

 Peranti teknologiAIPasukan Tsinghua mencadangkan rangka kerja pra-latihan Transformer graf berpandukan pengetahuan: kaedah untuk meningkatkan pembelajaran perwakilan molekul
Peranti teknologiAIPasukan Tsinghua mencadangkan rangka kerja pra-latihan Transformer graf berpandukan pengetahuan: kaedah untuk meningkatkan pembelajaran perwakilan molekul

Untuk menggalakkan ramalan sifat molekul, dalam bidang penemuan dadah, adalah sangat penting untuk mempelajari molekul yang berkesan perwakilan ciri. Baru-baru ini, orang ramai telah mengatasi cabaran kekurangan data dengan pra-latihan rangkaian saraf graf (GNN) menggunakan teknik pembelajaran yang diselia sendiri. Walau bagaimanapun, terdapat dua masalah utama dengan kaedah semasa berdasarkan pembelajaran penyeliaan kendiri: kekurangan strategi pembelajaran penyeliaan kendiri yang jelas dan keupayaan terhad GNN
Baru-baru ini, penyelidikan dari Universiti Tsinghua, West Lake University dan Makmal Zhijiang Pasukan itu mencadangkan Latihan Pra-latihan Pengubah Graf (KPGT) berpandukan Pengetahuan, rangka kerja pembelajaran diselia sendiri yang menyediakan ramalan sifat molekul yang lebih baik, boleh digeneralisasikan dan Teguh. Rangka kerja KPGT menyepadukan Transformer graf yang direka khusus untuk graf molekul dan strategi pra-latihan berpandukan pengetahuan untuk menangkap sepenuhnya pengetahuan struktur dan semantik molekul.
Melalui ujian pengiraan yang meluas pada 63 set data, KPGT telah menunjukkan prestasi unggul dalam meramalkan sifat molekul dalam pelbagai bidang. Tambahan pula, kebolehgunaan praktikal KPGT dalam penemuan ubat telah disahkan dengan mengenal pasti perencat berpotensi dua sasaran antitumor. Secara keseluruhan, KPGT boleh menyediakan alat yang berkuasa dan berguna untuk memajukan proses penemuan dadah berbantukan AI.
Penyelidikan itu bertajuk "Rangka kerja pra-latihan berpandukan pengetahuan untuk meningkatkan pembelajaran perwakilan molekul" dan diterbitkan dalam "Nature Communications" pada 21 November 2023.

Menentukan sifat molekul secara eksperimen memerlukan masa dan sumber yang penting, dan mengenal pasti molekul dengan sifat yang dikehendaki adalah salah satu cabaran paling ketara dalam penemuan ubat. Dalam beberapa tahun kebelakangan ini, kaedah berasaskan kecerdasan buatan telah memainkan peranan yang semakin penting dalam meramalkan sifat molekul. Salah satu cabaran utama kaedah berasaskan kecerdasan buatan untuk meramalkan sifat molekul ialah pencirian molekul
Dalam beberapa tahun kebelakangan ini, kaedah berasaskan pembelajaran mendalam telah muncul sebagai alat yang berpotensi berguna untuk meramalkan sifat molekul, terutamanya kerana keupayaan mereka untuk Keupayaan cemerlang untuk mengekstrak ciri berkesan secara automatik daripada data input mudah. Terutamanya, pelbagai seni bina rangkaian saraf, termasuk rangkaian saraf berulang (RNN), rangkaian saraf konvolusi (CNN), dan rangkaian saraf graf (GNN), mahir memodelkan data molekul dalam pelbagai format, daripada input molekul dipermudahkan kepada sistem input Line ( SMILES) kepada imej molekul dan gambar rajah molekul. Walau bagaimanapun, ketersediaan terhad molekul penanda dan keluasan ruang kimia mengehadkan prestasi ramalan mereka, terutamanya apabila berurusan dengan sampel data luar pengedaran.
