
Rumah >Peranti teknologi >AI >Perhatian Kilat-2: Mekanisme perhatian generasi baharu yang mencapai panjang jujukan tidak terhingga, kos kuasa pengkomputeran berterusan dan ketepatan pemodelan yang lebih tinggi
Perhatian Kilat-2: Mekanisme perhatian generasi baharu yang mencapai panjang jujukan tidak terhingga, kos kuasa pengkomputeran berterusan dan ketepatan pemodelan yang lebih tinggi

- 王林ke hadapan
- 2024-01-18 12:42:12937semak imbas
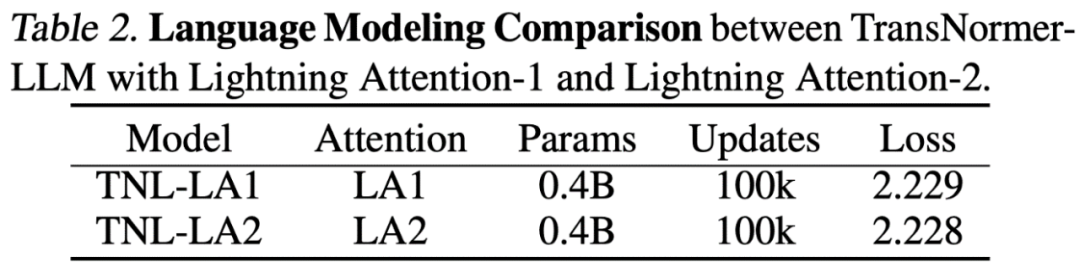
Lightning Attention-2 ialah mekanisme perhatian linear baharu yang menjadikan kos latihan dan inferens bagi jujukan panjang konsisten dengan panjang jujukan 1K.
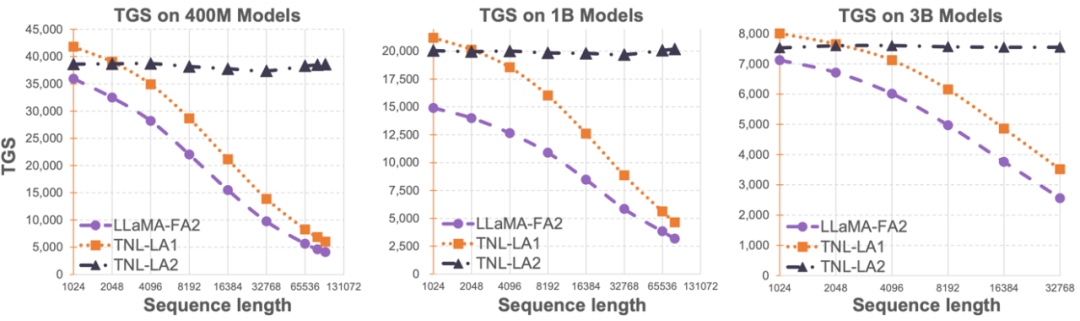 Gambar 1
Gambar 1
Kertas: Lightning Attention-2: Makan Tengahari Percuma untuk Mengendalikan Panjang Urutan Tanpa Had dalam Model Bahasa Besar Alamat kertas: https://arxiv.org/pdf/2401.04658.pdf alamat sumber:Open https ://github.com/OpenNLPLab/lightning-attention
Mengekalkan kelajuan pra-latihan yang konsisten, yang berbeza dari segi kelajuan yang besar pada setiap model ia berbunyi seperti Misi yang mustahil. Malah, ini boleh dicapai jika kerumitan pengiraan mekanisme perhatian kekal linear berkenaan dengan panjang jujukan. Sejak kemunculan perhatian linear [https://arxiv.org/abs/2006.16236] pada tahun 2020, penyelidik telah berusaha keras untuk menjadikan kecekapan sebenar perhatian linear konsisten dengan kerumitan pengiraan linear teorinya. Sebelum 2023, kebanyakan bekerja pada perhatian linear tertumpu pada menjajarkan ketepatannya dengan Transformers. Akhirnya pada pertengahan 2023, mekanisme perhatian linear yang dipertingkatkan [https://arxiv.org/abs/2307.14995] boleh diselaraskan dengan seni bina Transformer yang canggih dalam ketepatan. Walau bagaimanapun, helah pengiraan "daraban kiri kepada pendaraban kanan" yang paling kritikal (ditunjukkan dalam rajah di bawah) yang mengubah kerumitan pengiraan kepada linear dalam perhatian linear (seperti yang ditunjukkan dalam rajah di bawah) adalah lebih perlahan daripada algoritma pendaraban kiri langsung dalam sebenar. pelaksanaan. Sebabnya ialah pelaksanaan pendaraban kanan memerlukan penggunaan penjumlahan kumulatif (cumsum) yang mengandungi sejumlah besar operasi gelung Bilangan besar operasi IO menjadikan kecekapan pendaraban kanan jauh lebih rendah daripada pendaraban kiri.
