
Rumah >Peranti teknologi >AI >Kai-Fu Lee mengambil bahagian dalam Zero One Wish, yang mengeluarkan model besar berbilang modal sumber terbuka bertaraf dunia.
Kai-Fu Lee mengambil bahagian dalam Zero One Wish, yang mengeluarkan model besar berbilang modal sumber terbuka bertaraf dunia.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-25 11:09:051165semak imbas
Mengetuai dua senarai berwibawa dalam bahasa Cina dan Inggeris, Kai-Fu Lee menyerahkan model besar berbilang modalhelaian jawapan!
Ia kurang daripada tiga bulan sejak keluaran model besar sumber terbuka pertamanya Yi-34B dan Yi-6B.

Model ini dipanggil Yi Vision Language(Yi-VL), dan kini secara rasmi dibuka kepada dunia.
Kedua-duanya tergolong dalam siri Yi dan juga mempunyai dua versi:
Yi-VL-34B dan Yi-VL-6B.
Mari kita lihat dua contoh terlebih dahulu untuk mengalami prestasi Yi-VL dalam pelbagai senario seperti dialog grafik:

Yi-VL membuat analisis terperinci tentang keseluruhan gambar, bukan sahaja menerangkan kandungan dan juga "siling" dijaga.
Dalam bahasa Cina, Yi-VL juga boleh menyatakan dengan jelas dan tepat:

Selain itu, keputusan ujian rasmi turut diberikan.
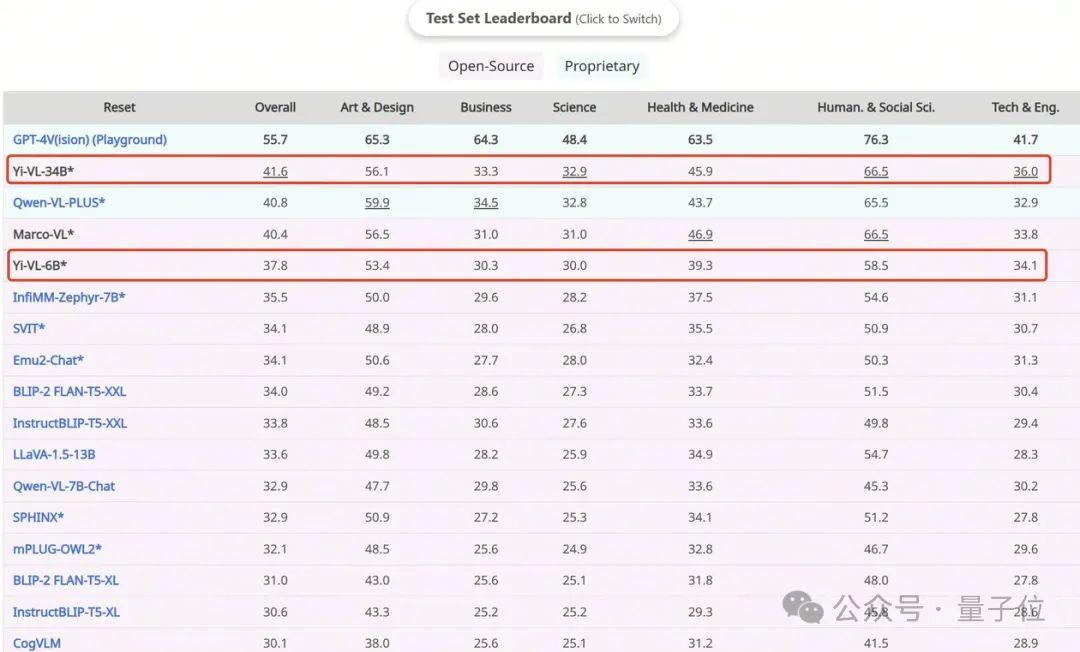
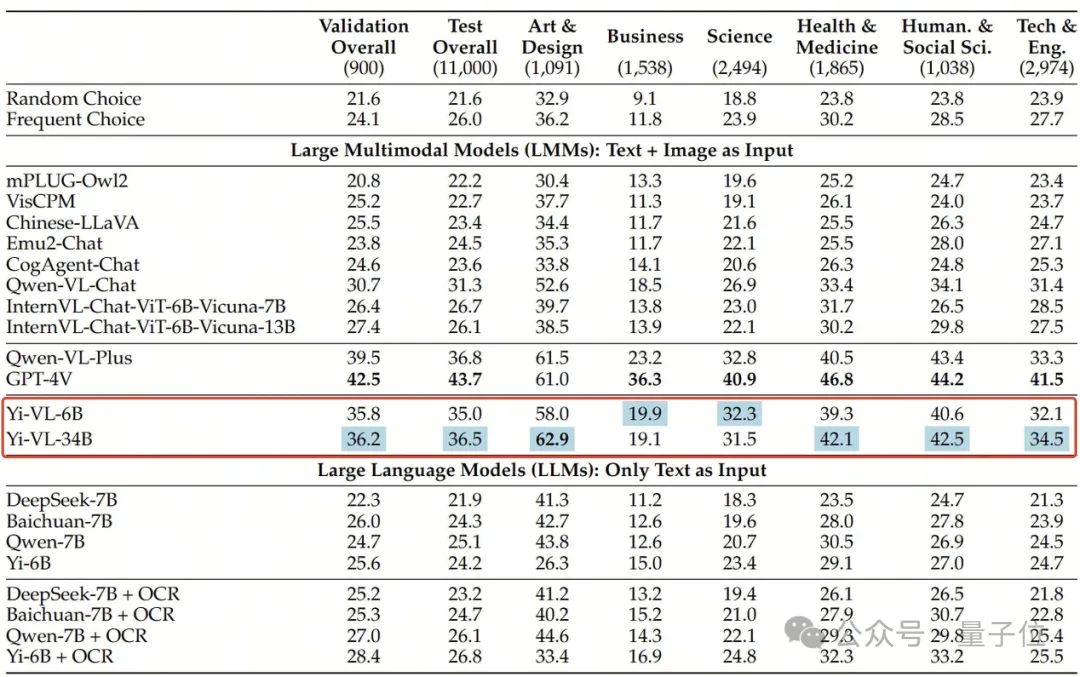
Yi-VL-34B mempunyai ketepatan 41.6% pada set data Inggeris MMMU, kedua selepas GPT-4V dengan ketepatan 55.7%, mengatasi siri model berbilang modal yang besar.
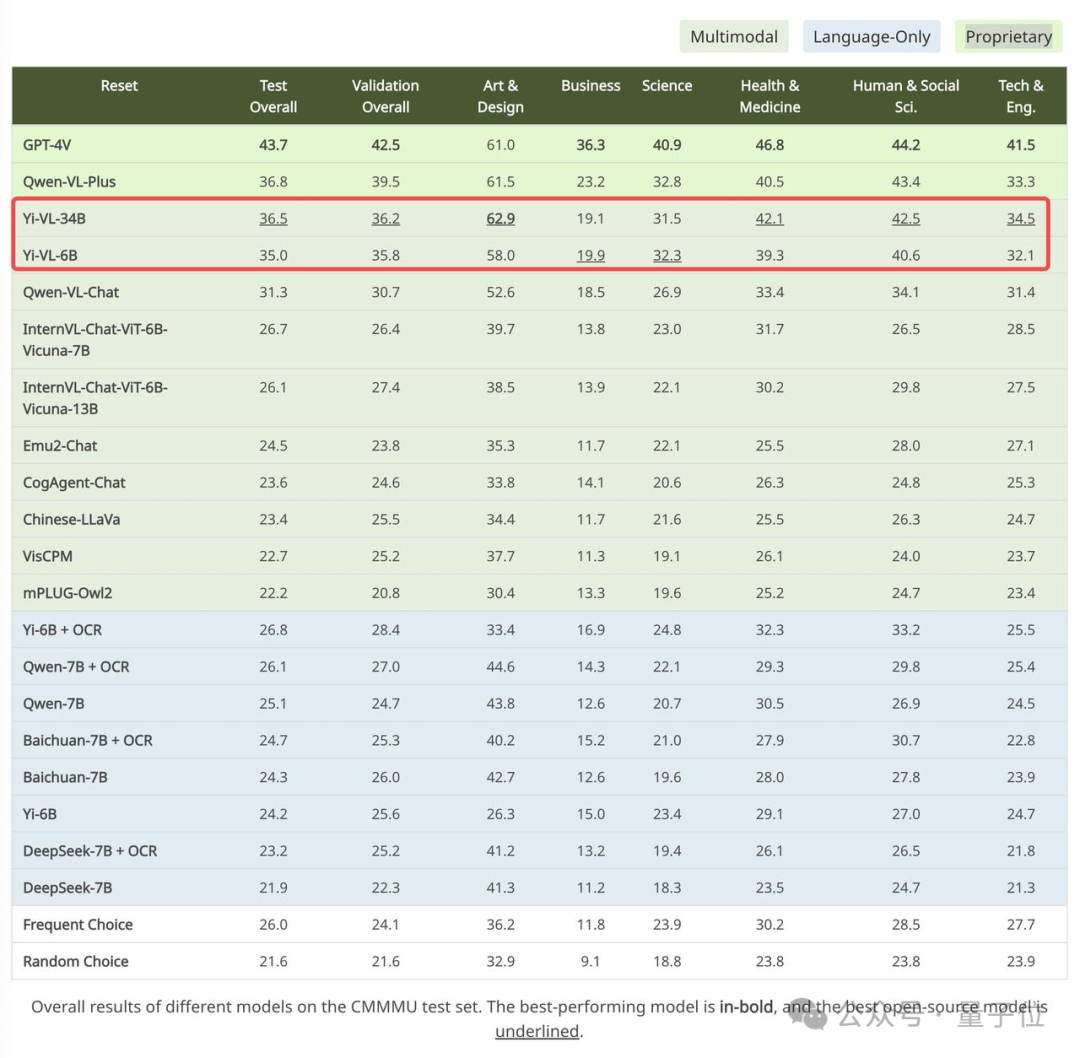
Pada set data Cina CMMMU, ketepatan Yi-VL-34B ialah 36.5%, yang mendahului model berbilang modal sumber terbuka terkini.
Apakah rupa Yi-VL?
Yi-VL dibangunkan berdasarkan model bahasa Yi Anda boleh melihat keupayaan pemahaman teks yang berkuasa berdasarkan model bahasa Yi Anda hanya perlu menyelaraskan gambar untuk mendapatkan model bahasa visual berbilang modal yang baik - ini juga model Yi-VL Salah satu sorotan teras.
Dalam reka bentuk seni bina, model Yi-VL adalah berdasarkan seni bina LLaVA sumber terbuka dan mengandungi tiga modul utama:
- Vision Transformer (dirujuk sebagai ViT) untuk pengekodan imej, menggunakan OpenClip ViT sumber terbuka -Model H/14 Mulakan parameter yang boleh dilatih dan belajar mengekstrak ciri daripada pasangan "teks imej" berskala besar, memberikan model keupayaan untuk memproses dan memahami imej.
- Modul Unjuran membawa keupayaan untuk menjajarkan ciri imej dan ciri teks secara spatial kepada model. Modul ini terdiri daripada perceptron berbilang lapisan (MLP) yang mengandungi normalisasi lapisan . Reka bentuk ini membolehkan model menggabungkan dan memproses maklumat visual dan teks dengan lebih berkesan, meningkatkan ketepatan pemahaman dan penjanaan pelbagai mod. Pengenalan model bahasa besar Yi-34B-Chat dan Yi-6B-Chat menyediakan Yi-VL dengan keupayaan pemahaman dan penjanaan bahasa yang berkuasa. Bahagian model ini menggunakan teknologi pemprosesan bahasa semula jadi termaju untuk membantu Yi-VL memahami secara mendalam struktur bahasa yang kompleks dan menjana output teks yang koheren dan relevan.
