
Rumah >Peranti teknologi >AI >Skala kecil, kecekapan tinggi: DeepMind melancarkan penyelesaian berbilang modal Mirasol 3B
Skala kecil, kecekapan tinggi: DeepMind melancarkan penyelesaian berbilang modal Mirasol 3B

- PHPzke hadapan
- 2023-11-28 14:19:291034semak imbas
Salah satu cabaran utama yang dihadapi pembelajaran pelbagai mod ialah keperluan untuk menggabungkan modaliti heterogen seperti teks, audio dan model video perlu menggabungkan isyarat daripada sumber yang berbeza. Walau bagaimanapun, modaliti ini mempunyai ciri yang berbeza dan sukar untuk digabungkan melalui satu model. Sebagai contoh, video dan teks mempunyai kadar pensampelan yang berbeza
Baru-baru ini, pasukan penyelidik daripada Google DeepMind telah mengasingkan model berbilang modal kepada berbilang model autoregresif bebas dan khusus untuk diproses mengikut ciri pelbagai modaliti yang dimasukkan.
Secara khusus, kajian ini mencadangkan model multimodal yang dipanggil Mirasol3B. Mirasol3B terdiri daripada komponen autoregresif audio dan video yang disegerakkan masa serta komponen autoregresif untuk modaliti kontekstual. Modaliti ini tidak semestinya diselaraskan secara sementara, tetapi disusun secara berurutan

Alamat kertas: https://arxiv.org/abs/2311.05698
peringkat penanda aras yang lebih besar dalam model yang lebih besar. Dengan mempelajari perwakilan yang lebih padat, mengawal panjang jujukan perwakilan ciri audio-video, dan pemodelan berdasarkan surat-menyurat temporal, Mirasol3B dapat memenuhi keperluan pengiraan tinggi input berbilang modal dengan berkesan.
Pengenalan Kaedah
Mirasol3B ialah model multimodal teks audio-video di mana pemodelan autoregresif dipisahkan kepada komponen autoregresif untuk modaliti sejajar masa (cth. audio, video) dan komponen bukan autoregresif modaliti kontekstual yang dijajarkan secara sementara (cth., teks). Mirasol3B menggunakan pemberat perhatian silang untuk menyelaraskan proses pembelajaran komponen ini. Penyahgandingan ini menjadikan pengedaran parameter dalam model lebih munasabah, memperuntukkan kapasiti yang mencukupi kepada modaliti (video dan audio), dan menjadikan model keseluruhan lebih ringan.
Seperti yang ditunjukkan dalam Rajah 1, Mirasol3B terdiri daripada dua komponen pembelajaran utama: komponen autoregresif dan komponen gabungan input. Antaranya, komponen autoregresif direka untuk mengendalikan input berbilang mod yang hampir serentak seperti video dan audio untuk kombinasi input yang tepat pada masanya tukar bahasa ke cina. Kajian ini mencadangkan untuk membahagikan modaliti yang dijajarkan secara sementara ke dalam segmen masa dan mempelajari perwakilan bersama audio-video dalam segmen masa. Secara khusus, penyelidikan ini mencadangkan mekanisme pembelajaran ciri bersama modal yang dipanggil "Combiner". "Combiner" menggabungkan ciri modal dalam tempoh masa yang sama untuk menjana perwakilan yang lebih padat


"Penggabung" dengan berkesan memenuhi keperluan perwakilan modal untuk menjadi cekap dan bermaklumat. Ia boleh merangkumi sepenuhnya acara dan aktiviti dalam video dan modaliti serentak lain, dan boleh digunakan dalam model autoregresif berikutnya untuk mempelajari kebergantungan jangka panjang.
Untuk memproses isyarat video dan audio dan menyesuaikan diri dengan input video/audio yang lebih panjang, ia dibahagikan kepada (kira-kira disegerakkan dalam masa) kepingan kecil, dan kemudian perwakilan audio-visual bersama dipelajari melalui "Combiner" . Komponen kedua mengendalikan konteks, atau isyarat tidak sejajar sementara seperti maklumat teks global, yang selalunya masih berterusan. Ia juga autoregresif dan menggunakan ruang terpendam gabungan sebagai input perhatian silang.
Komponen pembelajaran mengandungi video dan audio, dan parameternya ialah 3B manakala komponen tanpa audio ialah 2.9B. Antaranya, kebanyakan parameter digunakan dalam model autoregresif audio dan video. Mirasol3B biasanya memproses video 128 bingkai, dan juga boleh memproses video yang lebih panjang, seperti 512 bingkai Disebabkan reka bentuk partition dan seni bina model "Combiner", menambah lebih banyak bingkai atau meningkatkan saiz dan bilangan blok, dsb., hanya Parameter akan ditingkatkan sedikit, yang menyelesaikan masalah bahawa video yang lebih panjang memerlukan lebih banyak parameter dan memori yang lebih besar.

