
Rumah >Peranti teknologi >AI >Pembelajaran diselia berbanding tanpa seliaan: Pakar menentukan jurang
Pembelajaran diselia berbanding tanpa seliaan: Pakar menentukan jurang

- 王林ke hadapan
- 2023-11-23 18:09:22960semak imbas
Apa yang perlu ditulis semula ialah: Fahami ciri-ciri pembelajaran diselia, pembelajaran tanpa penyeliaan dan pembelajaran separa penyeliaan, dan cara ia digunakan dalam projek pembelajaran mesin
#🎜🎜 #
Apabila membincangkan teknologi kecerdasan buatan, pembelajaran terselia selalunya merupakan kaedah yang paling mendapat perhatian kerana ia biasanya merupakan langkah terakhir dalam mencipta model kecerdasan buatan yang boleh digunakan Digunakan dalam pengecaman imej, ramalan yang lebih baik, pengesyoran produk dan pemarkahan petunjuk
Sebaliknya, pembelajaran tanpa pengawasan cenderung berlaku pada awal kitaran hayat pembangunan AI Bekerja di belakang adegan: Ia sering digunakan untuk meletakkan asas kepada keajaiban pembelajaran di bawah seliaan terungkap, sama seperti kerja rungutan yang membolehkan pengurus menyinar. Seperti yang dijelaskan kemudian, kedua-dua model pembelajaran mesin boleh digunakan dengan berkesan untuk masalah perniagaan.
Pada peringkat teknikal, perbezaan antara pembelajaran diselia dan tidak diselia ialah sama ada data mentah yang digunakan untuk mencipta algoritma adalah pra-label (pembelajaran diselia) atau tidak dilabelkan (Tanpa seliaan pembelajaran). Apakah pembelajaran yang diselia?
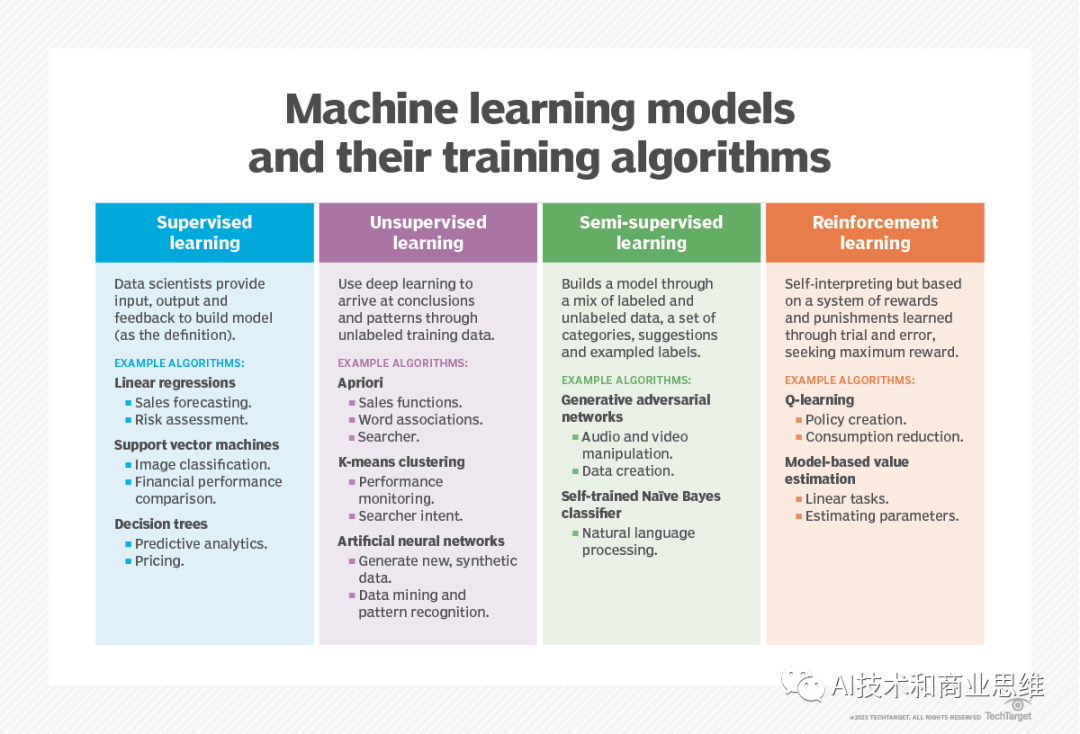
Dalam pembelajaran diselia, saintis data menyediakan algoritma dengan data latihan berlabel dan mentakrifkan pembolehubah yang mereka mahu algoritma menilai untuk kaitannya #🎜🎜 ## 🎜🎜#Data input dan pembolehubah output algoritma ditentukan melalui data latihan. Contohnya, jika anda ingin menggunakan pembelajaran diselia untuk melatih algoritma untuk menentukan sama ada imej mengandungi kucing, anda boleh membuat label untuk setiap imej yang digunakan dalam data latihan untuk menunjukkan sama ada imej itu mengandungi kucing# 🎜🎜##🎜 🎜#
Seperti yang kami jelaskan dalam takrifan pembelajaran terselia kami: “[A] algoritma komputer dilatih pada data input yang dilabelkan untuk output tertentu Model ini dilatih pada Terlatih sehingga ia dapat mengesan asas corak dan hubungan antara data input dan label output, membolehkannya menghasilkan hasil pelabelan yang tepat apabila dibentangkan dengan data yang tidak pernah dilihat sebelum ini termasuk klasifikasi, pepohon keputusan dan regresi dan pemodelan ramalan, yang boleh anda pelajari dalam tutorial pembelajaran mesin Arcitura Education Teknik pembelajaran mesin yang diselia digunakan dalam pelbagai aplikasi perniagaan, termasuk Kandungan berikut: #
Diperibadikan. pemasaran
Insurans/Keputusan Pengunderaitan Kredit #🎜🎜🎜##🎜🎜🎜
Pengesanan Penipuan Apakah itu pembelajaran tanpa pengawasan 🎜🎜#Dalam pembelajaran tanpa pengawasan, terdapat algoritma yang sesuai untuk kaedah ini (seperti pengelompokan K-means), yang dilatih pada data tidak berlabel . Algoritma mengimbas set data, mencari sebarang korelasi yang bermakna di dalamnya, dengan kata lain, pembelajaran tanpa pengawasan mengenal pasti corak dan persamaan dalam data daripada mengaitkannya dengan beberapa ukuran luaran
