
Rumah >Peranti teknologi >AI >Sebarkan semuanya? 3DifFusionDet: Model resapan memasuki pengesanan sasaran 3D gabungan LV!
Sebarkan semuanya? 3DifFusionDet: Model resapan memasuki pengesanan sasaran 3D gabungan LV!

- 王林ke hadapan
- 2023-12-14 16:51:58745semak imbas
Pemahaman peribadi pengarang
Dalam beberapa tahun kebelakangan ini, model resapan telah sangat berjaya dalam tugas penjanaan, dan secara semula jadi telah diperluaskan kepada tugas pengesanan sasaran sebagai peralihan dari kotak hingar ke kotak objek ) yang menghilangkan resapan proses. Semasa fasa latihan, kotak sasaran disebarkan daripada kotak kebenaran tanah kepada pengedaran rawak, dan model mempelajari cara untuk membalikkan proses menambahkan bunyi pada kotak kebenaran tanah ini. Semasa fasa inferens, model memperhalusi set kotak sasaran yang dijana secara rawak ke dalam hasil output secara progresif. Berbanding dengan kaedah pengesanan objek tradisional, yang bergantung pada set pertanyaan yang boleh dipelajari yang tetap, 3DifFusionDet tidak memerlukan pertanyaan yang boleh dipelajari untuk pengesanan objek.
Idea utama 3DifFusionDet
Rangka kerja 3DifFusionDet mewakili pengesanan sasaran 3D sebagai proses penyebaran bunyi daripada kotak 3D yang bising kepada kotak sasaran. Dalam rangka kerja ini, kotak kebenaran tanah dilatih dengan resapan pengedaran rawak dan model mempelajari proses hingar songsang. Semasa inferens, model secara beransur-ansur memperhalusi set kotak yang dijana secara rawak. Di bawah strategi penjajaran ciri, kaedah penghalusan progresif boleh memberi sumbangan penting kepada gabungan kamera lidar. Proses penghalusan berulang juga menunjukkan kebolehsuaian yang hebat dengan menggunakan rangka kerja pada pelbagai persekitaran pengesanan yang memerlukan tahap ketepatan dan kelajuan yang berbeza. KITTI ialah penanda aras untuk pengecaman sasaran trafik sebenar Sebilangan besar eksperimen telah dijalankan ke atas KITTI, yang menunjukkan bahawa berbanding dengan pengesan awal, KITTI boleh mencapai prestasi yang baik
Sumbangan utama 3DifFusionDet adalah seperti berikut:
- Perwakilan daripada Pengesanan sasaran 3D Untuk proses denoising generatif, 3DifFusionDet dicadangkan, yang merupakan penyelidikan pertama yang menggunakan model resapan pada pengesanan sasaran 3D.
- Kaji strategi penjajaran gabungan Kamera-LiDAR yang optimum di bawah rangka kerja proses denoising generatif, dan cadangkan 2 strategi penjajaran gabungan cawangan untuk menggunakan maklumat pelengkap yang disediakan oleh kedua-dua modaliti.
- Menjalankan eksperimen yang meluas pada penanda aras KITTI. Berbanding dengan kaedah sedia ada yang direka bentuk dengan baik, 3DifFusionDet mencapai hasil yang kompetitif, menunjukkan janji model resapan dalam tugas pengesanan objek 3D.
