
Rumah >Peranti teknologi >AI >Aplikasi kaedah pembetulan sebab dan akibat dalam senario pengesyoran Ant Marketing
Aplikasi kaedah pembetulan sebab dan akibat dalam senario pengesyoran Ant Marketing

- PHPzke hadapan
- 2024-01-13 12:15:131492semak imbas
1. Latar belakang bias kausal
1. Penjanaan bias
Dalam sistem pengesyoran, model pengesyoran dilatih dengan mengumpul data untuk mengesyorkan item yang sesuai kepada pengguna. Apabila pengguna berinteraksi dengan item yang disyorkan, data yang dikumpul digunakan untuk terus melatih model, membentuk gelung tertutup. Walau bagaimanapun, mungkin terdapat pelbagai faktor yang mempengaruhi dalam gelung tertutup ini, mengakibatkan ralat. Sebab utama ralat ialah kebanyakan data yang digunakan untuk melatih model adalah data pemerhatian dan bukannya data latihan yang ideal, yang dipengaruhi oleh faktor seperti strategi pendedahan dan pemilihan pengguna. Intipati berat sebelah ini terletak pada perbezaan antara jangkaan anggaran risiko empirikal dan jangkaan anggaran risiko ideal sebenar.

2. Kecondongan biasa
Kecondongan yang lebih biasa dalam sistem pemasaran pengesyoran terutamanya termasuk tiga jenis berikut:
- secara aktif mengikut pilihan pengguna: Ia adalah mengikut pilihan pengguna aktif mengikut keutamaan mereka sendiri yang disebabkan oleh item tersebut.
- Bias pendedahan: Item yang disyorkan biasanya hanya subset daripada kumpulan calon item keseluruhan Pengguna hanya boleh berinteraksi dengan item yang disyorkan oleh sistem apabila memilih, mengakibatkan bias dalam data pemerhatian.
Bidang populariti: Perkadaran tinggi beberapa item popular dalam data latihan menyebabkan model mempelajari prestasi ini dan mengesyorkan item yang lebih popular, menyebabkan kesan Matthew.
Ada penyelewengan lain, seperti sisihan kedudukan, sisihan konsisten, dll.
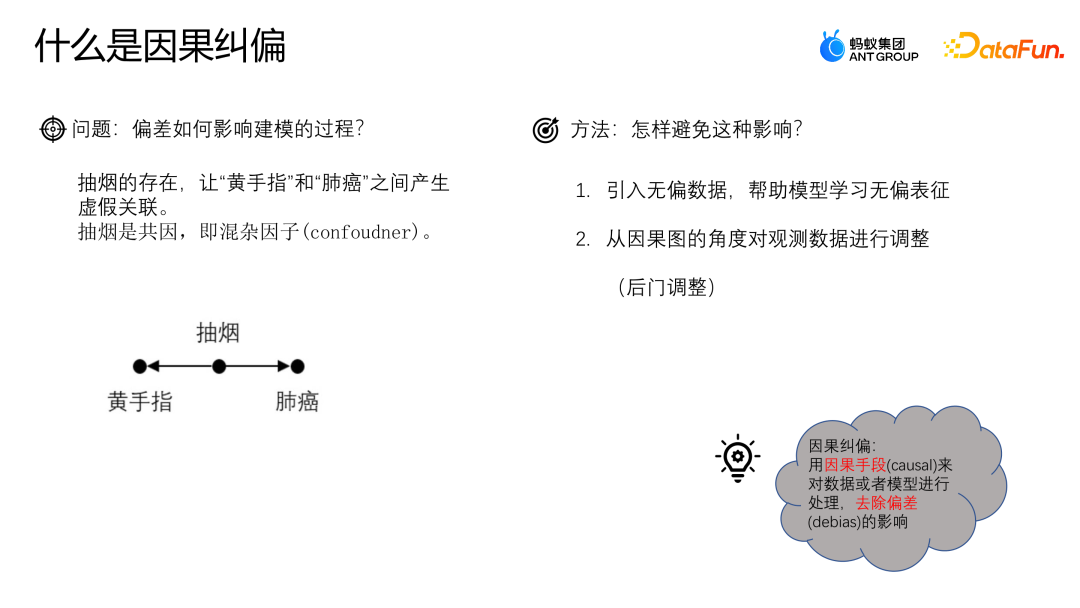
Bagaimana untuk mengelakkan masalah ini? Kaedah biasa ialah memperkenalkan data tidak berat sebelah dan menggunakan data tidak berat sebelah untuk membantu model mempelajari perwakilan tidak berat sebelah ialah bermula dari perspektif rajah sebab dan membetulkan sisihan dengan melaraskan pemerhatian; data kemudian. Pembetulan kausal adalah untuk memproses data atau model melalui cara kausal untuk menghapuskan pengaruh bias.
