
Rumah >Peranti teknologi >AI >Kaedah baharu Google ASPIRE: memperkasakan LLM dengan keupayaan pemarkahan sendiri, menyelesaikan masalah 'ilusi' dengan berkesan dan mengatasi 10 kali ganda model volum
Kaedah baharu Google ASPIRE: memperkasakan LLM dengan keupayaan pemarkahan sendiri, menyelesaikan masalah 'ilusi' dengan berkesan dan mengatasi 10 kali ganda model volum

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-23 17:21:13862semak imbas
Masalah "ilusi" model besar akan selesai tidak lama lagi?
Para penyelidik di University of Wisconsin-Madison dan Google baru-baru ini melancarkan sistem ASPIRE, yang membolehkan model besar menilai sendiri output mereka.
Jika pengguna melihat bahawa hasil yang dihasilkan oleh model mempunyai skor yang rendah, dia akan menyedari bahawa balasan itu mungkin ilusi.
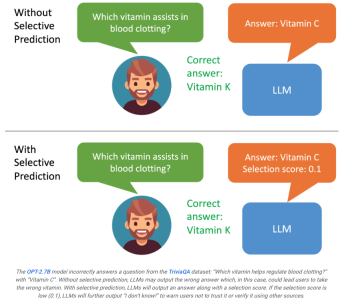
Sekiranya sistem boleh menapis kandungan output berdasarkan hasil penilaian, contohnya, apabila rating rendah, model besar boleh menjana pernyataan seperti "Saya tidak dapat menjawab soalan ini", yang mungkin memaksimumkan penambahbaikan masalah halusinasi.

Alamat kertas: https://aclanthology.org/2023.findings-emnlp.345.pdf
ASPIRE membolehkan LLM mengeluarkan jawapan dan skor keyakinan jawapan.
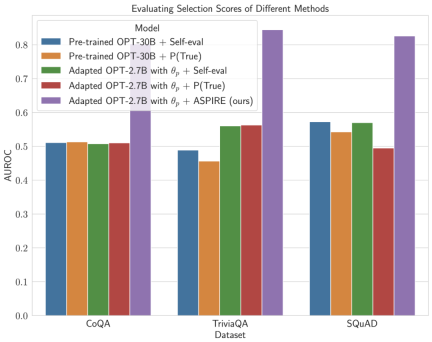
Keputusan percubaan penyelidik menunjukkan bahawa ASPIRE secara ketara mengatasi kaedah ramalan terpilih tradisional pada pelbagai set data QA (seperti penanda aras CoQA).
Biar LLM bukan sahaja menjawab soalan tetapi juga menilai jawapan tersebut.
Dalam ujian penanda aras ramalan terpilih, penyelidik mencapai keputusan lebih daripada 10 kali ganda skala model melalui sistem ASPIRE.
Ia seperti meminta pelajar mengesahkan jawapan mereka sendiri di belakang buku teks Walaupun kedengarannya agak tidak boleh dipercayai, jika difikirkan dengan teliti, semua orang memang akan berpuas hati dengan jawapan selepas menjawab soalan. Akan ada penilaian.
Inilah intipati ASPIRE, yang melibatkan tiga peringkat:
(1) Menala untuk tugas tertentu,
(2)
Jawapan,( 3 ) Menilai pembelajaran kendiri.
Di mata penyelidik, ASPIRE bukan sekadar rangka kerja lain, ia mewakili masa depan yang cerah yang meningkatkan kebolehpercayaan LLM secara menyeluruh dan mengurangkan halusinasi.
Jika LLM boleh menjadi rakan kongsi yang boleh dipercayai dalam proses membuat keputusan.
Selagi kita terus mengoptimumkan keupayaan ramalan terpilih, manusia selangkah lebih dekat untuk merealisasikan potensi model besar sepenuhnya.
Penyelidik berharap dapat menggunakan ASPIRE untuk memulakan evolusi generasi LLM seterusnya, dengan itu mencipta kecerdasan buatan yang lebih dipercayai dan sedar diri.
