
Rumah >Peranti teknologi >AI >Pratonton GPT-5! Allen Institute for Artificial Intelligence mengeluarkan model multi-modal terkuat untuk meramalkan keupayaan baharu GPT-5
Pratonton GPT-5! Allen Institute for Artificial Intelligence mengeluarkan model multi-modal terkuat untuk meramalkan keupayaan baharu GPT-5

- PHPzke hadapan
- 2024-01-11 18:21:41617semak imbas
Bilakah GPT-5 akan tiba dan apakah keupayaan yang akan ada?
Sebuah model baharu dari Allen Institute for AI memberitahu anda jawapannya.
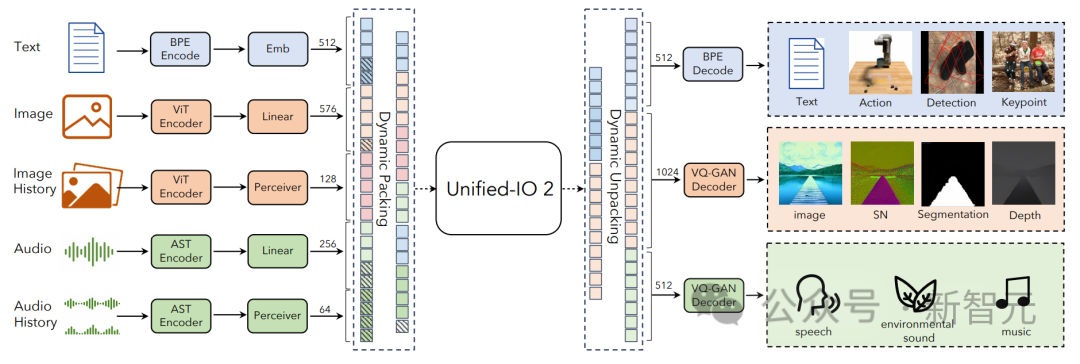
Unified-IO 2 yang dilancarkan oleh Allen Institute for Artificial Intelligence ialah model pertama yang boleh memproses dan menjana teks, imej, audio, video dan urutan tindakan.
Model AI lanjutan ini dilatih menggunakan berbilion titik data Saiz model hanya 7B, tetapi ia mempamerkan keupayaan berbilang modal yang paling luas setakat ini.

Alamat kertas: https://arxiv.org/pdf/2312.17172.pdf
Jadi, apakah hubungan antara Unified-IO 2 dan GPT-5?
Pada Jun 2022, Allen Institute for Artificial Intelligence melancarkan generasi pertama Unified-IO, menjadi salah satu model berbilang modal yang mampu memproses imej dan bahasa secara serentak.
Pada masa yang sama, OpenAI sedang menguji GPT-4 secara dalaman dan akan mengeluarkannya secara rasmi pada Mac 2023.
Jadi, Unified-IO boleh dilihat sebagai pratonton model AI berskala besar masa hadapan.
OpenAI mungkin menguji GPT-5 secara dalaman dan akan mengeluarkannya dalam beberapa bulan.
Keupayaan yang ditunjukkan kepada kami oleh Unified-IO 2 kali ini juga akan menjadi perkara yang boleh kami nantikan pada tahun baharu:
GPT-5 dan model AI baharu yang lain boleh mengendalikan lebih banyak modaliti, Pembelajaran yang meluas untuk melaksanakan banyak tugas secara tempatan dan pemahaman asas berinteraksi dengan objek dan robot.
