
Rumah >Peranti teknologi >AI >Google melancarkan set data BIG-Bench Mistake untuk membantu AI meningkatkan keupayaan pembetulan ralat
Google melancarkan set data BIG-Bench Mistake untuk membantu AI meningkatkan keupayaan pembetulan ralat

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-16 18:57:16682semak imbas
Google Research baru-baru ini menjalankan kajian penilaian ke atas model bahasa popular, menggunakan penanda aras BIG-Bench sendiri dan set data "BIG-Bench Mistake" yang baru ditubuhkan. Mereka tertumpu terutamanya pada kebarangkalian ralat dan keupayaan pembetulan ralat model bahasa. Kajian ini menyediakan data berharga untuk lebih memahami prestasi model bahasa di pasaran.
Penyelidik Google berkata mereka mencipta set data penanda aras khas yang dipanggil "BIG-Bench Mistake" untuk menilai "kebarangkalian ralat" dan "keupayaan pembetulan diri" model bahasa yang besar. Ini disebabkan oleh kekurangan set data yang sepadan pada masa lalu untuk menilai dan menguji penunjuk utama ini dengan berkesan.
Para penyelidik menggunakan model bahasa PaLM untuk menjalankan 5 tugasan dalam tugasan penanda aras BIG-Bench mereka sendiri, dan menambahkan trajektori "Chain-of-Thought" yang dijana pada bahagian "Logic Error" untuk menguji semula ketepatan Model.
Untuk meningkatkan ketepatan set data, penyelidik Google mengulangi proses di atas dan akhirnya mencipta set data penanda aras khusus untuk penilaian, yang mengandungi 255 ralat logik, yang dipanggil "BIG-Bench Mistake".
Para penyelidik menegaskan bahawa ralat logik dalam set data "BIG-Bench Mistake" sangat jelas, jadi ia boleh digunakan sebagai standard yang baik untuk ujian model bahasa. Set data ini membantu model belajar daripada ralat mudah dan secara beransur-ansur meningkatkan keupayaannya untuk mengenal pasti ralat.
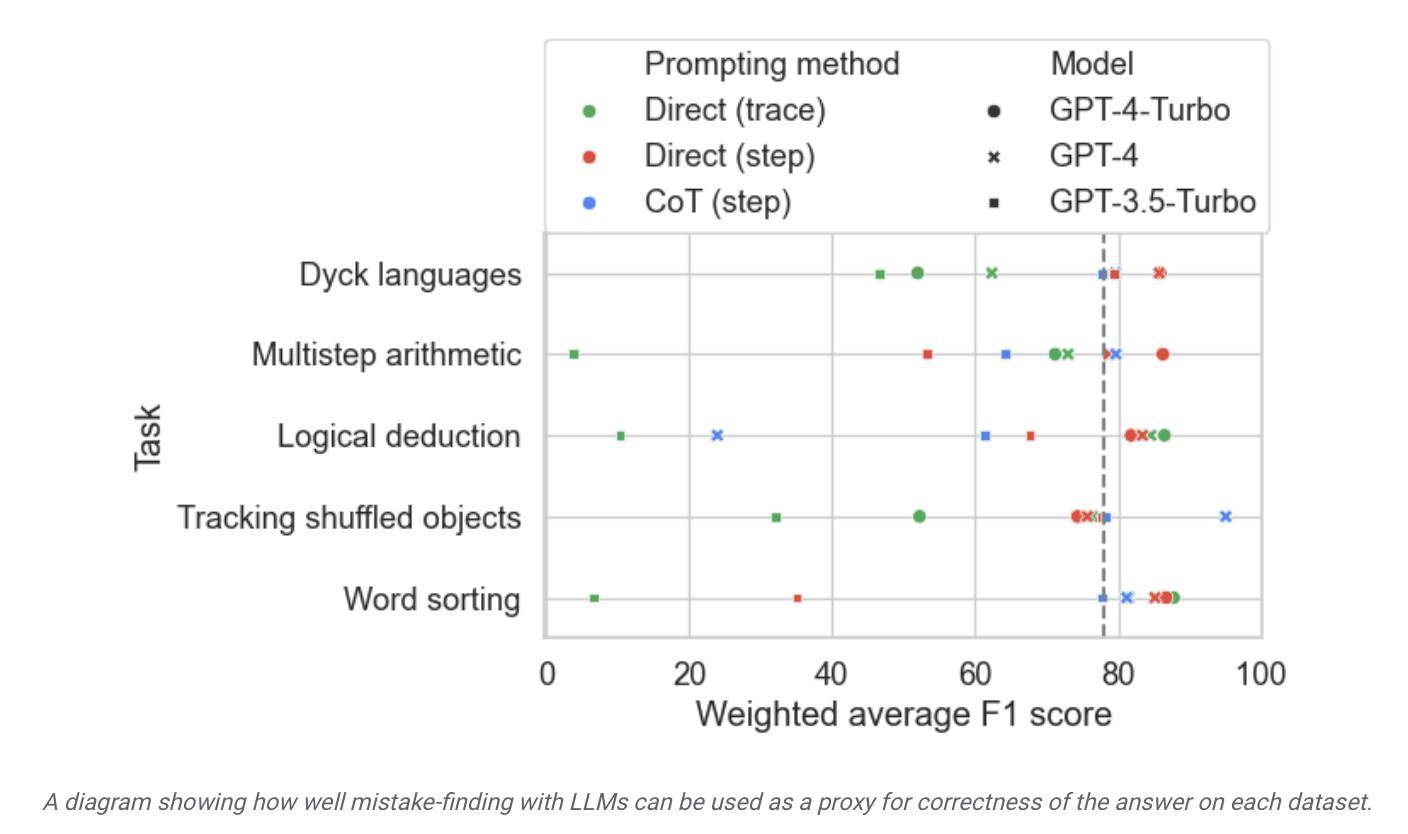
Para penyelidik menggunakan set data ini untuk menguji model di pasaran dan mendapati bahawa walaupun kebanyakan model bahasa boleh mengenal pasti ralat logik dalam proses penaakulan dan membetulkannya sendiri, proses ini tidak begitu ideal. Selalunya, campur tangan manusia juga diperlukan untuk membetulkan apa yang dihasilkan oleh model.
▲ Sumber gambar siaran akhbar Google Research
Menurut laporan itu, Google mendakwa bahawa ia dianggap sebagai model bahasa besar yang paling maju pada masa ini, tetapi keupayaan pembetulan sendirinya agak terhad. Dalam ujian, model berprestasi terbaik mendapati hanya 52.9% ralat logik.

Penyelidik Google juga mendakwa bahawa set data BIG-Bench Mistake ini kondusif untuk meningkatkan keupayaan pembetulan kendiri model Selepas memperhalusi model pada tugas ujian yang berkaitan, "walaupun model kecil biasanya berprestasi lebih baik daripada model besar dengan gesaan sampel sifar. " ".
Menurut ini, Google percaya bahawa dari segi pembetulan ralat model, model kecil proprietari boleh digunakan untuk "mengawasi" model besar daripada membiarkan model bahasa besar belajar "membetulkan kesilapan diri", menggunakan model khusus kecil yang didedikasikan untuk menyelia. model besar bermanfaat untuk meningkatkan kecekapan, mengurangkan kos penggunaan AI yang berkaitan dan memudahkan penalaan halus.
Atas ialah kandungan terperinci Google melancarkan set data BIG-Bench Mistake untuk membantu AI meningkatkan keupayaan pembetulan ralat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI