
Rumah >Peranti teknologi >AI >Tafsiran baharu tahap kecerdasan GPT-4 yang semakin menurun
Tafsiran baharu tahap kecerdasan GPT-4 yang semakin menurun

- 王林ke hadapan
- 2024-01-14 12:15:051271semak imbas
GPT-4, yang telah dianggap sebagai salah satu model bahasa yang paling berkuasa di dunia sejak dikeluarkan, malangnya telah mengalami beberapa siri krisis kepercayaan.
Khabar angin baru-baru ini bahawa GPT-4 telah menjadi "malas" lebih menarik jika kita menghubungkan insiden "intermittent intelligence" awal tahun ini dengan reka bentuk semula OpenAI bagi seni bina GPT-4. Seseorang telah menguji dan mendapati bahawa selagi anda memberitahu GPT-4 "ia adalah percutian musim sejuk", ia akan menjadi malas, seolah-olah ia telah memasuki keadaan hibernasi.
Untuk menyelesaikan masalah prestasi sifar sampel model yang lemah pada tugasan baharu, kami boleh mengambil kaedah berikut: 1. Peningkatan data: Meningkatkan keupayaan generalisasi model dengan mengembangkan dan mengubah data sedia ada. Contohnya, data imej boleh diubah dengan putaran, penskalaan, terjemahan, dsb., atau dengan mensintesis sampel data baharu. 2. Memindahkan pembelajaran: Gunakan model yang telah dilatih mengenai tugasan lain untuk memindahkan parameter dan pengetahuan mereka kepada tugasan baharu. Ini boleh memanfaatkan pengetahuan dan pengalaman sedia ada untuk meningkatkan prestasi GPT-4 Baru-baru ini, penyelidik dari University of California, Santa Cruz menerbitkan penemuan baharu dalam kertas kerja yang mungkin dapat menjelaskan kemerosotan prestasi GPT-4 .
 "Kami mendapati bahawa LLM menunjukkan prestasi yang lebih baik pada set data yang dikeluarkan sebelum tarikh penciptaan data latihan berbanding set data yang dikeluarkan selepasnya." tugasan baru. Ini bermakna LLM hanyalah kaedah meniru kecerdasan berdasarkan perolehan anggaran, terutamanya menghafal sesuatu tanpa sebarang tahap pemahaman.
"Kami mendapati bahawa LLM menunjukkan prestasi yang lebih baik pada set data yang dikeluarkan sebelum tarikh penciptaan data latihan berbanding set data yang dikeluarkan selepasnya." tugasan baru. Ini bermakna LLM hanyalah kaedah meniru kecerdasan berdasarkan perolehan anggaran, terutamanya menghafal sesuatu tanpa sebarang tahap pemahaman.
Secara terus terang, keupayaan generalisasi LLM adalah "tidak sekuat yang dinyatakan" - asasnya tidak kukuh, dan akan sentiasa ada kesilapan dalam pertempuran sebenar.
Sebab utama keputusan ini ialah "pencemaran tugas", yang merupakan salah satu bentuk pencemaran data. Pencemaran data yang kita kenal sebelum ini ialah pencemaran data ujian, iaitu kemasukan contoh dan label data ujian dalam data pra-latihan. "Pencemaran tugas" ialah penambahan contoh latihan tugasan kepada data pra-latihan, menjadikan penilaian dalam kaedah sampel sifar atau beberapa sampel tidak lagi realistik dan berkesan.
Pengkaji menjalankan analisis sistematik terhadap masalah pencemaran data buat kali pertama dalam makalah:
Pautan kertas: https://arxiv.org/pdf/23312.pdf/23312.pdf Selepas membaca ini Dalam kertas itu, seseorang berkata "secara pesimis":
Inilah nasib semua model pembelajaran mesin (ML) yang tidak mempunyai keupayaan pembelajaran berterusan, iaitu, berat model ML akan dibekukan selepas latihan tetapi pengedaran input akan terus berubah, dan jika model tidak dapat terus menyesuaikan diri dengan perubahan ini, ia akan perlahan-lahan merosot.
