
Rumah >Peranti teknologi >AI >Wajib dibaca untuk pengurus produk AI! Panduan pemula untuk bermula dengan algoritma pembelajaran mesin
Wajib dibaca untuk pengurus produk AI! Panduan pemula untuk bermula dengan algoritma pembelajaran mesin

- 王林ke hadapan
- 2023-11-28 17:25:46863semak imbas
Kandungan tentang algoritma pembelajaran mesin Qujie ialah topik artikel seterusnya. Artikel ini dikongsi untuk pelajar yang merupakan pengurus produk AI dan sangat disyorkan kepada pelajar yang baru memasuki bidang ini!

Kami telah bercakap sebelum ini tentang industri kecerdasan buatan, keluk kedua pengurus produk, dan perbezaan antara kedua-dua jawatan Kali ini kami akan menyelidiki lebih mendalam ke peringkat seterusnya - algoritma pembelajaran mesin yang menarik.
Algoritma pembelajaran mesin mungkin agak sukar difahami Saya faham bahawa ramai orang, termasuk saya, berasa sakit kepala pada mulanya. Saya cuba untuk tidak menggunakan formula dan hanya membentangkannya secara beransur-ansur ke bahagian.
1. Gambaran keseluruhan algoritma pembelajaran mesin
Pertama, mari kita fahami konsep asas algoritma pembelajaran mesin.
Pembelajaran mesin ialah kaedah untuk komputer belajar dan menambah baik melalui data, dan algoritma pembelajaran mesin ialah alat untuk mencapai ini
Ringkasnya, algoritma pembelajaran mesin ialah satu set peraturan atau model yang boleh belajar berdasarkan data input dan kemudian membuat ramalan atau keputusan berdasarkan pengetahuan yang dipelajari.
Detik Keseronokan: Bayangkan anda mengambil bahagian dalam pencarian harta karun yang misteri. Dalam permainan, anda perlu mencari lokasi harta karun berdasarkan peta harta karun. Peta harta karun ini ialah data, dan anda hanya perlu mencari harta karun dengan menganalisis data. Dalam kehidupan sebenar, kita boleh mencapai tugas ini melalui algoritma pembelajaran mesin.
Algoritma pembelajaran mesin adalah seperti robot pemburu harta karun pintar yang boleh mempelajari corak daripada sejumlah besar data dan kemudian membuat ramalan atau keputusan berdasarkan corak ini. Matlamat teras algoritma pembelajaran mesin adalah untuk mengurangkan ralat pemetaan daripada data kepada hasil, dengan itu menjadikan produk kami lebih pintar dan tepat.
Algoritma pembelajaran mesin mempunyai pelbagai senario aplikasi Aplikasi biasa termasuk masalah klasifikasi, analisis kelompok dan masalah regresi. Ketiga-tiga senario aplikasi ini mempunyai aplikasi tersendiri dalam kehidupan sebenar. Seterusnya, senario aplikasi mereka dan aplikasi praktikal masing-masing akan diperkenalkan
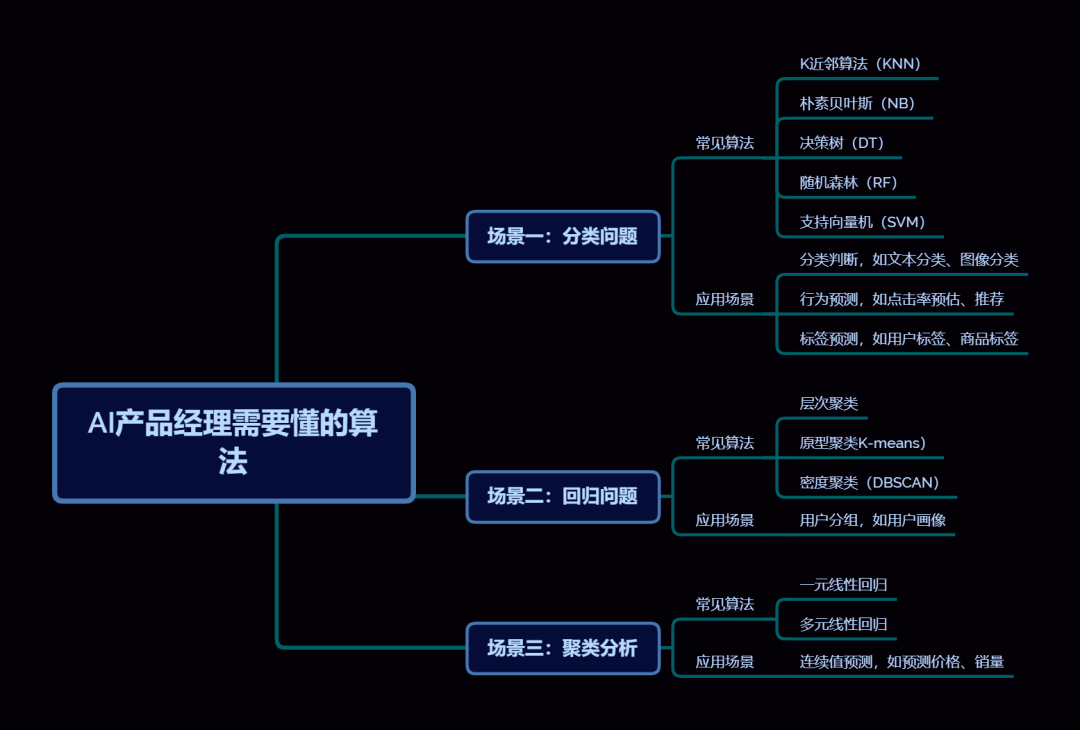
2. Senario 1: Masalah klasifikasi
1) Senario aplikasi: Penghakiman klasifikasi, ramalan label, ramalan tingkah laku.
