
Rumah >Peranti teknologi >AI >Kurangkan pangkat Transformer untuk meningkatkan prestasi sambil mengekalkan LLM tanpa mengurangkan penyingkiran lebih daripada 90% komponen dalam lapisan tertentu
Kurangkan pangkat Transformer untuk meningkatkan prestasi sambil mengekalkan LLM tanpa mengurangkan penyingkiran lebih daripada 90% komponen dalam lapisan tertentu

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-13 21:51:06747semak imbas
MIT dan Microsoft menjalankan penyelidikan bersama dan mendapati bahawa tiada latihan tambahan diperlukan untuk meningkatkan prestasi tugas model bahasa besar dan mengurangkan saiznya
Dalam era model besar, Transformer terkenal dengan keupayaan uniknya Menyokong keseluruhan bidang penyelidikan saintifik. Sejak diperkenalkan, model bahasa berasaskan Transformer (LLM) telah menunjukkan prestasi cemerlang dalam pelbagai tugas. Seni bina asas Transformer telah menjadi teknologi terkini untuk pemodelan dan penaakulan bahasa semula jadi, dan telah menunjukkan prospek yang kukuh dalam bidang seperti penglihatan komputer dan pembelajaran pengukuhan
Walau bagaimanapun, seni bina Transformer semasa adalah sangat besar dan biasanya memerlukan sejumlah besar sumber pengkomputeran untuk latihan dan penaakulan.
Tulis semula seperti ini: Adalah wajar untuk melakukan ini kerana Transformer yang dilatih dengan lebih banyak parameter atau data jelas lebih berkebolehan berbanding model lain. Walau bagaimanapun, semakin banyak penyelidikan menunjukkan bahawa model berasaskan Transformer dan rangkaian saraf tidak perlu mengekalkan semua parameter penyesuaian untuk mengekalkan hipotesis yang dipelajari
Secara umum, penparameteran berlebihan nampaknya membantu semasa melatih model, tetapi Model ini boleh menjadi sangat berguna. dicantas sebelum inferens. Kajian telah menunjukkan bahawa rangkaian saraf selalunya boleh mengeluarkan lebih daripada 90% berat tanpa sebarang penurunan prestasi yang ketara. Fenomena ini telah mencetuskan minat penyelidik dalam strategi pemangkasan yang membantu penaakulan model
Penyelidik dari MIT dan Microsoft menulis dalam kertas kerja "The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction" membentangkan penemuan mengejutkan yang berhati-hati. pemangkasan pada lapisan tertentu model Transformer boleh meningkatkan prestasi model pada tugas tertentu dengan ketara.

