
Rumah >Peranti teknologi >AI >Penambahan Data Kod dalam Pembelajaran Mendalam: Kajian 89 Penyelidikan dalam 5 Tahun
Penambahan Data Kod dalam Pembelajaran Mendalam: Kajian 89 Penyelidikan dalam 5 Tahun

- 王林ke hadapan
- 2023-11-23 14:33:441278semak imbas
Dengan perkembangan pesat pembelajaran mendalam dan model berskala besar, usaha mengejar teknologi inovatif terus meningkat. Dalam proses ini, teknologi penambahan data telah menunjukkan nilai yang tidak boleh diabaikan
Baru-baru ini, satu kajian yang dijalankan bersama oleh Monash University, Singapore Management University, Huawei Noah's Ark Laboratory, Beihang University dan Australian National University Berdasarkan 89 kajian penyelidikan berkaitan dalam tempoh 5 tahun yang lalu, semakan komprehensif mengenai aplikasi peningkatan data kod dalam pembelajaran mendalam telah dikeluarkan.

- Alamat kertas: https://arxiv.org/abs/2305.19915
- Alamat projek: https://github.com/details Ini Kajian semula ini bukan sahaja membincangkan secara mendalam aplikasi teknologi peningkatan data kod dalam bidang pembelajaran mendalam, tetapi juga mengharapkan potensi pembangunan masa depannya. Sebagai teknik untuk meningkatkan kepelbagaian sampel latihan tanpa mengumpul data baharu, penambahan data kod telah mendapat aplikasi yang meluas dalam penyelidikan pembelajaran mesin. Teknik-teknik ini mempunyai kepentingan yang signifikan untuk meningkatkan prestasi model dipacu data di kawasan miskin sumber.