4. Gambar rajah sebab-akibat
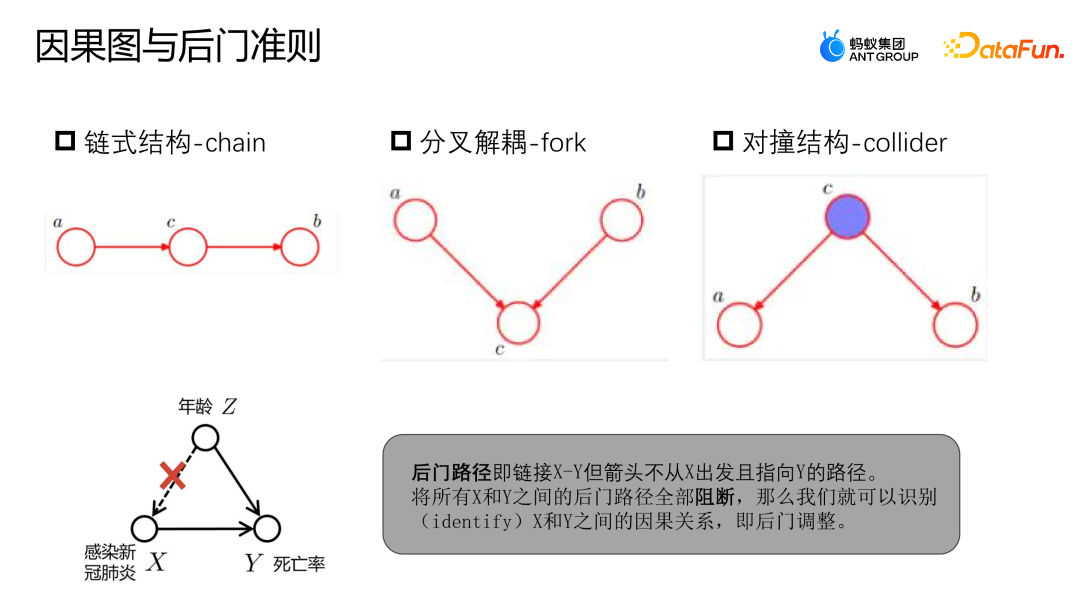
Anda boleh rujuk contoh dalam gambar di atas untuk menentukan laluan backdoor dan kriteria backdoor. Laluan pintu belakang merujuk kepada laluan yang menghubungkan X ke Y, tetapi bermula dari Z dan akhirnya menghala ke Y. Sama seperti contoh sebelumnya, hubungan antara jangkitan COVID-19 dan kematian bukanlah sebab musabab semata-mata. Jangkitan dengan COVID-19 dipengaruhi oleh umur orang yang lebih tua lebih berkemungkinan dijangkiti COVID-19, dan kadar kematian mereka juga lebih tinggi. Walau bagaimanapun, jika kita mempunyai data yang mencukupi untuk menyekat semua laluan pintu belakang antara X dan Y, iaitu, diberikan Z, maka X dan Y boleh dimodelkan sebagai hubungan bebas, supaya kita boleh mendapatkan sebab dan akibat sebenar.
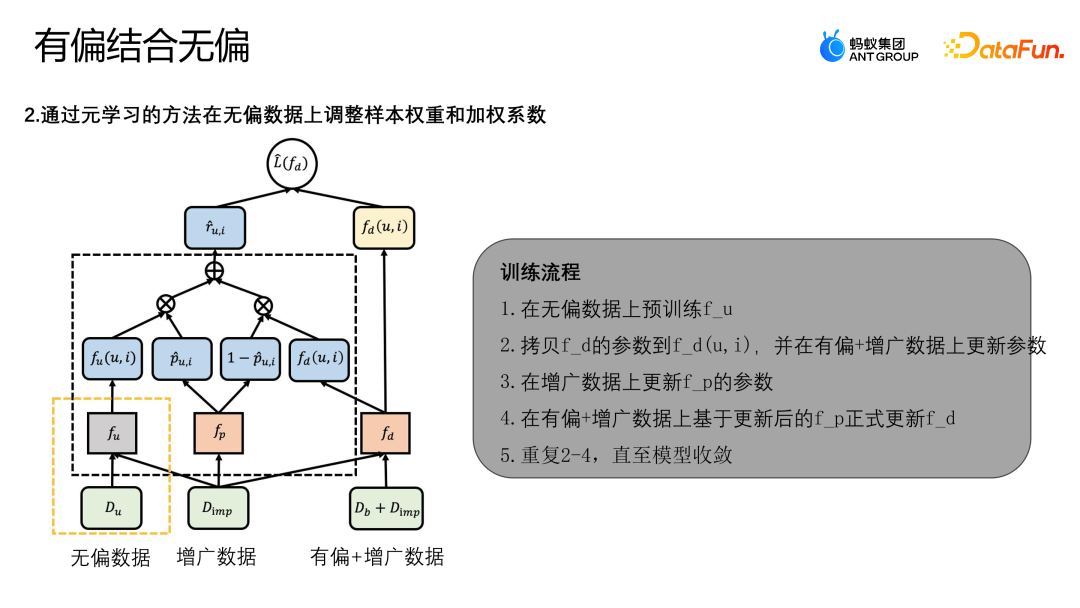
Pengagihan keseluruhan data tidak berat sebelah adalah berbeza daripada data berat sebelah Data berat sebelah akan tertumpu pada bahagian tertentu dari keseluruhan ruang sampel, dan sampel yang hilang akan tertumpu di sebahagian kawasan. dengan data yang agak kurang berat sebelah Oleh itu, jika sampel ditambah adalah berhampiran dengan kawasan dengan kawasan yang lebih tidak berat sebelah, maka data tidak berat sebelah akan memainkan lebih banyak peranan jika sampel ditambah adalah hampir dengan kawasan dengan data berat sebelah, maka data berat sebelah akan dimainkan lebih banyak peranan. Untuk tujuan ini, kertas kerja ini mereka bentuk model MDI yang boleh menggunakan data tidak berat sebelah dan berat sebelah dengan lebih baik untuk penambahan data.
