
 pembangunan bahagian belakangTutorial PythonCara menggunakan Python untuk melatih AI untuk bermain permainan Ular
pembangunan bahagian belakangTutorial PythonCara menggunakan Python untuk melatih AI untuk bermain permainan UlarCara menggunakan Python untuk melatih AI untuk bermain permainan Ular

Ini ialah panduan ringkas tentang cara menggunakan pembelajaran pengukuhan untuk melatih AI untuk bermain permainan Ular. Artikel itu menunjukkan langkah demi langkah cara menyediakan persekitaran permainan tersuai dan menggunakan perpustakaan algoritma Stable-Baselines3 piawai python untuk melatih AI bermain Snake.
Dalam projek ini, kami menggunakan Stable-Baselines3, perpustakaan piawai yang menyediakan pelaksanaan algoritma pembelajaran tetulang (RL) berasaskan PyTorch yang mudah digunakan.
Pertama, sediakan persekitaran. Terdapat banyak persekitaran permainan terbina dalam pustaka Stable-Baselines Di sini kami menggunakan versi Ular klasik yang diubah suai, dengan dinding silang silang tambahan di tengah.
Pelan ganjaran yang lebih baik adalah dengan hanya memberi ganjaran langkah lebih dekat dengan makanan. Penjagaan mesti diambil di sini, kerana ular itu masih boleh belajar berjalan dalam bulatan, mendapat ganjaran apabila mendekati makanan, kemudian berpusing dan kembali. Untuk mengelakkan ini, kita juga mesti memberikan penalti yang setara untuk menjauhi makanan, dengan kata lain, kita perlu memastikan bahawa ganjaran bersih pada gelung tertutup adalah sifar. Kita juga perlu memperkenalkan penalti untuk memukul dinding, kerana dalam beberapa kes seekor ular akan memilih untuk memukul dinding untuk mendekati makanannya.
Kebanyakan algoritma pembelajaran mesin agak kompleks dan sukar untuk dilaksanakan. Nasib baik, Stable-Baselines3 sudah melaksanakan beberapa algoritma terkini yang kami gunakan. Dalam contoh, kami akan menggunakan Pengoptimuman Dasar Proksimal (PPO). Walaupun kami tidak perlu mengetahui butiran tentang cara algoritma berfungsi (lihat video penjelasan ini jika anda berminat), kami perlu mempunyai pemahaman asas tentang hiperparameternya dan perkara yang dilakukannya. Nasib baik, PPO hanya mempunyai beberapa daripadanya, dan kami akan menggunakan yang berikut:
kadar_pembelajaran: Menetapkan seberapa besar langkah untuk kemas kini dasar, sama seperti senario pembelajaran mesin yang lain. Menetapkannya terlalu tinggi boleh menghalang algoritma daripada mencari penyelesaian yang betul atau menolaknya ke arah yang tidak boleh pulih. Menetapkannya terlalu rendah akan menjadikan latihan mengambil masa yang lebih lama. Helah biasa ialah menggunakan fungsi penjadual untuk menalanya semasa latihan.
gamma: faktor diskaun untuk ganjaran masa hadapan, antara 0 (hanya ganjaran segera penting) dan 1 (ganjaran masa depan mempunyai nilai yang sama dengan ganjaran segera). Untuk mengekalkan kesan latihan, adalah lebih baik untuk mengekalkannya di atas 0.9.
clip_range1+-clip_range: Satu ciri penting PPO, ia wujud untuk memastikan model tidak berubah dengan ketara semasa latihan. Mengurangkannya membantu memperhalusi model dalam peringkat latihan kemudian.
ent_coef: Pada asasnya, lebih tinggi nilainya, lebih banyak algoritma digalakkan untuk meneroka tindakan tidak optimum yang berbeza, yang boleh membantu skim melarikan diri maksimum ganjaran tempatan.
Secara umumnya, mulakan sahaja dengan hiperparameter lalai.
Langkah seterusnya adalah untuk melatih beberapa langkah yang telah ditetapkan, kemudian lihat sendiri prestasi algoritma, dan kemudian mulakan semula dengan parameter baharu yang mungkin berprestasi terbaik. Di sini kami merancang ganjaran untuk masa latihan yang berbeza.
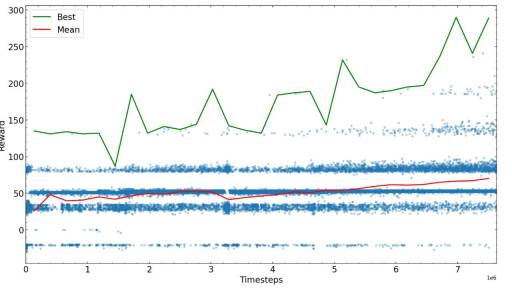
Selepas langkah yang mencukupi, algoritma latihan ular menumpu kepada nilai ganjaran tertentu, anda boleh melengkapkan latihan atau cuba memperhalusi parameter dan meneruskan latihan.
Langkah latihan yang diperlukan untuk mencapai ganjaran maksimum yang mungkin bergantung pada masalah, skema ganjaran dan hiperparameter, jadi adalah disyorkan untuk mengoptimumkan sebelum melatih algoritma. Pada akhir contoh melatih AI untuk bermain permainan Ular, kami mendapati bahawa AI dapat mencari makanan dalam labirin dan mengelak daripada berlanggar dengan ekor.
