
Rumah >Peranti teknologi >AI >Model kecil tetapi hebat semakin meningkat: TinyLlama dan LiteLlama menjadi pilihan popular
Model kecil tetapi hebat semakin meningkat: TinyLlama dan LiteLlama menjadi pilihan popular

- WBOYke hadapan
- 2024-01-14 12:27:151440semak imbas
Pada masa ini, penyelidik mula menumpukan pada model kecil yang padat dan berprestasi tinggi, walaupun semua orang sedang mengkaji model besar dengan skala parameter mencecah puluhan bilion atau bahkan ratusan bilion.
Model kecil digunakan secara meluas dalam peranti tepi, seperti telefon pintar, peranti IoT dan sistem terbenam. Peranti ini selalunya mempunyai kuasa pengkomputeran dan ruang storan yang terhad dan tidak dapat menjalankan model bahasa yang besar dengan cekap. Oleh itu, mengkaji model kecil menjadi sangat penting.
Dua kajian yang akan kami perkenalkan seterusnya mungkin memenuhi keperluan anda untuk model kecil.
TinyLlama-1.1B
Para penyelidik di Universiti Teknologi dan Reka Bentuk Singapura (SUTD) baru-baru ini mengeluarkan TinyLlama, model bahasa dengan 1.1 bilion parameter yang telah dilatih pada kira-kira 3 trilion kereta api.

- Alamat kertas: https://arxiv.org/pdf/2401.02385.pdf
- Alamat projek: https://jzhubhang README_zh-CN.md
TinyLlama adalah berdasarkan seni bina dan tokenizer Llama 2, yang menjadikannya mudah untuk disepadukan dengan banyak projek sumber terbuka menggunakan Llama. Selain itu, TinyLlama hanya mempunyai 1.1 bilion parameter dan bersaiz kecil, menjadikannya sesuai untuk aplikasi yang memerlukan pengiraan terhad dan jejak memori.
Kajian menunjukkan bahawa hanya 16 GPU A100-40G boleh melengkapkan latihan TinyLlama dalam masa 90 hari.

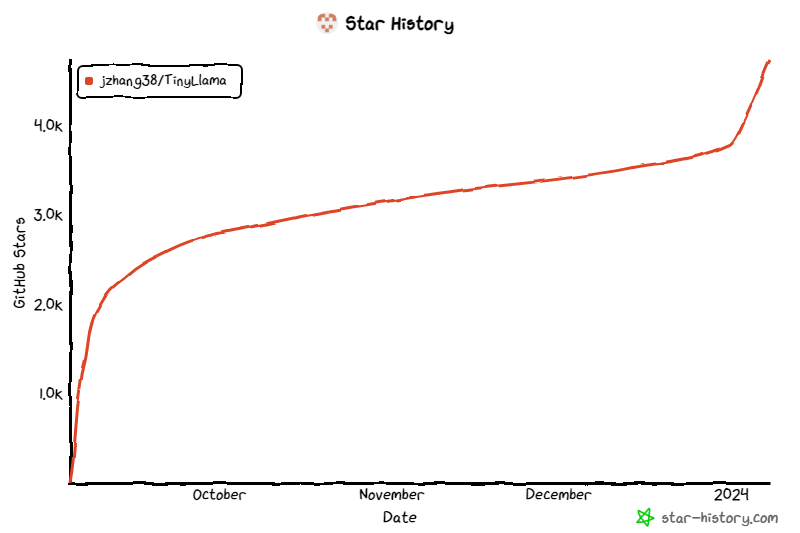
Projek ini terus mendapat perhatian sejak dilancarkan, dan bilangan bintang semasa mencecah 4.7K.