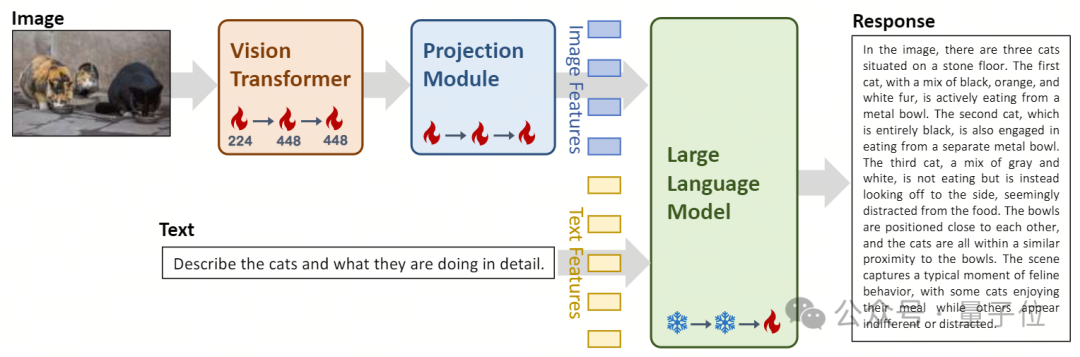 △Ilustrasi: Reka bentuk seni bina model Yi-VL dan gambaran keseluruhan proses kaedah latihan
△Ilustrasi: Reka bentuk seni bina model Yi-VL dan gambaran keseluruhan proses kaedah latihan
Dalam
kaedah latihan, proses latihan model Yi-VL dibahagikan kepada tiga peringkat, bertujuan untuk meningkatkan visual secara menyeluruh dan kualiti visual model Keupayaan pemprosesan bahasa. Pada peringkat pertama, 100 juta set data berpasangan "teks imej" digunakan untuk melatih modul ViT dan Unjuran.
Pada peringkat ini, peleraian imej ditetapkan kepada 224x224 untuk meningkatkan keupayaan pemerolehan pengetahuan ViT dalam seni bina tertentu sambil mencapai penjajaran yang cekap dengan model bahasa yang besar.
Pada peringkat kedua, resolusi imej ViT ditingkatkan kepada 448x448, menjadikan model lebih baik dalam mengenali butiran visual yang kompleks. Kira-kira 25 juta pasangan "teks imej" digunakan dalam peringkat ini.
Pada peringkat ketiga, parameter keseluruhan model dibuka untuk latihan, dengan matlamat untuk meningkatkan prestasi model dalam interaksi sembang berbilang modal. Data latihan merangkumi sumber data yang pelbagai, dengan jumlah kira-kira 1 juta pasangan "teks imej", memastikan keluasan dan keseimbangan data.
Pasukan teknikal Zero-One Everything juga telah mengesahkan bahawa ia boleh melatih pemahaman imej yang cekap dan grafik yang lancar berdasarkan pemahaman bahasa yang berkuasa dan keupayaan penjanaan model bahasa Yi menggunakan kaedah latihan pelbagai mod lain seperti BLIP, Flamingo, EVA, dsb. Model teks grafik multimodal untuk dialog tekstual.
Model siri Yi boleh digunakan sebagai model bahasa asas untuk model berbilang modal, memberikan pilihan baharu untuk komuniti sumber terbuka. Pada masa yang sama, pasukan multi-modal zero-one-things sedang meneroka pra-latihan pelbagai mod dari awal ke pendekatan dan melepasi GPT-4V dengan lebih pantas dan mencapai tahap eselon pertama di dunia.
