
Rumah >Peranti teknologi >AI >Menerobos dinding dimensi, X-Dreamer membawa teks berkualiti tinggi kepada penjanaan 3D, menyepadukan bidang penjanaan 2D dan 3D.
Menerobos dinding dimensi, X-Dreamer membawa teks berkualiti tinggi kepada penjanaan 3D, menyepadukan bidang penjanaan 2D dan 3D.

- PHPzke hadapan
- 2023-12-15 13:54:33595semak imbas
Dalam beberapa tahun kebelakangan ini, kemajuan ketara telah dicapai dalam menukar teks secara automatik kepada kandungan 3D, didorong oleh pembangunan model resapan terlatih [1, 2, 3]. Antaranya, DreamFusion[4] memperkenalkan kaedah berkesan yang menggunakan model penyebaran 2D terlatih[5] untuk menjana aset 3D secara automatik daripada teks tanpa memerlukan set data aset 3D khusus
Diperkenalkan oleh DreamFusion Inovasi utama ialah algoritma Pensampelan Penyulingan Pecahan (SDS). Algoritma menilai perwakilan 3D tunggal menggunakan model resapan 2D terlatih, seperti NeRF [6], mengoptimumkannya untuk memastikan imej yang diberikan daripada mana-mana perspektif kamera mengekalkan konsistensi yang tinggi dengan teks yang diberikan. Diilhamkan oleh algoritma SDS mani, beberapa karya [7, 8, 9, 10, 11] telah muncul untuk memajukan tugas penjanaan teks-ke-3D dengan menggunakan model penyebaran 2D yang telah terlatih.
Walaupun kemajuan ketara telah dicapai dalam penjanaan teks-ke-3D dengan memanfaatkan model resapan teks-ke-2D yang telah terlatih, masih terdapat jurang medan yang besar antara imej 2D dan aset 3D. Perbezaan ini jelas ditunjukkan dalam Rajah 1.
Pertama, model teks-ke-2D menghasilkan hasil penjanaan agnostik kamera, memfokuskan pada penjanaan imej berkualiti tinggi dari sudut tertentu sambil mengabaikan sudut lain. Sebaliknya, penciptaan kandungan 3D terikat dengan parameter kamera seperti kedudukan, sudut penangkapan dan medan pandangan. Oleh itu, model teks-ke-3D mesti menghasilkan hasil yang berkualiti tinggi ke atas semua parameter kamera yang mungkin.
Selain itu, model generatif teks-ke-2D perlu menjana elemen latar depan dan latar belakang secara serentak untuk mengekalkan keselarasan keseluruhan imej. Sebaliknya, model generatif teks-ke-3D hanya perlu menumpukan pada mencipta objek latar depan. Perbezaan ini membolehkan model teks-ke-3D memperuntukkan lebih banyak sumber dan perhatian untuk mewakili dan menjana objek latar depan dengan tepat. Oleh itu, apabila menggunakan model penyebaran 2D terlatih secara langsung untuk penciptaan aset 3D, perbezaan domain antara penjanaan teks-ke-2D dan teks-ke-3D menjadi halangan prestasi yang jelas
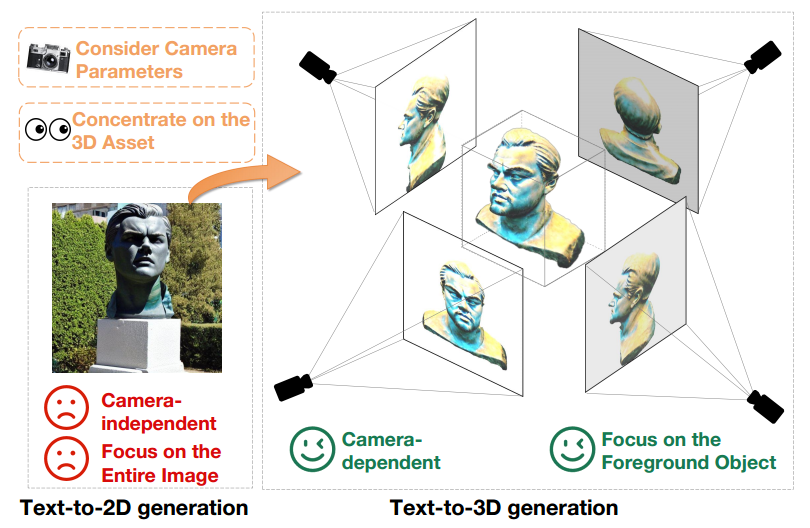
Rajah 1 Output teks bagi model terjana -ke-2D (kiri) dan model terjana teks-ke-3D (kanan) di bawah gesaan teks yang sama, iaitu "Patung kepala Leonardo DiCaprio."