Dengan pencapaian luar biasa kaedah pembelajaran penyeliaan sendiri dalam bidang pemprosesan bahasa semula jadi dan penglihatan komputer, teknik ini telah digunakan untuk pra-melatih GNN dan meningkatkan pembelajaran perwakilan molekul, dengan itu melaksanakan molekul hiliran tugas ramalan harta Kemajuan besar telah dicapai dalam
Penyelidik membuat hipotesis bahawa memperkenalkan pengetahuan tambahan yang secara kuantitatif menerangkan ciri molekul ke dalam rangka kerja pembelajaran yang diselia sendiri dapat menangani cabaran ini dengan berkesan. Molekul mempunyai banyak ciri kuantitatif, seperti deskriptor molekul dan cap jari, yang boleh diperoleh dengan mudah dengan alat pengiraan yang sedia ada. Mengintegrasikan pengetahuan tambahan ini boleh memperkenalkan maklumat semantik molekul yang kaya ke dalam pembelajaran yang diselia sendiri, dengan itu meningkatkan pemerolehan perwakilan molekul yang kaya secara semantik.
Secara amnya, kaedah pembelajaran penyeliaan kendiri sedia ada bergantung pada GNN sebagai model teras. Walau bagaimanapun, GNN mempunyai kapasiti model yang terhad. Tambahan pula, GNN boleh mengalami kesukaran menangkap interaksi jarak jauh antara atom. Dan model berasaskan Transformer telah menjadi model yang mengubah permainan. Ia dicirikan oleh peningkatan bilangan parameter dan keupayaan untuk menangkap interaksi jarak jauh, menyediakan pendekatan yang menjanjikan untuk memodelkan ciri-ciri struktur molekul secara menyeluruh
Rangka kerja pembelajaran penyeliaan kendiri KPGT# 🎜🎜 #
Dalam kajian ini, penyelidik memperkenalkan rangka kerja pembelajaran penyeliaan kendiri yang dipanggil KPGT, yang bertujuan untuk meningkatkan pembelajaran perwakilan molekul dan dengan itu menggalakkan tugas ramalan sifat molekul hiliran. Rangka kerja KPGT terdiri daripada dua komponen utama: model tulang belakang yang dipanggil Line Graph Transformer (LiGhT) dan dasar pra-latihan berpandukan pengetahuan. Rangka kerja KPGT menggabungkan model LiGhT berkapasiti tinggi, yang direka khusus untuk memodelkan struktur graf molekul dengan tepat, dan menggunakan strategi pra-latihan berpandukan pengetahuan untuk menangkap struktur molekul dan pengetahuan semantik Pasukan penyelidik menggunakan data ChEMBL29 Tertumpu kira-kira 2 juta molekul, LiGhT telah dilatih terlebih dahulu melalui strategi pra-latihan berpandukan pengetahuan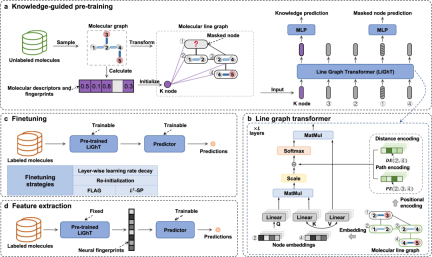 #🎜🎜T# Kandungan ditulis semula ialah: Carta: KPG Gambaran Keseluruhan . (Sumber: kertas)
#🎜🎜T# Kandungan ditulis semula ialah: Carta: KPG Gambaran Keseluruhan . (Sumber: kertas)
KPGT mengatasi kaedah asas dalam ramalan sifat molekul. Berbanding dengan beberapa kaedah asas, KPGT mencapai peningkatan ketara pada 63 set data.
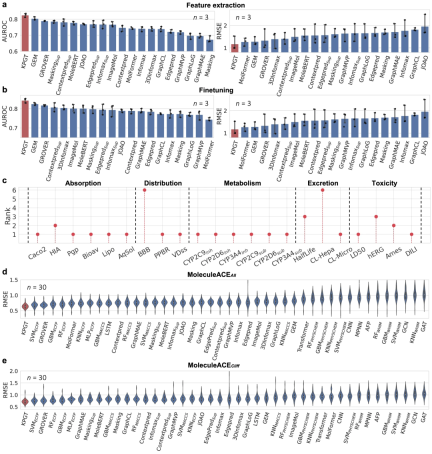
Selain itu, aplikasi praktikal KPGT telah ditunjukkan dengan berjaya menggunakan KPGT untuk mengenal pasti potensi perencat dua sasaran anti-tumor, hematopoietik progenitor kinase 1 (HPK1) dan reseptor faktor pertumbuhan fibroblast (FGFR1).

