
Rumah >Peranti teknologi >AI >Model yang lebih berguna memerlukan 'pemikiran langkah demi langkah' yang lebih mendalam daripada hanya 'pemikiran langkah demi langkah' yang tidak mencukupi
Model yang lebih berguna memerlukan 'pemikiran langkah demi langkah' yang lebih mendalam daripada hanya 'pemikiran langkah demi langkah' yang tidak mencukupi

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-25 14:18:191000semak imbas
Kemunculan model bahasa besar (LLM) baru-baru ini dan strategi pembayang lanjutannya bermakna penyelidikan model bahasa telah mencapai kemajuan yang ketara, terutamanya dalam tugas pemprosesan bahasa semula jadi klasik (NLP). Satu inovasi penting ialah teknologi dorongan Rantaian Pemikiran (CoT), yang dipuji kerana keupayaannya dalam penyelesaian masalah pelbagai langkah. Teknologi CoT mengikut penaakulan jujukan manusia dan menunjukkan prestasi cemerlang dalam pelbagai cabaran, termasuk tugasan merentas domain, generalisasi jangka panjang dan merentas bahasa. Dengan pendekatan penaakulan yang logik, langkah demi langkah, CoT menyediakan kebolehtafsiran penting dalam senario penyelesaian masalah yang kompleks.
Walaupun CoT telah mencapai kemajuan yang besar, komuniti penyelidik masih belum mencapai kata sepakat mengenai mekanisme khusus dan sebab keberkesanannya. Jurang pengetahuan ini bermakna peningkatan prestasi CoT kekal sebagai wilayah yang belum dipetakan. Pada masa ini, percubaan-dan-ralat ialah cara utama untuk meneroka penambahbaikan CoT, kerana penyelidik tidak mempunyai metodologi yang sistematik dan hanya boleh bergantung pada tekaan dan percubaan. Walau bagaimanapun, ini juga bermakna peluang penyelidikan penting wujud dalam bidang ini: membangunkan pemahaman yang mendalam dan berstruktur tentang kerja dalaman CoT. Pencapaian matlamat ini bukan sahaja akan menghilangkan proses CoT semasa, tetapi juga membuka jalan untuk aplikasi yang lebih dipercayai dan cekap bagi teknik ini dalam pelbagai tugas NLP yang kompleks.
Penyelidikan oleh penyelidik dari Northwestern University, University of Liverpool, dan Institut Teknologi New Jersey meneroka lebih lanjut hubungan antara panjang langkah penaakulan dan ketepatan kesimpulan untuk membantu orang lebih memahami cara menyelesaikan pemprosesan bahasa semula jadi (NLP) dengan berkesan ) masalah. Kajian ini meneroka sama ada langkah inferens ialah bahagian paling kritikal dalam gesaan yang membolehkan teks terbuka berterusan (CoT) berfungsi. Dalam eksperimen, penyelidik mengawal pembolehubah dengan ketat, terutamanya apabila memperkenalkan langkah penaakulan baharu, untuk memastikan tiada pengetahuan tambahan diperkenalkan. Dalam percubaan sampel sifar, penyelidik melaraskan gesaan awal daripada "Sila fikir langkah demi langkah" kepada "Sila fikir langkah demi langkah dan fikirkan sebanyak mungkin langkah yang mungkin." Untuk masalah sampel kecil, para penyelidik mereka bentuk eksperimen yang memanjangkan langkah penaakulan asas sambil mengekalkan semua faktor lain yang tetap. Melalui eksperimen ini, penyelidik mendapati korelasi antara panjang langkah penaakulan dan ketepatan kesimpulan. Lebih khusus lagi, peserta cenderung untuk memberikan kesimpulan yang lebih tepat apabila gesaan meminta mereka memikirkan lebih banyak langkah. Ini menunjukkan bahawa apabila menyelesaikan masalah NLP, ketepatan penyelesaian masalah boleh dipertingkatkan dengan melanjutkan langkah penaakulan. Penyelidikan ini sangat penting untuk pemahaman yang mendalam tentang cara masalah NLP diselesaikan, dan menyediakan panduan berguna untuk mengoptimumkan dan menambah baik teknologi NLP selanjutnya.

