
Rumah >pembangunan bahagian belakang >Tutorial Python >Bina sistem pengesyoran filem menggunakan Python
Bina sistem pengesyoran filem menggunakan Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-12 13:13:072376semak imbas
Dalam kerja perlombongan data harian, selain menggunakan Python untuk mengendalikan tugas pengelasan atau ramalan, kadangkala ia juga melibatkan tugas yang berkaitan dengan sistem pengesyoran.
Sistem pengesyoran digunakan dalam pelbagai bidang, contoh biasa termasuk penjana senarai main untuk perkhidmatan video dan muzik, pengesyor produk untuk kedai dalam talian atau pengesyor kandungan untuk platform media sosial. Dalam projek ini, kami mencipta pengesyor filem.
Penapisan kolaboratif meramalkan (menapis) minat pengguna secara automatik dengan mengumpulkan maklumat pilihan atau rasa daripada ramai pengguna. Sistem pengesyor telah dibangunkan untuk masa yang lama setakat ini, dan model mereka adalah berdasarkan pelbagai teknik seperti purata wajaran, korelasi, pembelajaran mesin, pembelajaran mendalam, dsb.
Dataset Movielens 20M mempunyai lebih 20 juta rating filem dan peristiwa penandaan sejak 1995. Dalam artikel ini, kami akan mendapatkan maklumat daripada fail movie.csv & rating.csv. Gunakan perpustakaan Python: Pandas, Seaborn, Scikit-learn dan SciPy untuk melatih model menggunakan persamaan kosinus dalam algoritma jiran terdekat-k.
Berikut ialah langkah teras projek:
- Import dan gabungkan set data dan buat Pandas DataFrame
- Tambahkan ciri yang diperlukan untuk menganalisis data
- Gunakan Seaborn untuk menggambarkan dan menganalisis data
- Tapis data tidak sah dengan menetapkan ambang
- Buat jadual pangsi dengan pengguna sebagai indeks dan filem sebagai lajur
- Buat model dan output KNN 5 pengesyoran yang serupa dengan setiap filem
Import data
Import dan gabungkan set data dan buat Pandas DataFrame
MovieLens 20M set data sejak 1995 Lebih 20 juta rating dan penandaan filem aktiviti sejak.
# usecols 允许选择自己选择的特征,并通过dtype设定对应类型
movies_df=pd.read_csv('movies.csv',
usecols=['movieId','title'],
dtype={'movieId':'int32','title':'str'})
movies_df.head()
ratings_df=pd.read_csv('ratings.csv',
usecols=['userId', 'movieId', 'rating','timestamp'],
dtype={'userId': 'int32', 'movieId': 'int32', 'rating': 'float32'})
ratings_df.head()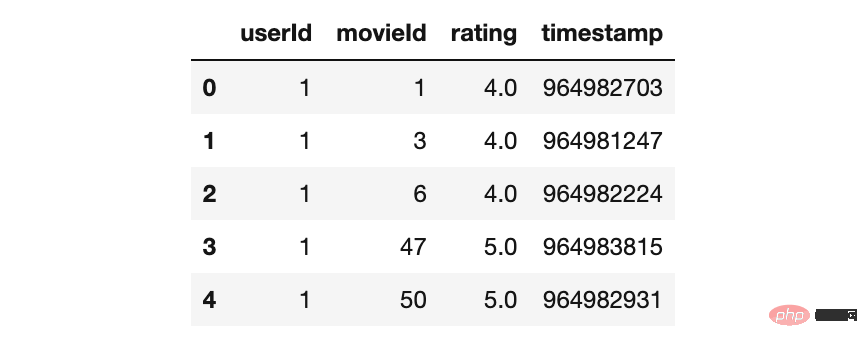
Semak sama ada terdapat sebarang nilai nol dan bilangan entri dalam kedua-dua data.