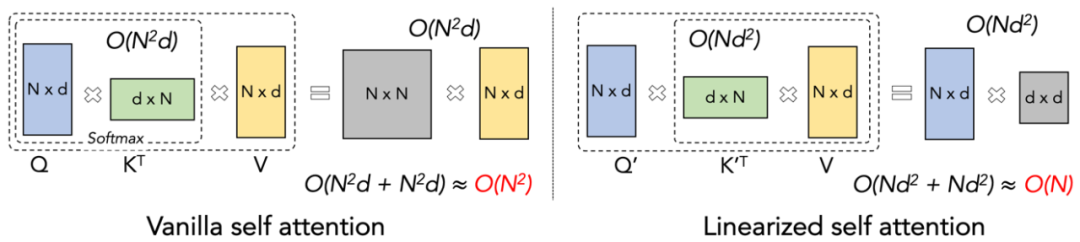
Untuk lebih memahami idea Lightning Attention-2, mari kita semak semula formula pengiraan softmax tradisional (Q^soft T)⊙ M_) V, dengan Q, K, V, M, O masing-masing adalah pertanyaan, kunci, nilai, topeng dan matriks keluaran M di sini ialah matriks semua-1 segi tiga yang lebih rendah dalam tugasan sehala (seperti GPT). . Dalam dua hala Ia boleh diabaikan dalam tugasan (seperti Bert), iaitu, tiada matriks topeng untuk tugasan dua hala.
Pengarang meringkaskan idea keseluruhan Lightning Attention-2 ke dalam tiga perkara berikut untuk penjelasan:
1 Salah satu idea teras Linear Attention adalah untuk mengeluarkan operator softmax yang mahal secara komputasi, membuat Perhatian Formula pengiraan boleh ditulis sebagai O=((QK^T)⊙M_) V. Walau bagaimanapun, disebabkan kewujudan matriks topeng M dalam tugasan sehala, borang ini masih boleh melakukan pengiraan pendaraban kiri sahaja, jadi kerumitan O (N) tidak dapat diperolehi. Tetapi untuk tugas dua hala, kerana tiada matriks topeng, formula pengiraan Perhatian Linear boleh dipermudahkan lagi kepada O=(QK^T) V. Kehalusan Perhatian Linear ialah dengan hanya menggunakan hukum bersekutu pendaraban matriks, formula pengiraannya boleh diubah lagi menjadi: O=Q (K^T V Borang pengiraan ini dipanggil pendaraban betul, dan bekas yang sepadan ialah Ambil kiri. Daripada Rajah 2, kita secara intuitif dapat memahami bahawa Perhatian Linear boleh mencapai kerumitan O (N) yang menarik dalam tugasan dua arah!
