
Rumah >Peranti teknologi >AI >Memanjat di sepanjang kabel rangkaian telah menjadi kenyataan Audio2Photoreal boleh menjana ekspresi dan pergerakan yang realistik melalui dialog.
Memanjat di sepanjang kabel rangkaian telah menjadi kenyataan Audio2Photoreal boleh menjana ekspresi dan pergerakan yang realistik melalui dialog.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-01-12 09:03:121443semak imbas
Apabila anda dan rakan anda berbual merentasi skrin mudah alih yang sejuk, anda perlu meneka nada orang lain. Apabila dia bercakap, ekspresi dan juga tindakannya boleh muncul dalam fikiran anda. Jelas sekali adalah lebih baik jika anda boleh membuat panggilan video, tetapi dalam situasi sebenar anda tidak boleh membuat panggilan video pada bila-bila masa.
Jika anda bersembang dengan rakan jauh, ia bukan melalui teks skrin sejuk atau avatar yang tiada ekspresi, tetapi orang maya digital yang realistik, dinamik dan ekspresif. Orang maya ini bukan sahaja dapat menghasilkan semula senyuman, mata, dan juga pergerakan badan yang halus rakan anda dengan sempurna. Adakah anda akan berasa lebih baik dan hangat? Ia benar-benar merangkumi ayat "Saya akan merangkak di sepanjang kabel rangkaian untuk mencari anda."
Ini bukan fantasi fiksyen sains, tetapi teknologi yang boleh direalisasikan dalam realiti.
Ekspresi muka dan pergerakan badan mengandungi sejumlah besar maklumat, yang akan sangat mempengaruhi maksud kandungan. Sebagai contoh, bercakap sambil melihat pihak lain sepanjang masa dan bercakap tanpa bertentang mata akan memberikan orang perasaan yang sama sekali berbeza, yang juga akan menjejaskan pemahaman pihak lain tentang kandungan komunikasi. Kami mempunyai keupayaan yang sangat berminat untuk mengesan ekspresi dan pergerakan halus ini semasa komunikasi dan menggunakannya untuk membangunkan pemahaman tahap tinggi tentang niat, tahap keselesaan atau pemahaman rakan perbualan. Oleh itu, membangunkan avatar perbualan yang sangat realistik yang menangkap kehalusan ini adalah penting untuk interaksi.
Untuk tujuan ini, penyelidik dari Meta dan University of California telah mencadangkan kaedah untuk menjana manusia maya yang realistik berdasarkan audio pertuturan perbualan antara dua orang. Ia boleh mensintesis pelbagai gerak isyarat frekuensi tinggi dan pergerakan muka ekspresif yang disegerakkan rapat dengan pertuturan. Untuk badan dan tangan, mereka mengeksploitasi kelebihan pendekatan berasaskan VQ autoregresif dan model penyebaran. Untuk wajah, mereka menggunakan model resapan yang dikondisikan pada audio. Pergerakan muka, badan dan tangan yang diramalkan kemudiannya dijadikan manusia maya yang realistik. Kami menunjukkan bahawa menambahkan syarat gerak isyarat berpandu pada model resapan boleh menjana gerak isyarat perbualan yang lebih pelbagai dan munasabah berbanding karya sebelumnya. . ng/ projects/audio2photoreal/

Para penyelidik berkata mereka adalah pasukan pertama yang mengkaji cara menjana pergerakan muka, badan dan tangan yang realistik untuk perbualan interpersonal. Berbanding dengan kajian terdahulu, para penyelidik mensintesis tindakan yang lebih realistik dan pelbagai berdasarkan kaedah VQ dan penyebaran.