- Tajuk kertas: Kesan Panjang Langkah Penaakulan terhadap Model Bahasa Besar
- Pautan kertas: https://arxiv.org.pdf
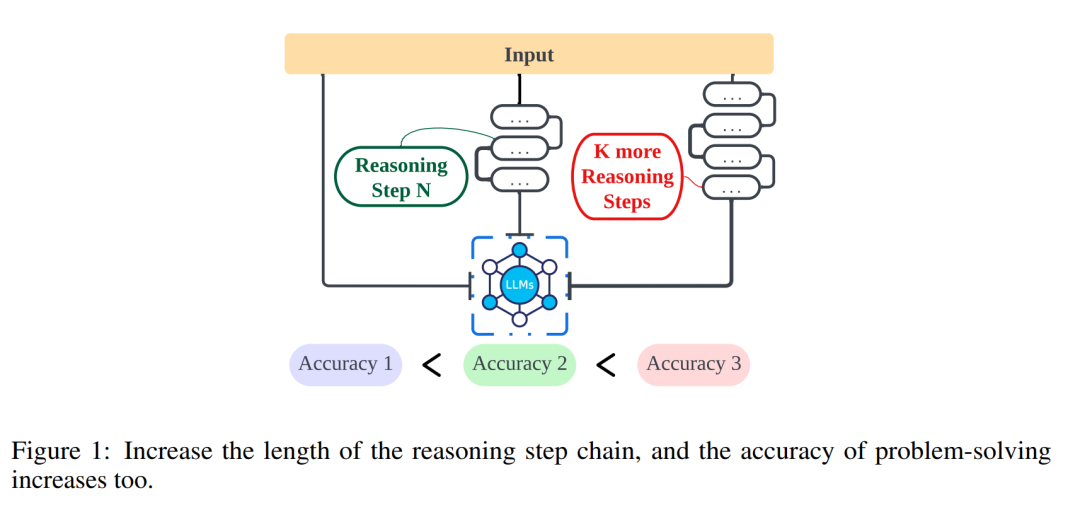
Penemuan utama artikel ini adalah seperti berikut:
Para penyelidik menggunakan analisis untuk mengkaji hubungan antara langkah penaakulan dan prestasi segera CoT. Andaian teras pendekatan mereka ialah langkah bersiri adalah komponen paling kritikal bagi isyarat CoT semasa inferens. Langkah-langkah ini membolehkan model bahasa menggunakan lebih logik untuk penaakulan apabila menjana kandungan balasan. Untuk menguji idea ini, penyelidik mereka bentuk eksperimen untuk mengubah proses penaakulan CoT dengan mengembangkan dan memampatkan langkah penaakulan asas secara berturut-turut. Pada masa yang sama, mereka mengekalkan semua faktor lain tetap. Khususnya, penyelidik hanya mengubah bilangan langkah penaakulan secara sistematik tanpa memperkenalkan kandungan penaakulan baharu atau memadam kandungan penaakulan sedia ada. Di bawah mereka menilai isyarat CoT sifar dan beberapa pukulan. Keseluruhan proses eksperimen ditunjukkan dalam Rajah 2. Melalui pendekatan analisis pembolehubah terkawal ini, para penyelidik menjelaskan bagaimana CoT mempengaruhi keupayaan LLM untuk menjana tindak balas yang kukuh secara logik. Analisis CoT sampel sifar Dalam senario sampel sifar, penyelidik menukar gesaan awal daripada "Sila fikir langkah demi langkah" kepada "Sila fikirkan langkah demi langkah" fikirkan sebanyak mungkin penyelesaian "langkah". Perubahan ini dibuat kerana tidak seperti persekitaran CoT beberapa pukulan, pengguna tidak boleh memperkenalkan langkah inferens tambahan semasa penggunaan. Dengan menukar gesaan awal, para penyelidik membimbing LLM untuk berfikir secara lebih luas. Kepentingan pendekatan ini terletak pada keupayaannya