Atas ialah kandungan terperinci Cara menggunakan Python untuk melatih AI untuk bermain permainan Ular. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Python vs C: Aplikasi dan kes penggunaan dibandingkanApr 12, 2025 am 12:01 AM
Python vs C: Aplikasi dan kes penggunaan dibandingkanApr 12, 2025 am 12:01 AMPython sesuai untuk sains data, pembangunan web dan tugas automasi, manakala C sesuai untuk pengaturcaraan sistem, pembangunan permainan dan sistem tertanam. Python terkenal dengan kesederhanaan dan ekosistem yang kuat, manakala C dikenali dengan keupayaan kawalan dan keupayaan kawalan yang mendasari.
 Rancangan Python 2 jam: Pendekatan yang realistikApr 11, 2025 am 12:04 AM
Rancangan Python 2 jam: Pendekatan yang realistikApr 11, 2025 am 12:04 AMAnda boleh mempelajari konsep pengaturcaraan asas dan kemahiran Python dalam masa 2 jam. 1. Belajar Pembolehubah dan Jenis Data, 2.
 Python: meneroka aplikasi utamanyaApr 10, 2025 am 09:41 AM
Python: meneroka aplikasi utamanyaApr 10, 2025 am 09:41 AMPython digunakan secara meluas dalam bidang pembangunan web, sains data, pembelajaran mesin, automasi dan skrip. 1) Dalam pembangunan web, kerangka Django dan Flask memudahkan proses pembangunan. 2) Dalam bidang sains data dan pembelajaran mesin, numpy, panda, scikit-learn dan perpustakaan tensorflow memberikan sokongan yang kuat. 3) Dari segi automasi dan skrip, Python sesuai untuk tugas -tugas seperti ujian automatik dan pengurusan sistem.
 Berapa banyak python yang boleh anda pelajari dalam 2 jam?Apr 09, 2025 pm 04:33 PM
Berapa banyak python yang boleh anda pelajari dalam 2 jam?Apr 09, 2025 pm 04:33 PMAnda boleh mempelajari asas -asas Python dalam masa dua jam. 1. Belajar pembolehubah dan jenis data, 2. Struktur kawalan induk seperti jika pernyataan dan gelung, 3 memahami definisi dan penggunaan fungsi. Ini akan membantu anda mula menulis program python mudah.
 Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam Kaedah Projek dan Masalah Dikemukakan Dalam masa 10 Jam?Apr 02, 2025 am 07:18 AM
Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam Kaedah Projek dan Masalah Dikemukakan Dalam masa 10 Jam?Apr 02, 2025 am 07:18 AMBagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam masa 10 jam? Sekiranya anda hanya mempunyai 10 jam untuk mengajar pemula komputer beberapa pengetahuan pengaturcaraan, apa yang akan anda pilih untuk mengajar ...
 Bagaimana untuk mengelakkan dikesan oleh penyemak imbas apabila menggunakan fiddler di mana-mana untuk membaca lelaki-dalam-tengah?Apr 02, 2025 am 07:15 AM
Bagaimana untuk mengelakkan dikesan oleh penyemak imbas apabila menggunakan fiddler di mana-mana untuk membaca lelaki-dalam-tengah?Apr 02, 2025 am 07:15 AMCara mengelakkan dikesan semasa menggunakan fiddlerevery di mana untuk bacaan lelaki-dalam-pertengahan apabila anda menggunakan fiddlerevery di mana ...
 Apa yang perlu saya lakukan jika modul '__builtin__' tidak dijumpai apabila memuatkan fail acar di Python 3.6?Apr 02, 2025 am 07:12 AM
Apa yang perlu saya lakukan jika modul '__builtin__' tidak dijumpai apabila memuatkan fail acar di Python 3.6?Apr 02, 2025 am 07:12 AMMemuatkan Fail Pickle di Python 3.6 Kesalahan Laporan Alam Sekitar: ModulenotFoundError: Nomodulenamed ...
 Bagaimana untuk meningkatkan ketepatan segmentasi kata Jieba dalam analisis komen tempat yang indah?Apr 02, 2025 am 07:09 AM
Bagaimana untuk meningkatkan ketepatan segmentasi kata Jieba dalam analisis komen tempat yang indah?Apr 02, 2025 am 07:09 AMBagaimana untuk menyelesaikan masalah segmentasi kata Jieba dalam analisis komen tempat yang indah? Semasa kami mengadakan komen dan analisis tempat yang indah, kami sering menggunakan alat segmentasi perkataan jieba untuk memproses teks ...


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

Penyesuai Pelayan SAP NetWeaver untuk Eclipse
Integrasikan Eclipse dengan pelayan aplikasi SAP NetWeaver.

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

Dreamweaver Mac版
Alat pembangunan web visual

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