Eksperimen dan Keputusan
Kajian ini menilai Mirasol3B pada penanda aras VideoQA standard, penanda aras VideoQA video panjang dan penanda aras audio+video.
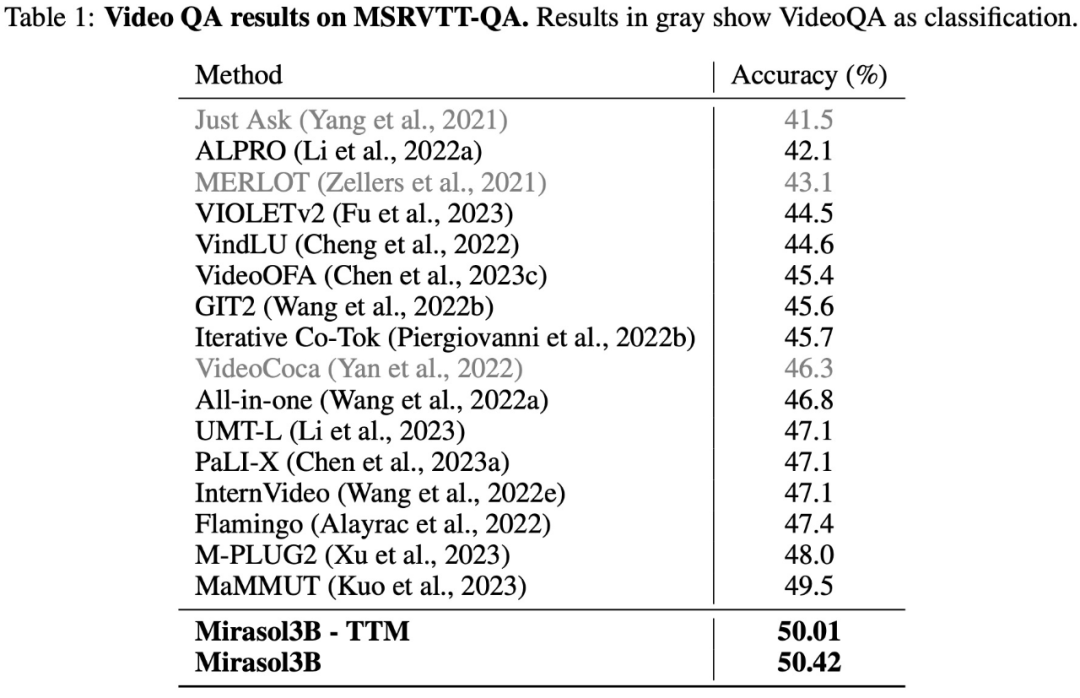
Keputusan ujian pada set data VideoQA MSRVTTQA ditunjukkan dalam Jadual 1 di bawah Mirasol3B mengatasi model SOTA semasa, serta model yang lebih besar seperti PaLI-X dan Flamingo.
Dari segi soal jawab video yang panjang, kajian ini menguji dan menilai Mirasol3B pada set data ActivityNet-QA dan NExTQA Keputusan ditunjukkan dalam Jadual 2 di bawah:

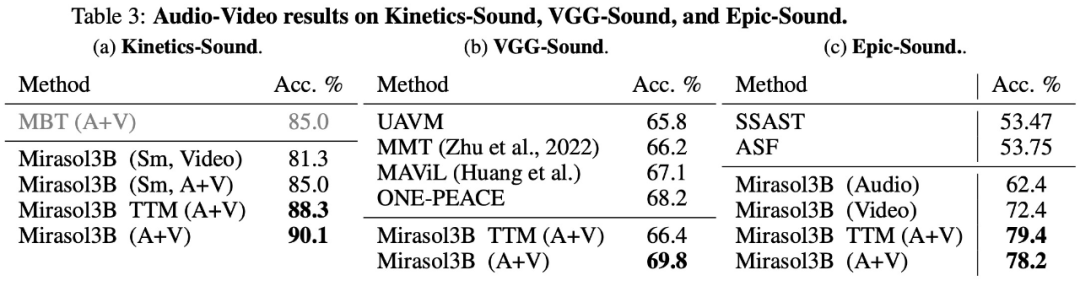
. akhir, kajian KineticsSound, VGG-Sound dan Epic-Sound telah dipilih untuk penanda aras audio-video dan penilaian generasi terbuka telah diterima pakai. Keputusan eksperimen ditunjukkan dalam Jadual 3 di bawah:
Pembaca yang berminat boleh membaca teks asal kertas untuk mengetahui lebih lanjut tentang kandungan penyelidikan. 🎜🎜
Atas ialah kandungan terperinci Skala kecil, kecekapan tinggi: DeepMind melancarkan penyelesaian berbilang modal Mirasol 3B. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 常用的关系型数据库有哪些?
- 一旦断电,数据就会丢失的存储器是什么
- Cara mengekstrak dan menjumlahkan data yang sepadan dengan nama yang sama
- Pakar AI terkemuka Google menyertai OpenAI dan memberi amaran kepada Google supaya tidak menggunakan data ChatGPT untuk melatih Bard
- Aplikasi dan penyelidikan carian industri berdasarkan model bahasa pra-terlatih