untuk meningkatkan ketepatan model tanpa memerlukan latihan tambahan atau kaedah pengoptimuman dipacu contoh tambahan yang tipikal dalam senario beberapa pukulan. Strategi penghalusan ini memastikan proses inferens yang lebih komprehensif dan terperinci, meningkatkan prestasi model dengan ketara di bawah keadaan sampel sifar. Analisis CoT sampel kecil Bahagian ini akan mengubah suai rantai inferens dalam CoT dengan menambah atau memampatkan langkah inferens. Matlamatnya adalah untuk mengkaji bagaimana perubahan dalam struktur penaakulan mempengaruhi keputusan LLM. Semasa pengembangan langkah inferens, penyelidik perlu mengelak daripada memperkenalkan sebarang maklumat baharu berkaitan tugasan. Dengan cara ini, langkah penaakulan menjadi satu-satunya pembolehubah kajian. Untuk tujuan ini, penyelidik mereka strategi penyelidikan berikut untuk melanjutkan langkah inferens aplikasi LLM yang berbeza. Orang sering mempunyai corak tetap dalam cara mereka berfikir tentang masalah, seperti mengulangi masalah berulang kali untuk mendapatkan pemahaman yang lebih mendalam, mencipta persamaan matematik untuk mengurangkan beban ingatan, menganalisis makna perkataan dalam masalah untuk membantu memahami topik, meringkaskan keadaan semasa untuk memudahkan Penerangan tentang topik. Berdasarkan inspirasi CoT sampel sifar dan Auto-CoT, penyelidik menjangkakan proses CoT menjadi model piawai dan memperoleh hasil yang betul dengan mengehadkan arah pemikiran CoT di bahagian yang segera. Teras kaedah ini adalah untuk mensimulasikan proses pemikiran manusia dan membentuk semula rantai pemikiran. Lima strategi segera yang biasa diberikan dalam Jadual 6. Secara umum, strategi masa nyata dalam artikel ini ditunjukkan dalam model. Apa yang ditunjukkan dalam Jadual 1 adalah satu contoh, dan contoh empat strategi