Rajah di atas menunjukkan rajah rangka kerja algoritma Model MDI menggunakan kaedah meta-pembelajaran untuk melaraskan berat sampel dan pekali wajaran pada data tidak berat sebelah. Pertama sekali, terdapat dua peringkat dalam latihan model MDI: Fasa 1: Gunakan data tidak berat sebelah untuk melatih guru model fu yang tidak berat sebelah. Berikut ialah proses latihan lengkap algoritma: 2. Eksperimen pada model pembetulan gabungan data Kami menjalankan penilaian ke atas dua set data awam, Yahoo R3 dan Coat. Yahoo R3 mengumpul 15,000+ penilaian pengguna bagi 1,000 lagu, dan mengumpulkan sejumlah 310,000+ data berat sebelah dan 5,400 keping data tidak berat sebelah. Set data Coat mengumpulkan 6900+ keping data berat sebelah dan 4600+ keping data tidak berat sebelah melalui 290 penilaian pengguna bagi 300 helai pakaian. Penilaian pengguna dalam kedua-dua set data berjulat dari 1 hingga 5. Data berat sebelah datang daripada pengguna data platform dan sampel tidak berat sebelah dikumpulkan dengan memilih dan menilai pengguna secara rawak. Kaedah perbandingan Baseline yang kami gunakan adalah seperti berikut: kaedah pertama ialah menggunakan model yang dilatih oleh data tidak berat sebelah, data berat sebelah tunggal dan gabungan data langsung kaedah kedua ialah menggunakan sebahagian kecil Data data tidak berat sebelah; perwakilan biasa direka bentuk untuk mengekang persamaan data berat sebelah dan perwakilan data tidak berat sebelah untuk melaksanakan operasi pembetulan bias; kaedah ketiga ialah kaedah berat kebarangkalian songsang, kebarangkalian songsang bagi skor kecenderungan. Teguh berganda juga merupakan kaedah pembetulan biasa; Teguh berganda bebas kecenderungan ialah kaedah penambahan data, yang mula-mula menggunakan sampel tidak berat sebelah untuk mempelajari model ditambah, dan kemudian menggunakan sampel ditambah untuk membantu keseluruhan model Auto Debias juga akan menggunakan beberapa data tidak berat sebelah untuk penambahan untuk membantu membetulkan bias model.
Pada set data Yahoo R3, kaedah yang kami cadangkan mempunyai indeks prestasi terbaik pada MAE, dan prestasi terbaik pada MSE kecuali IPS. Tiga kaedah penambahan data, PFDR, Auto Debias dan MDI yang dicadangkan kami, akan berprestasi lebih baik dalam kebanyakan kes Walau bagaimanapun, memandangkan PFDR menggunakan data yang tidak berat sebelah untuk melatih model ditambah terlebih dahulu, ia akan sangat bergantung pada data yang tidak berat sebelah hanya mempunyai 464 sampel data latihan tidak berat sebelah pada model Coat Apabila terdapat lebih sedikit sampel tidak berat sebelah, modul penambahannya akan menjadi lemah dan prestasi data akan menjadi agak lemah.
Kami juga menilai prestasi model ini di bawah perkadaran data tidak berat sebelah yang berbeza pada dua set data awam, masing-masing menggunakan 50% hingga 40% data tidak berat sebelah dan semua data berat sebelah untuk latihan, Logiknya disahkan dengan 10% pertama data tidak berat sebelah dan data yang selebihnya diuji. Tetapan ini adalah sama seperti percubaan sebelumnya. Angka di atas menunjukkan prestasi MAE menggunakan kaedah berbeza di bawah perkadaran data tidak berat sebelah yang berbeza. Absis mewakili bahagian data tidak berat sebelah, dan ordinat mewakili kesan setiap kaedah pada data tidak berat sebelah data Apabila perkadaran data separa meningkat, MAE AutoDebias, IPS dan DoubleRubus tidak mempunyai proses penurunan yang jelas. Walau bagaimanapun, daripada mengikuti kaedah Debias, kaedah secara langsung menggunakan gabungan data asal untuk belajar akan mengalami penurunan yang ketara Ini kerana lebih tinggi bahagian sampel data tidak berat sebelah, lebih baik kualiti data keseluruhan kami, jadi model boleh belajar. Prestasi yang lebih baik. Apabila data Yahoo R3 menggunakan lebih daripada 30% data tidak berat sebelah untuk latihan,
Tetapan λ=0 bermakna modul tambahan dibuang terus Pu,i = 1 bermakna hanya data tidak berat sebelah digunakan untuk memodelkan modul data ditambah Pu,i = 0 bermakna hanya data bercantum berat sebelah dan ditambah; digunakan untuk membina model modular data tambahan. Rajah di atas menunjukkan keputusan eksperimen ablasi Dapat dilihat bahawa kaedah MDI telah mencapai keputusan yang agak baik pada tiga set data, menunjukkan bahawa modul penambahan adalah perlu. Sama ada pada set data awam atau set data dalam senario perniagaan sebenar, kaedah penambahan yang kami cadangkan untuk menggabungkan data tidak berat sebelah dan berat sebelah mempunyai hasil yang lebih baik daripada penyelesaian gabungan data sebelumnya, dan keteguhan MDI juga telah disahkan melalui parameter eksperimen sensitiviti dan eksperimen ablasi.