#🎜 🎜##🎜. 🎜#Pendekatan ini berguna apabila anda tidak tahu perkara yang anda cari, tetapi kurang berguna apabila anda mengetahuinya jika anda menunjukkan beribu-ribu atau ratusan kepada algoritma yang tidak diselia, ia mungkin mengklasifikasikan subset imej yang dikenal pasti oleh manusia sebagai kucing Sebaliknya, algoritma diselia yang dilatih pada data berlabel kucing berbanding anjing dapat mengenal pasti kucing dengan tahap keyakinan yang tinggi memerlukan berjuta-juta imej berlabel untuk membangunkan model, ramalan yang dihasilkan oleh mesin memerlukan banyak usaha manusia #Ada jalan tengah: pembelajaran separuh diselia- Apa itu. pembelajaran separa diselia?
- Pembelajaran separa diselia ialah kaedah berkesan yang menggabungkan pembelajaran tanpa seliaan dan pembelajaran seliaan untuk menjana label secara automatik aliran kerja tertentu, dan kemudian memasukkan label ini ke dalam algoritma pembelajaran diselia secara manual Labelkan beberapa imej, manakala algoritma pembelajaran tanpa pengawasan meneka label imej lain, dan akhirnya semua label dan imej dimasukkan ke dalam algoritma pembelajaran diselia, dengan itu mencipta AI. Model Satu faedah pembelajaran separa penyeliaan ialah ia mengurangkan kos penggunaan set data yang besar dalam pembelajaran mesin. Menurut Aaron Kalb, pengasas bersama dan ketua pegawai inovasi platform katalog data perusahaan Alation, jika manusia boleh dibenarkan melabel 0.01% daripada berjuta-juta sampel, komputer boleh menggunakan label tersebut untuk meningkatkan ketepatan ramalan mereka dengan ketara# 🎜🎜##🎜 🎜#
Apakah itu pembelajaran pengukuhan?
Kaedah pembelajaran mesin lain ialah pembelajaran pengukuhan. Pembelajaran pengukuhan biasanya digunakan untuk mengajar mesin melengkapkan urutan langkah, dan berbeza daripada pembelajaran diselia dan tidak diselia. Ahli sains data memprogramkan algoritma untuk melaksanakan tugas, memberikan isyarat atau peneguhan positif atau negatif apabila menentukan cara untuk menyelesaikan tugasan. Pengaturcara menetapkan peraturan untuk ganjaran, tetapi membenarkan algoritma menentukan langkah yang perlu diambil untuk memaksimumkan ganjaran untuk menyelesaikan tugas.
Bilakah anda harus menggunakan pembelajaran terselia berbanding pembelajaran tanpa pengawasan?
Shivani Rao, pengurus pembelajaran mesin di LinkedIn, berkata amalan terbaik untuk menggunakan kaedah pembelajaran mesin diselia atau tidak diselia selalunya bergantung pada persekitaran, perkara yang boleh anda lakukan dengan data anda dan permohonan anda. Pilihan untuk menggunakan algoritma pembelajaran mesin diselia berbanding tidak diselia juga akan berubah dari semasa ke semasa, kata Rao. Pada peringkat awal proses pembinaan model, data selalunya tidak dilabelkan, manakala data berlabel boleh muncul dalam peringkat pemodelan kemudian.
Sebagai contoh, untuk masalah meramal sama ada ahli LinkedIn akan menonton video kursus, model pertama menggunakan teknik tanpa pengawasan. Selepas cadangan ini disediakan, metrik yang merekodkan sama ada seseorang mengklik pada cadangan akan memberikan data baharu untuk menjana hashtag
LinkedIn juga menggunakan teknik ini untuk menandakan pelajar yang mungkin ingin kursus dalam talian untuk kemahiran memperoleh. Penanda manusia, seperti pengarang, penerbit atau pelajar, boleh memberikan senarai kemahiran yang tepat dan tepat yang diajar dalam kursus, tetapi mereka tidak mungkin memberikan senarai lengkap kemahiran tersebut. Oleh itu, label data ini boleh dianggap tidak lengkap. Jenis masalah ini boleh menggunakan teknik separa diselia untuk membantu membina set label yang lebih lengkap.