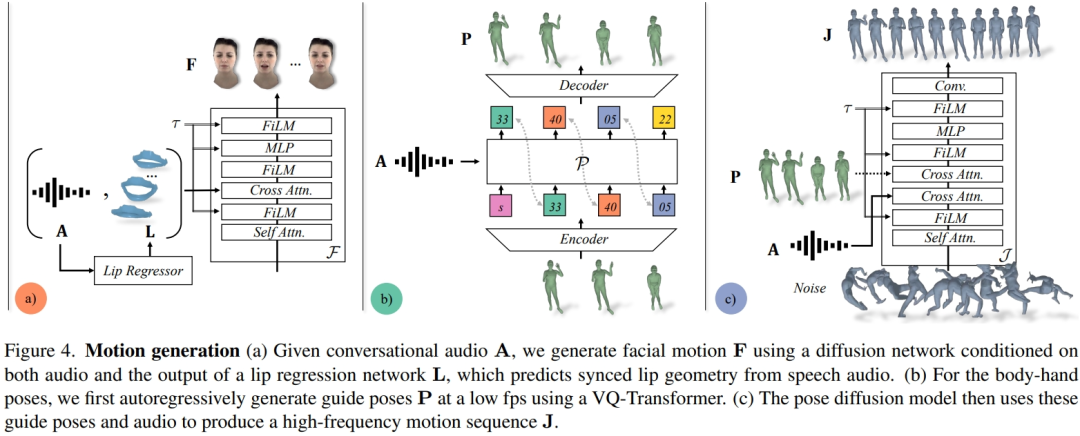
- Gambaran Keseluruhan KaedahPenyelidik mengekstrak kod ekspresi terpendam daripada data berbilang pandangan yang direkodkan untuk mewakili wajah, dan menggunakan sudut sendi dalam rangka kinematik untuk mewakili postur badan. Seperti yang ditunjukkan dalam Rajah 3, sistem ini terdiri daripada dua model generatif, yang menjana kod ekspresi dan urutan postur badan apabila memasukkan audio perbualan dua orang. Kod ekspresi dan urutan pose badan kemudiannya boleh dipaparkan dalam bingkai demi bingkai menggunakan Neural Avatar Renderer, yang boleh menjana avatar bertekstur sepenuhnya dengan muka, badan dan tangan daripada paparan kamera yang diberikan.
- Perlu diingatkan bahawa dinamik badan dan muka sangat berbeza. Pertama, wajah berkorelasi kuat dengan audio input, terutamanya pergerakan bibir, manakala badan berkorelasi lemah dengan pertuturan. Ini menghasilkan kepelbagaian gerak isyarat badan yang lebih kompleks dalam input pertuturan yang diberikan. Kedua, memandangkan muka dan badan diwakili dalam dua ruang yang berbeza, mereka masing-masing mengikut dinamik temporal yang berbeza. Oleh itu, para penyelidik menggunakan dua model gerakan bebas untuk mensimulasikan muka dan badan. Dengan cara ini, model muka boleh "memberi tumpuan" pada butiran muka yang konsisten dengan pertuturan, manakala model badan boleh memberi lebih tumpuan kepada penjanaan pergerakan badan yang pelbagai tetapi munasabah.
Model gerakan muka ialah model resapan yang dikondisikan pada audio input dan bucu bibir yang dijana oleh regressor bibir yang telah terlatih (Rajah 4a). Bagi model pergerakan anggota badan, penyelidik mendapati bahawa pergerakan yang dihasilkan oleh model penyebaran tulen yang hanya dikondisikan pada audio tidak mempunyai kepelbagaian dan tidak cukup diselaraskan dalam urutan masa. Walau bagaimanapun, kualiti bertambah baik apabila penyelidik menggunakan postur bimbingan yang berbeza. Oleh itu, mereka membahagikan model gerakan badan kepada dua bahagian: pertama, perapi audio autoregresif meramalkan pose panduan kasar pada 1 fp (Rajah 4b), dan kemudian model resapan menggunakan pose panduan kasar ini untuk mengisi butiran halus dan tinggi. pergerakan frekuensi (Rajah 4c). Lihat artikel asal untuk mendapatkan butiran lanjut tentang tetapan kaedah.