Sila klik pautan berikut untuk melihat kertas: https://arxiv.org/pdf/2312.13558.pdf
Laman utama kertas: https://pratyushashama.giterhub.io
Gambaran Keseluruhan Laser
menyediakan pengenalan terperinci kepada campur tangan LASER. Intervensi LASER satu langkah ditakrifkan oleh triplet (τ, ℓ, ρ), yang mengandungi parameter τ, bilangan lapisan ℓ dan pangkat yang dikurangkan ρ. Bersama-sama nilai ini menerangkan matriks yang akan digantikan dengan penghampiran peringkat rendah, dan tahap penghampiran. Penyelidik mengelaskan jenis matriks yang mereka akan campur tangan berdasarkan jenis parameterPenyelidik menumpukan pada matriks dalam W = {W_q, W_k, W_v, W_o, U_in, U_out}, yang terdiri daripada matriks dalam MLP dan lapisan perhatian . Bilangan strata mewakili strata intervensi penyelidik (stratum pertama diindeks bermula dari 0). Sebagai contoh, Llama-2 mempunyai 32 lapisan, jadi ℓ ∈ {0, 1, 2,・・・31}. Akhirnya, ρ ∈ [0, 1) menerangkan bahagian kedudukan maksimum yang harus dikekalkan apabila membuat anggaran peringkat rendah. Sebagai contoh, andaikan, pangkat maksimum matriks ini ialah d. Para penyelidik menggantikannya dengan anggaran ⌊ρ・d⌋-. 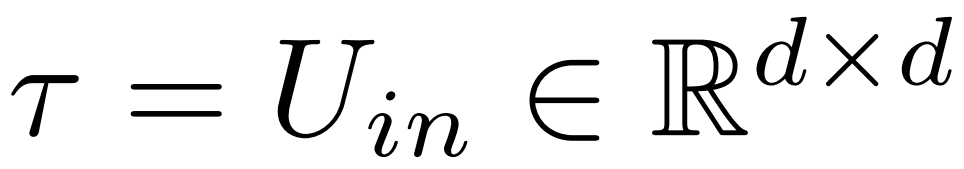
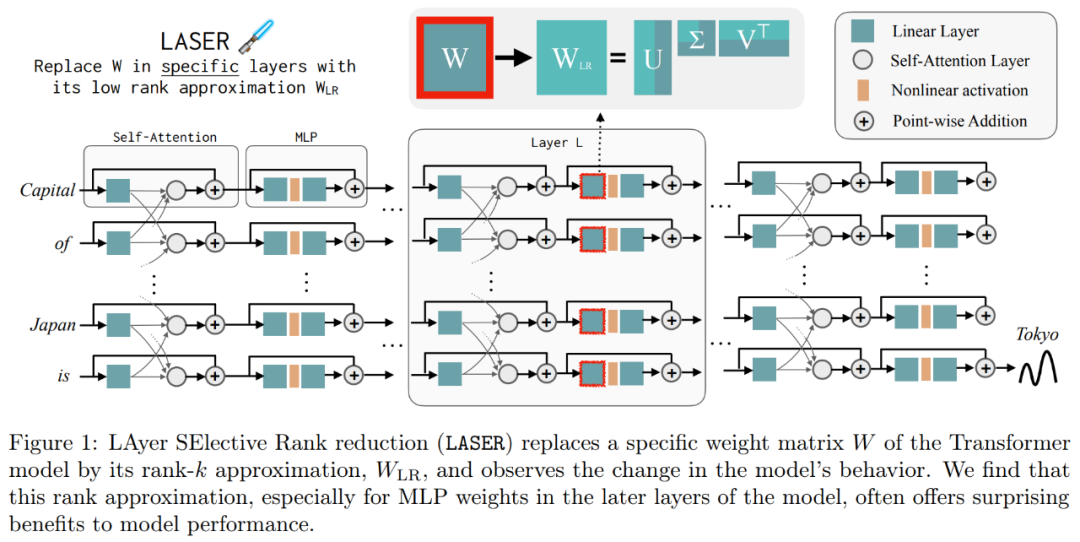
LASER boleh menyekat aliran maklumat tertentu dalam rangkaian dan secara tidak dijangka menghasilkan faedah prestasi yang ketara. Intervensi ini juga boleh digabungkan dengan mudah, seperti menggunakan set intervensi dalam sebarang susunan 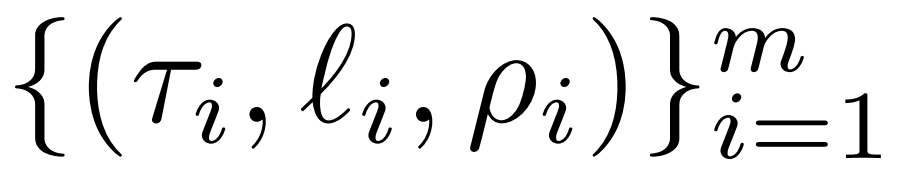 .
.
Kaedah LASER hanyalah carian mudah untuk campur tangan sedemikian, diubah suai untuk membawa manfaat maksimum. Walau bagaimanapun, terdapat banyak cara lain untuk menggabungkan campur tangan ini, yang merupakan hala tuju untuk kerja masa depan.
Untuk mengekalkan maksud asal tidak berubah, kandungan perlu ditulis semula ke dalam bahasa Cina. Tidak perlu muncul ayat asal
Di bahagian eksperimen, pengkaji menggunakan model GPT-J yang telah dilatih pada set data PILE Bilangan lapisan model ialah 27 dan parameternya ialah 6 bilion. Tingkah laku model kemudian dinilai pada set data CounterFact, yang mengandungi sampel tiga kali ganda (topik, hubungan dan jawapan), dengan tiga gesaan parafrasa disediakan untuk setiap soalan.
