
Rumah >Peranti teknologi >AI >Kaedah untuk membina sistem RAG multimodal: menggunakan CLIP dan LLM
Kaedah untuk membina sistem RAG multimodal: menggunakan CLIP dan LLM

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-13 22:24:121148semak imbas
Kami akan membincangkan cara untuk membina sistem Retrieval Augmented Generation (RAG) menggunakan sumber terbuka Large Language Multi-Modal. Fokus kami adalah untuk mencapai ini tanpa bergantung pada indeks LangChain atau LLlama untuk mengelakkan penambahan lebih banyak kebergantungan rangka kerja.

Apakah itu RAG
Dalam bidang kecerdasan buatan, kemunculan teknologi penjanaan dipertingkatkan (RAG) telah membawa peningkatan revolusioner kepada model bahasa besar (Model Bahasa Besar). Intipati RAG adalah untuk meningkatkan tindak balas kecerdasan buatan dengan membenarkan model mendapatkan maklumat masa nyata secara dinamik daripada sumber luaran. Pengenalan teknologi ini membolehkan AI bertindak balas terhadap keperluan pengguna secara lebih khusus. Dengan mendapatkan semula dan menggabungkan maklumat daripada sumber luaran, RAG mampu menjana jawapan yang lebih tepat dan komprehensif, memberikan pengguna kandungan yang lebih berharga. Peningkatan keupayaan ini telah membawa prospek yang lebih luas kepada bidang aplikasi kecerdasan buatan, termasuk perkhidmatan pelanggan pintar, carian pintar dan sistem soal jawab pengetahuan. Kemunculan RAG menandakan perkembangan selanjutnya model bahasa, membawa
kepada kecerdasan buatan ini dengan lancar menggabungkan proses pencarian semula dinamik dengan keupayaan penjanaan, membolehkan kecerdasan buatan menyesuaikan diri dengan perubahan maklumat dalam pelbagai bidang. Tidak seperti penalaan halus dan latihan semula, RAG menyediakan penyelesaian kos efektif yang membolehkan AI mendapatkan maklumat terkini dan berkaitan tanpa mengubah keseluruhan model. Gabungan keupayaan ini memberikan RAG kelebihan dalam bertindak balas terhadap persekitaran maklumat yang berubah dengan pantas.
Peranan RAG
1. Meningkatkan ketepatan dan kebolehpercayaan:
menyelesaikan masalah ketidakpastian model bahasa besar (LLM) dengan membekalkannya kepada sumber pengetahuan yang boleh dipercayai, risiko yang boleh dipercayai maklumat palsu atau lapuk menjadikan respons lebih tepat dan boleh dipercayai.
2. Tingkatkan ketelusan dan kepercayaan:
Model AI Generatif seperti LLM selalunya kurang ketelusan, yang menyukarkan orang untuk mempercayai output mereka. RAG menangani kebimbangan tentang berat sebelah, kebolehpercayaan dan pematuhan dengan menyediakan kawalan yang lebih besar.
3. Kurangkan halusinasi:
LLM terdedah kepada reaksi halusinasi - memberikan maklumat yang koheren tetapi tidak tepat atau rekaan. RAG mengurangkan risiko nasihat mengelirukan kepada sektor utama dengan bergantung pada sumber berwibawa untuk memastikan responsif.
4. Kebolehsuaian Kos Berkesan:
RAG menyediakan cara kos efektif untuk meningkatkan output AI tanpa memerlukan latihan semula/penalaan yang meluas. Maklumat boleh sentiasa dikemas kini dan relevan dengan mendapatkan semula butiran khusus secara dinamik mengikut keperluan, memastikan kebolehsesuaian AI untuk menukar maklumat.
Model modal pelbagaimodal
Multimodal melibatkan mempunyai berbilang input dan menggabungkannya menjadi satu output, mengambil CLIP sebagai contoh: data latihan CLIP ialah pasangan imej teks, dan melalui pembelajaran kontrastif, model Keupayaan untuk belajar padanan perhubungan antara pasangan teks-imej.