Eksperimen dan keputusan
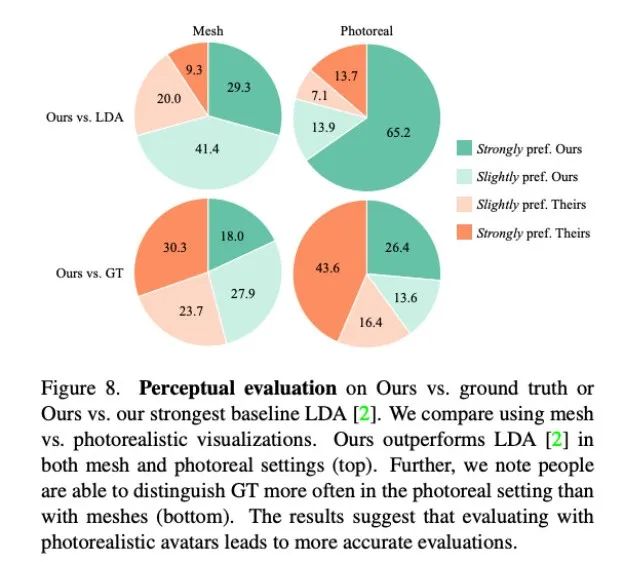
Para penyelidik menilai secara kuantitatif keupayaan Audio2Photoreal untuk menjana tindakan dialog yang realistik dengan berkesan berdasarkan data sebenar. Penilaian persepsi juga dilakukan untuk mengesahkan keputusan kuantitatif dan mengukur kesesuaian Audio2Photoreal dalam menghasilkan gerak isyarat dalam konteks perbualan tertentu. Keputusan eksperimen menunjukkan bahawa penilai lebih sensitif terhadap gerak isyarat halus apabila gerak isyarat tersebut dipersembahkan pada avatar yang realistik dan bukannya mesh 3D.
Para penyelidik membandingkan hasil yang dihasilkan kaedah ini dengan tiga kaedah asas: KNN, SHOW, dan LDA berdasarkan urutan gerakan rawak dalam set latihan. Eksperimen ablasi telah dijalankan untuk menguji keberkesanan setiap komponen Audio2Photoreal tanpa audio atau gerak isyarat berpandu, tanpa gerak isyarat berpandu tetapi berdasarkan audio, dan tanpa audio tetapi berdasarkan gerak isyarat berpandu.
Keputusan kuantitatif
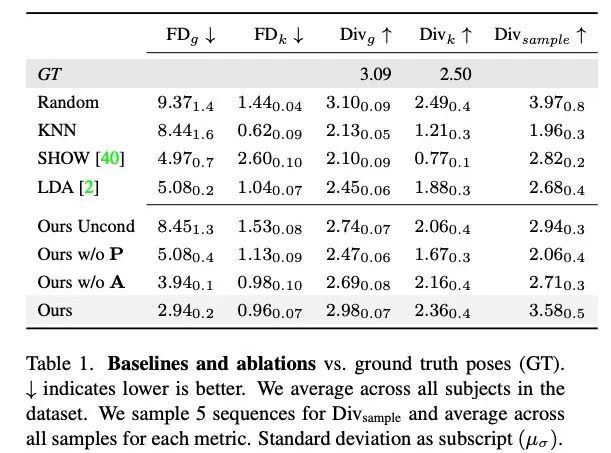
Jadual 1 menunjukkan bahawa berbanding dengan kajian terdahulu, kaedah kami mempunyai skor FD terendah apabila menjana gerakan dengan kepelbagaian tertinggi. Walaupun rawak mempunyai kepelbagaian yang baik yang sepadan dengan GT, segmen rawak tidak sepadan dengan dinamik perbualan yang sepadan, menghasilkan FD_g yang tinggi.
Rajah 5 menunjukkan kepelbagaian pose bimbingan yang dihasilkan oleh kaedah kami. Pensampelan P transformer berasaskan VQ membolehkan penjanaan gerak isyarat yang sangat berbeza dengan input audio yang sama.

Seperti yang ditunjukkan dalam Rajah 6, model resapan akan belajar untuk menjana tindakan dinamik, di mana tindakan akan lebih sepadan dengan audio perbualan.