Untuk menyelesaikan masalah ini, kertas kerja mencadangkan X-Dreamer, kaedah baru untuk penciptaan kandungan teks-ke-3D berkualiti tinggi yang boleh merapatkan jurang teks-ke-2D dan teks-ke-3D antara generasi dengan berkesan.
Komponen utama X-Dreamer ialah dua reka bentuk yang inovatif: Penyesuaian Peringkat Rendah Berpandukan Kamera (CG-LoRA) dan kehilangan Penjajaran Topeng Perhatian (AMA).
Pertama, kaedah sedia ada [7, 8, 9, 10] biasanya menggunakan model resapan pra-latihan 2D [5, 12] untuk penjanaan teks-ke-3D, yang tidak mempunyai sambungan yang wujud dengan parameter kamera. Untuk menangani had ini dan memastikan X-Dreamer menghasilkan hasil yang dipengaruhi secara langsung oleh parameter kamera, makalah ini memperkenalkan CG-LoRA untuk melaraskan model resapan 2D yang telah terlatih. Terutamanya, parameter CG-LoRA dijana secara dinamik berdasarkan maklumat kamera semasa setiap lelaran, dengan itu mewujudkan hubungan yang teguh antara model teks-ke-3D dan parameter kamera.
Kedua, model resapan teks-ke-2D pra-terlatih memperuntukkan perhatian kepada penjanaan latar depan dan latar belakang, manakala penciptaan aset 3D memerlukan lebih perhatian kepada penjanaan objek latar depan yang tepat. Untuk menangani isu ini, makalah itu mencadangkan kehilangan AMA, yang menggunakan topeng binari objek 3D untuk membimbing peta perhatian model penyebaran terlatih untuk mengutamakan penciptaan objek latar depan. Dengan menggabungkan modul ini, X-Dreamer mengutamakan penjanaan objek latar depan, dengan ketara meningkatkan kualiti keseluruhan kandungan 3D yang dijana.

Laman utama projek:
https://xmu-xiaoma666.github.io/Projects/X-Dreamer/
halaman utama Githubia /X-Dreamer
PerbincanganArtikelAlamat: https://arxiv.org/abs/2312.00085
X-Dreamer telah membuat sumbangan teks-ke-3 bidang berikut:
- Makalah ini mencadangkan pendekatan baru, X-Dreamer, untuk penciptaan kandungan teks-ke-3D yang berkualiti tinggi, dengan berkesan merapatkan jurang utama antara penjanaan teks-ke-2D dan teks-ke-3D .
- Untuk meningkatkan penjajaran antara hasil yang dijana dan perspektif kamera, kertas kerja mencadangkan CG-LoRA, yang menggunakan maklumat kamera untuk menjana parameter khusus model resapan 2D secara dinamik.
-
Untuk mengutamakan penciptaan objek latar depan dalam model teks-ke-3D, makalah ini memperkenalkan kehilangan AMA, yang menggunakan topeng binari objek 3D latar depan untuk membimbing peta perhatian model penyebaran 2D.