# 检查缺失值 movies_df.isnull().sum()
movieId 0
tajuk 0
dtype: int64
ratings_df.isnull().sum()
userId 0
movieId 0
rating 0
cap masa 0
dtype: int64
print("Movies:",movies_df.shape)
print("Ratings:",ratings_df.shape)Filem: (9742, 2)
Penilaian: (100836, 4)
'MovieId' bingkai data pada lajur gabungan
# movies_df.info() # ratings_df.info() movies_merged_df=movies_df.merge(ratings_df, on='movieId') movies_merged_df.head()
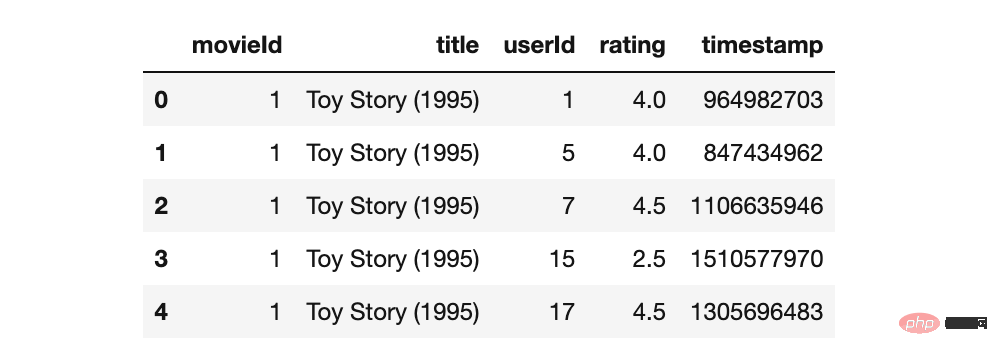
kini digabungkan berjaya mengimport set data .
Tambahkan ciri terbitan
Tambahkan ciri yang diperlukan untuk menganalisis data.
Buat lajur 'Penilaian Purata' & 'Kira Penilaian' dengan mengumpulkan rating pengguna mengikut tajuk filem.
movies_average_rating=movies_merged_df.groupby('title')['rating']
.mean().sort_values(ascending=False)
.reset_index().rename(columns={'rating':'Average Rating'})
movies_average_rating.head()
movies_rating_count=movies_merged_df.groupby('title')['rating']
.count().sort_values(ascending=True)
.reset_index().rename(columns={'rating':'Rating Count'}) #ascending=False
movies_rating_count_avg=movies_rating_count.merge(movies_average_rating, on='title')
movies_rating_count_avg.head()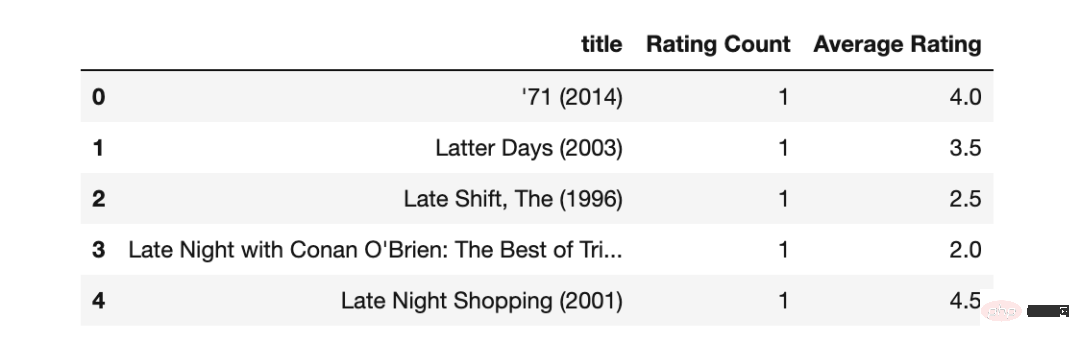
Pada masa ini 2 ciri terbitan baharu telah dicipta.
Penggambaran Data
Gunakan Seaborn untuk menggambarkan data:
- Selepas analisis, didapati bahawa banyak filem mempunyai 5 bintang sempurna pada set data yang dinilai hampir 100,000 pengguna Penilaian purata. Ini menunjukkan kehadiran outlier, yang perlu kami sahkan lagi melalui visualisasi.
- Penilaian kebanyakan filem adalah agak tunggal. Adalah disyorkan untuk menetapkan ambang penilaian untuk menjana pengesyoran yang berharga.
Gunakan seaborn & matplotlib untuk menggambarkan data untuk memerhati dan menganalisis data dengan lebih baik.
Plot histogram bagi ciri yang baru dibuat dan lihat pengedarannya. Tetapkan saiz tong kepada 80. Tetapan nilai ini memerlukan analisis terperinci dan tetapan munasabah.