Mekanisme ASPIRE
Penalaan halus khusus tugas
ASPIRE melakukan penalaan halus khusus tugasan untuk melatih parameter penyesuaian🜎🜎 membebaskan 
Untuk tujuan ini, teknik penalaan halus yang cekap parameter (cth., penalaan halus perkataan kiu lembut dan LoRA) boleh digunakan untuk memperhalusi LLM pra-latihan pada tugas itu, kerana mereka boleh memperoleh generalisasi yang kukuh dengan berkesan dengan sejumlah kecil data sasaran.
Secara khusus, parameter LLM (θ) dibekukan dan parameter penyesuaian
ditambah untuk penalaan halus. 
Penalaan halus ini boleh meningkatkan prestasi ramalan terpilih kerana ia bukan sahaja meningkatkan ketepatan ramalan, tetapi juga meningkatkan kemungkinan mengeluarkan jujukan dengan betul.
Selepas ditala untuk tugasan tertentu, ASPIRE menggunakan LLM dan belajar Matlamat penyelidik adalah untuk menjana jujukan output dengan kemungkinan yang tinggi. Mereka menggunakan Carian Rasuk sebagai algoritma penyahkodan untuk menjana jujukan output berkemungkinan tinggi dan menggunakan metrik Rouge-L untuk menentukan sama ada jujukan output yang dijana adalah betul. . boleh mengelakkan perubahan tingkah laku ramalan LLM semasa mempelajari penilaian kendiri. . , penyelidik memperoleh ramalan pertanyaan melalui penyahkodan carian pancaran. Para penyelidik kemudiannya mentakrifkan skor pilihan yang menggabungkan kemungkinan menjana jawapan dengan skor penilaian kendiri yang dipelajari (iaitu, kemungkinan ramalan itu betul untuk pertanyaan) untuk membuat ramalan terpilih. Dengan melaraskan latihan menggunakan isyarat lembut Sebagai contoh, model OPT-2.7B dengan ASPIRE menunjukkan prestasi yang lebih baik berbanding model OPT-30B pra-latihan yang lebih besar menggunakan set data CoQA dan SQuAD. Hasil ini mencadangkan bahawa dengan penalaan yang sesuai, LLM yang lebih kecil mungkin mempunyai keupayaan untuk memadankan atau mungkin melebihi ketepatan model yang lebih besar dalam beberapa kes. Apabila menyelidiki pengiraan skor pemilihan untuk ramalan model tetap, ASPIRE mencapai skor AUROC yang lebih tinggi daripada kaedah garis dasar untuk semua set data (urutan output betul yang dipilih secara rawak mempunyai nilai yang lebih tinggi daripada urutan output salah yang dipilih secara rawak) kebarangkalian skor pemilihan yang lebih tinggi). Sebagai contoh, pada penanda aras CoQA, ASPIRE meningkatkan AUROC daripada 51.3% kepada 80.3% berbanding garis dasar. Satu corak menarik muncul daripada penilaian pada set data TriviaQA. . Sebaliknya, model OPT-2.7B yang jauh lebih kecil mengatasi model lain dalam hal ini selepas dipertingkatkan dengan ASPIRE. Perbezaan ini merangkumi isu penting: LLM yang lebih besar yang menggunakan teknik penilaian kendiri tradisional mungkin tidak berkesan dalam ramalan terpilih seperti model yang dipertingkatkan ASPIRE yang lebih kecil.
Perjalanan percubaan penyelidik dengan ASPIRE menyerlahkan anjakan utama dalam landskap LLM: kapasiti model bahasa bukanlah keseluruhan dan akhir dari prestasinya. Sebaliknya, keberkesanan model boleh dipertingkatkan dengan banyak melalui pelarasan dasar, membolehkan ramalan yang lebih tepat dan yakin walaupun dalam model yang lebih kecil. Oleh itu, ASPIRE menunjukkan potensi LLM untuk menentukan dengan wajar kepastian jawapannya sendiri dan dengan ketara mengatasi prestasi 10x lebih besar model lain dalam tugas ramalan terpilih. Pensampelan Jawapan
 untuk menjana jawapan yang berbeza bagi setiap soalan latihan dan mencipta set data untuk pembelajaran penilaian kendiri.
untuk menjana jawapan yang berbeza bagi setiap soalan latihan dan mencipta set data untuk pembelajaran penilaian kendiri.