Perincian seni bina model TinyLlama adalah seperti berikut:

Butiran latihan adalah seperti berikut:
yang penyelidik mengatakan ini bertujuan untuk melombong penggunaan yang lebih besar data Potensi untuk melatih model yang lebih kecil. Mereka menumpukan pada meneroka gelagat model yang lebih kecil apabila dilatih dengan bilangan token yang jauh lebih besar daripada yang disyorkan oleh undang-undang penskalaan. 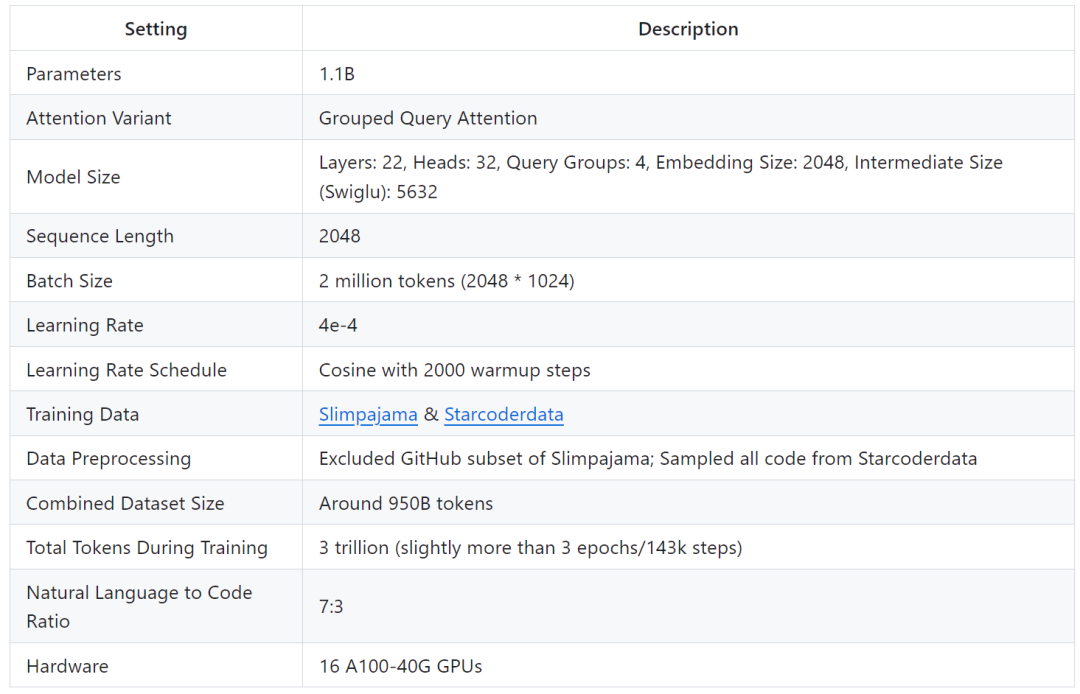
Walaupun saiznya agak kecil, TinyLlama berprestasi agak baik pada pelbagai tugas hiliran, dengan ketara mengatasi model bahasa sumber terbuka sedia ada dengan saiz yang sama. Khususnya, TinyLlama mengatasi prestasi OPT-1.3B dan Pythia1.4B dalam pelbagai tugas hiliran.
Selain itu, TinyLlama juga menggunakan pelbagai kaedah pengoptimuman, seperti flash attention 2, FSDP (Fully Sharded Data Parallel), xFormers, dll.
Dengan sokongan teknologi ini, daya tampung latihan TinyLlama mencapai 24,000 token sesaat setiap GPU A100-40G. Contohnya, model TinyLlama-1.1B hanya memerlukan 3,456 jam GPU A100 untuk token 300B, berbanding 4,830 jam untuk Pythia dan 7,920 jam untuk MPT. Ini menunjukkan keberkesanan pengoptimuman kajian ini dan potensi untuk menjimatkan masa dan sumber yang ketara dalam latihan model berskala besar.