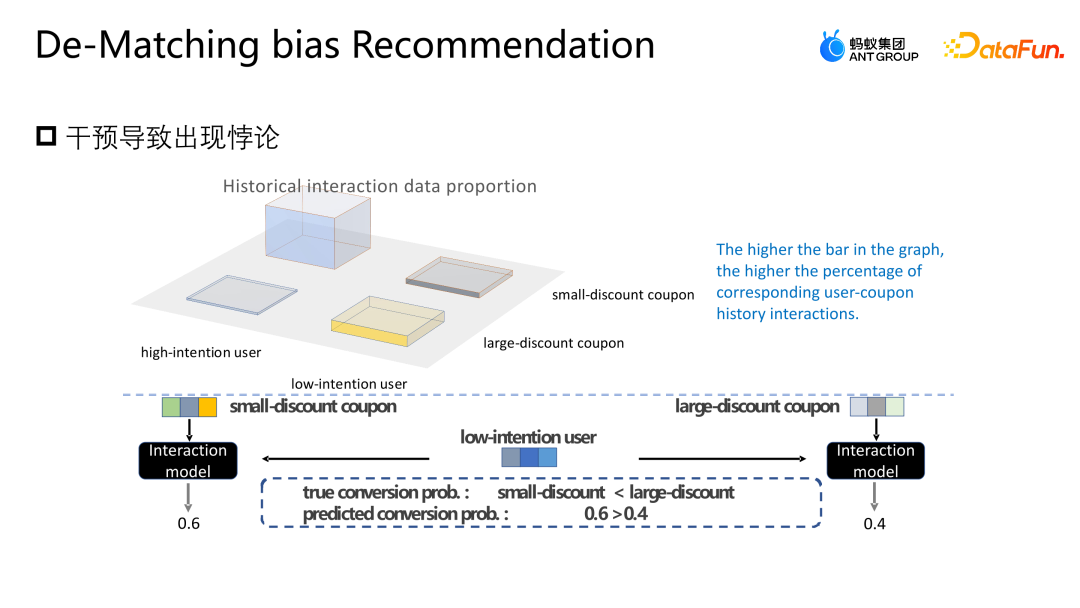
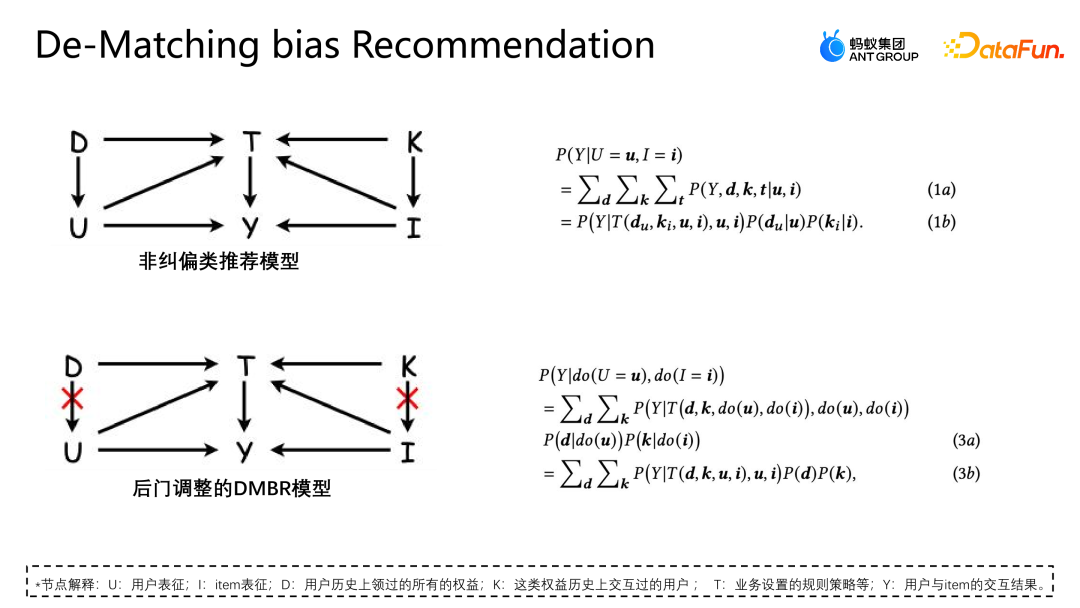
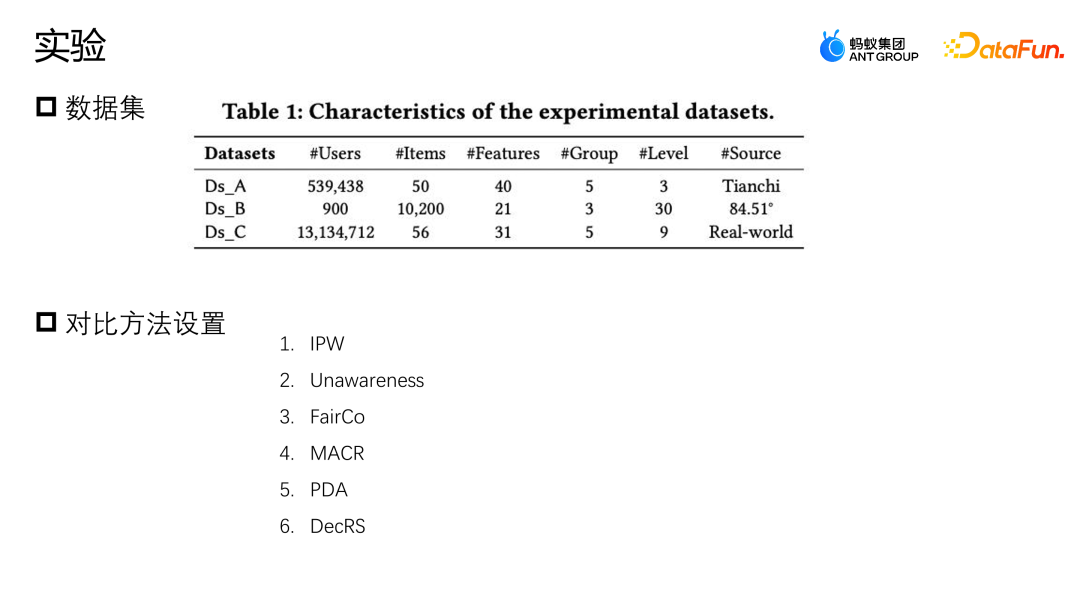
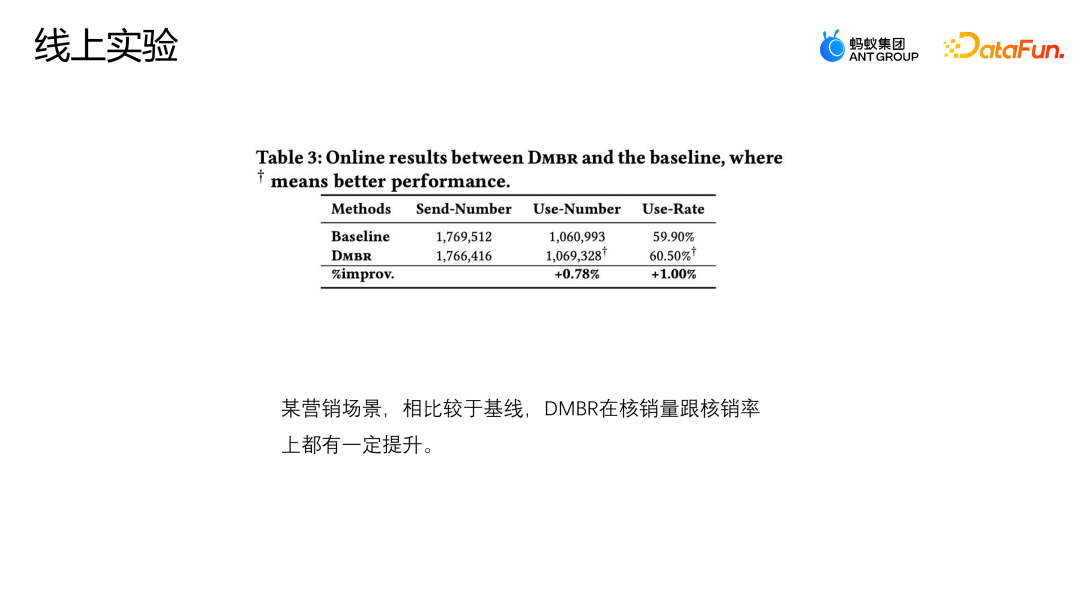
Mari kita perkenalkan satu lagi kerja pasukan: pembetulan berdasarkan pelarasan pintu belakang Karya ini juga telah diterbitkan di Laluan Industri SIGIR2023. Senario pelarasan dan pembetulan pintu belakang adalah senario pengesyoran pemasaran Seperti yang ditunjukkan dalam rajah di bawah, interaksi antara pengguna dan kupon atau pengguna dan sebarang iklan atau item tidak tertakluk kepada sebarang campur tangan sebarang interaksi, dan setiap kupon juga mempunyai peluang yang sama mungkin didedahkan kepada mana-mana pengguna. Tetapi dalam senario perniagaan sebenar, untuk melindungi atau membantu sesetengah peniaga kecil meningkatkan trafik dan memastikan pengalaman penyertaan pengguna secara keseluruhan, satu siri kekangan dasar biasanya ditetapkan Kupon tertentu akan terdedah lebih banyak, dan kumpulan pengguna lain akan lebih terdedah kepada kupon lain Intervensi jenis ini ialah pengasas bersama yang dinyatakan di atas. Apakah masalah yang akan ditimbulkan oleh campur tangan seperti ini dalam senario pemasaran e-dagang? Seperti yang ditunjukkan dalam rajah di atas, untuk kesederhanaan, kami hanya membahagikan pengguna kepada dua kategori: kesediaan tinggi untuk mengambil bahagian dan kesediaan rendah untuk mengambil bahagian, dan kupon kepada dua kategori: diskaun besar dan diskaun kecil. Ketinggian histogram dalam rajah mewakili perkadaran global bagi sampel yang sepadan Semakin tinggi histogram, semakin besar perkadaran sampel yang sepadan dalam data latihan keseluruhan. Kupon diskaun kecil dan sampel pengguna niat penyertaan tinggi yang ditunjukkan dalam angka menyumbang majoriti, yang akan menyebabkan model mempelajari pengedaran yang ditunjukkan dalam angka tersebut. Tetapi sebenarnya, menghadapi ambang penggunaan yang sama, pengguna pasti akan memilih kupon dengan diskaun yang lebih tinggi, supaya mereka dapat menjimatkan lebih banyak wang. Model dalam gambar menunjukkan bahawa kebarangkalian penukaran sebenar kupon diskaun kecil adalah lebih rendah daripada kupon diskaun besar Walau bagaimanapun, anggaran model untuk sampel tertentu akan berfikir bahawa kebarangkalian hapus kira kupon diskaun kecil adalah lebih tinggi, jadi. model juga akan mengesyorkan kupon yang sepadan, ini mewujudkan