
Rumah >Peranti teknologi >AI >Detik Swin model visual Mamba, Akademi Sains China, Huawei dan lain-lain melancarkan VMamba
Detik Swin model visual Mamba, Akademi Sains China, Huawei dan lain-lain melancarkan VMamba

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-22 15:21:11995semak imbas
Kedudukan transformer dalam bidang model besar tidak boleh digoncangkan. Walau bagaimanapun, apabila skala model mengembang dan panjang jujukan meningkat, batasan seni bina Transformer tradisional mula menjadi jelas. Nasib baik, kedatangan Mamba dengan cepat mengubah keadaan ini. Prestasi cemerlangnya serta-merta menimbulkan sensasi dalam komuniti AI. Kemunculan Mamba telah membawa penemuan besar kepada latihan model berskala besar dan pemprosesan jujukan. Kelebihannya merebak dengan pantas dalam komuniti AI, membawa harapan besar untuk penyelidikan dan aplikasi masa depan.
Pada Khamis lalu, pengenalan Vision Mamba (Vim) telah menunjukkan potensi besarnya untuk menjadi tulang belakang generasi seterusnya model asas visual. Hanya sehari kemudian, penyelidik dari Akademi Sains China, Huawei dan Makmal Pengcheng mencadangkan VMamba: Model visual Mamba dengan medan penerimaan global dan kerumitan linear. Kerja ini menandakan momen Swin model Mamba visual.

- Tajuk kertas: VMamba: Model Angkasa Negeri Visual
- Alamat kertas: https://arxiv.org/abs/2401.1016 b .com/MzeroMiko/VMamba
- CNN dan Visual Transformer (ViT) kini merupakan dua model visual asas paling arus perdana. Walaupun CNN mempunyai kerumitan linear, ViT mempunyai keupayaan pemasangan data yang lebih berkuasa, tetapi pada kos kerumitan pengiraan yang lebih tinggi. Penyelidik percaya bahawa ViT mempunyai keupayaan pemasangan yang kuat kerana ia mempunyai medan penerimaan global dan berat dinamik. Diilhamkan oleh model Mamba, penyelidik mereka bentuk model yang mempunyai kedua-dua sifat yang sangat baik di bawah kerumitan linear, iaitu Model Angkasa Negeri Visual (VMamba).
Seperti yang ditunjukkan dalam rajah di bawah, VMamba-S mencapai ketepatan 83.5% pada ImageNet-1K, iaitu 3.2% lebih tinggi daripada Vim-S dan 0.5% lebih tinggi daripada Swin-S.
Pengenalan Kaedah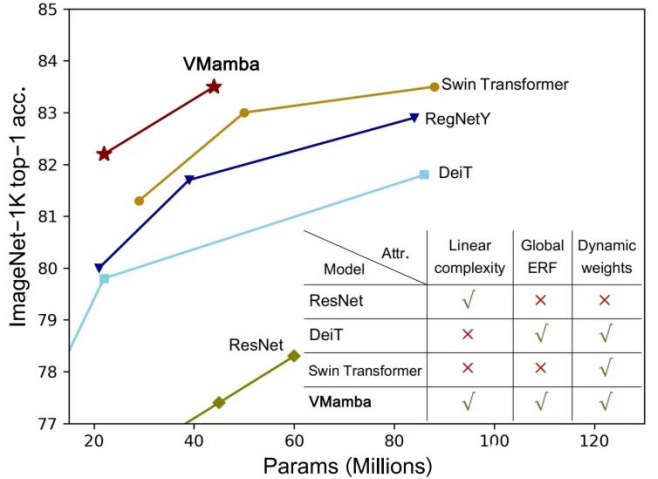
Kunci kejayaan VMamba terletak pada penggunaan model S6, yang pada asalnya direka bentuk untuk menyelesaikan tugasan bahasa semula jadi (LP) Tidak seperti mekanisme perhatian ViT, model S6 secara berkesan mengurangkan kerumitan kuadratik kepada lineariti dengan berinteraksi setiap elemen dalam vektor 1D dengan maklumat imbasan sebelumnya. Interaksi ini menjadikan VMamba lebih cekap apabila memproses data berskala besar. Oleh itu, pengenalan model S6 meletakkan asas yang kukuh untuk kejayaan VMamba. 
Walau bagaimanapun, memandangkan isyarat visual (seperti imej) tidak disusun secara semula jadi seperti urutan teks, kaedah pengimbasan data dalam S6 tidak boleh digunakan secara langsung pada isyarat visual. Untuk tujuan ini, penyelidik mereka bentuk mekanisme pengimbasan Cross-Scan. Modul Imbas Silang (CSM) mengamalkan strategi pengimbasan empat hala, iaitu mengimbas dari empat penjuru peta ciri secara serentak (lihat rajah di atas).
