
Rumah >Peranti teknologi >AI >Dua petua hebat untuk meningkatkan kecekapan kod Pandas anda
Dua petua hebat untuk meningkatkan kecekapan kod Pandas anda

- 王林ke hadapan
- 2024-01-18 20:12:051193semak imbas
Jika anda pernah menggunakan Panda untuk bekerja dengan data jadual, anda mungkin sudah biasa dengan proses mengimport data, membersihkan dan mengubahnya, kemudian menggunakannya sebagai input kepada model. Walau bagaimanapun, apabila anda perlu menskalakan dan memasukkan kod anda ke dalam pengeluaran, saluran paip Pandas anda kemungkinan besar akan mula ranap dan berjalan perlahan. Dalam artikel ini, saya akan berkongsi 2 petua untuk membantu anda mempercepatkan pelaksanaan kod Pandas, meningkatkan kecekapan pemprosesan data dan mengelakkan perangkap biasa.

Petua 1: Operasi Vektorisasi
Dalam Panda, operasi vektorisasi ialah alat cekap yang boleh memproses lajur keseluruhan bingkai data dengan cara yang lebih ringkas tanpa perlu menggelung baris demi baris.
Bagaimana ia berfungsi?
Penyiaran ialah elemen utama operasi bervektor, membolehkan anda memanipulasi objek secara intuitif dengan bentuk yang berbeza.
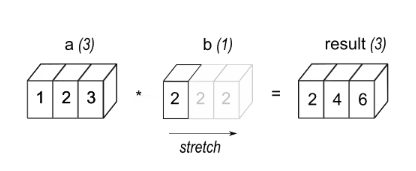
cth1: Tatasusunan a dengan 3 elemen didarab dengan skalar b, menghasilkan tatasusunan dengan bentuk yang sama seperti Sumber.
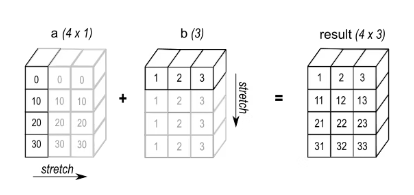
cth2: Semasa menjalankan operasi tambah, tambah tatasusunan a dengan bentuk (4,1) dan tatasusunan b dengan bentuk (3,).
Terdapat banyak artikel membincangkan perkara ini, terutamanya dalam pembelajaran mendalam di mana pendaraban matriks berskala besar adalah perkara biasa. Artikel ini akan membincangkan dua contoh ringkas.
Mula-mula, katakan anda ingin mengira bilangan kali integer yang diberikan muncul dalam lajur. Berikut adalah 2 kaedah yang mungkin.
"""计算DataFrame X 中 "column_1" 列中等于目标值 target 的元素个数。参数:X: DataFrame,包含要计算的列 "column_1"。target: int,目标值。返回值:int,等于目标值 target 的元素个数。"""# 使用循环计数def count_loop(X, target: int) -> int:return sum(x == target for x in X["column_1"])# 使用矢量化操作计数def count_vectorized(X, target: int) -> int:return (X["column_1"] == target).sum()
Sekarang andaikan anda mempunyai DataFrame dengan lajur tarikh dan ingin mengimbanginya dengan bilangan hari tertentu. Pengiraan menggunakan operasi vektor adalah seperti berikut:
def offset_loop(X, days: int) -> pd.DataFrame:d = pd.Timedelta(days=days)X["column_const"] = [x + d for x in X["column_10"]]return Xdef offset_vectorized(X, days: int) -> pd.DataFrame:X["column_const"] = X["column_10"] + pd.Timedelta(days=days)return X
Petua 2: Lelaran
"untuk gelung"
Cara pertama dan paling intuitif untuk lelaran ialah menggunakan Python untuk gelung.
def loop(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:res = []i_remove_col = df.columns.get_loc(remove_col)i_words_to_remove_col = df.columns.get_loc(words_to_remove_col)for i_row in range(df.shape[0]):res.append(remove_words(df.iat[i_row, i_remove_col], df.iat[i_row, i_words_to_remove_col]))return result
「apply」
def apply(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return df.apply(func=lambda x: remove_words(x[remove_col], x[words_to_remove_col]), axis=1).tolist()
Pada setiap lelaran df.apply, boleh panggil yang disediakan mendapat Siri yang indeksnya ialah df.columns dan nilainya ialah baris. Ini bermakna panda perlu menjana urutan dalam setiap gelung, yang mahal. Untuk mengurangkan kos, lebih baik hubungi apply pada subset df yang anda tahu akan anda gunakan, seperti ini:
def apply_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return df[[remove_col, words_to_remove_col]].apply(func=lambda x: remove_words(x[remove_col], x[words_to_remove_col]), axis=1)
「Kombinasi senarai + itertuples」
Sudah pasti lebih baik untuk melelaran menggunakan itertuple digabungkan dengan senarai. itertuples menjana (bernama) tupel dengan data baris.
def itertuples_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x[0], x[1])for x in df[[remove_col, words_to_remove_col]].itertuples(index=False, name=None)]
「Kombinasi senarai + zip」
zip menerima objek boleh lelar dan menjana tuple, di mana tuple ke-i mengandungi semua elemen ke-i bagi objek boleh lelar yang diberikan mengikut susunan.
def zip_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x, y) for x, y in zip(df[remove_col], df[words_to_remove_col])]
「Kombinasi senarai + to_dict」
def to_dict_only_used_columns(df: pd.DataFrame) -> list[str]:return [remove_words(row[remove_col], row[words_to_remove_col])for row in df[[remove_col, words_to_remove_col]].to_dict(orient="records")]
「Caching」
Selain daripada teknik lelaran yang kami bincangkan, dua kaedah lain boleh membantu meningkatkan prestasi kod: caching dan paralelization. Caching amat berguna jika anda memanggil fungsi panda beberapa kali dengan parameter yang sama. Sebagai contoh, jika remove_words digunakan pada set data dengan banyak nilai pendua, anda boleh menggunakan functools.lru_cache untuk menyimpan hasil fungsi dan mengelakkan pengiraan semula setiap kali. Untuk menggunakan lru_cache, cuma tambahkan penghias @lru_cache pada pengisytiharan remove_words dan kemudian gunakan fungsi tersebut pada set data anda menggunakan kaedah lelaran pilihan anda. Ini boleh meningkatkan kelajuan dan kecekapan kod anda dengan ketara. Ambil kod berikut sebagai contoh:
@lru_cachedef remove_words(...):... # Same implementation as beforedef zip_only_used_cols_cached(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x, y) for x, y in zip(df[remove_col], df[words_to_remove_col])]
Menambah penghias ini menjana fungsi yang "mengingat" output input yang ditemui sebelum ini, menghapuskan keperluan untuk menjalankan semua kod semula.
"Parallelization"
The truf card terakhir ialah menggunakan pandarel untuk menyelaraskan panggilan fungsi kami merentasi berbilang blok df bebas. Alat ini mudah digunakan: anda hanya mengimport dan memulakannya, kemudian menukar semua .applys kepada .parallel_applys.
rreeeeAtas ialah kandungan terperinci Dua petua hebat untuk meningkatkan kecekapan kod Pandas anda. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!