Namun, dalam bidang pemodelan kod, potensi pendekatan ini masih belum dieksploitasi sepenuhnya. Pemodelan kod ialah bidang yang muncul di persimpangan pembelajaran mesin dan kejuruteraan perisian, yang melibatkan penerapan teknik pembelajaran mesin untuk menyelesaikan pelbagai tugas pengekodan, seperti penyiapan kod, ringkasan kod dan pengesanan kecacatan. Data kod mempunyai sifat berbilang modal (bahasa pengaturcaraan dan bahasa semula jadi), yang membawa cabaran unik kepada kaedah penambahan data tersuai
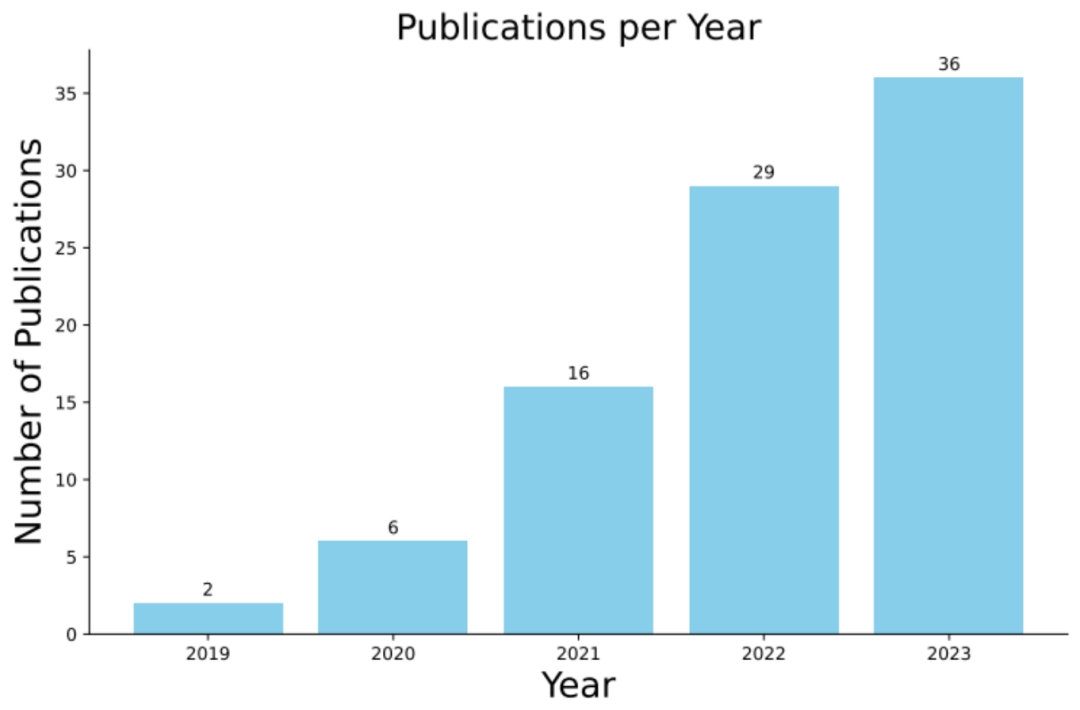
Laporan ulasan ini diterbitkan bersama oleh beberapa institusi akademik dan industri terkemuka. Ia bukan sahaja mendedahkan teknik peningkatan data kod secara mendalam, tetapi juga menyediakan panduan untuk penyelidikan dan aplikasi masa hadapan. Kami percaya bahawa ulasan ini akan memberi inspirasi kepada lebih ramai penyelidik untuk berminat dengan aplikasi penambahan data kod dalam pembelajaran mendalam dan menggalakkan penerokaan dan pembangunan selanjutnya dalam bidang ini
Pengenalan latar belakang
Peningkatan dan kebangkitan model kod. Pembangunan
: Model kod dilatih berdasarkan korpus kod sumber yang besar dan boleh mensimulasikan konteks coretan kod dengan tepat. Daripada penggunaan awal seni bina pembelajaran mendalam seperti LSTM dan Seq2Seq kepada penggabungan model bahasa pra-latihan kemudian, model ini telah menunjukkan prestasi cemerlang dalam tugas hiliran merentas pelbagai sumber. Sebagai contoh, sesetengah model mengambil kira aliran data program semasa peringkat pra-latihan, iaitu struktur tahap semantik kod dan digunakan untuk menangkap hubungan antara pembolehubah. Kepentingan teknologi penambahan data
