala mempamerkan gelagat GPT-4 berbilang modal pada imej/arahan yang tidak kelihatan dan mengikut arahan berbilang mod sintetik pada data Set mencapai skor relatif 85.1% berbanding dengan GPT -4. Sinergi LLaVA dan GPT-4 mencapai ketepatan terkini 92.53% apabila memperhalusi menjawab soalan saintifik. . Untuk mengatasi cabaran ini, penyelidik memperkenalkan rangka kerja inferens model bahasa baharu, Tree of Thoughts (ToT), yang menyamaratakan pendekatan Rantaian Pemikiran yang popular dalam mendorong model bahasa dan membolehkan penerokaan teks yang konsisten dijalankan pada unit (idea) yang berfungsi sebagai langkah perantaraan dalam menyelesaikan masalah. ToT membolehkan model bahasa membuat keputusan yang disengajakan dengan mempertimbangkan pelbagai laluan penaakulan yang berbeza dan pilihan menilai sendiri untuk menentukan langkah seterusnya, melihat ke hadapan atau ke belakang apabila perlu untuk membuat pilihan global. Dalam kertas kerja ini, penyelidik menunjukkan bahawa model bahasa boleh mengajar diri mereka sendiri untuk menggunakan alat luaran melalui API mudah, dan mencapai gabungan terbaik antara keduanya. Mereka memperkenalkan Toolformer, model yang dilatih untuk menentukan API yang hendak dipanggil, masa untuk memanggilnya, parameter apa yang perlu dilalui dan cara terbaik untuk menggabungkan keputusan ke dalam ramalan token masa hadapan. Ini dilakukan dengan cara penyeliaan sendiri, hanya memerlukan sebilangan kecil demo bagi setiap API. Mereka menyepadukan pelbagai alat, termasuk kalkulator, sistem soal jawab, enjin carian, sistem terjemahan dan kalendar. Toolformer mencapai prestasi sifar pukulan yang dipertingkatkan dengan ketara pada pelbagai tugas hiliran sambil bersaing dengan model yang lebih besar, tanpa mengorbankan keupayaan pemodelan bahasa terasnya. Tajuk kertas: Voyager: Ejen Terwujud Terbuka dengan Model Bahasa Besar Alamat kertas: https://arxiv.pdf.05/ Voyager terdiri daripada tiga komponen utama: Pelajaran automatik yang direka untuk memaksimumkan penerokaan, Perpustakaan kemahiran kod boleh laku yang semakin berkembang untuk menyimpan dan mendapatkan semula tingkah laku yang kompleks, Mekanisme segera lelaran baharu yang menyepadukan maklum balas alam sekitar, ralat pelaksanaan dan pengesahan kendiri untuk menambah baik program. Voyager berinteraksi dengan GPT-4 melalui pertanyaan kotak hitam, mengelakkan keperluan untuk memperhalusi parameter model. Berdasarkan penyelidikan empirikal, Voyager menunjukkan keupayaan pembelajaran sepanjang hayat yang kukuh dalam konteks persekitaran dan menunjukkan kecekapan unggul dalam bermain Minecraft. Ia mendapat akses kepada item unik 3.3x lebih tinggi daripada tahap teknologi sebelumnya, bergerak 2.3x lebih lama dan membuka kunci pencapaian pokok teknologi utama 15.3x lebih cepat daripada tahap teknologi sebelumnya. Walau bagaimanapun, sementara Voyager dapat menggunakan perpustakaan kemahiran yang dipelajari untuk menyelesaikan tugasan baru dari awal dalam dunia Minecraft baharu, teknik lain sukar untuk digeneralisasikan. Paper Tajuk: Menilai Peta Kognitif dan Perancangan dalam Model Bahasa Besar dengan Alamat Cogeval paper: https://openreview.net/pdf?id=vtkgvgcge3 Kertas kerja ini mula-mula mencadangkan CogEval, protokol yang diilhamkan oleh sains kognitif untuk menilai secara sistematik keupayaan kognitif model bahasa besar. Kedua, kertas kerja menggunakan sistem CogEval untuk menilai lapan LLM (OpenAI GPT-4, GPT-3.5-turbo-175B, davinci-003-175B, Google Bard, Cohere-xlarge-52.4B, Anthropic Claude-175B - 52B, LLaMA-13B dan Alpaca-7B) keupayaan pemetaan dan perancangan kognitif. Gesaan tugas adalah berdasarkan eksperimen manusia dan tidak terdapat