Memandangkan penjanaan jujukan keluaran hanya bergantung kepada θ dan , pembekuan θ dan yang dipelajari
 Para penyelidik mengoptimumkan
Para penyelidik mengoptimumkan  supaya LLM yang disesuaikan dapat membezakan jawapan yang betul dan salah dengan sendirinya.
supaya LLM yang disesuaikan dapat membezakan jawapan yang betul dan salah dengan sendirinya.  Dalam rangka kerja ini, sebarang kaedah penalaan halus yang cekap parameter boleh digunakan untuk melatih
Dalam rangka kerja ini, sebarang kaedah penalaan halus yang cekap parameter boleh digunakan untuk melatih  dan
dan  Dalam kerja ini, penyelidik menggunakan penalaan halus kiu lembut, mekanisme yang mudah namun berkesan untuk mempelajari "isyarat lembut" untuk menala model bahasa beku supaya lebih berkesan daripada isyarat teks diskret tradisional untuk melaksanakan tugas hiliran tertentu.
Dalam kerja ini, penyelidik menggunakan penalaan halus kiu lembut, mekanisme yang mudah namun berkesan untuk mempelajari "isyarat lembut" untuk menala model bahasa beku supaya lebih berkesan daripada isyarat teks diskret tradisional untuk melaksanakan tugas hiliran tertentu. 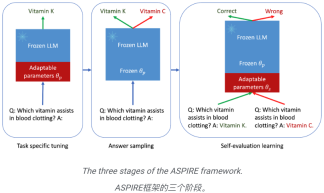

 Selepas latihan
Selepas latihan 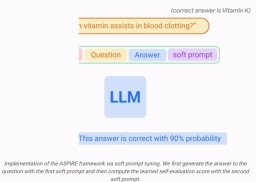 Keputusan
Keputusan Untuk menunjukkan keberkesanan ASPIRE, para penyelidik menggunakan pelbagai model Transformer (OPT) pra-latihan terbuka untuk menilai mereka pada tiga set data menjawab soalan (CoQA, TriviaQA dan SQuAD).
Untuk menunjukkan keberkesanan ASPIRE, para penyelidik menggunakan pelbagai model Transformer (OPT) pra-latihan terbuka untuk menilai mereka pada tiga set data menjawab soalan (CoQA, TriviaQA dan SQuAD).  Para penyelidik memerhatikan peningkatan yang ketara dalam ketepatan LLM.
Para penyelidik memerhatikan peningkatan yang ketara dalam ketepatan LLM. 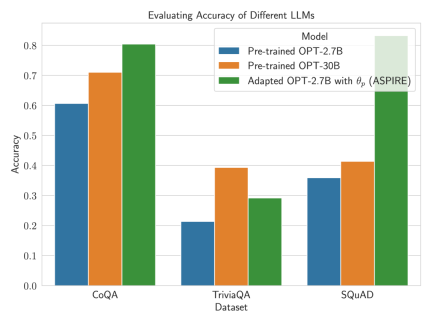
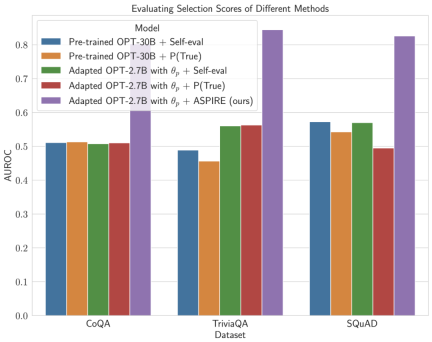
Atas ialah kandungan terperinci Kaedah baharu Google ASPIRE: memperkasakan LLM dengan keupayaan pemarkahan sendiri, menyelesaikan masalah 'ilusi' dengan berkesan dan mengatasi 10 kali ganda model volum. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!