Ini bermakna apabila bahasa pengaturcaraan sentiasa dikemas kini, alat pengekodan berasaskan LLM juga akan merosot. Ini adalah salah satu sebab mengapa anda tidak perlu terlalu bergantung pada alat yang rapuh itu.Melatih semula model ini secara berterusan adalah mahal, dan lambat laun seseorang akan berputus asa dengan kaedah yang tidak cekap ini.
Pada masa ini tiada model ML yang boleh dipercayai dan berterusan menyesuaikan diri dengan perubahan pengagihan input tanpa menyebabkan gangguan teruk atau kehilangan prestasi pada tugas pengekodan sebelumnya. Dan ini adalah salah satu bidang di mana rangkaian saraf biologi mahir. Disebabkan oleh keupayaan generalisasi rangkaian saraf biologi yang kukuh, pembelajaran tugasan yang berbeza boleh meningkatkan lagi prestasi sistem, kerana pengetahuan yang diperoleh daripada satu tugasan membantu meningkatkan keseluruhan proses pembelajaran itu sendiri, yang dipanggil "pembelajaran meta". Seberapa serius masalah "pencemaran tugas"? Mari kita lihat kandungan kertas itu.
Model dan Set Data
Terdapat 12 model yang digunakan dalam percubaan (seperti yang ditunjukkan dalam Jadual 1), 5 daripadanya adalah model siri GPT-3 dan 7 adalah model terbuka dengan berat bebas.
Set data terbahagi kepada dua kategori: set data yang dikeluarkan sebelum atau selepas 1 Januari 2021. Penyelidik menggunakan kaedah pembahagian ini untuk menganalisis perbezaan antara set data lama dan set data sampel baharu atau sedikit perbezaan prestasi sampel, dan menggunakan kaedah pembahagian yang sama untuk semua LLM. Jadual 1 menyenaraikan masa penciptaan setiap data latihan model, dan Jadual 2 menyenaraikan tarikh keluaran setiap set data.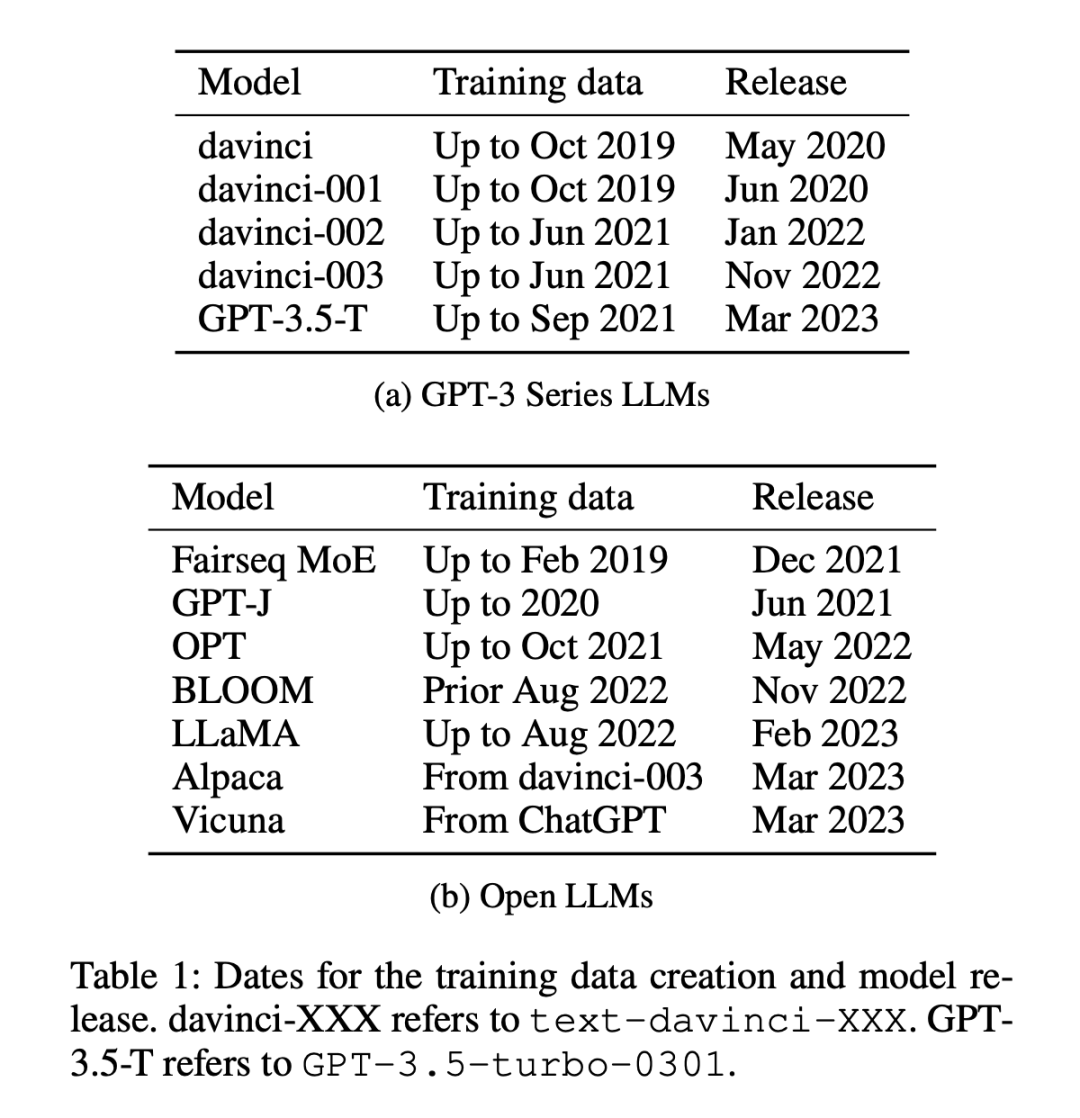