: Teknologi penambahan data meningkatkan kepelbagaian sampel latihan melalui sintesis data, dengan itu meningkatkan prestasi model dalam pelbagai aspek (seperti ketepatan dan keteguhan). Dalam bidang penglihatan komputer, sebagai contoh, kaedah penambahan data yang biasa digunakan termasuk pemangkasan imej, flipping, dan pelarasan warna. Dalam pemprosesan bahasa semula jadi, penambahan data sangat bergantung pada model bahasa yang boleh menulis semula konteks dengan menggantikan perkataan atau menulis semula ayat. Keistimewaan penambahan data kod
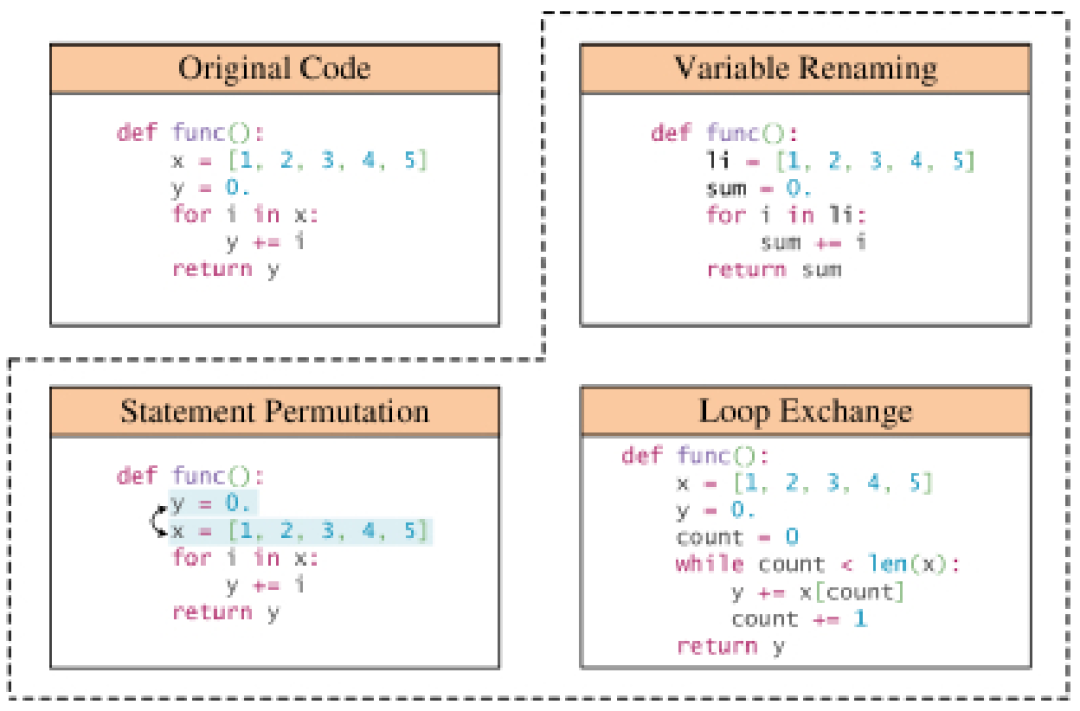
: Tidak seperti imej dan teks biasa, kod sumber dihadkan oleh peraturan sintaks yang ketat bagi bahasa pengaturcaraan, jadi fleksibiliti peningkatan adalah kurang. Kebanyakan kaedah penambahan data untuk kod mesti mematuhi peraturan transformasi khusus untuk mengekalkan kefungsian dan sintaks coretan kod asal. Amalan biasa ialah menggunakan penghurai untuk membina pepohon sintaks konkrit bagi kod sumber dan kemudian menukarnya menjadi pepohon sintaks abstrak, memudahkan perwakilan sambil mengekalkan maklumat utama seperti pengecam dan penyataan aliran kawalan. Transformasi ini adalah asas kaedah penambahan data berasaskan peraturan, dan ia membantu mensimulasikan perwakilan kod yang lebih pelbagai dalam dunia nyata, meningkatkan keteguhan model kod yang dilatih dengan data tambahan. Penerokaan mendalam kaedah penambahan data kod
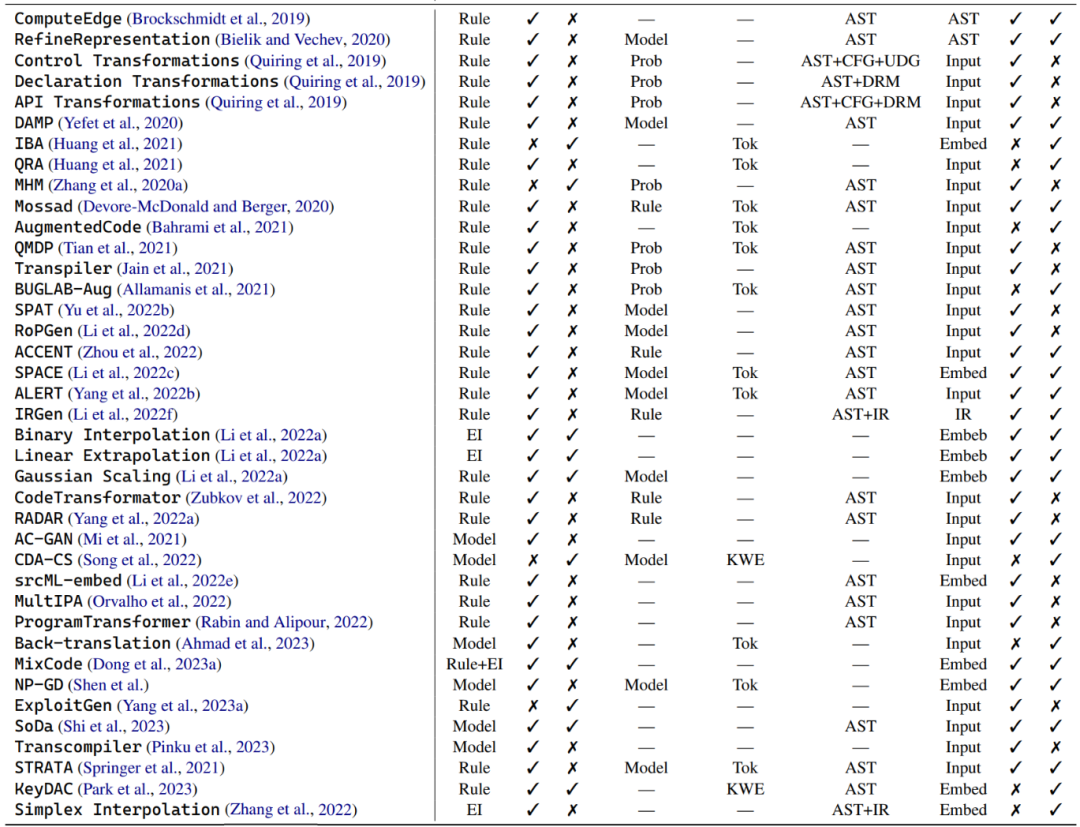
Dalam menyelami dunia penambahan data kod, penulis membahagikan teknik ini kepada tiga kategori utama: teknik berasaskan peraturan, teknik berasaskan model, dan contoh teknik interpolasi. Cawangan-cawangan yang berbeza ini diterangkan secara ringkas di bawah.