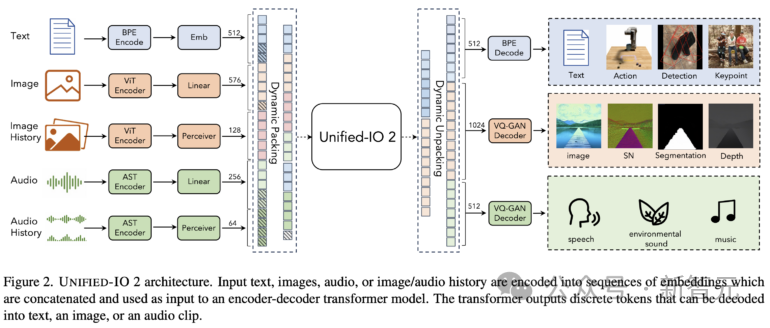
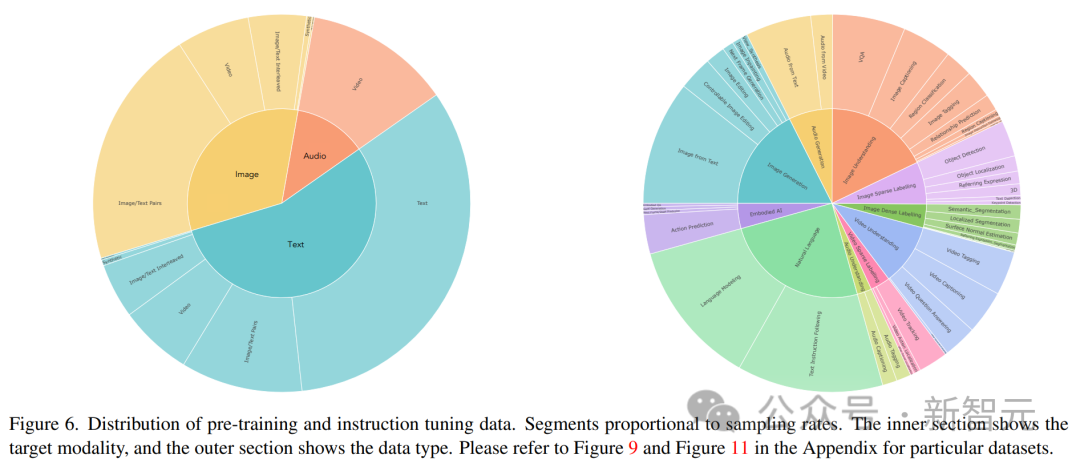
Data latihan Unified-IO 2 termasuk: 1 bilion pasangan teks imej, 1 trilion tag teks, 180 juta klip video, 130 juta imej dengan teks, 3 juta aset 3D dan 1 juta jujukan gerakan ejen robot.
Pasukan penyelidik menggabungkan sejumlah lebih daripada 120 set data ke dalam pakej 600 TB yang meliputi 220 tugas visual, bahasa, pendengaran dan motor.
Unified-IO 2 menggunakan seni bina penyahkod pengekod dengan beberapa perubahan untuk menstabilkan latihan dan menggunakan isyarat berbilang modal dengan berkesan.
Model boleh menjawab soalan, menulis teks mengikut arahan dan menganalisis kandungan teks.
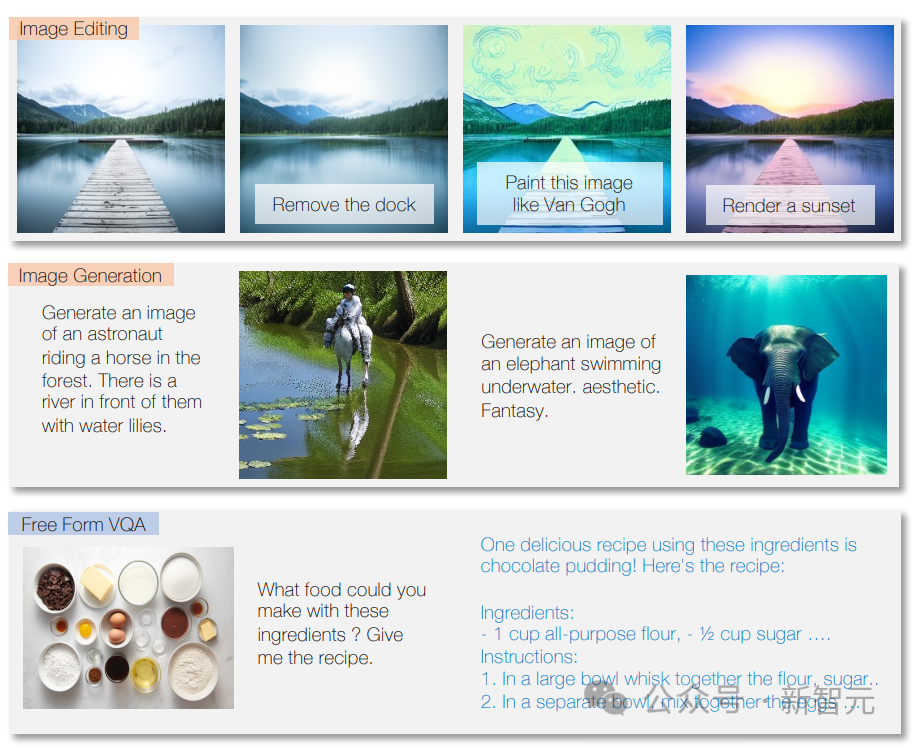
Model ini juga boleh mengenal pasti kandungan imej, memberikan penerangan imej, melaksanakan tugas pemprosesan imej dan mencipta imej baharu berdasarkan penerangan teks.