lain boleh dilihat dalam kertas asal. Hubungan antara langkah inferens dan ketepatan Jadual 2 membandingkan penggunaan set data 15-6turbo-3 ketepatan. Terima kasih kepada penyelidik yang dapat menyeragamkan proses rantaian pemikiran, maka adalah mungkin untuk mengukur peningkatan ketepatan dengan menambah langkah-langkah kepada proses asas CoT. Keputusan eksperimen ini boleh menjawab soalan yang dikemukakan sebelum ini: Apakah hubungan antara langkah inferens dengan prestasi CoT? Percubaan ini adalah berdasarkan model GPT-3.5-turbo-1106. Para penyelidik mendapati bahawa proses CoT yang berkesan, seperti menambah sehingga enam langkah tambahan proses pemikiran kepada proses CoT, akan meningkatkan keupayaan penaakulan model bahasa yang besar, dan ini ditunjukkan dalam semua set data. Dalam erti kata lain, penyelidik mendapati hubungan linear tertentu antara ketepatan dan kerumitan CoT. Impak jawapan yang salah Adakah langkah inferens satu-satunya faktor yang mempengaruhi prestasi LLM? Para penyelidik membuat percubaan berikut. Tukar satu langkah segera kepada huraian yang salah dan lihat jika ia menjejaskan rantaian pemikiran. Untuk percubaan ini, kami menambahkan ralat pada semua gesaan. Lihat Jadual 3 untuk contoh khusus. Untuk masalah jenis aritmetik, walaupun salah satu keputusan yang cepat terpesong, kesan ke atas rantaian pemikiran dalam proses penaakulan akan menjadi minimum. Oleh itu, penyelidik percaya bahawa apabila menyelesaikan masalah jenis aritmetik, bahasa yang besar model adalah sangat penting untuk gesaan Terdapat lebih banyak perkara yang perlu dipelajari dalam rantaian model mental daripada dalam satu pengiraan. Untuk masalah logik seperti data syiling, sisihan dalam keputusan segera selalunya akan menyebabkan keseluruhan rantai pemikiran berpecah. Para penyelidik