
Rumah >Peranti teknologi >AI >SSM popular Mamba menarik perhatian Apple dan Cornell: tinggalkan model gangguan
SSM popular Mamba menarik perhatian Apple dan Cornell: tinggalkan model gangguan

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-12-15 08:41:04794semak imbas
Penyelidikan terkini dari Cornell University dan Apple menyimpulkan bahawa untuk menjana imej resolusi tinggi dengan kuasa pengkomputeran yang kurang, mekanisme perhatian boleh dihapuskan
Seperti yang kita sedia maklum, mekanisme perhatian adalah teras kepada seni bina Transformer Komponen adalah penting untuk penjanaan teks dan imej berkualiti tinggi. Tetapi kelemahannya juga jelas, iaitu, kerumitan pengiraan akan meningkat secara kuadratik apabila panjang jujukan meningkat. Ini adalah masalah yang menjengkelkan dalam teks panjang dan pemprosesan imej resolusi tinggi.
Untuk menyelesaikan masalah ini, penyelidikan baharu ini menggantikan mekanisme perhatian dalam seni bina tradisional dengan tulang belakang model angkasa keadaan (SSM) yang lebih berskala dan membangunkan model yang dipanggil Diffusion State Space Model (DIFFUSSM) ) seni bina baharu. Seni bina baharu ini boleh menggunakan kurang kuasa pengkomputeran untuk memadankan atau melebihi kesan penjanaan imej model resapan sedia ada dengan modul perhatian dan menjana imej resolusi tinggi dengan cemerlang.

Terima kasih kepada keluaran “Mamba” minggu lepas, model angkasa lepas negeri SSM semakin mendapat perhatian. Teras Mamba ialah pengenalan seni bina baharu - "model ruang keadaan terpilih", yang menjadikan Mamba setanding atau bahkan mengalahkan Transformer dalam pemodelan bahasa. Pada masa itu, pengarang kertas Albert Gu berkata bahawa kejayaan Mamba memberinya keyakinan terhadap masa depan SSM. Kini, kertas kerja dari Universiti Cornell dan Apple ini nampaknya telah menambah contoh baharu prospek permohonan SSM.
Shital Shah, jurutera penyelidik utama di Microsoft, memberi amaran bahawa mekanisme perhatian mungkin ditarik dari takhta yang telah didudukinya sejak sekian lama.
Gambaran Keseluruhan Kertas
Kemajuan pesat dalam bidang penjanaan imej telah didorong oleh penolakan model probabilistik penyebaran (DDPM). Model sebegini memodelkan proses penjanaan sebagai denoising berulang bagi pembolehubah pendam, dan apabila langkah denoising yang mencukupi dilakukan, mereka dapat menghasilkan sampel kesetiaan tinggi. Keupayaan DDPM untuk menangkap pengedaran visual yang kompleks menjadikan mereka berpotensi berfaedah dalam memacu gubahan fotorealistik resolusi tinggi.
Cabaran pengiraan yang ketara kekal dalam menskalakan DDPM kepada peleraian yang lebih tinggi. Halangan utama ialah pergantungan pada perhatian diri apabila mencapai penjanaan kesetiaan tinggi. Dalam seni bina U-Nets, kesesakan ini datang daripada menggabungkan ResNet dengan lapisan perhatian. DDPM melangkaui rangkaian permusuhan generatif (GAN) tetapi memerlukan lapisan perhatian berbilang kepala. Dalam seni bina Transformer, perhatian adalah komponen utama dan oleh itu penting untuk mencapai hasil sintesis imej yang terkini. Dalam kedua-dua seni bina, kerumitan perhatian berskala kuadratik dengan panjang jujukan, jadi menjadi tidak dapat dilaksanakan apabila memproses imej resolusi tinggi.
Kos pengiraan telah mendorong penyelidik terdahulu untuk menggunakan kaedah mampatan perwakilan. Seni bina resolusi tinggi sering menggunakan peleraian tampalan atau berskala. Penyekatan boleh mencipta perwakilan berbutir kasar dan mengurangkan kos pengiraan, tetapi dengan mengorbankan maklumat spatial frekuensi tinggi kritikal dan integriti struktur. Resolusi berbilang skala, sambil mengurangkan pengiraan lapisan perhatian, juga mengurangkan perincian spatial melalui pensampelan rendah dan memperkenalkan artifak apabila pensampelan naik digunakan.