Model ini menjana vektor benam yang sama (sangat serupa) untuk input berbeza yang mewakili perkara yang sama.
Multi-Modal
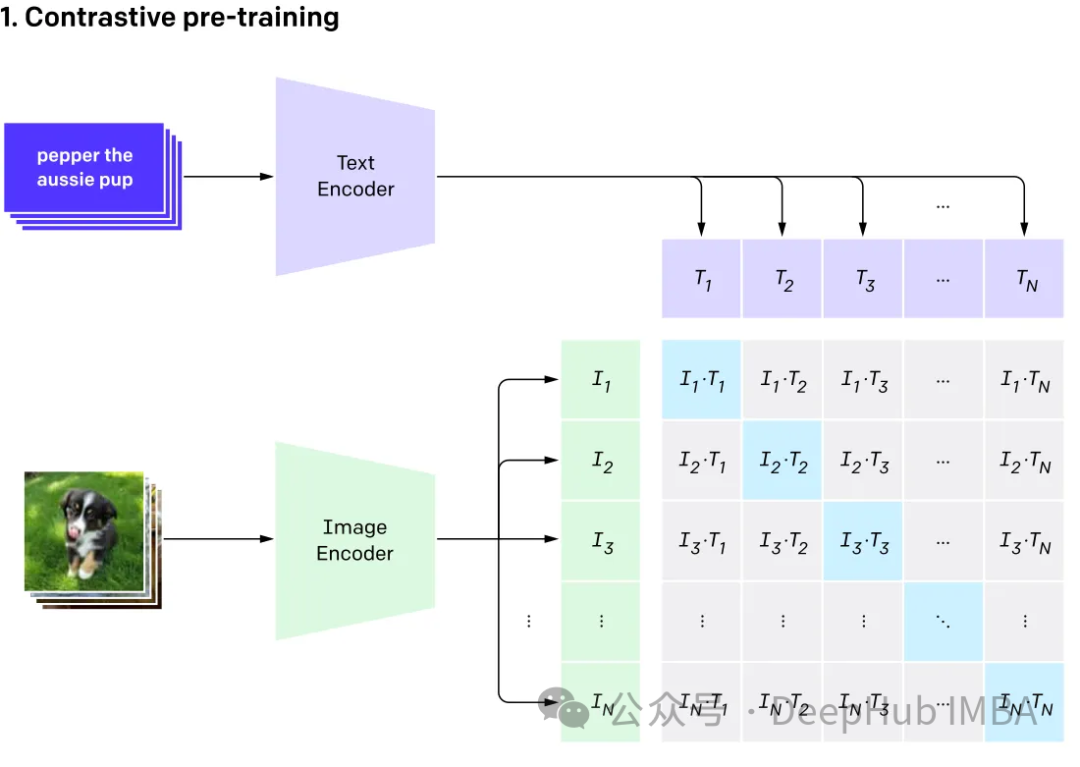
Multi-Modal Legar Language (Multi-Modal Language)
GPT4V dan Gemini Vision meneroka dan mengintegrasikan pelbagai jenis data (termasuk imej, teks , bahasa, audio, dsb.) model bahasa berbilang modal (MLLM). Walaupun model bahasa besar (LLM) seperti GPT-3, BERT dan RoBERTa berfungsi dengan baik pada tugas berasaskan teks, mereka menghadapi cabaran dalam memahami dan memproses jenis data lain. Untuk menangani had ini, model multimodal menggabungkan modaliti yang berbeza untuk membolehkan pemahaman yang lebih komprehensif tentang data yang berbeza.
Model bahasa besar berbilang modal Ia melangkaui kaedah berasaskan teks tradisional. Mengambil GPT-4 sebagai contoh, model ini boleh mengendalikan pelbagai jenis data dengan lancar, termasuk imej dan teks, menghasilkan pemahaman maklumat yang lebih lengkap.
Digabungkan dengan RAG
Di sini kami akan menggunakan Klip untuk membenamkan imej dan teks, menyimpan benaman ini dalam pangkalan data vektor ChromDB. Model besar kemudiannya akan dimanfaatkan untuk melibatkan diri dalam sesi sembang pengguna berdasarkan maklumat yang diambil.
Kami akan menggunakan imej dari Kaggle dan maklumat dari Wikipedia untuk mencipta chatbot pakar bunga
Mula-mula kami memasang pakej:
langkah-langkahnya sangat mudah untuk memproses data terlebih dahulu letak sahaja imej dan teks dalam folder可以随意使用任何矢量数据库,这里我们使用ChromaDB。 ChromaDB需要自定义嵌入函数 这里将创建2个集合,一个用于文本,另一个用于图像 对于Clip,我们可以像这样使用文本检索图像 也可以使用图像检索相关的图像 文本集合如下所示 然后使用上面的文本集合获取嵌入 结果如下: 或使用图片获取文本 上图的结果如下: 这样我们就完成了文本和图像的匹配工作,其实这里都是CLIP的工作,下面我们开始加入LLM。 我们是用visheratin/LLaVA-3b 加载tokenizer 然后定义处理器,方便我们以后调用 下面就可以直接使用了 得到的结果如下: 结果还包含了我们需要的大部分信息 这样我们整合就完成了,最后就是创建聊天模板, 如何创建聊天过程我们这里就不详细介绍了,完整代码在这里:
import chromadb from chromadb.utils.embedding_functions import OpenCLIPEmbeddingFunction from chromadb.utils.data_loaders import ImageLoader from chromadb.config import Settings client = chromadb.PersistentClient(path="DB") embedding_function = OpenCLIPEmbeddingFunction() image_loader = ImageLoader() # must be if you reads from URIs
from chromadb import Documents, EmbeddingFunction, Embeddings class MyEmbeddingFunction(EmbeddingFunction):def __call__(self, input: Documents) -> Embeddings:# embed the documents somehow or imagesreturn embeddings
collection_images = client.create_collection(name='multimodal_collection_images', embedding_functinotallow=embedding_function, data_loader=image_loader) collection_text = client.create_collection(name='multimodal_collection_text', embedding_functinotallow=embedding_function, ) # Get the Images IMAGE_FOLDER = '/kaggle/working/all_data' image_uris = sorted([os.path.join(IMAGE_FOLDER, image_name) for image_name in os.listdir(IMAGE_FOLDER) if not image_name.endswith('.txt')]) ids = [str(i) for i in range(len(image_uris))] collection_images.add(ids=ids, uris=image_uris) #now we have the images collection
from matplotlib import pyplot as plt retrieved = collection_images.query(query_texts=["tulip"], include=['data'], n_results=3) for img in retrieved['data'][0]:plt.imshow(img)plt.axis("off")plt.show()