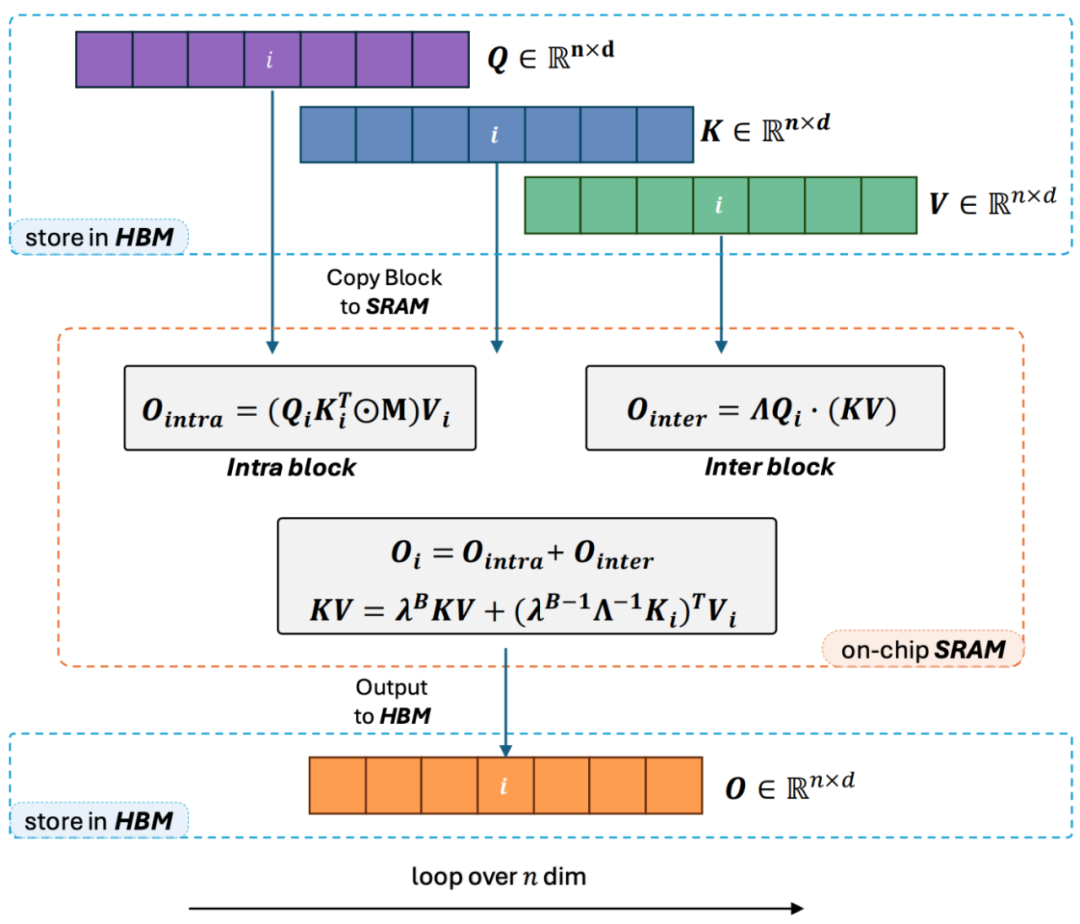
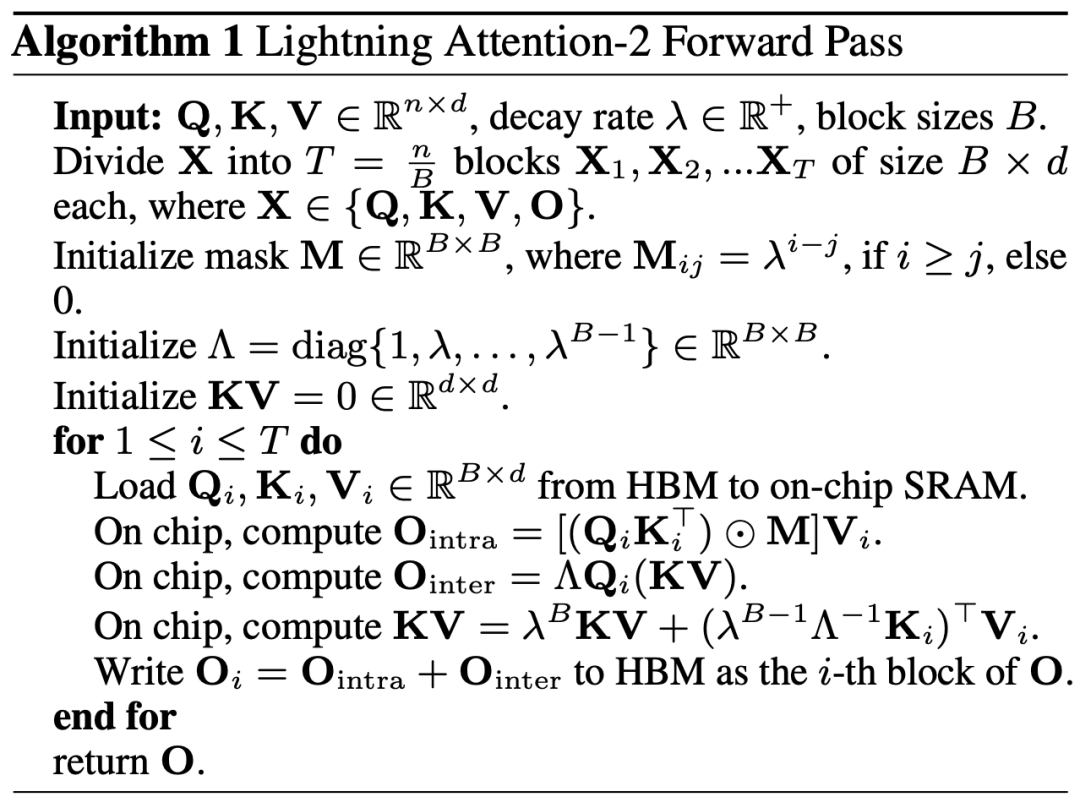
2 Namun, memandangkan model GPT penyahkod sahaja secara beransur-ansur menjadi standard de facto untuk LLM, cara menggunakan ciri pendaraban Linear Attention yang betul untuk mempercepatkan tugasan sehala telah menjadi masalah mendesak untuk diselesaikan. Untuk menyelesaikan masalah ini, penulis artikel ini mencadangkan untuk menggunakan idea "bahagi dan menakluki" untuk membahagikan pengiraan matriks perhatian kepada dua bentuk: matriks pepenjuru dan matriks bukan pepenjuru, dan menggunakan kaedah yang berbeza. cara untuk mengira mereka. Seperti yang ditunjukkan dalam Rajah 3, Linear Attention-2 menggunakan idea Tiling yang biasa digunakan dalam medan komputer untuk membahagikan matriks Q, K, dan V kepada bilangan blok yang sama. Antaranya, pengiraan bongkah itu sendiri (intra-blok) masih mengekalkan kaedah pengiraan pendaraban kiri kerana kewujudan matriks topeng, dengan kerumitan O (N^2 manakala pengiraan bongkah (antara-); blok) tidak mempunyai matriks topeng Dengan kewujudan , anda boleh menggunakan kaedah pengiraan pendaraban yang betul untuk menikmati kerumitan O (N). Selepas kedua-duanya dikira secara berasingan, ia boleh ditambah terus untuk mendapatkan output Perhatian Linear Oi sepadan dengan blok ke-i. Pada masa yang sama, keadaan KV terkumpul melalui cumsum untuk digunakan dalam pengiraan blok seterusnya. Dengan cara ini, kerumitan algoritma bagi keseluruhan Lightning Attention-2 ialah O (N^2) untuk intra-blok dan O (N) untuk Trade-off antara blok. Cara untuk mendapatkan pertukaran yang lebih baik ditentukan oleh saiz blok Tiling.