paradoks. Analisis sebab paradoks ini dari perspektif gambar rajah sebab akibat dalam senario semasa Struktur rajah sebab adalah seperti yang ditunjukkan dalam rajah di atas dan saya mewakili item. D dan K ialah interaksi sejarah antara perspektif pengguna dan perspektif ekuiti masing-masing mewakili beberapa kekangan peraturan yang ditetapkan oleh perniagaan semasa T tidak boleh dikira secara langsung, tetapi secara tidak langsung kita dapat melihat kesannya terhadap pengguna dan item melalui D dan K. pengaruh. y mewakili interaksi antara pengguna dan item, dan hasilnya ialah sama ada item itu diklik, dihapus kira, dsb. Rumus kebarangkalian bersyarat yang diwakili oleh rajah sebab ditunjukkan di bahagian atas sebelah kanan rajah Terbitan formula mengikut formula kebarangkalian Bayesian. Di bawah syarat U dan I yang diberikan, terbitan akhir P|Y ui bukan sahaja berkaitan dengan U dan I, kerana U akan dipengaruhi oleh du, iaitu, apabila p diberi u, kebarangkalian p (du) juga wujud daripada. Begitu juga apabila saya diberi, saya juga akan terkena ki Punca keadaan ini ialah kewujudan D dan K membawa kepada kewujudan laluan pintu belakang di tempat kejadian. Iaitu, laluan pintu belakang yang tidak bermula dari U tetapi akhirnya menghala ke y (laluan U-D-T-Y atau I-K-T-Y) akan mewakili konsep yang salah, iaitu, U bukan sahaja boleh menjejaskan y melalui T, tetapi juga mempengaruhi y melalui D. Kaedah pelarasan adalah untuk memotong laluan dari D ke U secara buatan, supaya U hanya boleh menjejaskan y secara langsung melalui U-T-Y dan U-Y Kaedah ini boleh menghapuskan korelasi palsu dan memodelkan hubungan sebab-akibat yang sebenar. Pelarasan pintu belakang adalah untuk melakukan do-calculus pada data cerapan, dan kemudian menggunakan operator do untuk mengagregatkan prestasi semua D dan semua K untuk mengelakkan U dan I daripada terjejas oleh D dan K. Dengan cara ini hubungan sebab dan akibat yang benar dimodelkan. Bentuk anggaran terbitan formula ini ditunjukkan dalam rajah di bawah. 4a ialah bentuk yang sama seperti 3b sebelumnya, dan 4b ialah anggaran ruang sampel. Kerana secara teorinya ruang sampel D dan K adalah tidak terhingga, penghampiran hanya boleh dibuat melalui data yang dikumpul (D dan K ruang sampel mengambil saiz). 