Ia juga boleh menjana muzik atau bunyi berdasarkan penerangan atau arahan, serta menganalisis video dan menjawab soalan tentangnya.
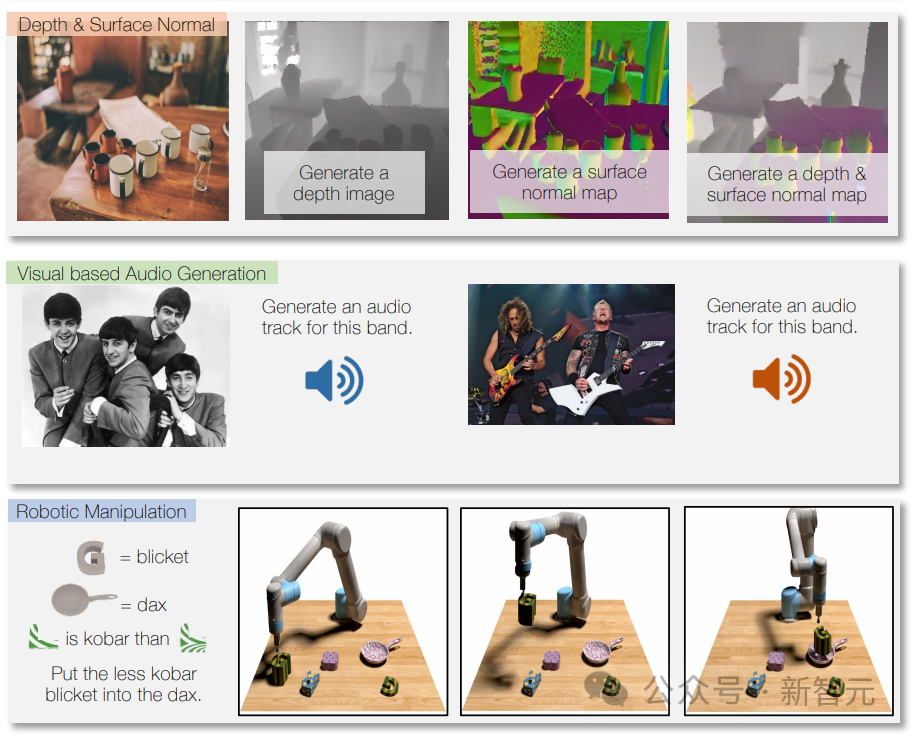
Dengan menggunakan data robot untuk latihan, Unified-IO 2 juga boleh menjana tindakan untuk sistem robot, seperti menukar arahan kepada urutan tindakan untuk robot.