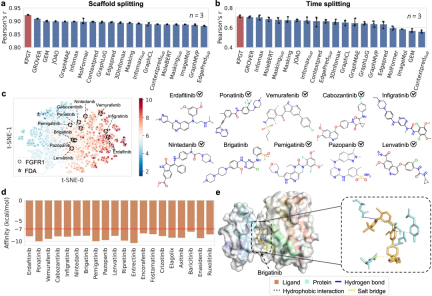
Batasan Penyelidikan
Walaupun kelebihan KPGT dalam ramalan sifat molekul yang berkesan, masih terdapat beberapa batasan.
Pertama sekali, penyepaduan pengetahuan tambahan adalah ciri yang paling ketara dalam kaedah yang dicadangkan. Sebagai tambahan kepada 200 deskriptor molekul dan 512 RDKFP yang digunakan dalam KPGT, terdapat potensi untuk menggabungkan pelbagai jenis pengetahuan maklumat tambahan yang lain. Selain itu, penyelidikan lanjut boleh menyepadukan konformasi molekul tiga dimensi (3D) ke dalam proses pra-latihan, membolehkan model menangkap maklumat 3D penting tentang molekul dan berpotensi meningkatkan keupayaan pembelajaran perwakilan. Walaupun KPGT pada masa ini menggunakan model tulang belakang dengan kira-kira 100 juta parameter dan pra-latihan pada 2 juta molekul, penerokaan pra-latihan berskala lebih besar boleh memberikan manfaat yang lebih besar untuk pembelajaran perwakilan molekul.
Secara keseluruhannya, KPGT menyediakan rangka kerja pembelajaran penyeliaan kendiri yang berkuasa untuk pembelajaran perwakilan molekul yang berkesan, dengan itu memajukan bidang penemuan dadah berbantukan kecerdasan buatan.
Pautan kertas: https://www.nature.com/articles/s41467-023-43214-1
Atas ialah kandungan terperinci Pasukan Tsinghua mencadangkan rangka kerja pra-latihan Transformer graf berpandukan pengetahuan: kaedah untuk meningkatkan pembelajaran perwakilan molekul. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Pembantu AI baru Meta: Booster Produktiviti atau Tenggelam Masa?May 01, 2025 am 11:18 AM
Pembantu AI baru Meta: Booster Produktiviti atau Tenggelam Masa?May 01, 2025 am 11:18 AMMETA telah bergabung dengan rakan-rakan seperti Nvidia, IBM dan Dell untuk mengembangkan integrasi penempatan peringkat perusahaan Llama Stack. Dari segi keselamatan, Meta telah melancarkan alat -alat baru seperti Llama Guard 4, Llamifirewall dan Cyberseceval 4, dan melancarkan program pembela Llama untuk meningkatkan keselamatan AI. Di samping itu, META telah mengedarkan $ 1.5 juta dalam geran Llama Impact kepada 10 institusi global, termasuk pemula yang bekerja untuk meningkatkan perkhidmatan awam, penjagaan kesihatan dan pendidikan. Permohonan Meta AI yang baru dikuasakan oleh Llama 4, dikandung sebagai Meta AI
 80% Gen Zers akan berkahwin dengan AI: KajianMay 01, 2025 am 11:17 AM
80% Gen Zers akan berkahwin dengan AI: KajianMay 01, 2025 am 11:17 AMJoi Ai, sebuah syarikat yang merintis interaksi manusia-ai, telah memperkenalkan istilah "AI-Lationships" untuk menggambarkan hubungan yang berkembang ini. Jaime Bronstein, ahli terapi hubungan di Joi Ai, menjelaskan bahawa ini tidak dimaksudkan untuk menggantikan manusia c
 AI membuat masalah bot Internet lebih teruk. Permulaan $ 2 bilion ini berada di barisan hadapanMay 01, 2025 am 11:16 AM
AI membuat masalah bot Internet lebih teruk. Permulaan $ 2 bilion ini berada di barisan hadapanMay 01, 2025 am 11:16 AMPenipuan dalam talian dan serangan bot menimbulkan cabaran penting bagi perniagaan. Peruncit melawan bot produk penimbunan, pengambilalihan akaun Bank Battle, dan platform media sosial berjuang dengan peniru. Kebangkitan AI memburukkan lagi masalah ini, Rende