4c dan 4d adalah kedua-dua terbitan penghampiran yang dikehendaki, dengan cara yang akhirnya hanya satu perwakilan tidak berat sebelah tambahan T perlu dimodelkan. T ialah model tambahan bagi perwakilan tidak berat sebelah T dengan merentasi jumlah taburan kebarangkalian perwakilan pengguna dan item dalam semua situasi untuk membantu model memperoleh anggaran data tidak berat sebelah akhir. Percubaan menggunakan dua set data sumber terbuka, Tianchi dan set data 84.51 (kupon). Simulasikan kesan strategi peraturan ini pada keseluruhan data melalui pensampelan. Pada masa yang sama, data yang dijana daripada senario aktiviti pemasaran e-dagang sebenar telah digunakan untuk menilai bersama kualiti algoritma. Kami membandingkan beberapa kaedah pembetulan arus perdana, seperti IPW, yang menggunakan wajaran kebarangkalian songsang untuk membetulkan kecondongan mengurangkan kesan berat sebelah dengan membuang ciri-ciri berat sebelah FairCo memperoleh anggaran yang tidak berat sebelah dengan memperkenalkan perwakilan kekangan istilah ralat; tugas menganggarkan konsistensi pengguna dan kepopularan item masing-masing, dan menolak konsistensi dan populariti dalam peringkat ramalan untuk mencapai anggaran yang tidak berat sebelah, PDA menghapuskan populariti dengan melaraskan item kerugian melalui campur tangan sebab-akibat pelarasan pintu belakang untuk menghapuskan bias maklumat, tetapi ia hanya membetulkan bias perspektif pengguna. Indeks penilaian percubaan ialah AUC Oleh kerana senario promosi pemasaran hanya mempunyai satu kupon yang disyorkan atau produk calon cadangan, ia pada asasnya merupakan masalah dua klasifikasi, jadi adalah lebih sesuai untuk menggunakan AUC untuk penilaian. . Membandingkan prestasi DNN dan MMOE di bawah seni bina yang berbeza, dapat dilihat bahawa model DMBR yang kami cadangkan mempunyai hasil yang lebih baik daripada kaedah bukan pembetulan asal dan kaedah pembetulan lain. Pada masa yang sama, Ds_A dan Ds_B telah mencapai kesan peningkatan yang lebih tinggi pada set data simulasi daripada set data perniagaan sebenar Ini kerana data dalam set data perniagaan sebenar akan menjadi lebih kompleks dan bukan sahaja akan dipengaruhi oleh peraturan dan polisi, tetapi juga mungkin dipengaruhi oleh faktor-faktor lain. Pada masa ini, model ini telah dilancarkan dalam senario acara pemasaran e-dagang Gambar di atas menunjukkan kesan dalam talian Berbanding dengan model garis dasar, model DMBR mempunyai peningkatan tertentu dalam kadar hapus kira dan jualan kelantangan.