Menggunakan LiDAR-Camera Fusion untuk Pengesanan Objek 3D
Untuk pengesanan objek 3D, Kamera dan LiDAR ialah dua jenis penderia pelengkap. Penderia LiDAR memfokuskan pada penyetempatan 3D dan menyediakan maklumat yang kaya tentang struktur 3D, manakala Kamera menyediakan maklumat warna yang boleh diperolehi ciri semantik yang kaya. Banyak usaha telah dilakukan untuk mengesan objek 3D dengan tepat dengan menggabungkan data daripada kamera dan LiDAR. Kaedah terkini terutamanya berdasarkan pengesan objek 3D berasaskan LiDAR dan berusaha untuk memasukkan maklumat imej ke dalam pelbagai peringkat proses pengesanan LiDAR, kerana prestasi kaedah pengesanan berasaskan LiDAR jauh lebih baik daripada kamera- kaedah berasaskan. Disebabkan oleh kerumitan sistem pengesanan berasaskan lidar dan berasaskan kamera, penggabungan kedua-dua mod sudah pasti akan meningkatkan kos pengiraan dan kelewatan masa inferens. Oleh itu, masalah menggabungkan maklumat multimodal secara berkesan masih kekal.
Model resapan
Model resapan ialah model generatif yang menyahbina secara beransur-ansur data yang diperhatikan dengan memperkenalkan hingar dan memulihkan data asal dengan membalikkan proses. Model resapan dan padanan skor denoising disambungkan melalui model probabilistik resapan denoising (Ho, Jain, dan Abbeel 2020a), yang baru-baru ini telah mencetuskan minat dalam aplikasi penglihatan komputer. Ia telah digunakan dalam banyak bidang, seperti penjanaan graf, pemahaman bahasa, pembelajaran teguh dan pemodelan data temporal.
Model penyebaran telah mencapai kejayaan besar dalam penjanaan dan sintesis imej. Sesetengah kerja perintis menggunakan model resapan untuk tugasan pembahagian imej. Berbanding dengan medan ini, potensi mereka untuk pengesanan objek masih belum dieksploitasi sepenuhnya. Pendekatan sebelumnya untuk pengesanan objek menggunakan model penyebaran telah dihadkan kepada kotak sempadan 2D. Berbanding dengan pengesanan 2D, pengesanan 3D menyediakan maklumat ruang sasaran yang lebih kaya dan boleh mencapai persepsi kedalaman dan pemahaman volum yang tepat, yang penting untuk aplikasi seperti pemanduan autonomi, di mana ia adalah perlu untuk mengenal pasti jarak tepat kenderaan di sekeliling dan arah adalah aspek penting untuk aplikasi seperti pemanduan autonomi.
Reka bentuk rangkaian 3DifFusionDet
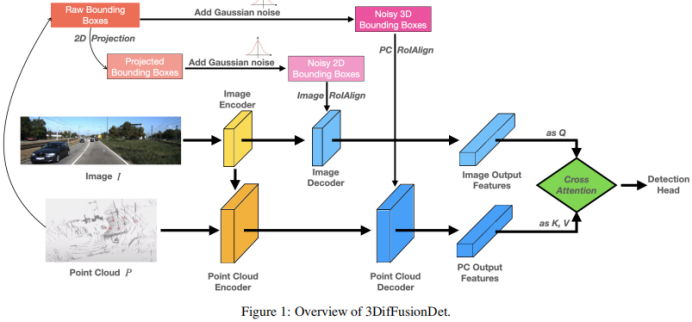
Rajah 1 menunjukkan seni bina keseluruhan 3DifFusionDet. Ia menerima input multimodal termasuk imej RGB dan awan titik. Membahagikan keseluruhan model kepada bahagian pengekstrakan ciri dan penyahkodan ciri, seperti halnya DiffusionDet, adalah sukar untuk menggunakan terus kepada ciri 3D asal dalam setiap langkah lelaran. Bahagian pengekstrakan ciri dijalankan sekali sahaja untuk mengekstrak perwakilan ciri dalam daripada input asal X, manakala komponen penyahkodan ciri dikondisikan pada ciri mendalam ini dan dilatih untuk melukis ramalan kotak secara progresif daripada kotak bising. Untuk menggunakan sepenuhnya maklumat pelengkap yang disediakan oleh kedua-dua modaliti, pengekod dan penyahkod bagi setiap modaliti diasingkan. Tambahan pula, penyahkod imej dan penyahkod awan titik dilatih secara berasingan untuk memperhalusi ciri 2D dan 3D menggunakan model resapan untuk menghasilkan kotak hingar dan masing-masing. Bagi sambungan kedua-dua cabang ciri ini, hanya menyambungkannya akan menyebabkan ricih maklumat, mengakibatkan kemerosotan prestasi. Untuk tujuan ini, mekanisme silang perhatian berbilang kepala diperkenalkan untuk menyelaraskan ciri-ciri ini secara mendalam. Ciri sejajar ini dimasukkan ke kepala pengesanan untuk meramalkan nilai sebenar akhir tanpa menghasilkan hingar.