Pertimbangan untuk pendekatan di atas ialah penilaian sifar dan beberapa pukulan melibatkan model yang membuat ramalan tentang tugasan yang tidak pernah dilihat atau hanya dilihat beberapa kali semasa latihan tugas khusus yang perlu diselesaikan, dengan itu Memastikan penilaian yang adil terhadap kebolehan pembelajaran mereka. Walau bagaimanapun, model yang tercemar boleh memberikan ilusi kecekapan yang mereka tidak pernah didedahkan atau hanya didedahkan beberapa kali kerana mereka telah dilatih mengenai contoh tugas semasa pra-latihan. Dalam set data kronologi, lebih mudah untuk mengesan ketidakkonsistenan tersebut, kerana sebarang pertindihan atau anomali akan menjadi jelas.
Kaedah pengukuran
Para penyelidik menggunakan empat kaedah untuk mengukur "pencemaran tugas":
- Pemeriksaan data latihan: Cari contoh latihan tugasan dalam data latihan.
- Pengekstrakan contoh tugas: Ekstrak contoh tugas daripada model sedia ada. Hanya model yang ditala arahan boleh diekstrak Analisis ini juga boleh digunakan untuk data latihan atau pengekstrakan data ujian. Ambil perhatian bahawa untuk mengesan pencemaran tugas, contoh tugas yang diekstrak tidak perlu sepadan dengan contoh data latihan sedia ada. Mana-mana contoh yang menunjukkan tugasan menunjukkan kemungkinan pencemaran pembelajaran sifar pukulan dan pembelajaran beberapa pukulan.
- Inferens Ahli: Kaedah ini hanya sesuai untuk tugas penjanaan. Menyemak bahawa kandungan yang dijana model untuk contoh input adalah betul-betul sama dengan set data asal. Jika ia sepadan dengan tepat, kita boleh membuat kesimpulan bahawa ia adalah ahli data latihan LLM. Ini berbeza daripada pengekstrakan contoh tugas kerana output yang dijana disemak untuk padanan yang tepat. Padanan tepat pada tugas penjanaan terbuka sangat menunjukkan bahawa model melihat contoh ini semasa latihan, melainkan model itu "psikik" dan mengetahui perkataan tepat yang digunakan dalam data. (Nota, ini hanya boleh digunakan untuk membina tugasan.)