2) Prinsip penyelesaian: Latih data yang diketahui dan ramalkan data yang tidak diketahui (termasuk dua klasifikasi dan berbilang klasifikasi. Jika hasil ramalan hanya mempunyai dua nilai diskret, seperti "0/1, ya/tidak", ia akan menjadi dua Pengelasan, jika hasil ramalan ialah berbilang nilai diskret, seperti "A/B/C", ia adalah berbilang pengelasan).
Algoritma pengelasan biasa termasuk yang berikut:
- Pokok keputusan: Pokok keputusan ialah algoritma pengelasan berdasarkan struktur pokok, yang mengelaskan data melalui satu siri soalan.
- Mesin Vektor Sokongan: Mesin vektor sokongan ialah algoritma pengelasan berdasarkan konsep geometri yang melakukan pengelasan dengan mencari satah margin maksimum dalam ruang data.
4) Kes: Cegah spam
Penapisan spam ialah masalah pengelasan biasa. Kita boleh menggunakan algoritma mesin vektor sokongan untuk menyelesaikan masalah ini. Dengan melatih model, kami boleh menentukan dengan tepat sama ada e-mel itu spam atau biasa berdasarkan kata kunci, pengirim dan maklumat lain dalam e-mel
3. Senario 2: Analisis kelompok
1) Senario aplikasi: Pengumpulan pengguna, potret pengguna
2) Prinsip penyelesaian: Analisis kluster ialah proses membahagikan set data kepada beberapa kategori. Kategori ini adalah berdasarkan sifat intrinsik atau persamaan data. Untuk meringkaskan ciri-cirinya dalam satu perkataan, "burung dari bulu berkumpul bersama".
3) Algoritma pengelompokan biasa
- K-means clustering: K-means clustering ialah algoritma pengelompokan berasaskan jarak. Ia membahagikan titik data ke dalam kategori K dengan mengira jarak antara mereka secara berulang.
- Pengkelompokan hierarki: Pengelompokan hierarki ialah algoritma pengelompokan berasaskan jarak. Ia secara beransur-ansur membahagikan titik data yang serupa kepada satu kategori dengan mengira jarak antara titik data.
4) Kes: Pembahagian pelanggan
Untuk segmentasi pelanggan, ia adalah aplikasi analisis kelompok biasa. Kami boleh menggunakan algoritma pengelompokan K-means untuk mengumpulkan pelanggan ke dalam kategori berbeza berdasarkan jumlah penggunaan mereka, kekerapan pembelian dan atribut lain, untuk merumuskan strategi pemasaran yang tepat
4. Senario 3: Masalah regresi
1) Senario aplikasi: Ramalkan harga dan jualan masa hadapan.
2) Prinsip penyelesaian: Suaikan graf (garis lurus/lengkung) mengikut taburan sampel, bentuk sistem persamaan, parameter input dan ramalkan nilai tertentu pada masa hadapan.
3) Algoritma regresi biasa
- Regression Linear: Regresi linear ialah algoritma regresi berdasarkan hubungan linear. Ia meramalkan data masa hadapan dengan memasangkan hubungan linear antara titik data.
- Regression pepohon keputusan: Regresi pepohon keputusan ialah algoritma regresi berdasarkan struktur pepohon. Ia meramalkan nilai sasaran melalui satu siri soalan.
- Sokong regresi mesin vektor: Sokongan regresi mesin vektor ialah algoritma regresi berdasarkan konsep geometri. Ia meramalkan nilai sasaran dengan mencari hyperplane margin maksimum dalam ruang data.
4) Ramalan harga saham kes
Ramalan harga saham adalah masalah regresi biasa. Kita boleh menggunakan regresi linear atau menyokong algoritma regresi mesin vektor untuk meramalkan harga saham masa hadapan berdasarkan data harga saham sejarah.
5. Kata akhir
Untuk meringkaskan, tujuan utama artikel ini adalah untuk memperkenalkan algoritma pembelajaran mesin arus perdana. Seterusnya, saya akan menganalisis algoritma bagi tiga senario aplikasi satu demi satu. Jika anda ingin mengetahui sebarang pengetahuan algoritma, sila kongsikan di ruangan komen Selamat datang untuk mencipta dan berkongsi bersama
Semoga ia dapat memberi inspirasi kepada anda, ayuh!
Tolong jangan cetak semula artikel ini pada asalnya Artikel ini diterbitkan oleh @六星笑 Product on Everyone is a Product Manager tanpa kebenaran
.Gambar tajuk datang daripada Unsplash, berdasarkan lesen CC0
Atas ialah kandungan terperinci Wajib dibaca untuk pengurus produk AI! Panduan pemula untuk bermula dengan algoritma pembelajaran mesin. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!