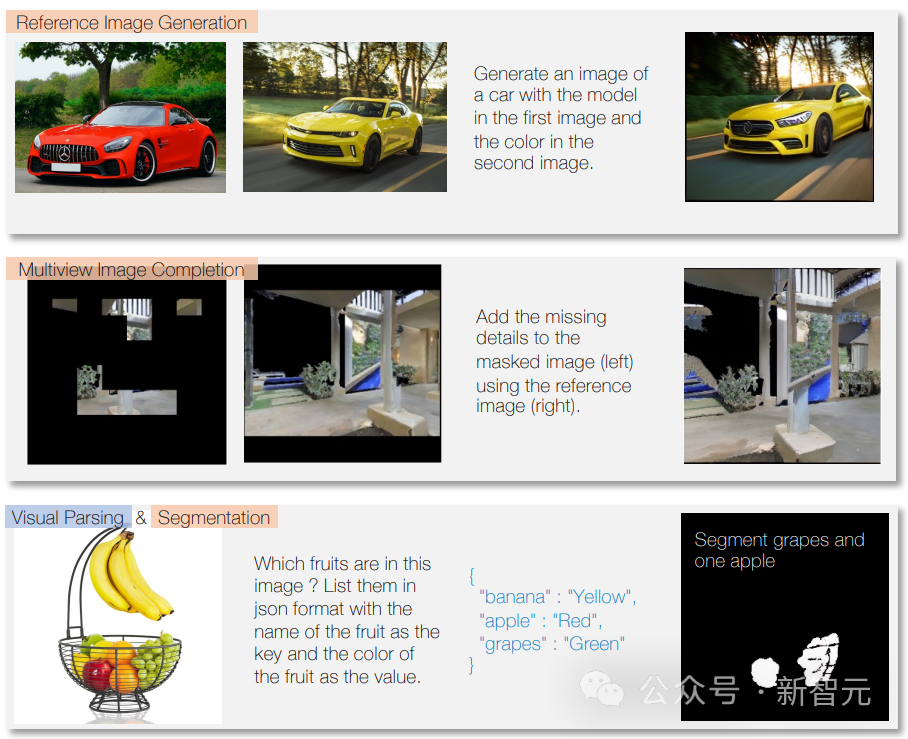
Terima kasih kepada latihan pelbagai modal, ia juga boleh mengendalikan modaliti yang berbeza, contohnya, melabelkan instrumen yang digunakan dalam trek tertentu pada imej.

Unified-IO 2 berprestasi baik pada lebih daripada 35 penanda aras, termasuk penjanaan dan pemahaman imej, pemahaman bahasa semula jadi, pemahaman video dan audio serta manipulasi robot.
Dalam kebanyakan tugas, ia adalah sebaik atau lebih baik daripada model khusus.
Unified-IO 2 mencapai markah tertinggi setakat ini pada penanda aras GRIT untuk tugasan imej (GRIT digunakan untuk menguji cara model mengendalikan hingar imej dan isu lain).
Para penyelidik kini merancang untuk melanjutkan lagi Unified-IO 2, meningkatkan kualiti data dan mengubah model penyahkod pengekod kepada seni bina model penyahkod standard industri.
Unified-IO 2
Unified-IO 2 ialah model berbilang mod autoregresif pertama yang mampu memahami dan menjana imej, teks, audio dan gerakan.
Untuk menyatukan modaliti yang berbeza, penyelidik melabelkan input dan output (imej, teks, audio, tindakan, kotak sempadan, dll.) ke dalam ruang semantik dikongsi dan kemudian menggunakan model pengubah pengekod-penyahkod tunggal Memprosesnya.
Disebabkan jumlah data yang banyak digunakan untuk melatih model dan datang daripada pelbagai modaliti yang berbeza, penyelidik telah menggunakan beberapa siri teknik untuk menambah baik keseluruhan proses latihan.
Untuk memudahkan pembelajaran isyarat penyeliaan sendiri dengan berkesan merentas pelbagai modaliti, penyelidik membangunkan hibrid multimodal baru bagi sasaran denoiser yang menggabungkan denoiser silang mod dan penjanaan.