Kaedah
X-Dreamer mengandungi dua peringkat utama: pembelajaran geometri dan pembelajaran rupa. Untuk pembelajaran geometri, kajian ini menggunakan DMTET sebagai perwakilan 3D dan menggunakan ellipsoid 3D untuk memulakannya. Apabila dimulakan, fungsi kerugian menggunakan kerugian ralat kuasa dua (MSE). Seterusnya, DMTET dan CG-LoRA dioptimumkan menggunakan kehilangan Pensampelan Penyulingan Pecahan (SDS) dan kehilangan AMA yang dicadangkan dalam kajian ini untuk memastikan penjajaran antara perwakilan 3D dan isyarat teks input
Untuk pembelajaran penampilan, kertas kerja menggunakan dua arah. Pemodelan fungsi pengedaran pantulan (BRDF). Secara khusus, kertas itu menggunakan MLP dengan parameter yang boleh dilatih untuk meramalkan bahan permukaan. Sama seperti peringkat pembelajaran geometri, kertas ini menggunakan kehilangan SDS dan kehilangan AMA untuk mengoptimumkan parameter boleh dilatih MLP dan CG-LoRA untuk mencapai penjajaran antara perwakilan 3D dan isyarat teks. Rajah 2 menunjukkan komposisi terperinci X-Dreamer.

Rajah 2 Gambaran Keseluruhan X-Dreamer, termasuk pembelajaran geometri dan pembelajaran rupa.
Pembelajaran Geometri(Pembelajaran Geometri)
Dalam modul ini, X-Dreamer menggunakan rangkaian MLP untuk membuat parameter DMTET menjadi 3DMTET. Untuk meningkatkan kestabilan pemodelan geometri, artikel ini menggunakan ellipsoid 3D sebagai konfigurasi awal DMTET
untuk membuat parameter DMTET menjadi 3DMTET. Untuk meningkatkan kestabilan pemodelan geometri, artikel ini menggunakan ellipsoid 3D sebagai konfigurasi awal DMTET  . Untuk setiap bucu
. Untuk setiap bucu 
 kepunyaan jejaring tetrahedral , kami melatih
kepunyaan jejaring tetrahedral , kami melatih  untuk meramalkan dua kuantiti penting: nilai SDF
untuk meramalkan dua kuantiti penting: nilai SDF  dan ubah bentuk mengimbangi
dan ubah bentuk mengimbangi  . Untuk memulakan
. Untuk memulakan  sebagai ellipsoid, artikel ini mengambil sampel N titik yang diagihkan sama rata dalam ellipsoid dan mengira nilai SDF yang sepadan
sebagai ellipsoid, artikel ini mengambil sampel N titik yang diagihkan sama rata dalam ellipsoid dan mengira nilai SDF yang sepadan  . Selepas itu, kehilangan min kuasa dua ralat (MSE) digunakan untuk mengoptimumkan
. Selepas itu, kehilangan min kuasa dua ralat (MSE) digunakan untuk mengoptimumkan  . Proses pengoptimuman ini memastikan bahawa DMTET dimulakan dengan berkesan untuk menyerupai ellipsoid 3D. Formula untuk kehilangan MSE adalah seperti berikut:
. Proses pengoptimuman ini memastikan bahawa DMTET dimulakan dengan berkesan untuk menyerupai ellipsoid 3D. Formula untuk kehilangan MSE adalah seperti berikut: 

Selepas memulakan geometri, selaraskan geometri DMTET dengan gesaan teks input. Ini dilakukan dengan menggunakan teknik pemaparan pembezaan untuk menjana peta biasa n dan topeng m objek daripada DMTET yang dimulakan diberi pose kamera sampel rawak c. Selepas itu, peta biasa n dimasukkan ke dalam model Resapan Stabil (SD) beku dengan pembenaman CG-LoRA yang boleh dilatih, dan parameter dalam
diberi pose kamera sampel rawak c. Selepas itu, peta biasa n dimasukkan ke dalam model Resapan Stabil (SD) beku dengan pembenaman CG-LoRA yang boleh dilatih, dan parameter dalam  dikemas kini menggunakan kehilangan SDS, ditakrifkan seperti berikut:
dikemas kini menggunakan kehilangan SDS, ditakrifkan seperti berikut:

di mana,  mewakili parameter SD dan
mewakili parameter SD dan  ialah ramalan hingar SD di bawah tahap hingar tertentu t dan pembenaman teks y. Tambahan pula,
ialah ramalan hingar SD di bawah tahap hingar tertentu t dan pembenaman teks y. Tambahan pula,  , dengan
, dengan 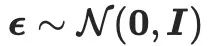 mewakili bunyi yang diambil sampel daripada taburan normal. Pelaksanaan
mewakili bunyi yang diambil sampel daripada taburan normal. Pelaksanaan  ,
,  dan
dan  adalah berdasarkan DreamFusion [4].