Kaedah pembetulan sebab dan akibat digunakan terutamanya dalam Ant dalam senario di mana terdapat peraturan atau polisi yang berbeza kekangan mungkin ditetapkan Bagi khalayak sasaran untuk pengiklanan, sesetengah iklan yang menyasarkan haiwan peliharaan berkemungkinan besar akan dihantar kepada pengguna yang mempunyai haiwan peliharaan. Dalam senario pemasaran e-dagang, beberapa strategi akan ditetapkan untuk memastikan trafik peniaga kecil dan mengelakkan semua trafik digunakan oleh peniaga besar. Serta memastikan pengalaman pengguna menyertai aktiviti, kerana keseluruhan belanjawan aktiviti adalah terhad, jika sesetengah pengguna yang tidak bertanggungjawab berulang kali mengambil bahagian dalam aktiviti tersebut, sejumlah besar sumber akan diambil, mengakibatkan pengalaman penyertaan aktiviti yang lemah untuk pengguna lain. Dalam senario seperti ini, terdapat aplikasi pembetulan sebab dan akibat.
2. Pembetulan berdasarkan Fusion Data
1. yang telah diterbitkan dalam SIGIR2023 di Laluan Industri. Idea kerja ini adalah untuk menggunakan data tidak berat sebelah untuk melakukan penambahan data dan membimbing pembetulan model.


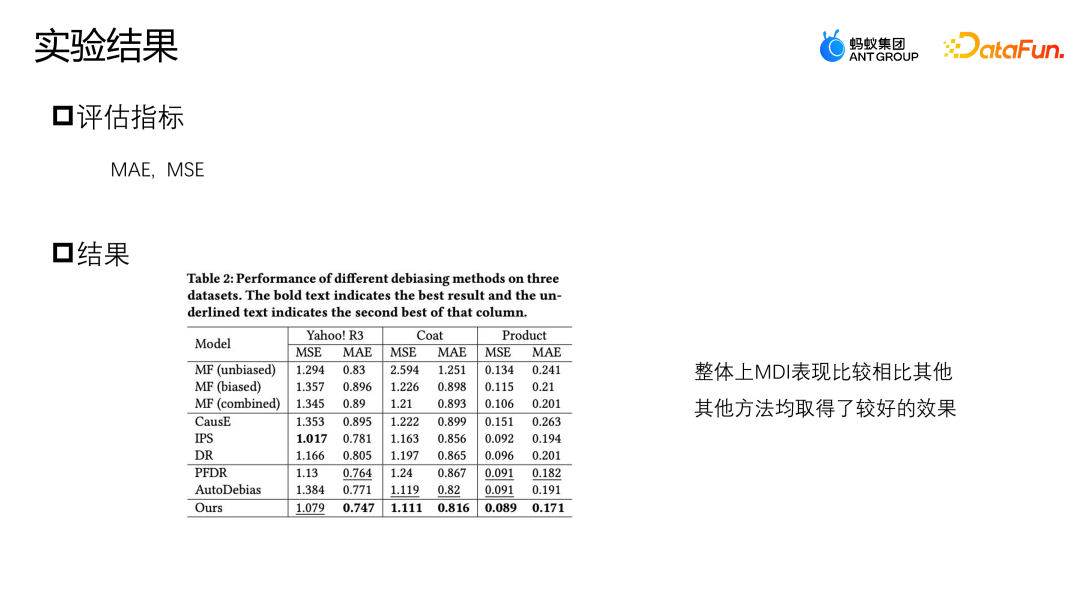