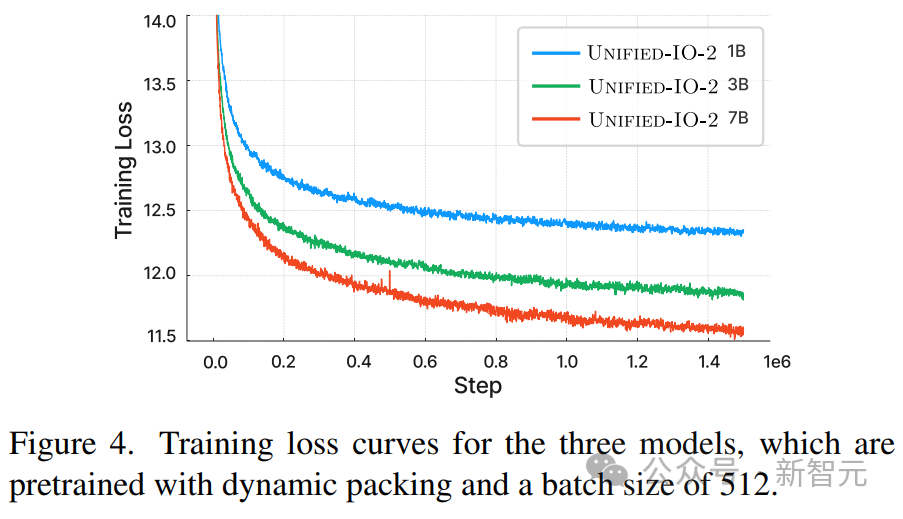
Pembungkusan dinamik juga telah dibangunkan untuk meningkatkan daya pengeluaran latihan sebanyak 4x untuk mengendalikan urutan yang sangat berubah-ubah.
Untuk mengatasi isu kestabilan dan kebolehskalaan dalam latihan, penyelidik membuat perubahan seni bina pada resampler perceptron, termasuk pembenaman putaran 2D, penormalan QK dan mekanisme perhatian kosinus berskala.
Untuk pelarasan arahan, pastikan setiap misi mempunyai gesaan yang jelas, sama ada menggunakan misi sedia ada atau membuat yang baharu. Tugasan terbuka juga disertakan, dan tugasan sintetik dicipta untuk corak yang kurang biasa untuk meningkatkan kepelbagaian tugas dan pengajaran.
Nyatakan Tugas Perwakilan Data Multimodal ke dalam urutan token dalam ruang perwakilan bersama, termasuk aspek berikut:
Text, struktur jarang dan operasiText input dan output adalah token menggunakan pengekodan pasangan bait dalam LLaMA, struktur jarang seperti kotak sempadan, titik kekunci dan pose kamera didiskrisikan dan kemudian dikodkan menggunakan 1000 token khas yang ditambahkan pada perbendaharaan kata.
Mata dikodkan menggunakan dua penanda (x, y), kotak dikodkan dengan urutan empat penanda (kiri atas dan kanan bawah), dan kuboid 3D diwakili dengan 12 penanda (pusat unjuran pengekodan, kedalaman maya, pasangan (bilangan saiz kotak yang dinormalkan, dan putaran sepusat berterusan).
Untuk tugasan yang terkandung, tindakan robot diskret dijana sebagai arahan teks (cth., "maju ke hadapan"). Tag khas digunakan untuk mengekod keadaan robot (seperti kedudukan dan putaran).
Imej dan Struktur Padat
Imej dikodkan menggunakan pengubah visual terlatih (ViT). Ciri tampalan lapisan kedua dan kedua terakhir ViT digabungkan untuk menangkap maklumat visual peringkat rendah dan tinggi.
Apabila menjana imej, gunakan VQ-GAN untuk menukar imej kepada penanda diskret Di sini, model VQ-GAN padat yang telah dilatih dengan saiz tampalan 8 × 8 digunakan untuk mengekod imej 256 × 256 ke dalam. 1024 token dan buku kod Saiznya ialah 16512.
Kemudian nyatakan setiap label piksel (termasuk kedalaman, permukaan normal dan topeng segmentasi binari) sebagai imej RGB.
Audio
U-IO 2 mengekod sehingga 4.08 saat audio ke dalam spektrogram, kemudian menggunakan penukar spektrogram audio terlatih (AST) untuk mengekod spektrogram dan menggabungkan ciri-ciri lapisan kedua AST dan gunakan lapisan linear untuk membina pembenaman input, sama seperti imej ViT.
Apabila menjana audio, gunakan ViT-VQGAN untuk menukar audio kepada token diskret Saiz tampalan model ialah 8 × 8, dan spektrogram 256 × 128 dikodkan kepada 512 token Saiz buku kod ialah 8196.
Imej dan Sejarah Audio
Model ini membenarkan sehingga empat segmen imej dan audio tambahan disediakan sebagai input, elemen ini juga dikodkan menggunakan ViT atau AST, dan seterusnya menggunakan resampler perceptron, ciri-cirinya lebih lanjut dimampatkan ke dalam nombor Bawah (32 untuk imej dan 16 untuk audio).