TinyLlama mencapai kelajuan latihan 24k token/saat/A100 Kelajuan ini bersamaan dengan model chinchilla-optimum dengan 1.1 bilion parameter dan 22 bilion token yang boleh dilatih oleh pengguna dalam 32 jam pada 8 A100. Pada masa yang sama, pengoptimuman ini juga sangat mengurangkan penggunaan memori. Pengguna boleh memasukkan model parameter 1.1 bilion ke dalam GPU 40GB sambil mengekalkan saiz kumpulan per-gpu sebanyak 16k token. Cuma tukar saiz kelompok sedikit lebih kecil, dan anda boleh melatih TinyLlama pada RTX 3090/4090.
 Dalam eksperimen, penyelidikan ini tertumpu terutamanya pada model bahasa dengan seni bina penyahkod tulen, yang mengandungi kira-kira 1 bilion parameter. Secara khusus, kajian itu membandingkan TinyLlama dengan OPT-1.3B, Pythia-1.0B dan Pythia-1.4B.
Dalam eksperimen, penyelidikan ini tertumpu terutamanya pada model bahasa dengan seni bina penyahkod tulen, yang mengandungi kira-kira 1 bilion parameter. Secara khusus, kajian itu membandingkan TinyLlama dengan OPT-1.3B, Pythia-1.0B dan Pythia-1.4B.
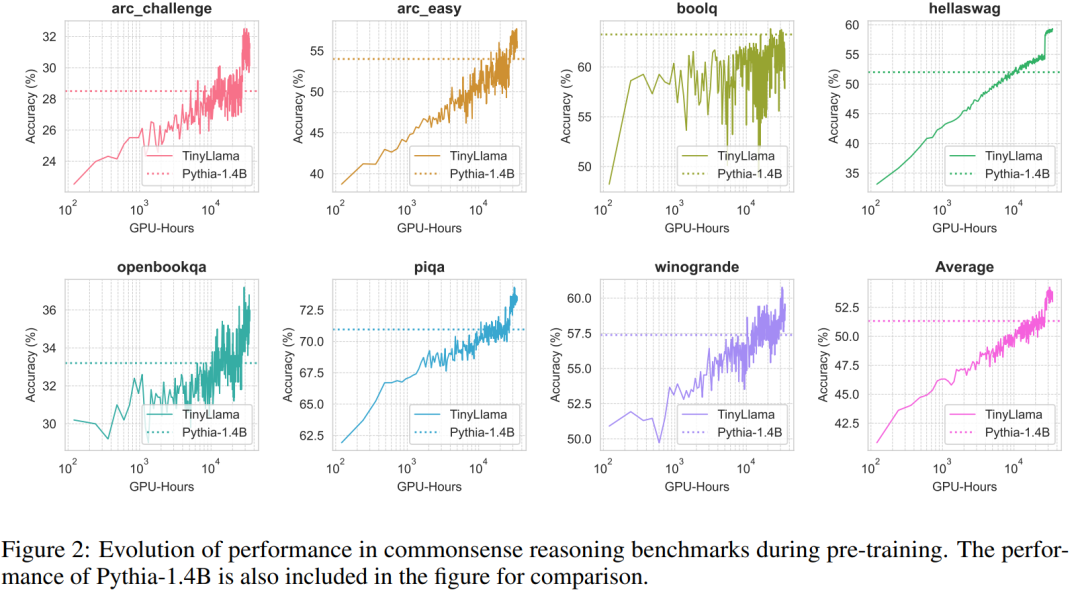
Prestasi TinyLlama pada tugas penaakulan akal ditunjukkan di bawah. Dapat dilihat bahawa TinyLlama mengatasi garis dasar pada banyak tugas dan memperoleh skor purata tertinggi.

Di samping itu, para penyelidik menjejaki ketepatan TinyLlama pada tanda aras penaakulan akal semasa pra-latihan Seperti yang ditunjukkan dalam Rajah 2, prestasi TinyLlama bertambah baik dengan peningkatan dalam sumber pengkomputeran, dalam kebanyakan tanda aras Exce. ketepatan Pythia-1.4B.