Teknologi berasaskan peraturan: Banyak kaedah penambahan data menggunakan peraturan yang telah ditetapkan untuk mengubah program sambil memastikan tidak melanggar peraturan tatabahasa dan semantik. Transformasi ini termasuk operasi seperti menggantikan nama pembolehubah, menamakan semula nama kaedah dan memasukkan kod tidak sah. Selain sintaks program asas, beberapa transformasi juga mempertimbangkan maklumat struktur yang lebih mendalam, seperti graf aliran kawalan dan rantai definisi penggunaan. Terdapat subset teknik peningkatan data berasaskan peraturan yang menumpukan pada meningkatkan konteks bahasa semula jadi dalam coretan kod, termasuk doktrin dan ulasan.
teknologi berasaskan model#🎜#🎜#🎜#🎜🎜 Satu siri teknik penambahan data untuk model kod direka bentuk untuk melatih pelbagai model untuk meningkatkan data. Sebagai contoh, beberapa kajian menggunakan Rangkaian Adversarial Generatif Klasifikasi Tambahan (ACGAN) untuk menjana penambahan. Kajian lain telah melatih rangkaian permusuhan generatif untuk meningkatkan kedua-dua penjanaan kod dan keupayaan carian kod. Kaedah ini terutamanya direka khusus untuk model kod dan bertujuan untuk meningkatkan perwakilan dan pemahaman konteks kod dalam cara yang berbeza.
Contoh Teknik Interpolasi: Teknik penambahan data jenis ini yang berasal daripada Campuran dan Beroperasi pada label dua atau lebih sampel sebenar. Sebagai contoh, diberikan tugas pengelasan binari dalam penglihatan komputer dan dua imej anjing dan kucing, kaedah penambahan data ini boleh menggabungkan input dua imej dan label sepadannya bersama-sama mengikut pemberat yang dipilih secara rawak. Walau bagaimanapun, dalam dunia kod, aplikasi kaedah ini dihadkan oleh sintaks dan fungsi program yang unik. Berbanding dengan interpolasi peringkat permukaan, kebanyakan kaedah penambahan data interpolasi menggabungkan berbilang contoh sebenar ke dalam satu input melalui pembenaman model. Sebagai contoh, terdapat penyelidikan tentang menggabungkan teknik berasaskan peraturan dengan Mixup untuk mencampurkan coretan kod asal dan perwakilan diubah.

Dalam aplikasi praktikal, reka bentuk dan keberkesanan teknik penambahan data untuk model kod dipengaruhi oleh banyak faktor, seperti kos pengiraan, sampel Kepelbagaian dan keteguhan model . Bahagian ini menyerlahkan faktor ini, memberikan pandangan dan petua untuk mereka bentuk dan mengoptimumkan kaedah penambahan data yang sesuai.