Yang pertama ialah analisis model GPT-J pada dataset CounterFact. Rajah 2 di bawah menunjukkan kesan ke atas kehilangan klasifikasi set data akibat penggunaan jumlah pengurangan pangkat yang berbeza pada setiap matriks dalam seni bina Transformer. Setiap lapisan Transformer terdiri daripada MLP kecil dua lapisan, dengan matriks input dan output ditunjukkan secara berasingan. Warna yang berbeza mewakili peratusan berbeza bagi komponen yang dialih keluar.
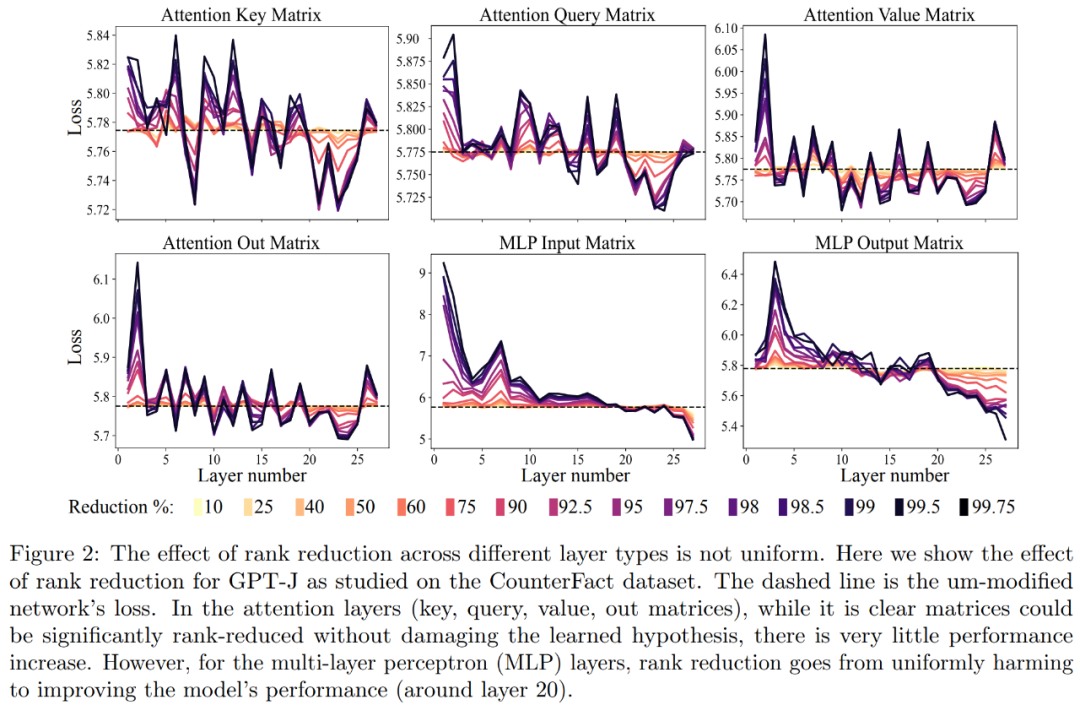
Berkenaan meningkatkan ketepatan dan keteguhan tafsiran, seperti yang ditunjukkan dalam Rajah 2 di atas dan Jadual 1 di bawah, penyelidik mendapati bahawa apabila melakukan pengurangan pangkat pada satu lapisan, hakikat bahawa model GPT-J berprestasi baik pada Dataset CounterFact Ketepatan meningkat daripada 13.1% kepada 24.0%. Adalah penting untuk ambil perhatian bahawa penambahbaikan ini hanya hasil daripada penurunan pangkat dan tidak melibatkan sebarang latihan lanjut atau penalaan halus model.