dalam set latihan LLM. Penyelidikan telah mendapati bahawa walaupun LLM menunjukkan keupayaan yang jelas dalam beberapa tugasan perancangan dengan struktur yang lebih mudah, apabila tugas menjadi kompleks, LLM akan jatuh ke dalam titik buta, termasuk halusinasi trajektori tidak sah dan jatuh ke dalam gelung. Penemuan ini tidak menyokong idea bahawa LLM mempunyai keupayaan perancangan plug-and-play. Mungkin LLM tidak memahami struktur hubungan yang mendasari di sebalik masalah perancangan, iaitu peta kognitif, dan menghadapi masalah membuka trajektori terarah matlamat berdasarkan struktur asas. . ini ialah ketidakupayaan mereka untuk melakukan penaakulan berasaskan kandungan dan membuat beberapa penambahbaikan. Pertama, hanya menjadikan parameter SSM sebagai fungsi input boleh menangani kelemahan mod diskretnya, membolehkan model secara selektif menyebarkan atau melupakan maklumat sepanjang dimensi panjang jujukan bergantung pada token semasa. Mamba berprestasi baik dalam kelajuan inferens (5x lebih tinggi daripada Transformers) dan menskala secara linear dengan panjang jujukan, meningkatkan prestasi pada data sebenar sehingga jujukan jutaan panjang. Sebagai tulang belakang model jujukan universal, Mamba telah mencapai prestasi terkini dalam pelbagai bidang termasuk bahasa, audio dan genomik. Dari segi pemodelan bahasa, model Mamba-1.4B mengatasi model Transformers dengan saiz yang sama dalam penilaian pra-latihan dan hiliran, dan menyaingi model Transformersnya dua kali ganda saiz. Walaupun kertas kerja ini tidak memenangi anugerah pada tahun 2023, seperti Mamba, sebagai model teknikal yang boleh merevolusikan seni bina model bahasa, masih terlalu awal untuk menilai kesannya. Bagaimana keadaan NeurIPS tahun depan, dan bagaimanakah bidang kecerdasan buatan dan sistem maklumat saraf akan berkembang pada tahun 2024 Walaupun terdapat banyak pendapat, siapa yang pasti? Sama-sama kita tunggu dan lihat.  Model bahasa semakin digunakan untuk menyelesaikan masalah umum dalam pelbagai tugas, tetapi masih terhad kepada proses membuat keputusan peringkat token, kiri ke kanan semasa inferens. Ini bermakna mereka mungkin berprestasi rendah dalam tugas yang memerlukan penerokaan, pandangan jauh strategik, atau di mana pembuatan keputusan awal memainkan peranan penting.
Model bahasa semakin digunakan untuk menyelesaikan masalah umum dalam pelbagai tugas, tetapi masih terhad kepada proses membuat keputusan peringkat token, kiri ke kanan semasa inferens. Ini bermakna mereka mungkin berprestasi rendah dalam tugas yang memerlukan penerokaan, pandangan jauh strategik, atau di mana pembuatan keputusan awal memainkan peranan penting. 


 Pengarang menegaskan bahawa banyak seni bina masa sub-linear semasa, seperti perhatian linear, lilitan berpagar dan model berulang, serta model ruang keadaan berstruktur (SSM), bertujuan untuk menyelesaikan ketidakcekapan pengiraan Transformer apabila memproses jujukan panjang. Walau bagaimanapun, model ini tidak berprestasi sebaik model perhatian pada domain penting seperti bahasa. Pengarang percaya bahawa kelemahan utama jenis
Pengarang menegaskan bahawa banyak seni bina masa sub-linear semasa, seperti perhatian linear, lilitan berpagar dan model berulang, serta model ruang keadaan berstruktur (SSM), bertujuan untuk menyelesaikan ketidakcekapan pengiraan Transformer apabila memproses jujukan panjang. Walau bagaimanapun, model ini tidak berprestasi sebaik model perhatian pada domain penting seperti bahasa. Pengarang percaya bahawa kelemahan utama jenis 

Atas ialah kandungan terperinci Tinjauan NeurIPS 2023: Tsinghua ToT mendorong model besar menjadi fokus. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!