juga menggunakan GPT-3.5-turbo-1106 untuk melengkapkan percubaan ini dan menjamin prestasi berdasarkan bilangan langkah yang optimum untuk setiap set data yang diperoleh daripada eksperimen sebelumnya. Keputusan ditunjukkan dalam Rajah 4. Langkah penaakulan mampat Percubaan sebelum ini telah menunjukkan bahawa menambah langkah inferens boleh meningkatkan ketepatan inferens LLM. Jadi adakah memampatkan langkah inferens asas menjejaskan prestasi LLM dalam masalah sampel kecil? Untuk tujuan ini, penyelidik menjalankan eksperimen mampatan langkah inferens dan menggunakan teknik yang digariskan dalam persediaan eksperimen untuk memekatkan proses inferens menjadi Auto CoT dan Few-Shot-CoT untuk mengurangkan bilangan langkah inferens. Keputusan ditunjukkan dalam Rajah 5. Keputusan menunjukkan bahawa prestasi model menurun dengan ketara dan kembali ke tahap yang pada asasnya bersamaan dengan kaedah sampel sifar. Keputusan ini seterusnya menunjukkan bahawa peningkatan langkah inferens CoT boleh meningkatkan prestasi CoT dan begitu juga sebaliknya. . Para penyelidik mengkaji purata bilangan langkah inferens yang digunakan dalam pelbagai model, termasuk teks-davinci-002, GPT-3.5-turbo-1106 dan GPT-4. Purata langkah inferens yang diperlukan untuk setiap model untuk mencapai prestasi puncak telah dikira melalui eksperimen pada GSM8K. Antara 8 set data, set data ini mempunyai perbezaan prestasi terbesar dengan text-davinci-002, GPT-3.5-turbo-1106 dan GPT-4. Dapat dilihat bahawa dalam model text-davinci-002 dengan prestasi awal yang paling teruk, strategi yang dicadangkan dalam artikel ini mempunyai kesan peningkatan yang paling tinggi. Keputusan ditunjukkan dalam Rajah 6. Impak masalah dalam contoh kerja kolaboratif