DIFFUSSM ialah model ruang keadaan resapan yang tidak menggunakan mekanisme perhatian dan direka bentuk untuk menyelesaikan masalah yang dihadapi apabila menggunakan mekanisme perhatian dalam sintesis imej resolusi tinggi. DIFFUSSM menggunakan model ruang keadaan berpagar (SSM) dalam proses resapan. Kajian terdahulu telah menunjukkan bahawa model jujukan berasaskan SSM adalah model jujukan saraf am yang berkesan dan cekap. Dengan mengguna pakai seni bina ini, teras SSM boleh didayakan untuk mengendalikan perwakilan imej yang lebih halus, menghapuskan jubin global atau lapisan berbilang skala. Untuk meningkatkan lagi kecekapan, DIFFUSSM menggunakan seni bina jam pasir dalam komponen padat rangkaian
Pengarang mengesahkan prestasi DIFFUSSM pada resolusi berbeza. Eksperimen pada ImageNet menunjukkan bahawa DIFFUSSM mencapai peningkatan yang konsisten dalam FID, sFID dan Skor Permulaan pada pelbagai resolusi dengan jumlah Gflop yang lebih sedikit.

Pautan kertas: https://arxiv.org/pdf/2311.18257.pdf
Rangka Kerja DIFFUSSM
Untuk tidak menukar makna asal, kandungan perlu ditulis semula dalam bahasa Cina. Matlamat penulis adalah untuk mereka bentuk seni bina penyebaran yang mampu mempelajari interaksi jarak jauh pada resolusi tinggi tanpa memerlukan "pengurangan panjang" seperti menyekat. Sama seperti DiT, pendekatan ini berfungsi dengan meratakan imej dan menganggapnya sebagai masalah pemodelan jujukan. Walau bagaimanapun, tidak seperti Transformer, kaedah ini menggunakan pengiraan sub-kuadrat apabila memproses panjang jujukan ini DIFFUSSM ialah komponen teras SSM dwiarah berpagar