- Analisis masa: Untuk set model yang data latihan dikumpulkan dalam jangka masa yang diketahui, ukur prestasinya pada set data dengan tarikh keluaran yang diketahui dan semak pencemaran menggunakan pemasaan bukti bukti.
Tiga kaedah pertama mempunyai ketepatan yang tinggi, tetapi kadar ingatan yang rendah. Jika anda boleh mencari data dalam data latihan tugasan, anda boleh yakin bahawa model telah melihat contoh. Walau bagaimanapun, disebabkan oleh perubahan dalam format data, perubahan dalam kata kunci yang digunakan untuk mentakrifkan tugas, dan saiz set data, mendapati tiada bukti pencemaran menggunakan tiga kaedah pertama tidak membuktikan ketiadaan pencemaran.
Kaedah keempat, analisis kronologi mempunyai kadar ingatan yang tinggi tetapi ketepatan yang rendah. Jika prestasi tinggi disebabkan oleh pencemaran tugas, maka analisis kronologi mempunyai peluang yang baik untuk mengesannya. Tetapi faktor lain juga mungkin menyebabkan prestasi bertambah baik dari semasa ke semasa dan oleh itu menjadi kurang tepat.
Oleh itu, penyelidik menggunakan keempat-empat kaedah untuk mengesan pencemaran tugas dan menemui bukti kukuh pencemaran tugas dalam kombinasi model dan set data tertentu.
Mereka mula-mula melakukan analisis masa pada semua model dan set data yang diuji kerana kemungkinan besar akan mengesan kemungkinan pencemaran, kemudian menggunakan pemeriksaan data latihan dan pengekstrakan contoh tugas untuk mencari bukti selanjutnya mengenai pencemaran tugasan; -tugas percuma, dan akhirnya analisis tambahan menggunakan serangan inferens keahlian.
Kesimpulan utama adalah seperti berikut:
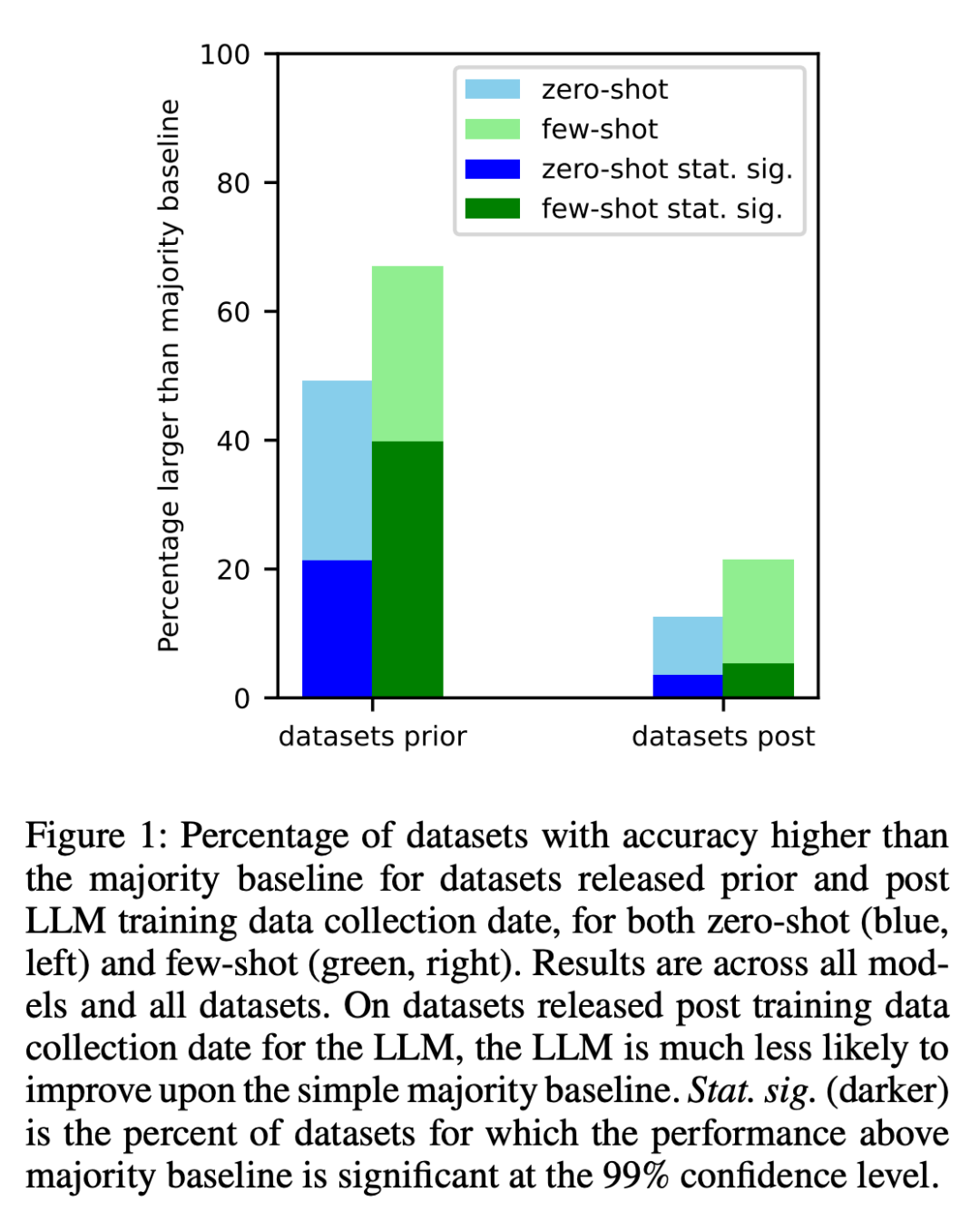
1. Para penyelidik menganalisis set data yang dibuat sebelum dan selepas data latihan setiap model dirangkak di Internet. Didapati bahawa kemungkinan prestasi melebihi kebanyakan garis dasar adalah lebih tinggi dengan ketara untuk set data yang dibuat sebelum mengumpul data latihan LLM (Rajah 1).
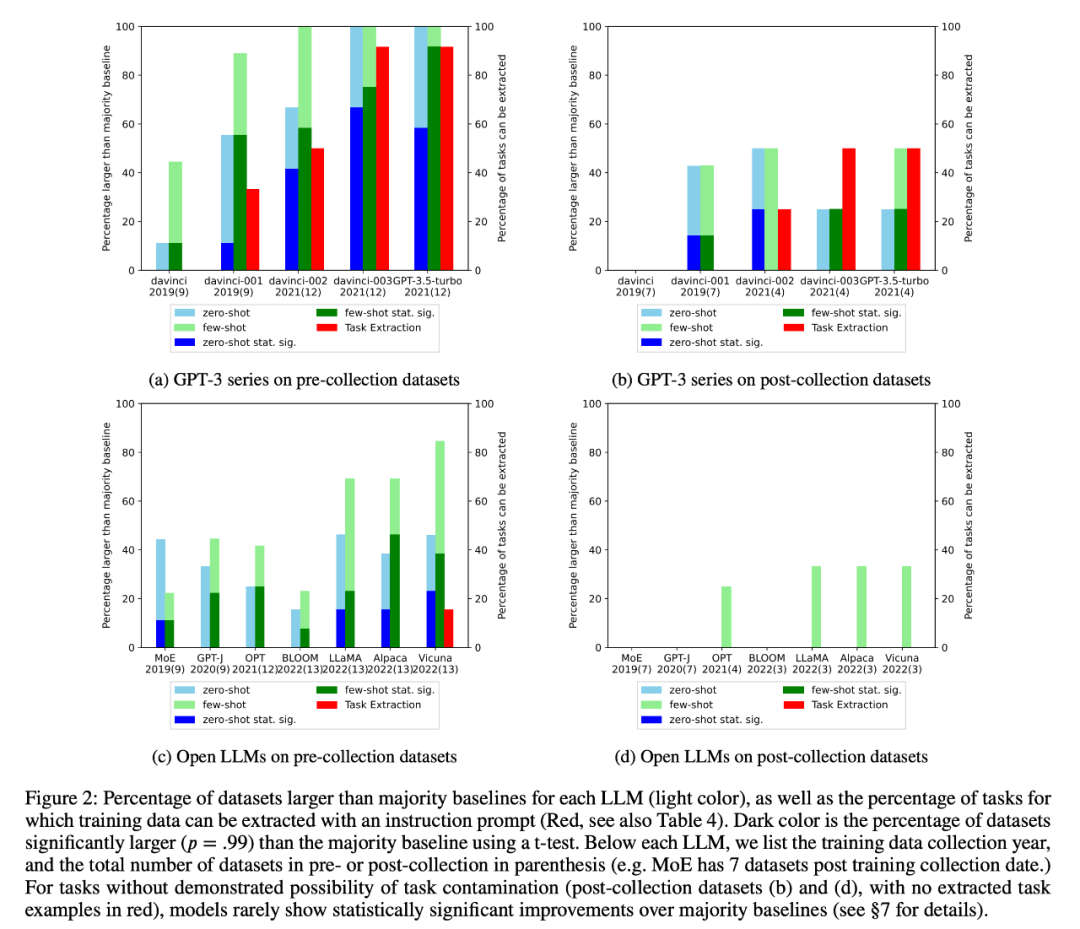