 Menjual ke Robot: Revolusi Pemasaran yang akan membuat atau memecahkan perniagaan andaMay 01, 2025 am 11:15 AM
Menjual ke Robot: Revolusi Pemasaran yang akan membuat atau memecahkan perniagaan andaMay 01, 2025 am 11:15 AMEjen AI bersedia untuk merevolusikan pemasaran, yang berpotensi melampaui kesan peralihan teknologi terdahulu. Ejen -ejen ini, yang mewakili kemajuan yang signifikan dalam AI generatif, bukan sahaja memproses maklumat seperti chatgpt tetapi juga mengambil actio
 Bagaimana Teknologi Penglihatan Komputer Mengubah NBA Playoff merasmikanMay 01, 2025 am 11:14 AM
Bagaimana Teknologi Penglihatan Komputer Mengubah NBA Playoff merasmikanMay 01, 2025 am 11:14 AMImpak AI terhadap keputusan NBA Game 4 penting Dua pertandingan NBA permainan yang penting mempamerkan peranan permainan AI yang berubah-ubah dalam merasmikan. Pada mulanya, Nikola Jokic dari Denver yang terlepas tiga pointer membawa kepada lorong-lorong terakhir yang terakhir oleh Aaron Gordon. Sony's Haw
 Bagaimana AI mempercepat masa depan ubat regeneratifMay 01, 2025 am 11:13 AM
Bagaimana AI mempercepat masa depan ubat regeneratifMay 01, 2025 am 11:13 AMSecara tradisinya, memperluaskan kepakaran perubatan regeneratif secara global menuntut perjalanan yang luas, latihan tangan, dan tahun mentor. Sekarang, AI sedang mengubah landskap ini, mengatasi batasan geografi dan mempercepatkan kemajuan melalui en
 Pengambilan kunci dari Intel Foundry Direct Connect 2025May 01, 2025 am 11:12 AM
Pengambilan kunci dari Intel Foundry Direct Connect 2025May 01, 2025 am 11:12 AMIntel sedang berusaha untuk mengembalikan proses pembuatannya ke kedudukan utama, sambil cuba menarik pelanggan semikonduktor yang hebat untuk membuat cip di fabanya. Untuk tujuan ini, Intel mesti membina lebih banyak kepercayaan dalam industri, bukan sahaja untuk membuktikan daya saing prosesnya, tetapi juga untuk menunjukkan bahawa rakan kongsi boleh mengeluarkan cip dalam aliran kerja yang biasa dan matang, konsisten dan sangat dipercayai. Semua yang saya dengar hari ini membuatkan saya percaya Intel bergerak ke arah matlamat ini. Ucapan utama CEO baru Tan Libai memulakan hari. Tan Libai adalah mudah dan ringkas. Beliau menggariskan beberapa cabaran dalam Perkhidmatan Foundry Intel dan langkah -langkah syarikat telah mengambil untuk menangani cabaran -cabaran ini dan merancang laluan yang berjaya untuk perkhidmatan Foundry Intel pada masa akan datang. Tan Libai bercakap mengenai proses perkhidmatan OEM Intel yang dilaksanakan untuk menjadikan pelanggan lebih banyak
 Ai salah? Sekarang ada insurans ' s untuk ituMay 01, 2025 am 11:11 AM
Ai salah? Sekarang ada insurans ' s untuk ituMay 01, 2025 am 11:11 AMMengulas kebimbangan yang semakin meningkat di sekitar risiko AI, Chaucer Group, firma insurans semula khusus global, dan Armilla AI telah bergabung untuk memperkenalkan produk insurans liabiliti pihak ketiga (TPL) novel. Dasar ini melindungi perniagaan terhadap


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Dreamweaver Mac版
Alat pembangunan web visual