yang dioptimumkan untuk memproses jujukan panjang. Untuk meningkatkan kecekapan, penulis memperkenalkan seni bina jam pasir dalam lapisan MLP. Reka bentuk ini secara bergilir-gilir mengembang dan mengecutkan panjang jujukan di sekitar SSM dua arah sambil secara terpilih mengurangkan panjang jujukan dalam MLP. Seni bina model lengkap ditunjukkan dalam Rajah 2
Secara khusus, setiap lapisan jam pasir menerima urutan input yang dipendekkan dan diratakan I ∈ R^(J×D), di mana M = L/J ialah Nisbah pengurangan dan pembesaran. Pada masa yang sama, keseluruhan blok, termasuk SSM dua arah, dikira pada panjang asal, mengambil kesempatan sepenuhnya daripada konteks global. σ digunakan dalam artikel ini untuk mewakili fungsi pengaktifan. Untuk l ∈ {1 , dengan j = ⌊l/M⌋, m = l mod M, D_m = 2D/M, persamaan pengiraan adalah seperti berikut: 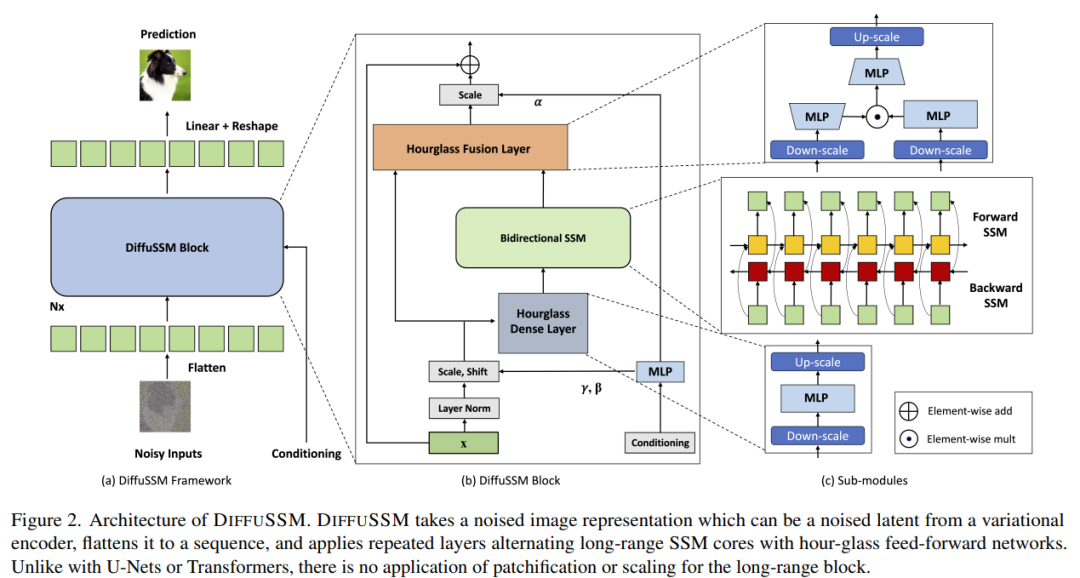
lapisan Sepadukan blok SSM berpagar menggunakan sambungan langkau. Penulis menyepadukan gabungan label kelas y ∈ R^(L×1) dan langkah masa t ∈ R^(L×1) di setiap lokasi, seperti yang ditunjukkan dalam Rajah 2. 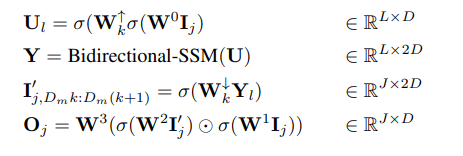
Parameter: Bilangan parameter dalam blok DIFFUSSM ditentukan terutamanya oleh transformasi linear W, yang mengandungi parameter 9D^2 + 2MD^2. Apabila M = 2, ini menghasilkan parameter 13D^2. Blok transformasi DiT mempunyai parameter 12D^2 dalam lapisan transformasi terasnya, bagaimanapun, seni bina DiT mempunyai lebih banyak parameter dalam komponen lapisan lain (penormalan lapisan penyesuaian). Para penyelidik memadankan parameter dalam eksperimen mereka dengan menggunakan lapisan DIFFUSSM tambahan.