adalah berdasarkan DreamFusion [4].
Tambahan pula, untuk memfokuskan SD pada penjanaan objek latar depan, X-Dreamer memperkenalkan kehilangan AMA tambahan untuk menyelaraskan topeng objek dengan peta perhatian SD seperti berikut:




mewakili bilangan lapisan perhatian, ialah peta perhatian lapisan perhatian ke-i. Fungsi
🎜🎜 digunakan untuk melaraskan saiz topeng objek 3D yang diberikan untuk memastikan saiznya sejajar dengan saiz peta perhatian. 🎜🎜🎜🎜🎜Pembelajaran Penampilan🎜(🎜Pembelajaran Penampilan🎜)🎜🎜Selepas memperoleh geometri objek 3D, matlamat artikel ini adalah untuk mengira rupa objek 3D menggunakan model bahan Rendering Berasaskan Fizikal (PBR). Model material termasuk istilah resapan  , istilah kekasaran dan metalliciti
, istilah kekasaran dan metalliciti  , dan istilah perubahan biasa
, dan istilah perubahan biasa  . Untuk sebarang titik
. Untuk sebarang titik 
pada permukaan geometri, multilayer perceptron (MLP) yang diparameterkan oleh  digunakan untuk mendapatkan tiga sebutan material, yang boleh dinyatakan seperti berikut:
digunakan untuk mendapatkan tiga sebutan material, yang boleh dinyatakan seperti berikut:

di mana,  Mewakili pengekodan kedudukan menggunakan teknologi grid cincang. Selepas itu, setiap piksel imej yang diberikan boleh dikira menggunakan formula berikut:
Mewakili pengekodan kedudukan menggunakan teknologi grid cincang. Selepas itu, setiap piksel imej yang diberikan boleh dikira menggunakan formula berikut:

Antaranya, 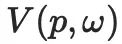 mewakili nilai piksel titik pada permukaan objek 3D yang diberikan dari arah
mewakili nilai piksel titik pada permukaan objek 3D yang diberikan dari arah 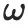
 .
.  mewakili hemisfera yang ditakrifkan oleh set arah kejadian yang memenuhi syarat
mewakili hemisfera yang ditakrifkan oleh set arah kejadian yang memenuhi syarat 
 , di mana
, di mana  mewakili arah kejadian dan
mewakili arah kejadian dan 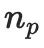 mewakili permukaan normal pada titik
mewakili permukaan normal pada titik  .