# 导入可视化库
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(font_scale = 1)
plt.rcParams["axes.grid"] = False
plt.style.use('dark_background')
%matplotlib inline
# 绘制图形
plt.figure(figsize=(12,4))
plt.hist(movies_rating_count_avg['Rating Count'],bins=80,color='tab:purple')
plt.ylabel('Ratings Count(Scaled)', fontsize=16)
plt.savefig('ratingcounthist.jpg')
plt.figure(figsize=(12,4))
plt.hist(movies_rating_count_avg['Average Rating'],bins=80,color='tab:purple')
plt.ylabel('Average Rating',fontsize=16)
plt.savefig('avgratinghist.jpg')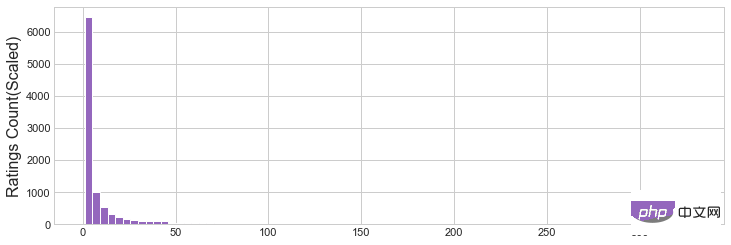
Rajah 1 Histogram Penilaian Purata
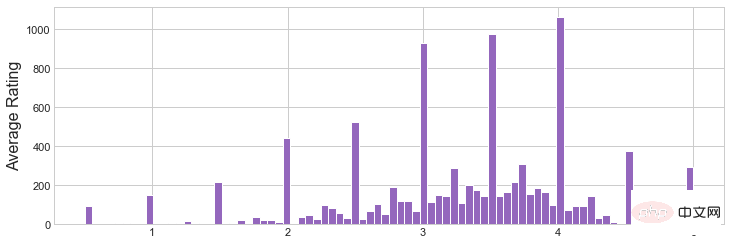
Rajah 2 Histogram Kiraan Penilaian
Sekarang buat carta 2D petak gabungan untuk menggambarkan kedua-dua ciri ini bersama-sama.
plot=sns.jointplot(x='Average Rating',
y='Rating Count',
data=movies_rating_count_avg,
alpha=0.5,
color='tab:pink')
plot.savefig('joinplot.jpg')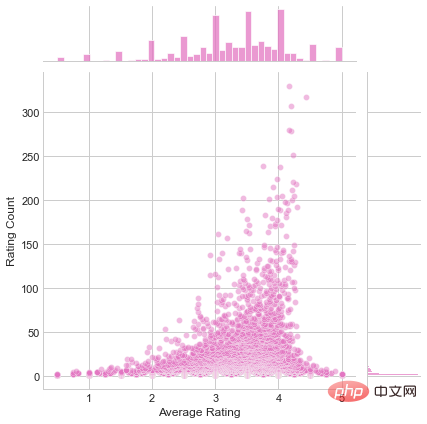
Graf dua dimensi bagi Penilaian Purata dan Kiraan Penilaian
分析
- 图1证实了,大部分电影的评分都是较低的。除了设置阈值之外,我们还可以在这个用例中使用一些更高百分比的分位数。
- 直方图 2 展示了“Average Rating”的分布函数。
数据清洗
运用describe()函数得到数据集的描述统计值,如分位数和标准差等。
pd.set_option('display.float_format', lambda x: '%.3f' % x)
print(rating_with_RatingCount['Rating Count'].describe())count 100836.000 mean58.759 std 61.965 min1.000 25% 13.000 50% 39.000 75% 84.000 max329.000 Name: Rating Count, dtype: float64
设置阈值并筛选出高于阈值的数据。
popularity_threshold = 50 popular_movies= rating_with_RatingCount[ rating_with_RatingCount['Rating Count']>=popularity_threshold] popular_movies.head() # popular_movies.shape
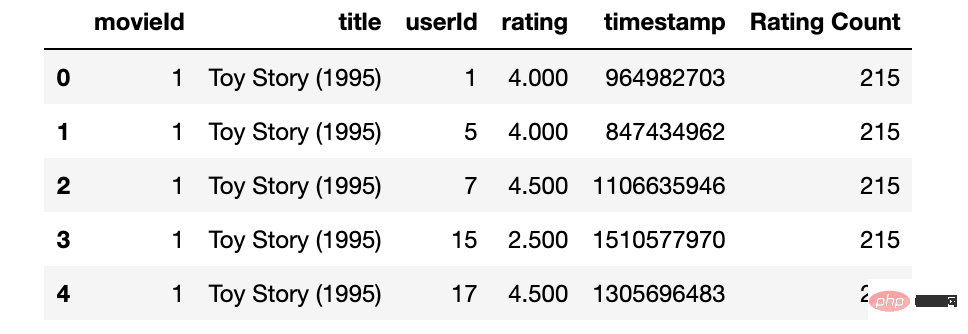
至此已经通过过滤掉了评论低于阈值的电影来清洗数据。
创建数据透视表
创建一个以用户为索引、以电影为列的数据透视表
为了稍后将数据加载到模型中,需要创建一个数据透视表。并设置'title'作为索引,'userId'为列,'rating'为值。
import os
movie_features_df=popular_movies.pivot_table(
index='title',columns='userId',values='rating').fillna(0)
movie_features_df.head()
movie_features_df.to_excel('output.xlsx')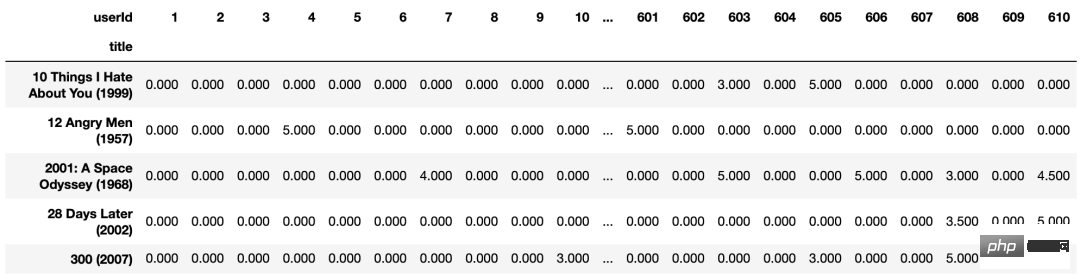