Kaedah Susun
: Dalam perbincangan sebelum ini, banyak strategi peningkatan data digunakan dalam satu kerja Pada masa yang sama, dicadangkan bahawa tujuannya adalah untuk meningkatkan prestasi model. Biasanya, gabungan ini termasuk dua jenis: jenis penambahan data yang sama atau campuran kaedah penambahan data yang berbeza. Yang pertama biasanya digunakan pada teknik penambahan data berasaskan peraturan, di mana titik permulaannya ialah satu transformasi kod tidak dapat mewakili sepenuhnya gaya pengekodan dan pelaksanaan yang pelbagai dalam dunia nyata. Beberapa kerja telah menunjukkan bahawa menggabungkan pelbagai jenis teknik penambahan data boleh meningkatkan prestasi model kod. Contohnya, skim transkod berasaskan peraturan dan penambahan data berasaskan model digabungkan untuk mencipta korpus yang dipertingkatkan untuk latihan model. Sementara penyelidikan lain dipertingkatkan pada bahasa pengaturcaraan, termasuk dua teknik peningkatan data: pengekstrakan bukan kata kunci berasaskan peraturan dan penggantian bukan kata kunci berasaskan model. Pengoptimuman
: Dalam sesetengah senario, seperti mempertingkatkan keteguhan dan kos untuk memilih calon contoh peningkatan tertentu. Pengarang merujuk kepada pemilihan calon bermatlamat ini sebagai pengoptimuman dalam penambahan data. Artikel ini terutamanya memperkenalkan tiga strategi: pemilihan kebarangkalian, pemilihan berasaskan model dan pemilihan berasaskan peraturan. Pemilihan kebarangkalian dioptimumkan dengan pensampelan daripada taburan kebarangkalian, manakala pemilihan berasaskan model dipandu oleh model dalam memilih contoh yang paling sesuai. Dalam pemilihan berasaskan peraturan, peraturan atau heuristik yang telah ditetapkan khusus digunakan untuk memilih contoh yang paling sesuai. pemilihan kebarangkalian
: Penulis memilih tiga wakil strategi pemilihan probabilistik dan MHM, Includes BUGLAB-Ogos. MHM menggunakan kaedah persampelan kemungkinan Metropolis-Hastings, teknik Markov Chain Monte Carlo untuk memilih contoh lawan dengan penggantian pengecam. QMDP menggunakan kaedah Q-pembelajaran untuk memilih dan melaksanakan transformasi struktur berasaskan peraturan secara strategik. Pemilihan berasaskan model: Beberapa teknik penambahan data yang menggunakan strategi ini menggunakan maklumat kecerunan model untuk membimbing pemilihan contoh peningkatan. Kaedah biasa ialah kaedah MP penambahan data, yang mengoptimumkan berdasarkan kehilangan model, memilih dan menjana contoh lawan melalui penamaan semula pembolehubah. SPACE memilih dan mengganggu pembenaman pengecam kod melalui pendakian kecerunan, dengan matlamat untuk memaksimumkan kesan prestasi model sambil mengekalkan ketepatan semantik dan sintaksis bahasa pengaturcaraan. Pemilihan berasaskan peraturan : Pemilihan berasaskan peraturan ialah kaedah berkuasa yang menggunakan fungsi atau peraturan kecergasan yang telah ditetapkan. Pendekatan ini selalunya bergantung pada penunjuk keputusan. Sebagai contoh, IRGen menggunakan teknik pengoptimuman berasaskan algoritma genetik dan fungsi kecergasan berdasarkan persamaan IR. Manakala penambahan data ACCENT dan RA R menggunakan metrik penilaian seperti BLEU dan CodeBLEU masing-masing untuk membimbing proses pemilihan dan penggantian untuk mencapai kesan permusuhan yang maksimum. . Mereka bentuk teknik penambahan data yang berkesan untuk menjana contoh musuh bagi mengenal pasti dan mengurangkan kelemahan dalam model kod telah menjadi tempat tumpuan penyelidikan dalam beberapa tahun kebelakangan ini. Pelbagai kajian telah mengukuhkan lagi keteguhan model kod dengan menguji dan meningkatkan