# now the text DB from chromadb.utils import embedding_functions default_ef = embedding_functions.DefaultEmbeddingFunction() text_pth = sorted([os.path.join(IMAGE_FOLDER, image_name) for image_name in os.listdir(IMAGE_FOLDER) if image_name.endswith('.txt')]) list_of_text = [] for text in text_pth:with open(text, 'r') as f:text = f.read()list_of_text.append(text) ids_txt_list = ['id'+str(i) for i in range(len(list_of_text))] ids_txt_list collection_text.add(documents = list_of_text,ids =ids_txt_list )
results = collection_text.query(query_texts=["What is the bellflower?"],n_results=1 ) results
{'ids': [['id0']],'distances': [[0.6072186183744086]],'metadatas': [[None]],'embeddings': None,'documents': [['Campanula () is the type genus of the Campanulaceae family of flowering plants. Campanula are commonly known as bellflowers and take both their common and scientific names from the bell-shaped flowers—campanula is Latin for "little bell".\nThe genus includes over 500 species and several subspecies, distributed across the temperate and subtropical regions of the Northern Hemisphere, with centers of diversity in the Mediterranean region, Balkans, Caucasus and mountains of western Asia. The range also extends into mountains in tropical regions of Asia and Africa.\nThe species include annual, biennial and perennial plants, and vary in habit from dwarf arctic and alpine species under 5 cm high, to large temperate grassland and woodland species growing to 2 metres (6 ft 7 in) tall.']],'uris': None,'data': None}
query_image = '/kaggle/input/flowers/flowers/rose/00f6e89a2f949f8165d5222955a5a37d.jpg' raw_image = Image.open(query_image) doc = collection_text.query(query_embeddings=embedding_function(query_image), n_results=1, )['documents'][0][0]

A rose is either a woody perennial flowering plant of the genus Rosa (), in the family Rosaceae (), or the flower it bears. There are over three hundred species and tens of thousands of cultivars. They form a group of plants that can be erect shrubs, climbing, or trailing, with stems that are often armed with sharp prickles. Their flowers vary in size and shape and are usually large and showy, in colours ranging from white through yellows and reds. Most species are native to Asia, with smaller numbers native to Europe, North America, and northwestern Africa. Species, cultivars and hybrids are all widely grown for their beauty and often are fragrant. Roses have acquired cultural significance in many societies. Rose plants range in size from compact, miniature roses, to climbers that can reach seven meters in height. Different species hybridize easily, and this has been used in the development of the wide range of garden roses.
from huggingface_hub import hf_hub_download hf_hub_download(repo_, filename="configuration_llava.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="configuration_phi.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="modeling_llava.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="modeling_phi.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="processing_llava.py", local_dir="./", force_download=True)
from modeling_llava import LlavaForConditionalGeneration import torch model = LlavaForConditionalGeneration.from_pretrained("visheratin/LLaVA-3b") model = model.to("cuda")
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("visheratin/LLaVA-3b")
from processing_llava import LlavaProcessor, OpenCLIPImageProcessor image_processor = OpenCLIPImageProcessor(model.config.preprocess_config) processor = LlavaProcessor(image_processor, tokenizer)
question = 'Answer with organized answers: What type of rose is in the picture? Mention some of its characteristics and how to take care of it ?' query_image = '/kaggle/input/flowers/flowers/rose/00f6e89a2f949f8165d5222955a5a37d.jpg' raw_image = Image.open(query_image) doc = collection_text.query(query_embeddings=embedding_function(query_image), n_results=1, )['documents'][0][0] plt.imshow(raw_image) plt.show() imgs = collection_images.query(query_uris=query_image, include=['data'], n_results=3) for img in imgs['data'][0][1:]:plt.imshow(img)plt.axis("off")plt.show()


prompt = """system A chat between a curious human and an artificial intelligence assistant. The assistant is an exprt in flowers , and gives helpful, detailed, and polite answers to the human's questions. The assistant does not hallucinate and pays very close attention to the details. user <image> {question} Use the following article as an answer source. Do not write outside its scope unless you find your answer better {article} if you thin your answer is better add it after document. assistant """.format(questinotallow='question', article=doc)</image>
Atas ialah kandungan terperinci Kaedah untuk membina sistem RAG multimodal: menggunakan CLIP dan LLM. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!