Strategi ini memastikan bahawa setiap elemen dalam ciri menyepadukan maklumat dari semua lokasi lain dalam arah yang berbeza, membentuk medan penerimaan global tanpa meningkatkan kerumitan pengiraan linear.
Berdasarkan CSM, pengarang mereka bentuk modul 2D-selektif-scan (SS2D). Seperti yang ditunjukkan dalam rajah di atas, SS2D terdiri daripada tiga langkah: 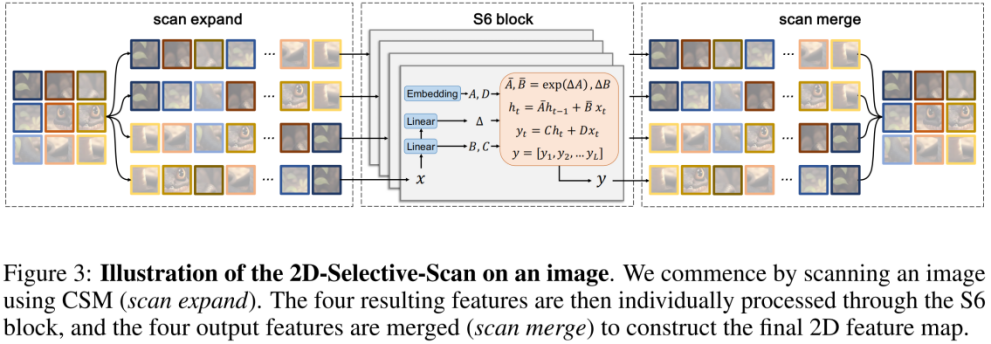
scan kembangkan meratakan ciri 2D menjadi vektor 1D di sepanjang 4 arah berbeza (kiri atas, kanan bawah, kiri bawah, kanan atas).
- Blok S6 secara bebas menghantar 4 vektor 1D yang diperoleh dalam langkah sebelumnya ke operasi S6.
- cantuman imbasan menggabungkan 4 vektor 1D yang terhasil menjadi output ciri 2D.
Gambar di atas ialah gambar rajah struktur VMamba yang dicadangkan dalam artikel ini. Rangka kerja keseluruhan VMamba adalah serupa dengan model visual arus perdana Perbezaan utama terletak pada pengendali yang digunakan dalam modul asas (blok VSS). Blok VSS menggunakan operasi 