Pada masa ini, model Yi-VL telah dibuka kepada orang ramai di platform seperti Hugging Face dan ModelScope Pengguna boleh mengalami sendiri prestasi model ini dalam pelbagai senario seperti dialog grafik dan teks.
Melangkaui siri model besar berbilang modal
Dalam penanda aras pelbagai mod baharu MMMU, kedua-dua versi Yi-VL-34B dan Yi-VL-6B berprestasi baik.
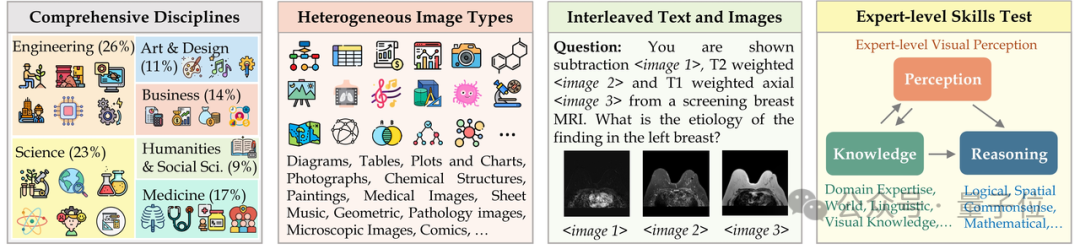
MMMU (Nama penuh: Massive Multi-discipline Multi-modal Understanding & Reasoning)Set data mengandungi 11,500 subjek daripada enam disiplin teras (seni dan reka bentuk, perniagaan, sains, Kesihatan dan perubatan, kemanusiaan dan sains sosial, dan teknologi dan kejuruteraan) masalah yang melibatkan jenis imej yang sangat heterogen dan maklumat teks-imej yang berjalin memerlukan permintaan yang sangat tinggi terhadap keupayaan persepsi dan penaakulan model yang lebih maju.
Dan Yi-VL-34B berjaya melepasi satu siri model besar berbilang modal dengan ketepatan 41.6% pada set ujian ini, kedua selepas GPT-4V(55.7%), menunjukkan Keupayaan berkuasa untuk memahami dan mengaplikasikan pengetahuan antara disiplin.
Begitu juga, pada set data CMMMU yang dicipta untuk adegan Cina, model Yi-VL menunjukkan kelebihan unik "memahami orang Cina dengan lebih baik".
CMMMU mengandungi kira-kira 12,000 soalan pelbagai modal bahasa Cina yang diperolehi daripada peperiksaan universiti, kuiz dan buku teks.

Antaranya, GPT-4V mempunyai ketepatan 43.7% pada set ujian ini, diikuti oleh Yi-VL-34B dengan ketepatan 36.5%, yang mendahului pelbagai mod sumber terbuka terkini. model.
Alamat projek:
[1]https://huggingface.co/01-ai
[2]https://www.modelscope.cn/organization/01ai
Atas ialah kandungan terperinci Kai-Fu Lee mengambil bahagian dalam Zero One Wish, yang mengeluarkan model besar berbilang modal sumber terbuka bertaraf dunia.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- css的盒子模型属性有哪些?css盒子模型相关属性的介绍
- Latihan ViT dan MAE mengurangkan jumlah pengiraan sebanyak separuh! Sea dan Universiti Peking bersama-sama mencadangkan Adan pengoptimum yang cekap, yang boleh digunakan untuk model dalam
- Enjin Gunung Berapi membantu Teknologi Shenzhen mengeluarkan model pra-latihan molekul 3D pertama dalam industri Uni-Mol
- Menggunakan model besar untuk mencipta paradigma baharu untuk latihan ringkasan teks
- Zoom memastikan ketelusan dalam penggunaan data dan memastikan latihan AI tertakluk kepada kebenaran pengguna