接下来将创建的数据透视表加载到模型。
建立 kNN 模型
建立 kNN 模型并输出与每部电影相似的 5 个推荐
使用scipy.sparse模块中的csr_matrix方法,将数据透视表转换为用于拟合模型的数组矩阵。
from scipy.sparse import csr_matrix movie_features_df_matrix = csr_matrix(movie_features_df.values)
最后,使用之前生成的矩阵数据,来训练来自sklearn中的NearestNeighbors算法。并设置参数:metric = 'cosine', algorithm = 'brute'
from sklearn.neighbors import NearestNeighbors model_knn = NearestNeighbors(metric = 'cosine', algorithm = 'brute') model_knn.fit(movie_features_df_matrix)
现在向模型传递一个索引,根据'kneighbors'算法要求,需要将数据转换为单行数组,并设置n_neighbors的值。
query_index = np.random.choice(movie_features_df.shape[0]) distances, indices = model_knn.kneighbors(movie_features_df.iloc[query_index,:].values.reshape(1, -1), n_neighbors = 6)
最后在 query_index 中输出出电影推荐。
for i in range(0, len(distances.flatten())):
if i == 0:
print('Recommendations for {0}:n'
.format(movie_features_df.index[query_index]))
else:
print('{0}: {1}, with distance of {2}:'
.format(i, movie_features_df.index[indices.flatten()[i]],
distances.flatten()[i]))Recommendations for Harry Potter and the Order of the Phoenix (2007): 1: Harry Potter and the Half-Blood Prince (2009), with distance of 0.2346513867378235: 2: Harry Potter and the Order of the Phoenix (2007), with distance of 0.3396233320236206: 3: Harry Potter and the Goblet of Fire (2005), with distance of 0.4170845150947571: 4: Harry Potter and the Prisoner of Azkaban (2004), with distance of 0.4499547481536865: 5: Harry Potter and the Chamber of Secrets (2002), with distance of 0.4506162405014038:
至此我们已经能够成功构建了一个仅基于用户评分的推荐引擎。
总结
以下是我们构建电影推荐系统的步骤摘要:
- 导入和合并数据集并创建 Pandas DataFrame
- 为了更好分析数据创建衍生变量
- 使用 Seaborn 可视化数据
- 通过设置阈值来清洗数据
- 创建了一个以用户为索引、以电影为列的数据透视表
- 建立一个 kNN 模型,并输出 5 个与每部电影最相似的推荐
写在最后
以下是可以扩展项目的一些方法:
- 这个数据集不是很大,可以在项目中的包含数据集中的其他文件来扩展这个项目的范围。
- 可以利用' ratings.csv' 中时间戳,分析评级在一段时间内的变化情况,并且可以在解析我们的模型时,根据时间戳对评级进行加权。
- 该模型的性能远优于加权平均或相关模型,但仍有提升的空间,如使用高级 ML 算法甚至 DL 模型。
Atas ialah kandungan terperinci Bina sistem pengesyoran filem menggunakan Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!