Untuk pengekod awan titik, kaedah berasaskan voxel digunakan untuk pengekstrakan dan kaedah berasaskan jarang digunakan untuk pemprosesan. Kaedah berasaskan Voxel menukar mata LiDAR kepada voxel. Berbanding dengan siri kaedah pengekstrakan ciri titik lain (seperti kaedah berasaskan titik), kaedah ini mendiskrisikan awan titik menjadi grid 3D yang sama jaraknya, mengurangkan keperluan memori sambil mengekalkan maklumat bentuk 3D asal sebanyak mungkin. Kaedah pemprosesan berasaskan sparsity seterusnya membantu rangkaian meningkatkan kecekapan pengiraan. Faedah ini mengimbangi keperluan pengiraan yang agak tinggi bagi model resapan.
Berbanding dengan ciri 2D, ciri 3D mengandungi dimensi tambahan, menjadikan pembelajaran lebih mencabar. Dengan mengambil kira perkara ini, selain mengekstrak ciri daripada modaliti asal, laluan gabungan ditambah yang menambahkan ciri imej yang diekstrak sebagai input lain kepada pengekod titik, memudahkan pertukaran maklumat dan memanfaatkan pembelajaran daripada sumber yang lebih pelbagai . Strategi PointFusion digunakan, di mana titik dari sensor LiDAR ditayangkan ke satah imej. Gabungan ciri imej dan titik yang sepadan kemudiannya diproses bersama oleh seni bina VoxelNet.
Penyahkod ciri. Ciri imej yang diekstrak dan ciri titik yang diekstrak digunakan sebagai input kepada penyahkod imej dan titik yang sepadan. Setiap penyahkod juga menggabungkan input daripada kotak bunyi yang dicipta secara unik atau dan masing-masing belajar untuk memperhalusi ciri 2D dan 3D, sebagai tambahan kepada ciri yang diekstrak yang sepadan.
Diinspirasikan oleh Sparse RCNN, penyahkod imej menerima input daripada koleksi kotak cadangan 2D dan memangkas ciri RoI daripada peta ciri yang dicipta oleh pengekod imej. Penyahkod titik menerima input daripada koleksi kotak cadangan 3D dan memangkas ciri RoI daripada peta ciri yang dibuat oleh pengekod imej. Untuk penyahkod titik, input ialah satu set kotak cadangan 3D untuk memangkas ciri RoI 3D daripada peta ciri yang dijana oleh pengekod titik
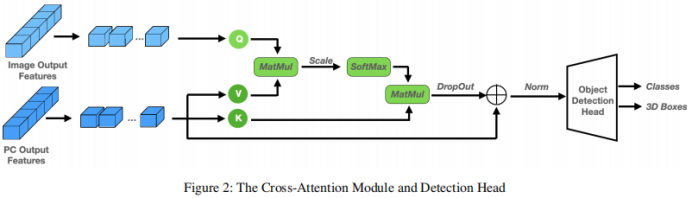
Modul Perhatian Silang. Selepas menyahkod kedua-dua cabang ciri, cara untuk menggabungkannya diperlukan. Pendekatan yang mudah adalah dengan menyambungkan dua cabang ciri dengan menyambungkannya. Kaedah ini nampaknya terlalu kasar dan boleh menyebabkan model mengalami pemotongan maklumat, yang membawa kepada kemerosotan prestasi. Oleh itu, mekanisme perhatian silang berbilang kepala diperkenalkan untuk menjajarkan dan memperhalusi ciri-ciri ini secara mendalam, seperti yang ditunjukkan dalam Rajah 1. Secara khusus, output penyahkod titik dianggap sebagai sumber k dan v, manakala output penyahkod imej diunjurkan ke q.