.  sepadan dengan cahaya kejadian dari peta persekitaran yang sudah siap dan
sepadan dengan cahaya kejadian dari peta persekitaran yang sudah siap dan  ialah Fungsi Pengedaran Pantulan Dwi Arah (BRDF) yang berkaitan dengan sifat bahan (iaitu
ialah Fungsi Pengedaran Pantulan Dwi Arah (BRDF) yang berkaitan dengan sifat bahan (iaitu  ). Dengan mengagregatkan semua warna piksel yang diberikan, imej yang diberikan
). Dengan mengagregatkan semua warna piksel yang diberikan, imej yang diberikan  diperoleh. Sama seperti peringkat pembelajaran geometri, imej yang dihasilkan
diperoleh. Sama seperti peringkat pembelajaran geometri, imej yang dihasilkan  dimasukkan ke dalam SD dan dioptimumkan
dimasukkan ke dalam SD dan dioptimumkan  menggunakan kehilangan SDS dan kehilangan AMA.
menggunakan kehilangan SDS dan kehilangan AMA.
Camera-Guided Low-Rank Adaptation (CG-LoRA)
Untuk menyelesaikan masalah penjanaan hasil 3D sub-optimum yang disebabkan oleh jurang domain 2, D dan penjanaan teks 3 - Dreamer mencadangkan kaedah penyesuaian peringkat rendah berdasarkan panduan kamera
Seperti yang ditunjukkan dalam Rajah 3, parameter kamera dan teks peka arah digunakan untuk membimbing penjanaan parameter dalam CG-LoRA, supaya X-Dreamer boleh berkesan melihat kedudukan kamera dan maklumat arah.
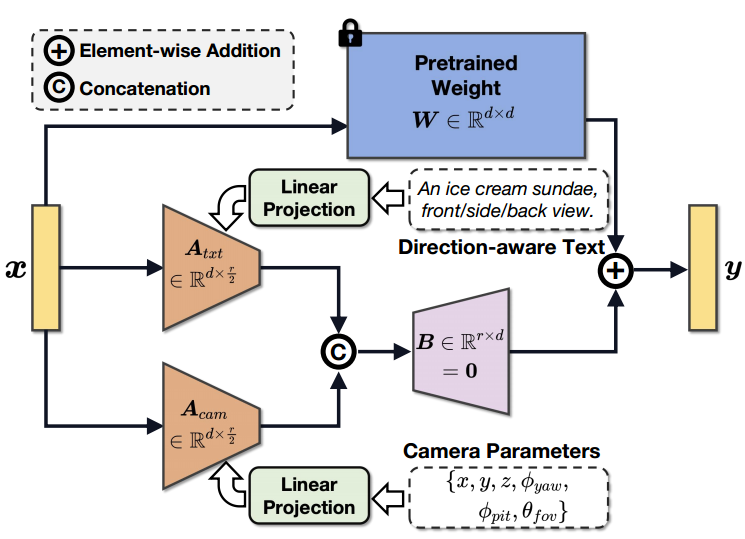
Rajah 3 Ilustrasi CG-LoRA berpandukan kamera.
Secara khusus, diberikan gesaan teks  dan parameter kamera
dan parameter kamera  , mula-mula gunakan pengekod CLIP teks pra-latihan
, mula-mula gunakan pengekod CLIP teks pra-latihan  dan MLP yang boleh dilatih
dan MLP yang boleh dilatih  untuk menayangkan input ini ke dalam ruang ciri:
untuk menayangkan input ini ke dalam ruang ciri:

dan  masing-masing ialah ciri teks dan kamera. Selepas itu, dua matriks peringkat rendah digunakan untuk projek
masing-masing ialah ciri teks dan kamera. Selepas itu, dua matriks peringkat rendah digunakan untuk projek 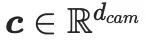 dan
dan  ke dalam matriks pengurangan dimensi yang boleh dilatih di CG-LORA:
ke dalam matriks pengurangan dimensi yang boleh dilatih di CG-LORA: 

dan  adalah CG-LORA daripada matriks pengurangan dua dimensi. Fungsi
adalah CG-LORA daripada matriks pengurangan dua dimensi. Fungsi 

kepada . 