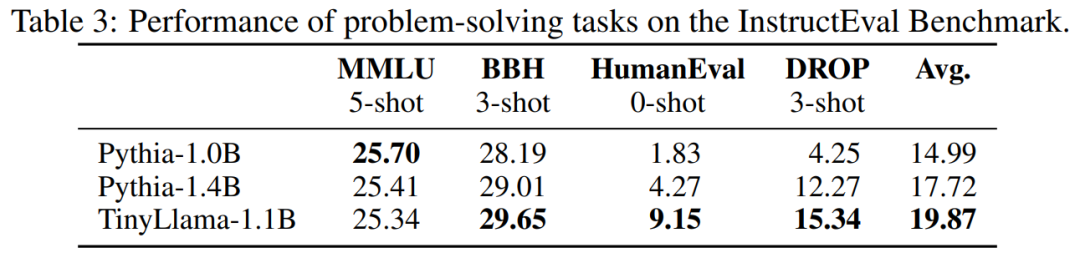
Jadual 3 menunjukkan bahawa TinyLlama mempamerkan keupayaan menyelesaikan masalah yang lebih baik berbanding model sedia ada. .
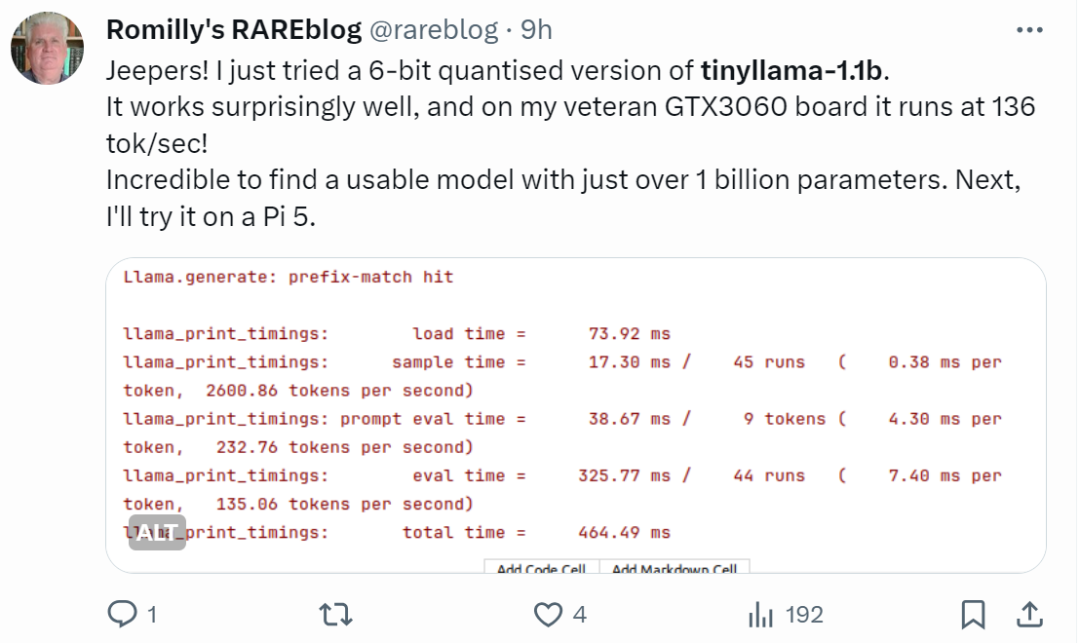
"Ia benar-benar pantas!"