Hasil eksperimen
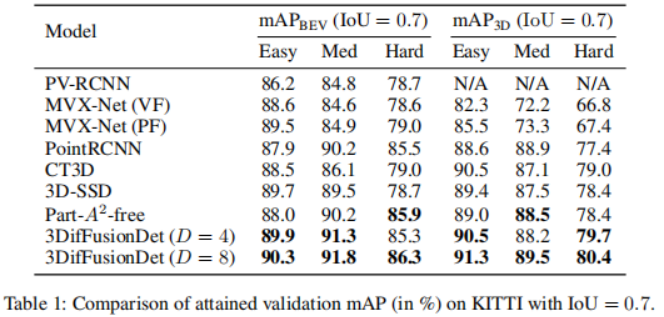
Eksperimen yang dijalankan pada penanda aras pengesanan objek 3D KITTI. Mengikuti protokol penilaian KITTI standard untuk mengukur prestasi pengesanan (IoU = 0.7), Jadual 1 menunjukkan skor min ketepatan (mAP) bagi kaedah 3DifFusionDet berbanding kaedah terkini pada set pengesahan KITTI. Melaporkan prestasi , mengikuti [diffusionDet, difficileist] dan menonjolkan dua model berprestasi terbaik untuk setiap tugas.
Menurut keputusan dalam Jadual 1, kaedah kajian ini menunjukkan peningkatan prestasi yang ketara berbanding garis dasar. Apabila D=4, kaedah tersebut mampu mengatasi kebanyakan model garis dasar dalam masa inferens yang lebih singkat. Apabila terus meningkatkan D kepada 8, prestasi terbaik dicapai antara semua model walaupun masa inferens lebih lama. Fleksibiliti ini mendedahkan bahawa kaedah ini mempunyai pelbagai aplikasi berpotensi
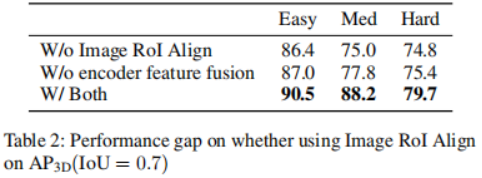
Eksperimen AblasiPertama, keperluan untuk mengekalkan cawangan penjajaran RoI imej dan gabungan ciri pengekod ditunjukkan. Untuk mereka bentuk pengesan objek 3D daripada Kamera dan LiDAR menggunakan model resapan, pendekatan yang paling mudah adalah dengan menggunakan terus kotak 3D bising yang dijana sebagai input kepada ciri 3D bercantum. Walau bagaimanapun, pendekatan ini mungkin mengalami pemotongan maklumat, mengakibatkan kemerosotan prestasi, seperti ditunjukkan dalam Jadual 2. Menggunakan ini, selain meletakkan RoIAlign awan titik di bawah ciri 3D yang dikodkan, kami juga mencipta cawangan kedua yang meletakkan imej RoIAlign di bawah ciri 2D yang dikodkan. Prestasi yang bertambah baik dengan ketara menunjukkan bahawa maklumat pelengkap yang disediakan oleh kedua-dua mod boleh dieksploitasi dengan lebih baik.