 dan
dan  ialah dua matriks peringkat rendah. Oleh itu, ia boleh diuraikan menjadi hasil darab dua matriks untuk mengurangkan parameter yang boleh dilatih dalam pelaksanaan, iaitu
ialah dua matriks peringkat rendah. Oleh itu, ia boleh diuraikan menjadi hasil darab dua matriks untuk mengurangkan parameter yang boleh dilatih dalam pelaksanaan, iaitu  ;
;  ialah nombor kecil (cth: 4). Mengikut komposisi LoRA, matriks pengembangan dimensi
ialah nombor kecil (cth: 4). Mengikut komposisi LoRA, matriks pengembangan dimensi  dimulakan kepada sifar untuk memastikan model memulakan latihan dengan parameter pra-latihan SD. Oleh itu, formula proses suapan CG-LoRA adalah seperti berikut:
dimulakan kepada sifar untuk memastikan model memulakan latihan dengan parameter pra-latihan SD. Oleh itu, formula proses suapan CG-LoRA adalah seperti berikut: 
 di mana, mewakili parameter beku model SD pra-latihan, dan
di mana, mewakili parameter beku model SD pra-latihan, dan 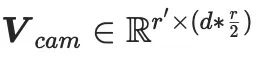 ialah operasi lata. Dalam pelaksanaan kaedah ini, CG-LoRA disepadukan ke dalam lapisan pembenaman linear modul perhatian dalam SD untuk menangkap maklumat orientasi dan kamera dengan berkesan.
ialah operasi lata. Dalam pelaksanaan kaedah ini, CG-LoRA disepadukan ke dalam lapisan pembenaman linear modul perhatian dalam SD untuk menangkap maklumat orientasi dan kamera dengan berkesan. 
 Apa yang perlu dinyatakan semula ialah: Kehilangan Penjajaran Topeng Perhatian (Kehilangan AMA)
Apa yang perlu dinyatakan semula ialah: Kehilangan Penjajaran Topeng Perhatian (Kehilangan AMA)

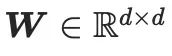 dan ciri label CLS utama
dan ciri label CLS utama  untuk mengira peta perhatian. Formula pengiraan adalah seperti berikut:
untuk mengira peta perhatian. Formula pengiraan adalah seperti berikut:
Antaranya,
Mulakan dari ellipsoid untuk menjana teks-ke-3D Kertas menunjukkan hasil penjanaan teks-ke-3D X-Dreamer menggunakan bentuk elips, seperti yang ditunjukkan dalam bentuk geometri awal Rajah 4 ditunjukkan. Hasilnya menunjukkan keupayaan X-Dreamer untuk menjana objek 3D yang berkualiti tinggi dan fotorealistik yang sepadan dengan tepat dengan gesaan teks input.
Bermula dari grid berbutir kasar untuk penjanaan teks-ke-3D Walaupun Sebilangan besar jejaring berbutir kasar boleh dimuat turun dari Internet, tetapi menggunakan jejaring ini secara langsung untuk mencipta kandungan 3D selalunya mengakibatkan prestasi yang lemah kerana kekurangan perincian geometri. Walau bagaimanapun, jerat ini boleh memberikan X-Dreamer dengan maklumat terdahulu bentuk 3D yang lebih baik daripada ellipsoid 3D. Oleh itu, anda juga boleh menggunakan grid panduan berbutir kasar untuk memulakan DMTET dan bukannya menggunakan ellipsoid. Seperti yang ditunjukkan dalam Rajah 5, X-Dreamer boleh menjana aset 3D dengan perincian geometri yang tepat berdasarkan teks yang diberikan, walaupun mesh berbutir kasar yang disediakan tidak mempunyai butiran. Rajah 5 Penjanaan Teks-ke-3D bermula daripada jaringan berbutir kasar. Apa yang perlu ditulis semula ialah: Perbandingan Kualitatif. Untuk menilai keberkesanan X-Dreamer, kertas kerja ini membandingkannya dengan empat kaedah lanjutan: DreamFusion [4], Magic3D [8] , Fantasia3D 7] dan ProlificDreamer [11], seperti yang ditunjukkan dalam Rajah 6 Jika dibandingkan dengan kaedah berasaskan SDS [4, 7, 8], X-Dreamer mengatasinya dalam menjana aset 3D yang berkualiti tinggi dan realistik. Tambahan pula, X-Dreamer menghasilkan kandungan 3D dengan kesan visual yang setanding atau lebih baik berbanding kaedah berasaskan VSD [11] sambil memerlukan masa