Ini mengurangkan panjang jujukan dengan ketara dan membolehkan model meneliti imej atau klip audio secara terperinci sambil menggunakan elemen daripada sejarah sebagai konteks.
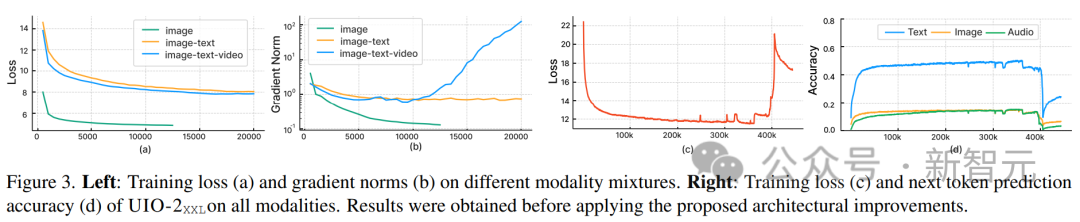
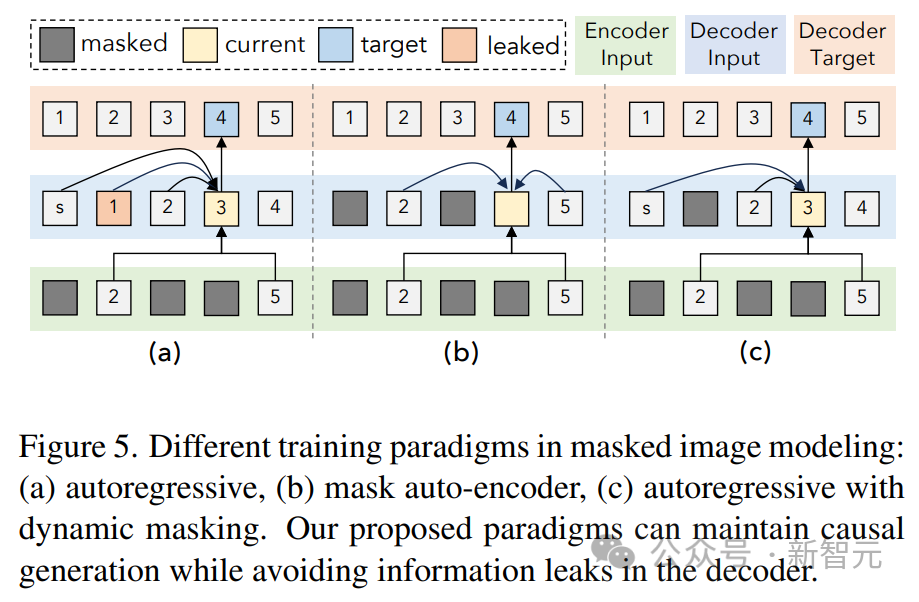
Penyelidik telah memerhatikan bahawa semasa kami menyepadukan mod lain, pelaksanaan standard selepas menggunakan U-IO membawa kepada latihan yang semakin tidak stabil. Seperti yang ditunjukkan dalam (a) dan (b) di bawah, latihan hanya pada penjanaan imej (lengkung hijau) membawa kepada kehilangan yang stabil dan penumpuan norma kecerunan. Memperkenalkan gabungan tugasan imej dan teks (lengkung oren) sedikit meningkatkan norma kecerunan berbanding modaliti tunggal, tetapi kekal stabil. Walau bagaimanapun, termasuk modaliti video (lengkung biru) menghasilkan peningkatan tanpa had bagi norma kecerunan. Seperti yang ditunjukkan dalam (c) dan (d) rajah, apabila versi XXL model dilatih pada semua modaliti, kerugian meletup selepas 350k langkah, dan ketepatan ramalan penanda seterusnya muncul pada 400k langkah jatuh. Untuk menyelesaikan masalah ini, penyelidik membuat pelbagai perubahan seni bina: Gunakan Putaran Position Embedding (RoPE) pada setiap lapisan Transformer. Untuk modaliti bukan teks, RoPE dilanjutkan ke lokasi 2D apabila modaliti imej dan audio disertakan, LayerNorm digunakan pada Q dan K sebelum pengiraan perhatian produk titik. Selain itu, menggunakan resampler perceptron, setiap bingkai imej dan klip audio dimampatkan ke dalam bilangan token tetap, dan menggunakan perhatian kosinus berskala untuk menggunakan normalisasi yang lebih ketat dalam perceptron, yang merupakan kereta api yang stabil dengan ketara. Untuk mengelakkan ketidakstabilan berangka, logaritma perhatian float32 juga didayakan, dan ViT dan AST dibekukan semasa pra-latihan dan diperhalusi pada akhir pelarasan arahan. Rajah di atas menunjukkan bahawa walaupun terdapat kepelbagaian modaliti input dan output, kehilangan pra-latihan model adalah stabil. Artikel ini mengikut paradigma UL2. Untuk sasaran imej dan audio, dua paradigma serupa ditakrifkan di sini: [R]: menutup topeng, menutup secara rawak x% daripada imej input atau ciri tampung audio dan membiarkan model membinanya semula [S] : Memerlukan model untuk menjana modaliti sasaran di bawah keadaan modal input lain. Semasa latihan, teks input awalan dengan penanda modal ([Teks], [Imej], atau [Audio]) dan penanda paradigma ([R], [S] atau [X]) untuk