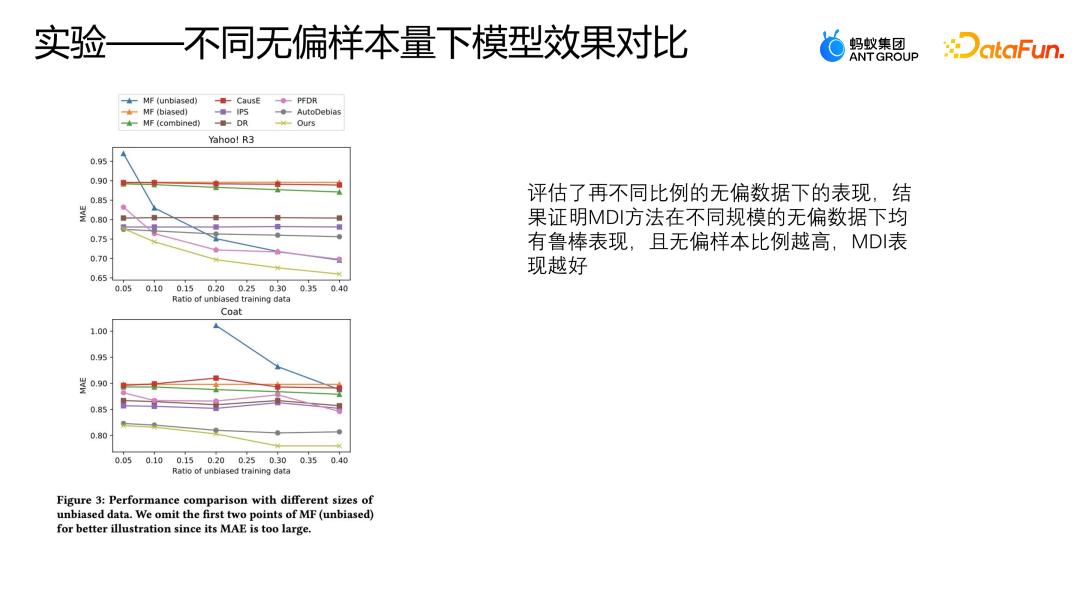 AutoDebias berprestasi betul-betul bertentangan dengan PFDR pada data yang berbeza. Memandangkan MDI telah mereka bentuk kaedah penambahan yang menggunakan kedua-dua data tidak berat sebelah dan data berat sebelah, ia mempunyai modul penambahan data yang lebih kukuh Oleh itu, ia boleh diperolehi dalam kedua-dua kes apabila terdapat sedikit data tidak berat sebelah atau apabila terdapat data tidak berat sebelah yang agak mencukupi keputusan.
AutoDebias berprestasi betul-betul bertentangan dengan PFDR pada data yang berbeza. Memandangkan MDI telah mereka bentuk kaedah penambahan yang menggunakan kedua-dua data tidak berat sebelah dan data berat sebelah, ia mempunyai modul penambahan data yang lebih kukuh Oleh itu, ia boleh diperolehi dalam kedua-dua kes apabila terdapat sedikit data tidak berat sebelah atau apabila terdapat data tidak berat sebelah yang agak mencukupi keputusan. 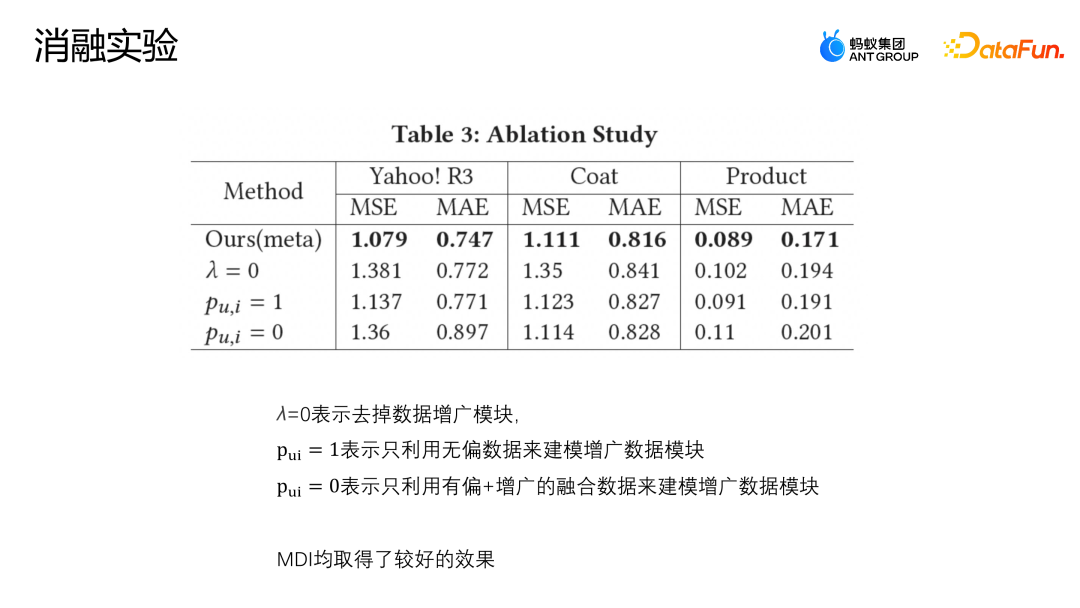
3. Pembetulan berdasarkan pelarasan pintu belakang



4. Aplikasi dalam Ant
Atas ialah kandungan terperinci Aplikasi kaedah pembetulan sebab dan akibat dalam senario pengesyoran Ant Marketing. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!