FLOP: Rajah 3 membandingkan Gflop antara DiT dan DIFFUSSM. Jumlah Flop bagi lapisan DIFFUSSM ialah
, dengan α mewakili pemalar yang dilaksanakan oleh FFT. Ini menghasilkan kira-kira 7.5LD^2 Gflops apabila M = 2 dan lapisan linear mendominasi pengiraan. Sebagai perbandingan, jika perhatian kendiri penuh digunakan dan bukannya SSM dalam seni bina jam pasir ini, terdapat tambahan 2DL^2 Flops. 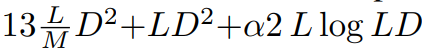
Pertimbangkan dua senario percubaan: 1) D ≈ L = 1024, yang akan menghasilkan tambahan 2LD^2 Flop, 2) 4D ≈ L = 4096, yang akan menyebabkan kos Flop dan^2 meningkat dengan ketara . Memandangkan kos teras SSM dua hala adalah kecil berbanding kos menggunakan perhatian, menggunakan seni bina jam pasir tidak berfungsi untuk model berasaskan perhatian. Seperti yang dibincangkan sebelum ini, DiT mengelakkan masalah ini dengan menggunakan chunking dengan mengorbankan perwakilan termampat. 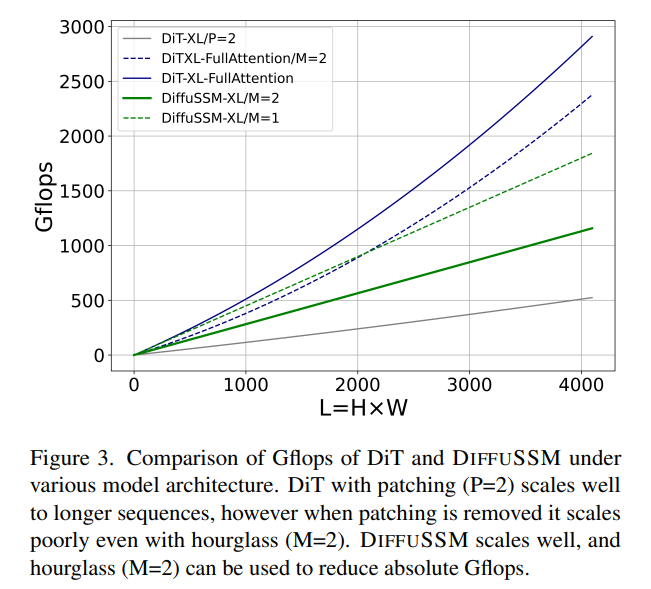
Hasil eksperimen
Menjana imej bersyarat kategori
Jadual berikut ialah hasil perbandingan DIFFUSSM dengan semua model penjanaan keadaan kategori terkini
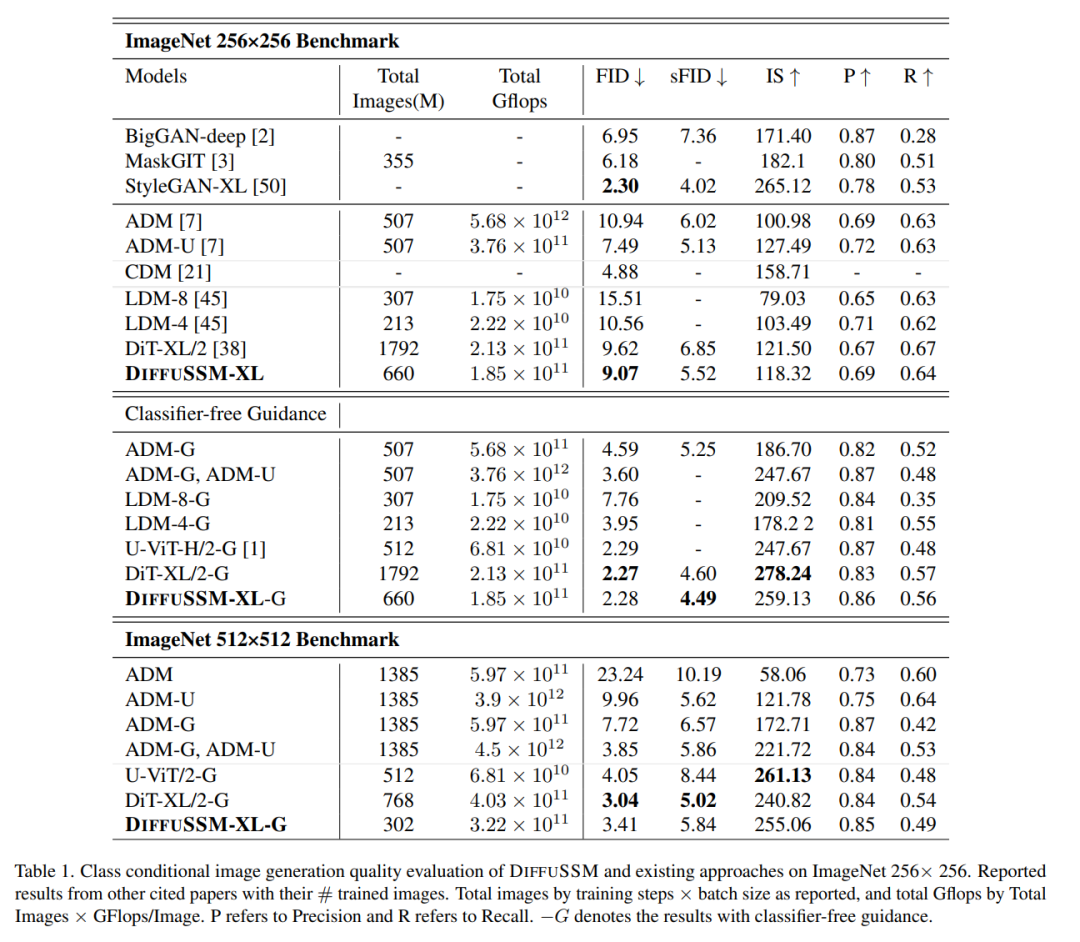
Skor FID DIFFUSSM mengatasi semua model apabila menggunakan panduan tanpa pengelas dan mengekalkan jurang yang agak kecil (0.01) jika dibandingkan dengan DiT. Ambil perhatian bahawa DIFFUSSM, dilatih dengan pengurangan 30% dalam jumlah Gflops, sudah pun mengatasi prestasi DiT tanpa menggunakan panduan tanpa pengelas. U-ViT ialah satu lagi seni bina berasaskan Transformer, tetapi menggunakan seni bina