menunjukkan tugas , dan gunakan pelekat dinamik untuk autoregresi. Seperti yang ditunjukkan dalam rajah di atas, satu masalah dengan imej dan audio masking denoising ialah kebocoran maklumat di bahagian penyahkod. Penyelesaian di sini adalah untuk menutup token dalam penyahkod (melainkan meramalkan token ini), yang tidak mengganggu ramalan sebab-akibat sambil menghapuskan kebocoran data. Latihan pada sejumlah besar data berbilang modal akan menghasilkan panjang jujukan yang sangat berubah-ubah untuk input dan output penukar. Pembungkusan digunakan di sini untuk menyelesaikan masalah ini: teg untuk berbilang contoh dimasukkan ke dalam urutan, dan perhatian dilindungi untuk menghalang penukar daripada terlibat silang antara contoh. Semasa latihan, algoritma heuristik digunakan untuk menyusun semula data yang distrim ke model supaya sampel panjang dipadankan dengan sampel pendek yang boleh dibungkus. Pembungkusan dinamik artikel ini meningkatkan daya pengeluaran latihan hampir 4 kali ganda. Penalaan arahan berbilang modal ialah proses utama untuk melengkapkan model dengan kemahiran dan keupayaan berbeza untuk pelbagai modaliti, malah menyesuaikan diri dengan arahan baharu dan unik. Penyelidik membina set data penalaan arahan berbilang mod dengan menggabungkan pelbagai set set data dan tugasan yang diselia. Taburan data penalaan arahan ditunjukkan dalam rajah di atas. Secara keseluruhan, campuran penalaan arahan terdiri daripada 60% data pembayang, 30% data yang diwarisi daripada pra-latihan (untuk mengelakkan pelupaan bencana), 6% data penambahan tugasan yang dibina menggunakan sumber data sedia ada dan 4% Teks bentuk bebas (untuk mendayakan sembang -balas seperti).
Seni bina model dan teknologi untuk latihan yang stabil
Objektif latihan pelbagai mod
Pengoptimuman Kecekapan
Penalaan Arahan
Atas ialah kandungan terperinci Pratonton GPT-5! Allen Institute for Artificial Intelligence mengeluarkan model multi-modal terkuat untuk meramalkan keupayaan baharu GPT-5. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 关系数据模型是什么
- 计算机显示器采用的颜色模型是什么
- Aplikasi dan penyelidikan carian industri berdasarkan model bahasa pra-terlatih
- Pengaturcara berada dalam bahaya! Dikatakan bahawa OpenAI merekrut tentera penyumberan luar secara global dan melatih petani kod ChatGPT langkah demi langkah
- NUS dan Byte bekerjasama merentas industri untuk mencapai latihan 72 kali lebih pantas melalui pengoptimuman model, dan memenangi Kertas Cemerlang AAAI2023.