Kemudian kami akan menganalisis kesan strategi gabungan yang berbeza: memandangkan ciri perwakilan 2D dan 3D yang dipelajari, bagaimana kami boleh menggabungkannya dengan lebih berkesan. Berbanding dengan ciri 2D, ciri 3D mempunyai dimensi tambahan, yang menjadikan proses pembelajaran lebih mencabar. Kami menambah laluan aliran maklumat daripada ciri imej ke ciri titik dengan menayangkan titik daripada sensor LiDAR ke ciri imej dan menggabungkannya dengan titik sepadan untuk diproses bersama. Ini ialah seni bina VoxelNet. Seperti yang dapat dilihat daripada Jadual 3, strategi gabungan ini mempunyai faedah yang besar untuk ketepatan pengesanan
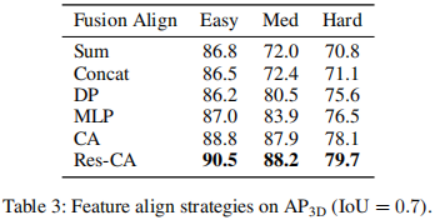
Bahagian lain yang perlu dicantumkan ialah sambungan dua cabang ciri selepas penyahkodan. Di sini, mekanisme silang perhatian berbilang kepala digunakan untuk menjajarkan dan memperhalusi ciri ini secara mendalam. Di samping itu, kaedah yang lebih langsung seperti penggunaan operasi penggabungan, operasi penjumlahan, operasi produk langsung, dan penggunaan multilayer perceptrons (MLPs) juga telah dikaji. Keputusan ditunjukkan dalam Jadual 4. Antaranya, mekanisme cross-attention menunjukkan prestasi terbaik, dengan latihan dan kelajuan inferens yang hampir sama.
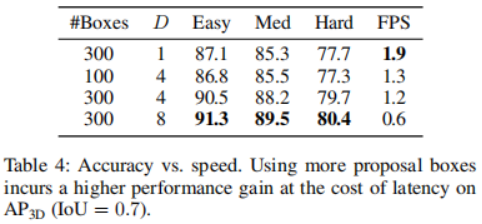
Kaji pertukaran antara ketepatan dan kelajuan inferens. Kesan memilih kotak cadangan dan D yang berbeza ditunjukkan dengan membandingkan ketepatan pengesanan 3D dan bingkai sesaat (FPS). Bilangan kotak cadangan dipilih daripada 100, 300, manakala D dipilih daripada 1, 4, 8. Masa berjalan dinilai pada GPU NVIDIA RTX A6000 tunggal dengan saiz kelompok 1. Telah didapati bahawa meningkatkan bilangan kotak cadangan daripada 100 kepada 300 menghasilkan peningkatan ketepatan yang ketara dengan kos kependaman yang boleh diabaikan (1.3 FPS lwn. 1.2 FPS). Sebaliknya, ketepatan pengesanan yang lebih baik membawa kepada masa inferens yang lebih lama. Apabila menukar D daripada 1 kepada 8, ketepatan pengesanan 3D meningkat daripada tajam (Mudah: 87.1 mAP kepada 90.5 mAP) kepada agak perlahan (Mudah: 90.5 AP kepada 91.3 mAP), manakala FPS terus berkurangan.
Penyelidikan Kes dan Kerja Masa DepanBerdasarkan sifat uniknya, artikel ini membincangkan potensi penggunaan 3DifFusionDet. Secara umumnya, inferens tepat, teguh dan masa nyata ialah tiga keperluan untuk tugas pengesanan objek. Dalam bidang persepsi untuk kenderaan autonomi, model persepsi amat sensitif terhadap keperluan masa nyata, memandangkan kereta yang bergerak pada kelajuan tinggi perlu menghabiskan masa dan jarak tambahan untuk memperlahankan atau menukar arah akibat inersia. Lebih penting lagi, untuk memastikan pengalaman menunggang yang selesa, kereta harus dipandu selancar mungkin dengan nilai pecutan mutlak terkecil di bawah premis keselamatan. Salah satu kelebihan utamanya ialah pengalaman perjalanan yang lebih lancar berbanding produk kereta pandu sendiri yang serupa. Untuk melakukan ini, kereta pandu sendiri harus mula bertindak balas dengan cepat, sama ada memecut, menurun atau membelok. Lebih cepat kereta bertindak balas, lebih banyak ruang untuk pergerakan dan pelarasan seterusnya. Ini adalah lebih penting daripada mendapatkan klasifikasi atau lokasi yang paling tepat bagi sasaran yang dikesan terlebih dahulu: apabila kereta mula bertindak balas, masih ada masa dan jarak untuk melaraskan cara ia berkelakuan, yang boleh digunakan untuk membuat keputusan selanjutnya dengan lebih tepat. Diekstrapolasi, hasilnya kemudiannya digunakan untuk memperhalusi tingkah laku pemanduan kereta.