2. Penyelidik menjalankan pemeriksaan data latihan dan pengekstrakan contoh tugasan untuk mencari kemungkinan pencemaran tugas. Telah didapati bahawa untuk tugasan pengelasan di mana pencemaran tugas tidak mungkin, model jarang mencapai peningkatan ketara secara statistik berbanding garis dasar majoriti mudah merentas pelbagai tugas, sama ada sifar atau beberapa pukulan (Rajah 2).
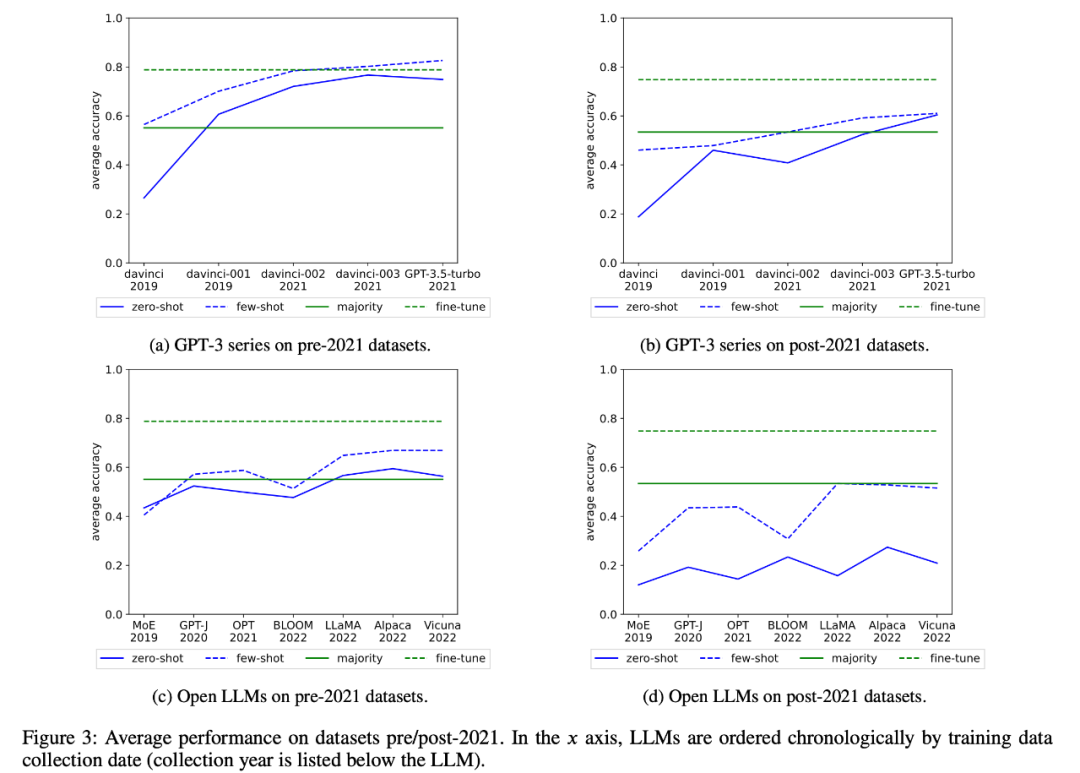
Para penyelidik juga menyemak prestasi purata siri GPT-3 dan membuka LLM dari semasa ke semasa, seperti yang ditunjukkan dalam Rajah 3:
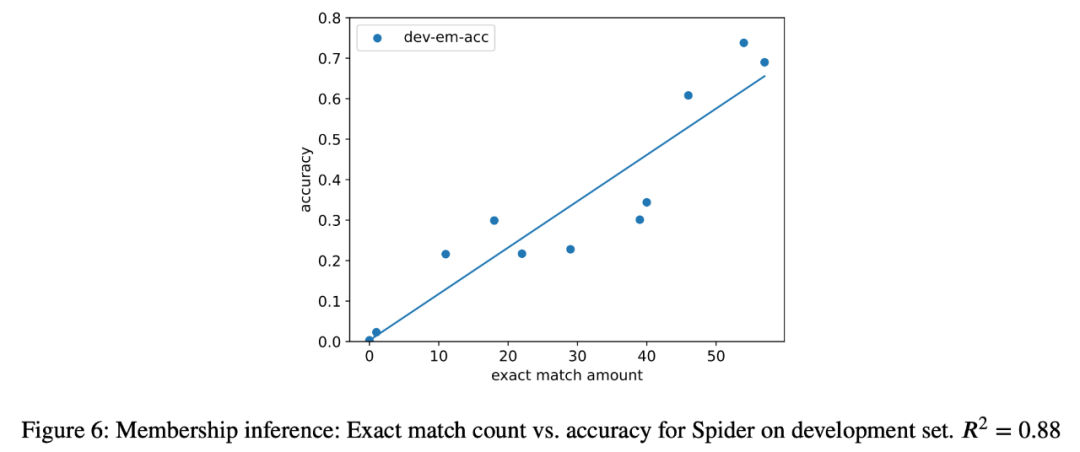
penyelidik Serangan inferens ahli terhadap tugas penghuraian semantik juga telah dicuba pada semua model dalam analisis dan korelasi yang kuat (R=.88) didapati antara bilangan contoh yang diekstrak dan ketepatan model dalam tugasan akhir (Rajah 6). ). Ini sangat membuktikan bahawa peningkatan prestasi sifar pukulan dalam tugasan ini adalah disebabkan oleh pencemaran tugas.
4 Para penyelidik juga mengkaji dengan teliti model siri GPT-3 dan mendapati bahawa contoh latihan boleh diekstrak daripada model GPT-3, dan dalam setiap versi dari davinci kepada GPT-3.5-turbo, bilangan contoh latihan yang boleh yang diekstrak semakin meningkat, yang berkait rapat dengan peningkatan prestasi sifar pukulan model GPT-3 pada tugas ini (Rajah 2). Ini sangat membuktikan bahawa peningkatan prestasi model GPT-3 daripada davinci kepada GPT-3.5-turbo pada tugasan ini adalah disebabkan oleh pencemaran tugas.
Atas ialah kandungan terperinci Tafsiran baharu tahap kecerdasan GPT-4 yang semakin menurun. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 'Genius matematik' Terence Tao: GPT-4 tidak dapat menyelesaikan masalah matematik yang belum diselesaikan, tetapi ia berguna untuk kerja
- Raja GPT-4 dinobatkan! Keupayaan anda untuk membaca gambar dan menjawab soalan adalah menakjubkan. Anda boleh masuk ke Stanford sendiri.
- Terminator Kong Yiji! GPT-4 memulakan perniagaan dengan $100, dan Musk telah diberhentikan kerja
- Cara menggunakan openai untuk menghasilkan imej dalam python
- OpenAI melancarkan aplikasi mudah alih kecerdasan buatan generatif pertama ChatGPT, membuka era baharu komunikasi pintar