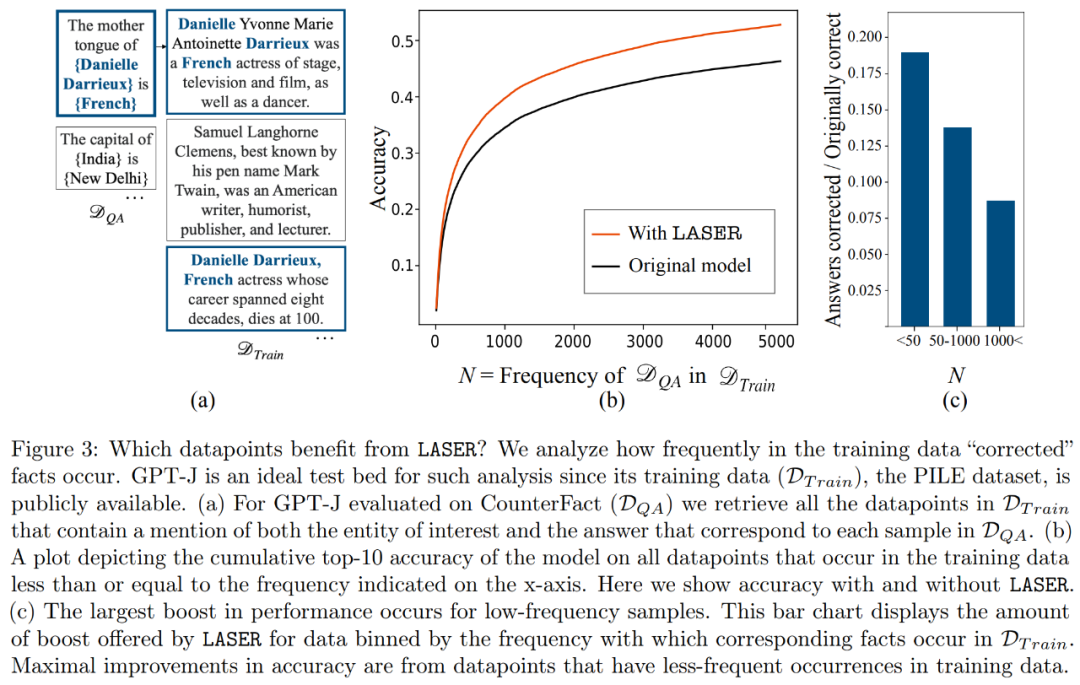
Fakta manakah yang akan dipulihkan dalam set data melalui pengurangan pangkat telah menjadi kebimbangan para penyelidik. Para penyelidik mendapati bahawa fakta pemulihan melalui pengurangan pangkat jarang muncul dalam data, seperti yang ditunjukkan dalam Rajah 3
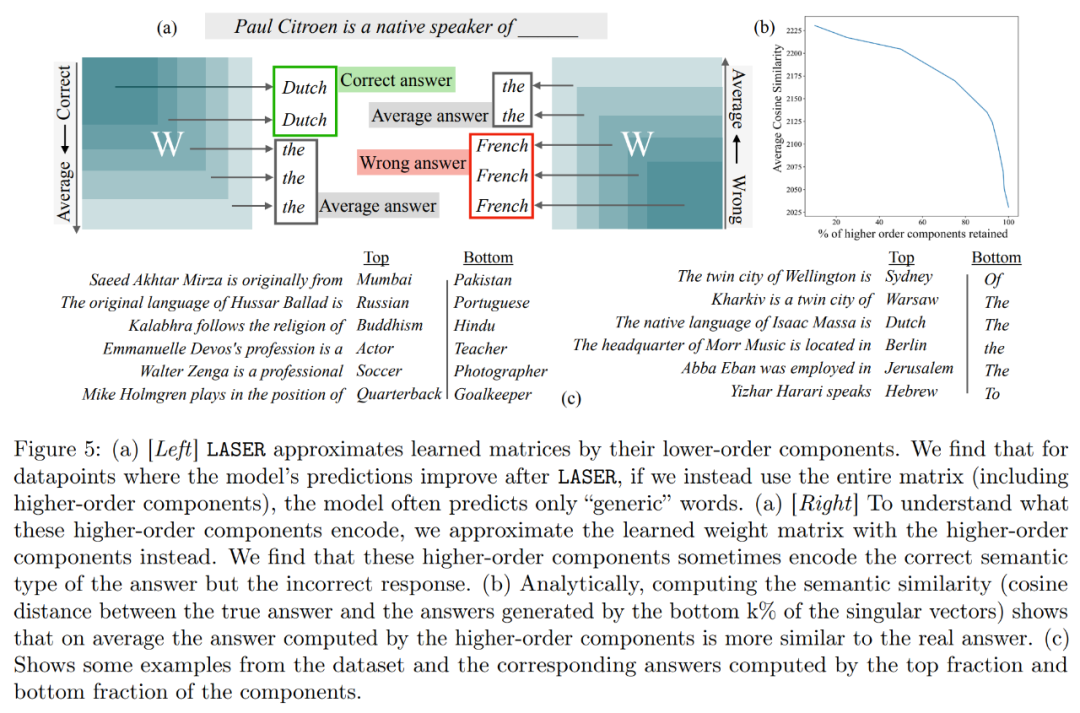
Apakah yang disimpan oleh komponen peringkat tinggi? Penyelidik menggunakan komponen tertib tinggi untuk menganggarkan matriks berat akhir Tidak seperti LASER, mereka tidak menggunakan komponen tertib rendah untuk anggaran, seperti yang ditunjukkan dalam Rajah 5(a). Apabila menghampiri matriks menggunakan bilangan komponen tertib tinggi yang berbeza, mereka mengukur persamaan kosinus purata antara jawapan yang benar dan yang diramalkan, seperti yang ditunjukkan dalam Rajah 5(b)