pengoptimuman yang kurang ketara. Secara khusus, proses pembelajaran geometri dan penampilan hanya mengambil masa kira-kira 27 minit untuk X-Dreamer, berbanding lebih daripada 8 jam untuk ProlificDreamer. Rajah 6 Perbandingan dengan kaedah terkini (SOTA). Kandungan yang perlu ditulis semula ialah: Eksperimen ablasi yang dijalankan untuk memahami dengan mendalam tentang kehilangan CG, ketepatan dan ketetapan CG. kajian ablasi, di mana setiap Modul ditambah secara individu untuk menilai kesannya. Seperti yang ditunjukkan dalam Rajah 7, keputusan ablasi menunjukkan bahawa apabila CG-LoRA dikecualikan daripada X-Dreamer, kualiti geometri dan rupa objek 3D yang dijana menurun dengan ketara. Selain itu, kehilangan AMA X-Dreamer juga mempunyai kesan buruk pada geometri dan kesetiaan penampilan aset 3D yang dijana. Ini perlu ditulis semula: Eksperimen ablasi menyediakan penyiasatan berharga ke atas sumbangan individu kerugian CG-LoRA dan AMA dalam meningkatkan geometri, rupa dan kualiti keseluruhan objek 3D yang dijana. Rajah 7 Kajian Ablasi X-Dreamer. Tujuan memperkenalkan kehilangan AMA adalah untuk memfokuskan perhatian pada objek latar depan semasa proses denoising. Ini dicapai dengan menjajarkan peta perhatian SD dengan topeng pemaparan objek 3D. Untuk menilai keberkesanan kehilangan AMA dalam mencapai matlamat ini, kertas kerja ini membandingkan peta perhatian SD dengan dan tanpa kehilangan AMA dalam pembelajaran geometri dan peringkat pembelajaran rupa masing-masing Seperti yang ditunjukkan dalam Rajah 8, ia boleh diperhatikan. bahawa menambah AMA Kehilangan bukan sahaja menambah baik geometri dan penampilan aset 3D yang dijana, ia juga membolehkan SD menumpukan perhatiannya secara khusus pada kawasan objek latar depan. Hasil visualisasi mengesahkan keberkesanan kehilangan AMA dalam membimbing perhatian SD, dengan itu meningkatkan kualiti geometri dan peringkat pembelajaran rupa dan pemfokusan objek latar depan Apa yang perlu ditulis semula ialah: Rajah 8 menunjukkan perhatian Hasil visualisasi plot daya, render mask dan imej yang diberikan dengan dan tanpa kehilangan AMA Penyelidikan ini memperkenalkan rangka kerja terobosan yang dipanggil X-Dreamer, yang bertujuan untuk menyelesaikan jurang teks-ke-2D dan teks-ke-Domain antara 3D penjanaan untuk meningkatkan penjanaan teks-ke-3D. Untuk mencapai matlamat ini, kertas kerja pertama kali mencadangkan CG-LoRA, sebuah modul yang menggabungkan maklumat tiga dimensi yang berkaitan (termasuk teks dan parameter kamera yang mengetahui arah) ke dalam model Resapan Stabil (SD) yang telah terlatih. Dengan berbuat demikian, makalah ini dapat menangkap maklumat yang berkaitan dengan domain tiga dimensi dengan berkesan. Tambahan pula, kertas kerja ini mereka bentuk kehilangan AMA untuk menyelaraskan peta perhatian yang dijana SD dengan topeng pemaparan objek 3D. Matlamat utama kehilangan AMA adalah untuk membimbing fokus teks kepada model 3D ke arah penjanaan objek latar depan. Melalui eksperimen yang meluas, kertas kerja ini menilai secara menyeluruh keberkesanan kaedah yang dicadangkan dan menunjukkan bahawa X-Dreamer mampu menjana kandungan 3D yang berkualiti tinggi dan realistik berdasarkan gesaan teks yang diberikan 🎜🎜 mewakili bilangan kepala dalam mekanisme perhatian berbilang kepala,
mewakili bilangan kepala dalam mekanisme perhatian berbilang kepala,  mewakili peta perhatian, dan kemudian peta perhatian keseluruhan dikira dengan purata nilai perhatian peta perhatian
mewakili peta perhatian, dan kemudian peta perhatian keseluruhan dikira dengan purata nilai perhatian peta perhatian  dalam semua kepala perhatian.