keteguhan model menggunakan pelbagai kaedah penambahan data. : Dalam bidang kejuruteraan perisian, sumber bahasa pengaturcaraan tidak seimbang dengan serius. Bahasa pengaturcaraan popular seperti Python dan Java memainkan peranan utama dalam repositori sumber terbuka, manakala banyak bahasa seperti Rust sangat miskin sumber. Model kod sering dilatih berdasarkan repositori dan forum sumber terbuka, dan ketidakseimbangan dalam sumber bahasa pengaturcaraan boleh menjejaskan prestasinya pada bahasa pengaturcaraan yang kekurangan sumber. Menggunakan kaedah penambahan data dalam domain sumber rendah ialah tema yang berulang. Peningkatan pengambilan semula: Dalam bidang pemprosesan dan pengekodan bahasa semula jadi, aplikasi peningkatan data peningkatan perolehan semakin menarik perhatian. Rangka kerja peningkatan perolehan untuk model kod ini menggabungkan contoh peningkatan perolehan semula daripada set latihan semasa pra-latihan atau penalaan halus model kod ini meningkatkan kecekapan parameter model. Pembelajaran Kontrastif: Pembelajaran kontrastif ialah satu lagi bidang aplikasi di mana kaedah penambahan data digunakan dalam senario kod. Ia membolehkan model mempelajari ruang pembenaman di mana sampel yang serupa berada berdekatan antara satu sama lain dan sampel yang tidak serupa berada lebih jauh. Kaedah penambahan data digunakan untuk membina sampel yang serupa dengan sampel positif untuk meningkatkan prestasi model dalam tugas seperti pengesanan kecacatan, pengesanan klon dan carian kod. Artikel berikut membincangkan beberapa tugas pengekodan biasa dan aplikasi usaha penambahan data pada set data penilaian, termasuk pengesanan klon, pengesanan kecacatan dan pembaikan, ringkasan kod, carian kod, penjanaan kod dan terjemahan kod Cabaran dan Peluang Dari segi peningkatan data kod, penulis percaya terdapat banyak cabaran besar. Walau bagaimanapun, cabaran inilah yang membawa kemungkinan baharu dan peluang menarik ke lapangan Perbincangan Teori : Pada masa ini, terdapat jurang yang jelas dalam penerokaan mendalam dan pemahaman teori tentang kaedah penambahan data dalam kod . Kebanyakan penyelidikan sedia ada memfokuskan kepada bidang pemprosesan imej dan bahasa semula jadi, melihat penambahan data sebagai kaedah mengaplikasikan pengetahuan sedia ada tentang data atau invarian tugas. Apabila beralih kepada kod, sementara kerja terdahulu memperkenalkan kaedah baharu atau menunjukkan cara teknik penambahan data boleh berkesan, mereka sering terlepas pandang mengapa dan bagaimana, terutamanya dari perspektif matematik. Sifat diskret kod menjadikan perbincangan teori menjadi lebih penting. Perbincangan teori membolehkan semua orang memahami penambahan data dari perspektif yang lebih luas daripada hanya dari segi hasil percubaan. : Dalam beberapa tahun kebelakangan ini, model kod pra-latihan telah digunakan secara meluas dalam bidang pengekodan, dan pengetahuan yang kaya telah terkumpul melalui penyeliaan sendiri korpora berskala besar. Walaupun banyak kajian telah menggunakan model kod pra-latihan untuk penambahan data, kebanyakan percubaan masih terhad kepada penggantian token topeng atau penjanaan langsung selepas penalaan halus. Mengeksploitasi potensi penambahan data model bahasa berskala besar ialah peluang penyelidikan yang muncul dalam dunia pengekodan. Berbeza dengan cara sebelumnya menggunakan model terlatih dalam peningkatan data, kerja-kerja ini telah membuka era "peningkatan data berasaskan petunjuk". Walau bagaimanapun, penerokaan penambahan data berasaskan petunjuk kekal sebagai kawasan penyelidikan yang agak tidak disentuh dalam dunia kod.