Kandungan yang ditulis semula adalah seperti berikut: Menurut keputusan dalam Jadual 4, apabila saiz langkah inferens adalah kecil, model 3DifFusionDet kami boleh melakukan inferens dengan cepat dan memperoleh ketepatan yang agak tinggi. Persepsi awal ini cukup tepat untuk membolehkan kereta pandu sendiri menghasilkan respons baharu. Apabila bilangan langkah inferens meningkat, kami dapat menjana pengesanan objek yang lebih tepat dan memperhalusi lagi respons kami. Pendekatan pengesanan progresif ini sesuai untuk tugas kami. Tambahan pula, memandangkan model kami boleh melaraskan bilangan kotak cadangan semasa inferens, kami boleh memanfaatkan maklumat terdahulu yang diperoleh daripada langkah kecil untuk mengoptimumkan bilangan kotak cadangan masa nyata. Mengikut keputusan dalam Jadual 4, prestasi di bawah rangka cadangan a priori yang berbeza juga berbeza. Oleh itu, membangunkan pengesan adaptif sebegini merupakan kerja yang menjanjikan
Kecuali untuk kereta pandu sendiri, model kertas ini pada asasnya sepadan dengan mana-mana senario kehidupan sebenar yang memerlukan masa inferens yang singkat dalam ruang tindak balas berterusan, terutamanya apabila pengesan berdasarkan In adegan di mana keputusan pengesanan bergerak. Mendapat manfaat daripada sifat model resapan, 3DifFusionDet boleh mencari kawasan ruang nyata yang hampir tepat yang diminati, mencetuskan mesin untuk memulakan operasi baharu dan pengoptimuman kendiri. Perceptron berketepatan lebih tinggi seterusnya memperhalusi operasi mesin. Untuk menggunakan model ke dalam pengesan gerakan ini, satu soalan terbuka ialah strategi untuk menggabungkan maklumat inferens antara inferens awal pada langkah yang lebih besar dan inferens yang lebih baru pada langkah yang lebih kecil, yang merupakan satu lagi soalan terbuka.
Ringkasan
Artikel ini memperkenalkan pengesan objek 3D baharu yang dipanggil 3DifFusion LiDARet yang berkuasa 3DifFusion. Merumuskan pengesanan objek 3D sebagai proses denoising generatif, ini adalah kerja pertama untuk menggunakan model resapan pada pengesanan objek 3D. Dalam konteks menjana rangka kerja proses denoising, kajian ini meneroka strategi penjajaran gabungan lidar kamera yang paling berkesan dan mencadangkan strategi penjajaran gabungan untuk mengeksploitasi sepenuhnya maklumat pelengkap yang disediakan oleh kedua-dua mod. Berbanding dengan pengesan matang, 3DifFusionDet berprestasi baik, menunjukkan prospek aplikasi luas model resapan dalam tugas pengesanan objek. Hasil pembelajarannya yang berkuasa dan model penaakulan yang fleksibel menjadikannya mempunyai potensi kegunaan yang luas

Pautan asal: https://mp.weixin.qq.com/s/0Fya4RYelNUU5OdAQp9DVA
Atas ialah kandungan terperinci Sebarkan semuanya? 3DifFusionDet: Model resapan memasuki pengesanan sasaran 3D gabungan LV!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!