2D-selektif-scan yang diperkenalkan di atas, iaitu SS2D. SS2D memastikan VMamba mencapai 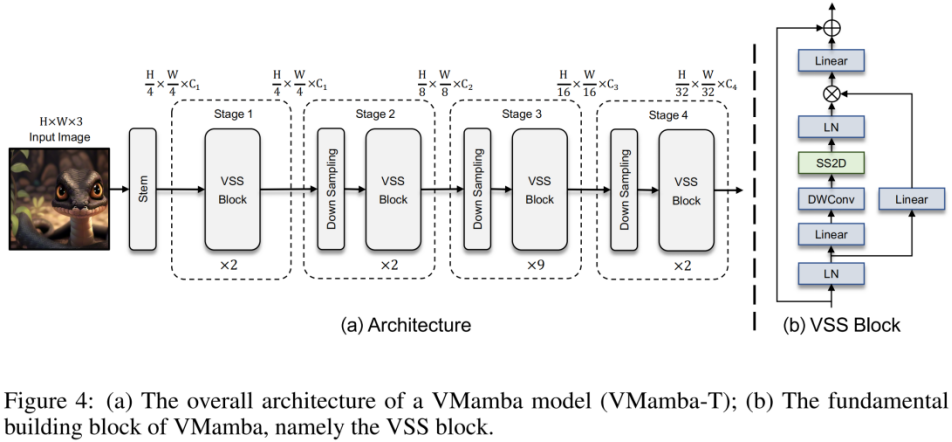 bidang penerimaan global dengan kos
bidang penerimaan global dengan kos
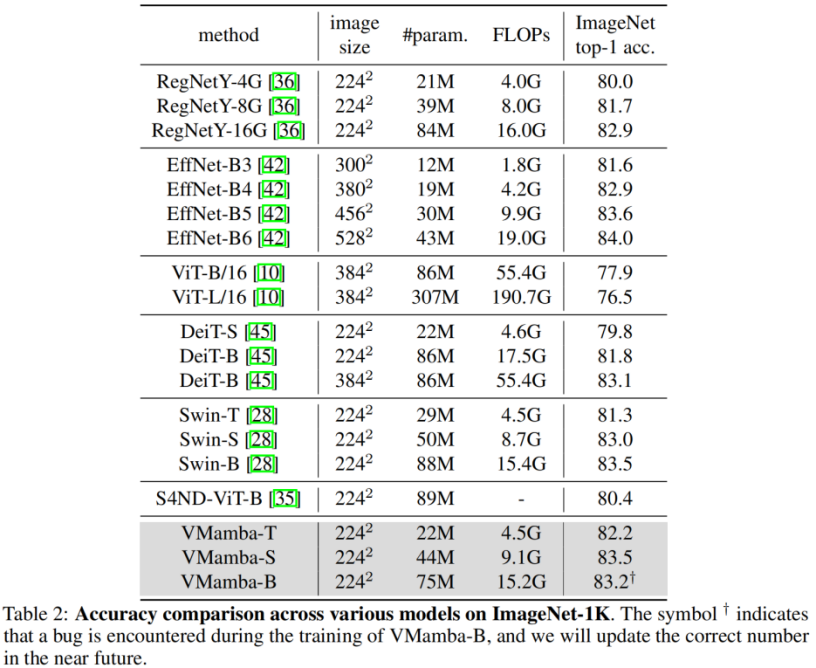
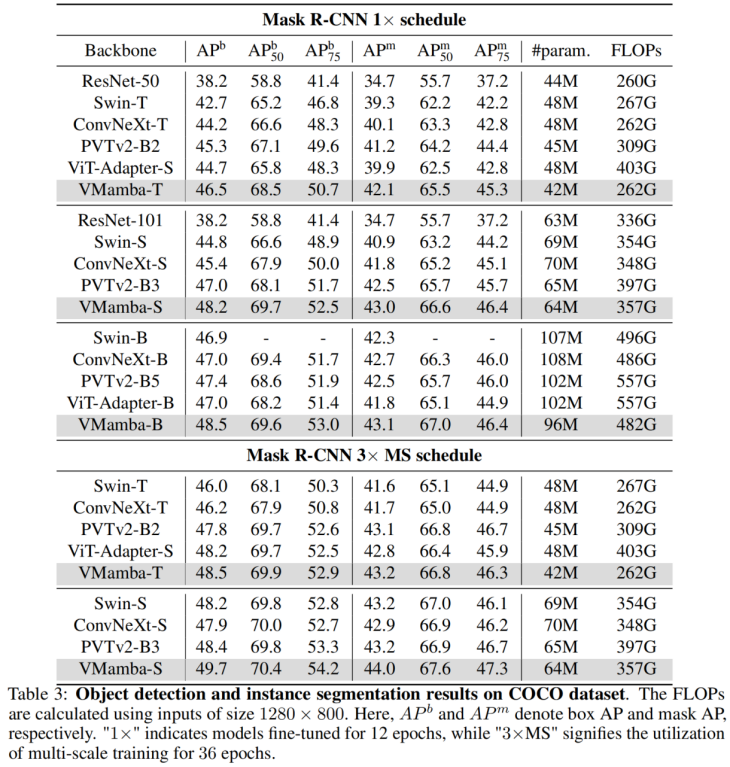
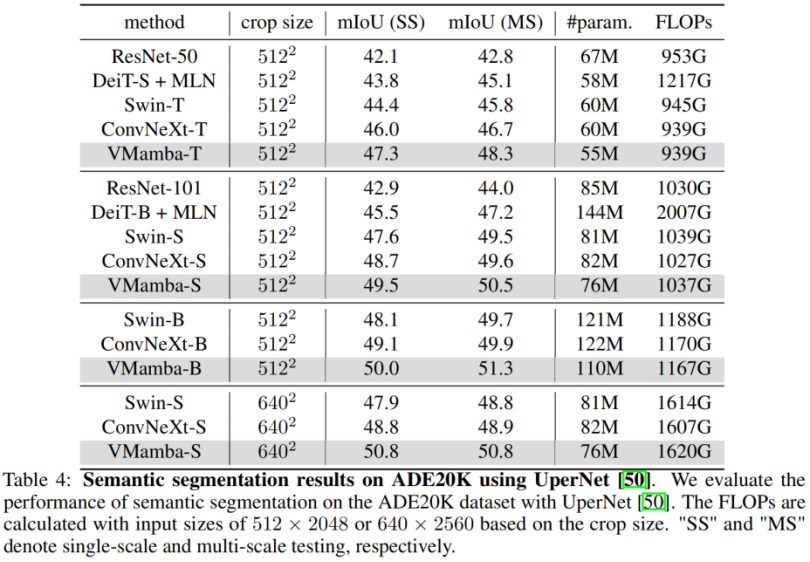
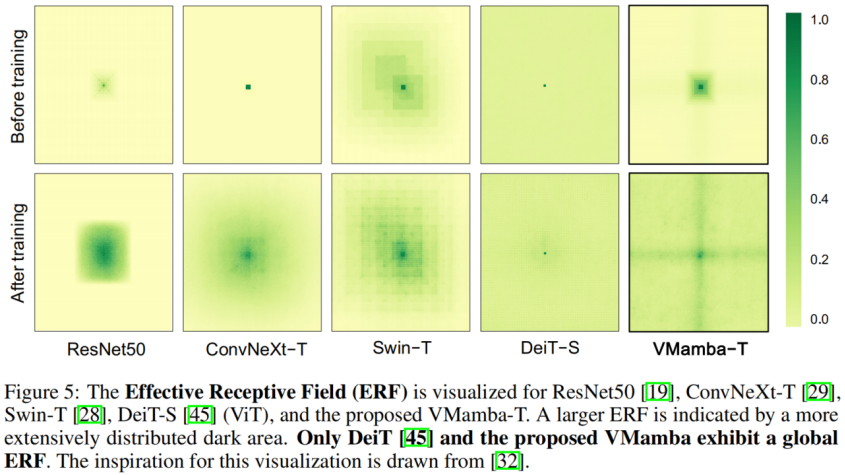
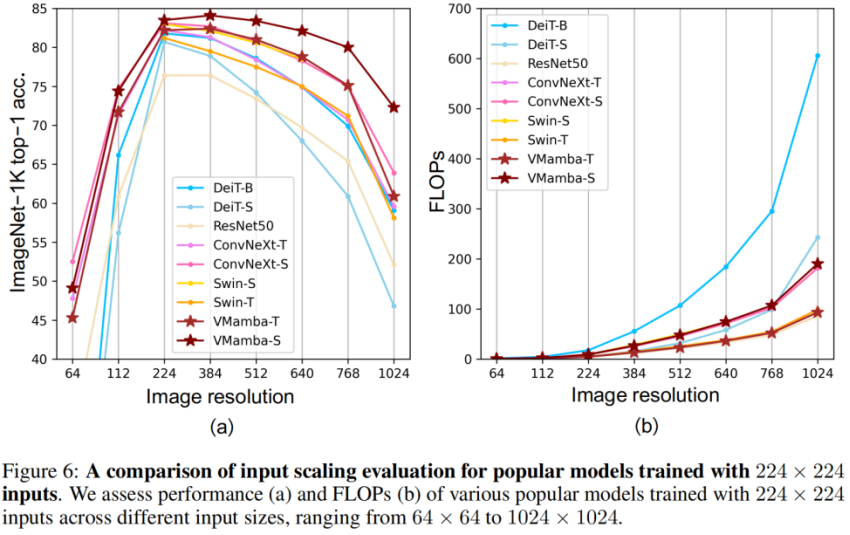
. Pengkelasan ImageNet Tidak sukar untuk melihatnya di bawah amaun parameter dan FLOP yang sama: Keputusan ini jauh lebih tinggi daripada model Vision Mamba (Vim), yang mengesahkan sepenuhnya potensi VMamba. COCO pengesanan sasaran Pada set data COOCO, VMamba juga mengekalkan prestasi cemerlang: dalam kes penalaan halus 12 zaman/S46B.5% masing-masing dicapai 48.2%/48.5% mAP, melebihi Swin-T/S/B sebanyak 3.8%/3.6%/1.6% mAP dan melebihi ConvNeXt-T/S/B sebanyak 2.3%/2.8%/1.5% mAP. Keputusan ini mengesahkan bahawa VMamba berfungsi sepenuhnya dalam eksperimen visual hiliran, menunjukkan potensinya untuk menggantikan model visual asas arus perdana. Segmentasi Semantik ADE20K Pada ADE20K, VMamba juga menunjukkan prestasi yang cemerlang. Model VMamba-T mencapai 47.3% mIoU pada resolusi 512 × 512, skor yang mengatasi semua pesaing, termasuk ResNet, DeiT, Swin dan ConvNeXt. Kelebihan ini masih boleh dikekalkan di bawah model VMamba-S/B. Medan penerimaan yang berkesan VMamba mempunyai ciri penerimaan berkesan global yang lain dan hanya model DeiT ini Walau bagaimanapun, perlu diperhatikan bahawa kos DeiT ialah kerumitan kuadratik, manakala VMamaba ialah kerumitan linear. Penskalaan skala input Akhirnya, marilah kita menantikan lebih banyak model penglihatan berasaskan Mamba yang dicadangkan, bersama CNN dan ViT, untuk menyediakan pilihan ketiga untuk model penglihatan asas. Hasil eksperimen
Eksperimen analisis
Atas ialah kandungan terperinci Detik Swin model visual Mamba, Akademi Sains China, Huawei dan lain-lain melancarkan VMamba. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!