Model Kecil LiteLlama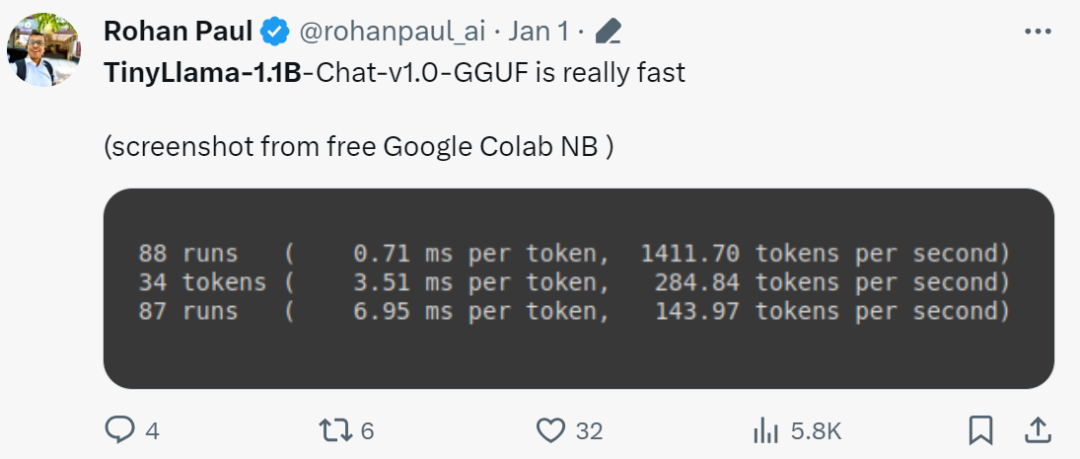
Bahasa
sebarkan perhatian. Xiaotian Han dari Texas Tech dan A&M University mengeluarkan SLM-LiteLlama. Ia mempunyai parameter 460M dan dilatih dengan token 1T. Ini ialah garpu sumber terbuka LLaMa 2 Meta AI, tetapi dengan saiz model yang jauh lebih kecil.
Alamat projek: https://huggingface.co/ahxt/LiteLlama-460M-1T
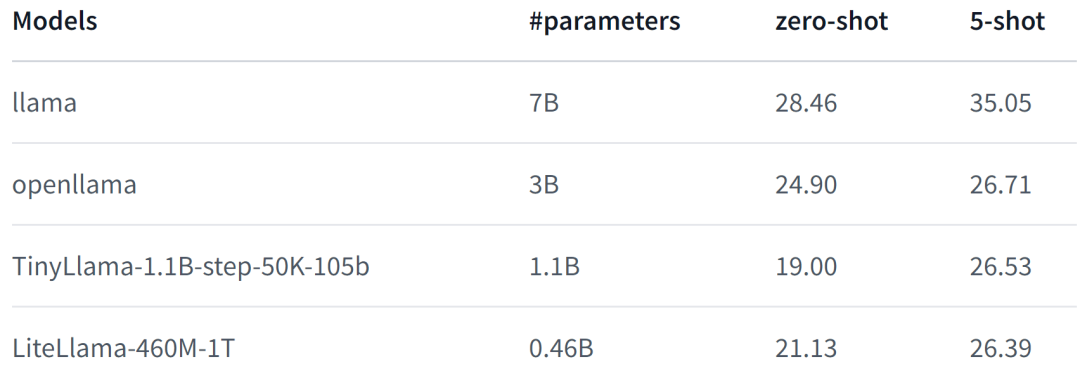
LiteLlama-460M-1T dilatih pada set data RedPajama2 untuk mengguna pakai set data GPTkena2 dan teks Penulis menilai model pada tugas MMLU, dan hasilnya ditunjukkan dalam rajah di bawah Walaupun dengan pengurangan ketara dalam bilangan parameter, LiteLlama-460M-1T masih boleh mencapai hasil yang setanding atau lebih baik daripada model lain. .
Menghadapi skala LiteLlama telah banyak dikurangkan, dan sesetengah netizen ingin tahu sama ada ia boleh dijalankan pada memori 4GB. Kalau nak tahu juga, apa kata cuba sendiri.
Atas ialah kandungan terperinci Model kecil tetapi hebat semakin meningkat: TinyLlama dan LiteLlama menjadi pilihan popular. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!