Apakah kesan masalah terhadap keupayaan penaakulan LLM? Para penyelidik ingin meneroka sama ada menukar alasan CoT akan menjejaskan prestasi CoT. Memandangkan artikel ini terutamanya mengkaji kesan langkah inferens ke atas prestasi, penyelidik perlu mengesahkan bahawa masalah itu sendiri tidak mempunyai kesan ke atas prestasi. Oleh itu, penyelidik memilih set data MultiArith dan GSM8K dan dua kaedah CoT (auto-CoT dan few-shot-CoT) untuk menjalankan eksperimen dalam GPT-3.5-turbo-1106. Pendekatan eksperimen kertas ini melibatkan pengubahsuaian yang disengajakan kepada sampel masalah dalam set data matematik ini, seperti menukar kandungan soalan dalam Jadual 4. Perlu diperhatikan bahawa pemerhatian awal menunjukkan bahawa pengubahsuaian kepada masalah itu sendiri mempunyai kesan yang paling kecil terhadap prestasi antara beberapa faktor, seperti yang ditunjukkan dalam Jadual 5.
Untuk butiran lanjut, sila baca kertas asal.
Kaedah Penyelidikan
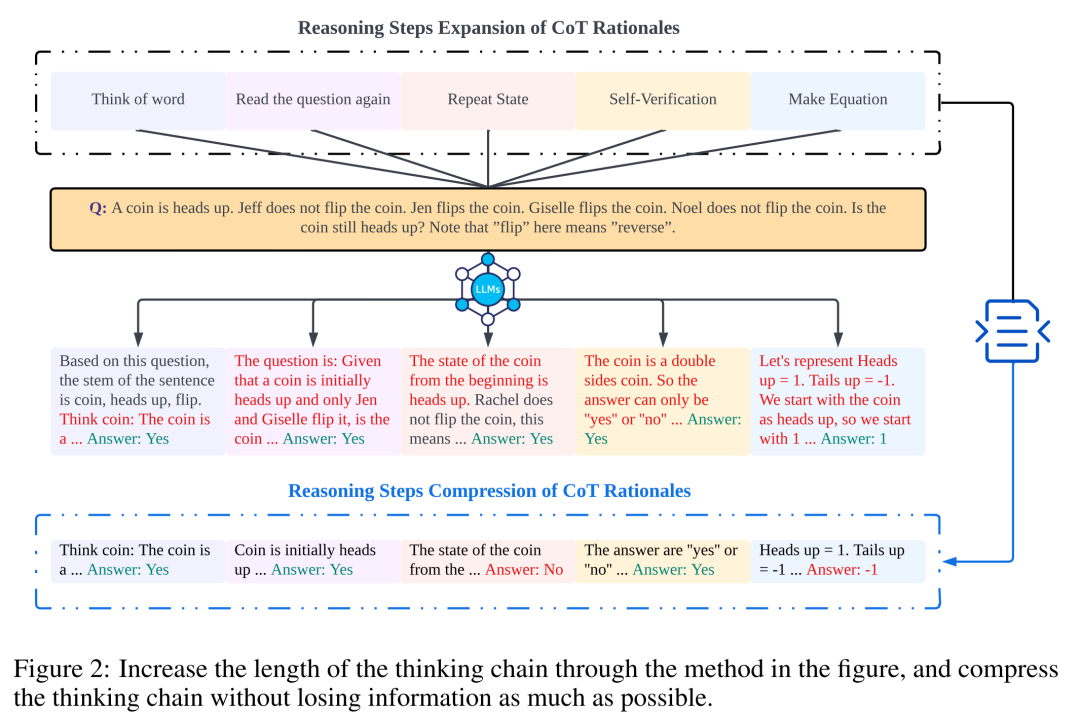


Eksperimen dan keputusan
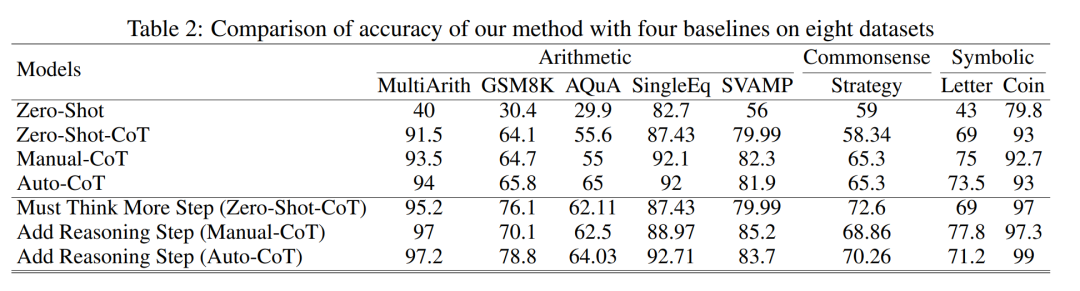
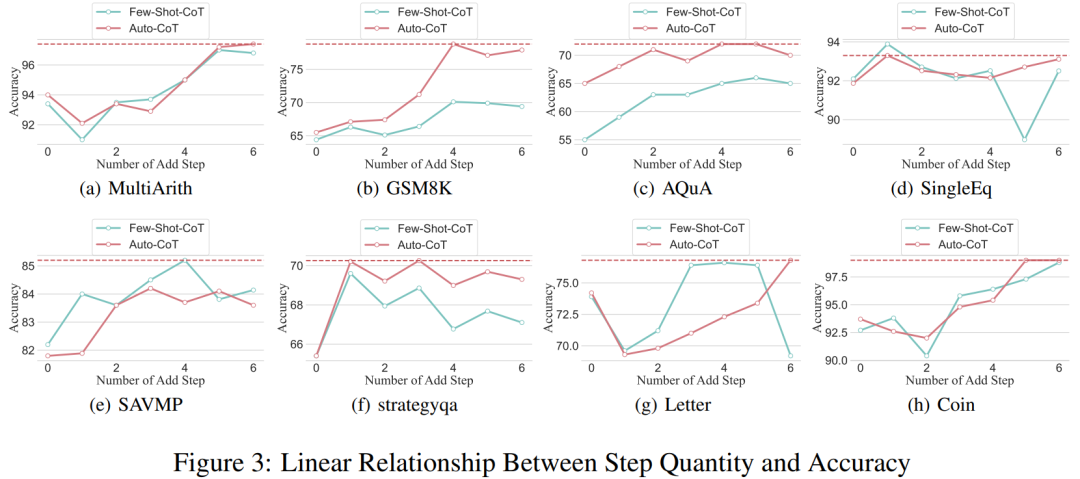

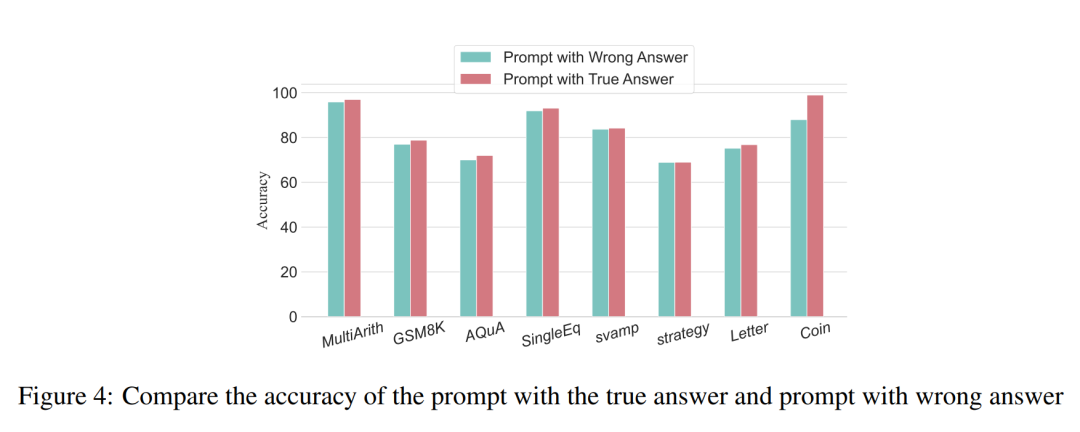
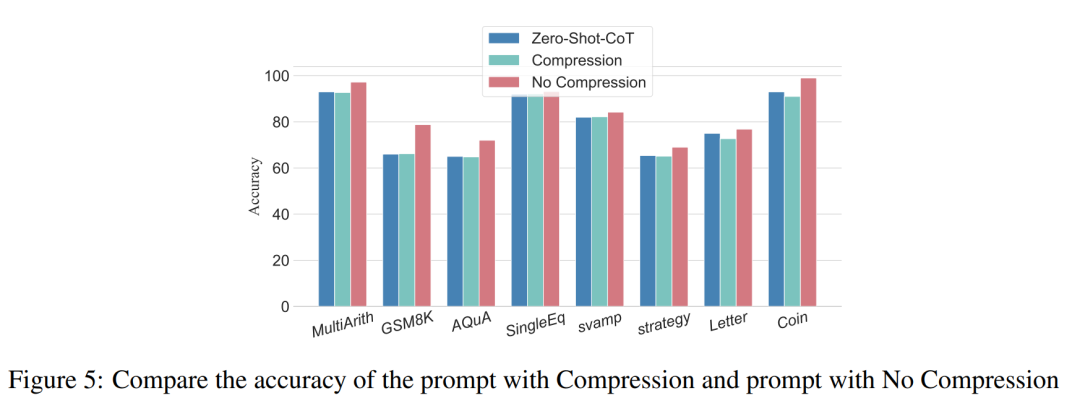
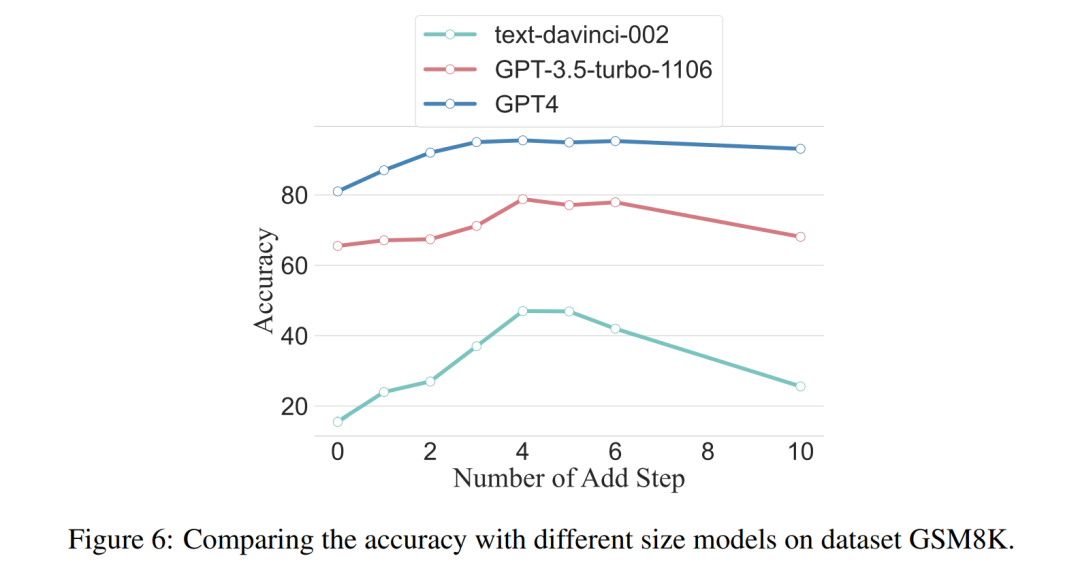
 Dapatan awal ini menunjukkan bahawa panjang langkah dalam proses penaakulan adalah faktor paling penting yang mempengaruhi keupayaan penaakulan model besar, dan masalah itu sendiri bukanlah pengaruh terbesar.
Dapatan awal ini menunjukkan bahawa panjang langkah dalam proses penaakulan adalah faktor paling penting yang mempengaruhi keupayaan penaakulan model besar, dan masalah itu sendiri bukanlah pengaruh terbesar.
Atas ialah kandungan terperinci Model yang lebih berguna memerlukan 'pemikiran langkah demi langkah' yang lebih mendalam daripada hanya 'pemikiran langkah demi langkah' yang tidak mencukupi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!