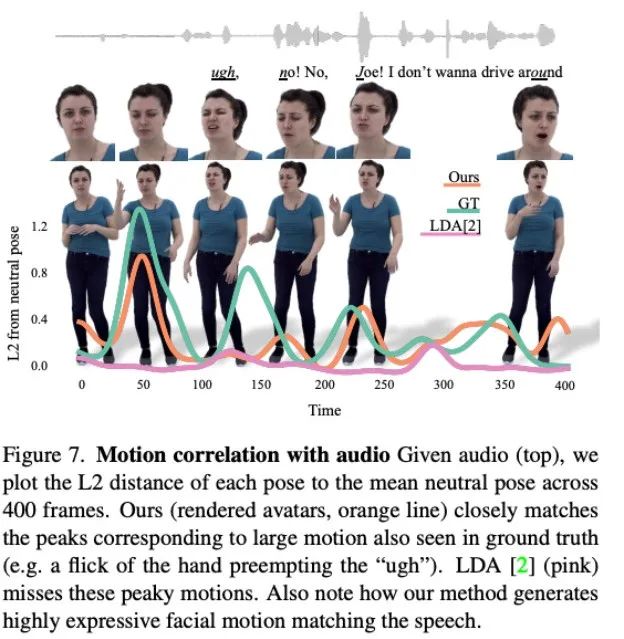
Rajah 7 menunjukkan bahawa gerakan yang dihasilkan oleh LDA tidak mempunyai daya hidup dan kurang pergerakan. Sebaliknya, perubahan gerakan yang disintesis oleh kaedah ini lebih konsisten dengan keadaan sebenar.
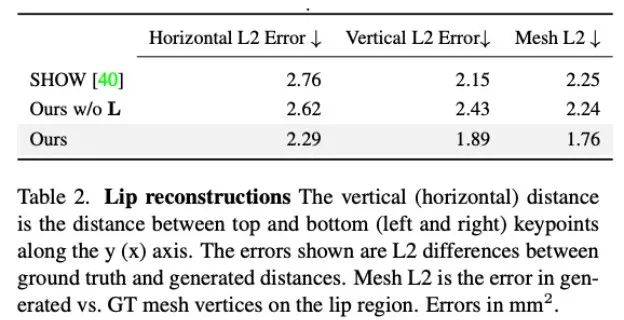
Selain itu, pengkaji turut menganalisis ketepatan kaedah ini dalam menghasilkan pergerakan bibir. Seperti yang ditunjukkan oleh statistik dalam Jadual 2, Audio2Photoreal mengatasi dengan ketara kaedah garis dasar SHOW, serta prestasi selepas mengalih keluar regressor bibir terlatih dalam eksperimen ablasi. Reka bentuk ini meningkatkan penyegerakan bentuk mulut semasa bercakap, dengan berkesan mengelakkan pergerakan rawak membuka dan menutup mulut apabila tidak bercakap, membolehkan model mencapai pembinaan semula pergerakan bibir yang lebih baik, dan pada masa yang sama mengurangkan bucu jejaring muka ( Grid L2) ralat.
Penilaian kualitatif
Memandangkan keselarasan gerak isyarat dalam perbualan sukar untuk diukur, penyelidik menggunakan kaedah kualitatif untuk penilaian. Mereka menjalankan dua set ujian A/B di MTurk. Secara khusus, mereka meminta penilai untuk menonton hasil yang dijana bagi kaedah kami dan kaedah garis dasar atau pasangan video kaedah kami dan adegan sebenar, dan meminta mereka menilai video yang mana usul itu kelihatan lebih munasabah.
Seperti yang ditunjukkan dalam Rajah 8, kaedah ini jauh lebih baik daripada kaedah garis dasar sebelumnya LDA, dan kira-kira 70% daripada penilai memilih Audio2Photoreal dari segi grid dan realisme.
Seperti yang ditunjukkan dalam carta teratas Rajah 8, berbanding dengan LDA, penilaian penilai kaedah ini berubah daripada "sangat suka" kepada "sangat suka". Berbanding dengan keadaan sebenar, penilaian yang sama dibentangkan. Namun, penilai lebih mengutamakan perkara sebenar berbanding Audio2Photoreal dalam hal realisme.
Untuk butiran lanjut teknikal, sila baca kertas asal.
Atas ialah kandungan terperinci Memanjat di sepanjang kabel rangkaian telah menjadi kenyataan Audio2Photoreal boleh menjana ekspresi dan pergerakan yang realistik melalui dialog.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!