Bharath Thota, pakar dalam sains data dan analisis lanjutan serta rakan kongsi di firma perunding Kearney, berkata pemilihan pasukannya Faktor praktikal juga cenderung diambil kira apabila menggunakan pembelajaran diselia atau tidak diselia.
Thota berkata: “Kami memilih pembelajaran terselia sebagai aplikasi apabila terdapat data berlabel yang tersedia, dengan matlamat untuk meramalkan atau mengklasifikasikan pemerhatian masa hadapan Apabila tiada Apabila tersedia melabelkan data, kami menggunakan pembelajaran tanpa pengawasan, dengan matlamat untuk membangunkan strategi dengan mengenal pasti corak atau coretan daripada data,” kata Kalb, seorang saintis data Alation yang bekerja secara dalaman digunakan dalam pelbagai aplikasi. Contohnya, mereka membangunkan proses mesin manusia yang bekerjasama untuk menterjemah nama objek data yang tidak jelas ke dalam bahasa manusia—contohnya, "na_gr_rvnu_ps" kepada "jumlah hasil perkhidmatan profesional Amerika Utara." Dalam kes ini, tekaan mesin, manusia mengesahkan, pembelajaran mesin
" Anda boleh menganggapnya sebagai pembelajaran separa penyeliaan dalam gelung berulang, mewujudkan ketepatan yang lebih baik. kitaran seks yang mulia,” kata Kalb. 5 teknik pembelajaran tanpa pengawasan Untuk regresi (memasang model pada set titik data untuk membuat ramalan) atau masalah klasifikasi (adakah imej mempunyai kucing? Set data asal dihiris dan dipotong dadu untuk melengkapkan usaha pembelajaran yang diselia dengan cara seperti :
dengan titik data ciri dikumpulkan bersama untuk membantu memahami dan meneroka data dengan lebih berkesan, contohnya, syarikat mungkin menggunakan data kaedah pengelompokan untuk membahagikan pelanggan kepada kumpulan berdasarkan demografi mereka, minat, gelagat pembelian dan faktor lain 🎜🎜#
Pengurangan dimensi model berfungsi dengan menganalisis hubungan antara pembolehubah untuk berfungsi dengan lebih baik Contoh mudah pengurangan dimensi adalah menggunakan keuntungan sebagai satu dimensi, yang mewakili hasil tolak perbelanjaan - dua dimensi bebas , pengekod auto, kepada Algoritma seperti penukaran teks-ke-vektor atau pembenaman kejiranan stokastik teragih-T menjana jenis pembolehubah baharu yang lebih kompleks
Pengurangan dimensi boleh membantu mengurangkan masalah overfitting, di mana model itu berada. sesuai. Berfungsi dengan baik dengan set data yang kecil, tetapi tidak menyamaratakan dengan baik kepada data baharu Teknologi ini juga membolehkan syarikat memvisualisasikan data berdimensi tinggi dalam 2D atau 3D yang mudah difahami oleh manusia 🎜🎜#Anomali atau pengesanan luar . Pembelajaran tanpa pengawasan boleh membantu mengenal pasti dan membuang anomali sebagai langkah penyediaan data yang boleh meningkatkan prestasi model pembelajaran mesin 🎜🎜#
.Transfer pembelajaran. Algoritma ini memanfaatkan model yang dilatih mengenai tugasan yang berkaitan tetapi berbeza. Sebagai contoh, pemindahan teknik pembelajaran memudahkan untuk memperhalusi pengelas yang dilatih pada artikel Wikipedia untuk melabel sebarang jenis teks baharu dengan topik yang betul. Rao LinkedIn berkata ini adalah salah satu cara paling berkesan dan paling cepat untuk menyelesaikan masalah data tidak berlabel.
Algoritma berasaskan graf. Rao berkata teknik ini cuba membina graf yang menangkap hubungan antara titik data. Contohnya, jika setiap titik data mewakili ahli LinkedIn yang mempunyai kemahiran, anda boleh mewakili ahli menggunakan graf, dengan tepi mewakili pertindihan kemahiran antara ahli. Algoritma graf juga boleh membantu memindahkan label daripada titik data yang diketahui kepada titik data yang tidak diketahui tetapi berkait rapat. Pembelajaran tanpa pengawasan juga boleh digunakan untuk membina graf antara pelbagai jenis entiti (sumber dan sasaran). Lebih kuat kelebihan, lebih tinggi pertalian nod sumber kepada nod sasaran. Sebagai contoh, LinkedIn menggunakannya untuk memadankan ahli dengan kursus berasaskan kemahiran.
Atas ialah kandungan terperinci Pembelajaran diselia berbanding tanpa seliaan: Pakar menentukan jurang. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!