berasaskan UNet dengan sambungan lompat jauh antara blok. U-ViT menggunakan lebih sedikit FLOP dan berprestasi lebih baik pada resolusi 256×256, tetapi ini tidak berlaku dalam set data 512×512. Penulis terutamanya membandingkan dengan DiT Demi keadilan, sambungan long-hop ini tidak diterima pakai. Pengarang selanjutnya menjalankan perbandingan pada penanda aras resolusi lebih tinggi menggunakan panduan tanpa pengelas. Keputusan DIFFUSSM agak kukuh dan hampir dengan model resolusi tinggi yang canggih, hanya lebih rendah daripada DiT pada sFID dan mencapai skor FID yang setanding. DIFFUSSM telah dilatih pada 302 juta imej, memerhati 40% daripada imej dan menggunakan 25% kurang Gflops daripada DiT Penjanaan imej tanpa syarat Berdasarkan anggaran penjanaan imej tanpa syarat oleh pengarang perbandingan ditunjukkan dalam Jadual 2. Penyelidikan penulis mendapati bahawa di bawah bajet latihan yang setanding dengan LDM, DIFFUSSM mencapai skor FID yang setanding (perbezaan -0.08 dan 0.07). Keputusan ini menyerlahkan kebolehgunaan DIFFUSSM merentas penanda aras yang berbeza dan tugas yang berbeza. Sama seperti LDM, kaedah ini tidak mengatasi prestasi ADM pada tugas LSUN-Bilik Tidur kerana ia hanya menggunakan 25% daripada jumlah belanjawan latihan ADM. Untuk tugasan ini, model GAN terbaik mengatasi model resapan dalam kategori model Sila rujuk kertas asal untuk butiran lanjut 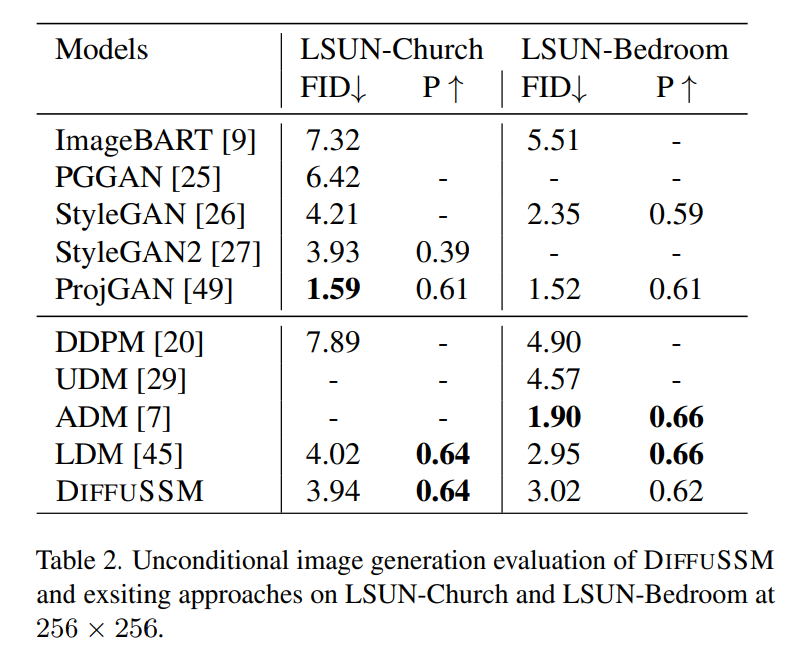
Atas ialah kandungan terperinci SSM popular Mamba menarik perhatian Apple dan Cornell: tinggalkan model gangguan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!