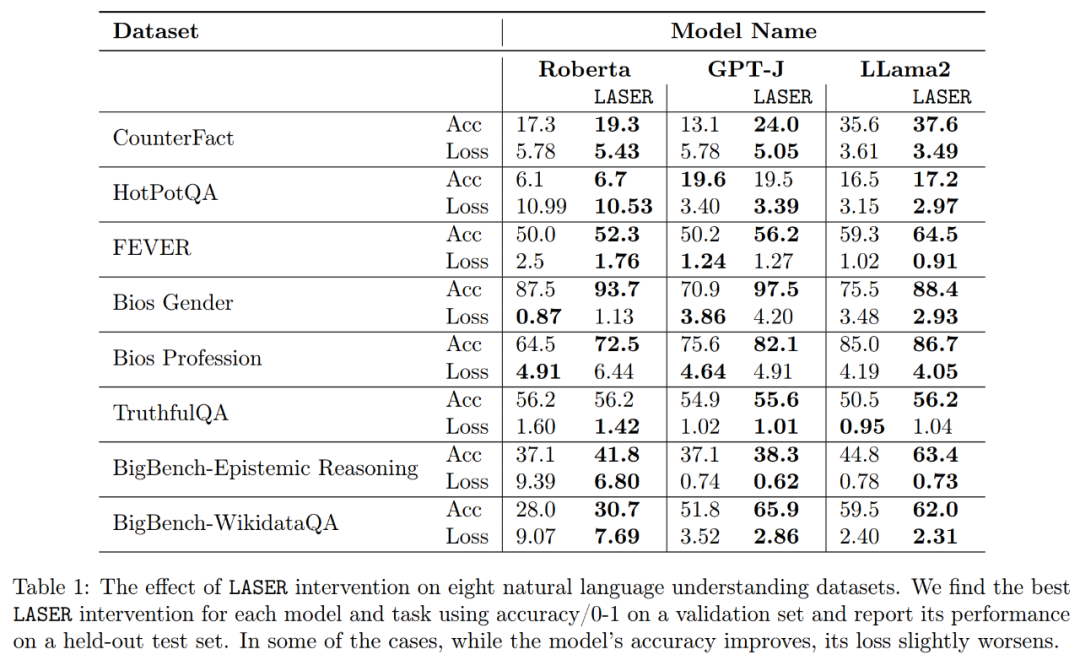
Akhir sekali, penyelidik menilai penemuan mereka Kebolehgeneralisasian 3 berbeza. LLM pada tugas pemahaman berbilang bahasa. Untuk setiap tugasan, mereka menilai prestasi model dengan menjana tiga metrik: ketepatan, ketepatan klasifikasi dan kerugian. Seperti yang ditunjukkan dalam Jadual 1 di atas, walaupun pengurangan pangkat adalah besar, ia tidak akan menyebabkan ketepatan model berkurangan, tetapi ia boleh meningkatkan prestasi model.
Atas ialah kandungan terperinci Kurangkan pangkat Transformer untuk meningkatkan prestasi sambil mengekalkan LLM tanpa mengurangkan penyingkiran lebih daripada 90% komponen dalam lapisan tertentu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!