dalam semua kepala perhatian.  Memandangkan fungsi softmax digunakan untuk menormalkan nilai peta perhatian, nilai pengaktifan dalam peta perhatian mungkin menjadi sangat kecil apabila resolusi ciri imej adalah tinggi. Walau bagaimanapun, menjajarkan terus peta perhatian dengan topeng objek 3D yang diberikan adalah tidak optimum, memandangkan setiap elemen dalam topeng objek 3D yang diberikan ialah nilai binari 0 atau 1. Untuk menyelesaikan masalah ini, kertas kerja mencadangkan teknik normalisasi yang memetakan nilai dalam peta perhatian kepada antara (0, 1). Formula untuk proses normalisasi ini adalah seperti berikut:
Memandangkan fungsi softmax digunakan untuk menormalkan nilai peta perhatian, nilai pengaktifan dalam peta perhatian mungkin menjadi sangat kecil apabila resolusi ciri imej adalah tinggi. Walau bagaimanapun, menjajarkan terus peta perhatian dengan topeng objek 3D yang diberikan adalah tidak optimum, memandangkan setiap elemen dalam topeng objek 3D yang diberikan ialah nilai binari 0 atau 1. Untuk menyelesaikan masalah ini, kertas kerja mencadangkan teknik normalisasi yang memetakan nilai dalam peta perhatian kepada antara (0, 1). Formula untuk proses normalisasi ini adalah seperti berikut:  di mana
di mana  ) untuk mengelakkan 0 daripada muncul dalam penyebut. Akhir sekali, kehilangan AMA digunakan untuk menyelaraskan peta perhatian semua lapisan perhatian kepada topeng yang diberikan objek 3D.
) untuk mengelakkan 0 daripada muncul dalam penyebut. Akhir sekali, kehilangan AMA digunakan untuk menyelaraskan peta perhatian semua lapisan perhatian kepada topeng yang diberikan objek 3D.  Hasil eksperimen
Hasil eksperimen
Kertas ini menggunakan empat GPU Nvidia RTX 3090 dan perpustakaan PyTorch untuk menjalankan eksperimen. Untuk mengira kehilangan SDS, model Stable Diffusion yang dilaksanakan melalui Hugging Face Diffusers telah digunakan. Untuk pengekod DMTET dan bahan, ia dilaksanakan sebagai MLP dua lapisan dan MLP satu lapisan masing-masing, dengan dimensi lapisan tersembunyi 32.
 Rajah 4 Menggunakan ellipsoid sebagai titik permulaan untuk penjanaan teks-ke-3D
Rajah 4 Menggunakan ellipsoid sebagai titik permulaan untuk penjanaan teks-ke-3D



Atas ialah kandungan terperinci Menerobos dinding dimensi, X-Dreamer membawa teks berkualiti tinggi kepada penjanaan 3D, menyepadukan bidang penjanaan 2D dan 3D.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!