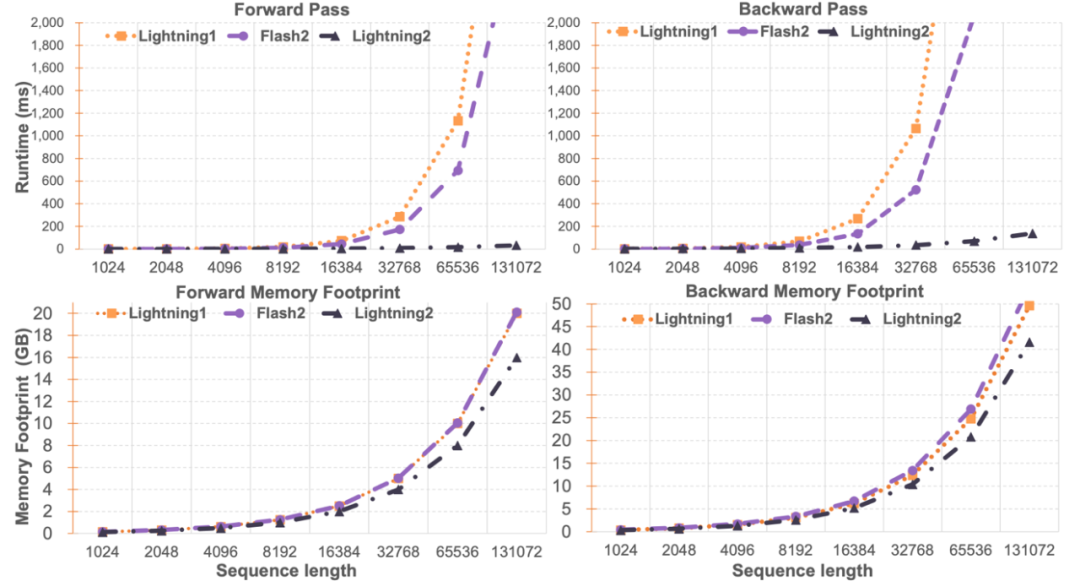
3 Pembaca yang berhati-hati akan mendapati bahawa proses di atas hanyalah bahagian algoritma Lightning Attention-2 Sebab mengapa ia dinamakan Lightning adalah kerana penulis mempertimbangkan sepenuhnya kecekapan proses algoritma dalam pelaksanaan perkakasan GPU. proses. Diilhamkan oleh siri kerja FlashAttention, apabila benar-benar melakukan pengiraan pada GPU, pengarang mengalihkan tensor Q_i, K_i, V_i split daripada HBM yang lebih perlahan dengan kapasiti yang lebih besar di dalam GPU kepada SRAM yang lebih pantas dengan kapasiti yang lebih kecil sistem, dengan itu mengurangkan sejumlah besar overhed IO memori.Selepas blok melengkapkan pengiraan Perhatian Linear, hasil keluarannya O_i akan dialihkan kembali ke HBM. Ulangi proses ini sehingga semua blok telah diproses.


Atas ialah kandungan terperinci Perhatian Kilat-2: Mekanisme perhatian generasi baharu yang mencapai panjang jujukan tidak terhingga, kos kuasa pengkomputeran berterusan dan ketepatan pemodelan yang lebih tinggi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:
Artikel ini dikembalikan pada:jiqizhixin.com. Jika ada pelanggaran, sila hubungi admin@php.cn Padam
Artikel sebelumnya:Yidako Chuang telah dianugerahkan Kecerdasan Buatan "Anugerah Vitality Inovasi Industri", berita baik untuk memulakan tahun baru!Artikel seterusnya:Yidako Chuang telah dianugerahkan Kecerdasan Buatan "Anugerah Vitality Inovasi Industri", berita baik untuk memulakan tahun baru!
Artikel berkaitan
Lihat lagi- 世界vr产业大会地址在哪
- Peraturan baharu untuk bulan Oktober ada di sini! Melibatkan papan tanda lalu lintas jalan baharu, industri kecerdasan buatan, dsb.
- Mengambil 'Exhibition Express', Qingdao Artificial Intelligence Industrial Park meneroka cara baharu untuk menarik pelaburan
- Memfokuskan pada ekosistem perniagaan digital dan industri metaverse, Lujiazui Digital Intelligence World berusaha untuk mencipta kluster industri elemen data
- Liu Qiang: Membina ekosistem kandungan industri pelancongan budaya Internet generasi seterusnya