Kandungan yang ditulis semula: Berbeza daripada cara sebelumnya menggunakan model terlatih dalam peningkatan data, kerja-kerja ini membawa kepada era "peningkatan data berasaskan petunjuk". Walau bagaimanapun, dalam domain pengekodan, masih terdapat sedikit kajian tentang penambahan data berasaskan pembayang : Penulis memfokuskan pada menyiasat teknik penambahan data untuk tugas hiliran biasa bagi pemprosesan kod. Walau bagaimanapun, penulis menyedari bahawa masih terdapat sedikit penyelidikan mengenai data khusus tugas lain dalam domain pengekodan. Sebagai contoh, pengesyoran API dan penjanaan jujukan API boleh dianggap sebagai sebahagian daripada tugas pengekodan. Penulis memerhatikan jurang dalam teknik penambahan data antara dua tahap berbeza ini, memberikan peluang untuk kerja masa depan untuk diterokai. Lebih banyak penerokaan kod peringkat projek dan bahasa pengaturcaraan sumber rendah : Kaedah sedia ada dalam fungsi Kemajuan yang mencukupi telah dibuat pada coretan kod tahap dan bahasa pengaturcaraan biasa. Pada masa yang sama, kaedah peningkatan untuk bahasa sumber rendah, walaupun dalam permintaan yang lebih besar, agak terhad. Penerokaan dalam kedua-dua arah ini masih terhad, dan pengarang percaya bahawa mereka mungkin arah yang menjanjikan. mengurangkan berat sebelah sosial : Apabila model kod maju dalam pembangunan perisian, ia mungkin Untuk membangunkan manusia -aplikasi berpusat seperti sumber manusia dan pendidikan, di mana prosedur berat sebelah boleh membawa kepada keputusan yang tidak adil dan tidak beretika untuk populasi yang kurang diwakili. Walaupun berat sebelah sosial dalam NLP telah dikaji dengan baik dan boleh dikurangkan melalui penambahan data, berat sebelah sosial dalam kod masih belum mendapat perhatian. small sample learning: Dalam senario sampel kecil, model perlu dilaksanakan secara berbeza daripada model pembelajaran mesin tradisional Prestasi setanding, tetapi data latihan sangat terhad. Kaedah penambahan data menyediakan penyelesaian yang mudah untuk masalah ini. Walau bagaimanapun, terdapat kerja terhad untuk menggunakan kaedah penambahan data dalam senario sampel kecil. Dalam beberapa contoh senario, penulis merasakan bahawa ini adalah soalan yang menarik tentang cara menyediakan model dengan keupayaan generalisasi dan penyelesaian masalah dengan menjana data tambahan yang berkualiti tinggi. Aplikasi berbilangmodal: Perlu diingatkan bahawa hanya memfokuskan pada kod peringkat fungsi dan Adakah snippets tidak tepat mewakili kerumitan dan nuansa situasi pengaturcaraan dunia sebenar. Dalam kes ini, pembangun biasanya bekerja pada berbilang fail dan folder pada masa yang sama. Walaupun aplikasi multimodal ini semakin popular, tiada penyelidikan telah menggunakan kaedah penambahan data kepada mereka. Salah satu cabaran adalah untuk merapatkan perwakilan pembenaman setiap modaliti dalam model kod secara berkesan, yang telah dikaji dalam tugas multimodal visual-linguistik. kekurangan perpaduan : Kesusasteraan penambahan data kod semasa menyajikan landskap yang paling mencabar, kaedah ini sering dicirikan sebagai tambahan. Beberapa kajian empirikal telah cuba membandingkan kaedah penambahan data untuk model kod. Walau bagaimanapun, kerja-kerja ini tidak mengeksploitasi kebanyakan kaedah penambahan data lanjutan sedia ada. Walaupun rangka kerja penambahan data yang mantap wujud untuk penglihatan komputer (seperti pustaka pembesaran lalai dalam PyTorch) dan NLP (seperti NL-Augmenter), perpustakaan yang sepadan untuk teknik penambahan data tujuan umum untuk model kod jelas tiada. Tambahan pula, memandangkan kaedah penambahan data sedia ada sering dinilai menggunakan pelbagai set data, adalah sukar untuk menentukan keberkesanannya. Oleh itu, penulis percaya bahawa kemajuan penyelidikan penambahan data akan sangat digalakkan dengan mewujudkan tugas penanda aras yang seragam dan bersatu, serta set data untuk membandingkan dan menilai keberkesanan kaedah pembesaran yang berbeza. Ini akan membuka jalan kepada pemahaman yang lebih sistematik dan perbandingan tentang kekuatan dan batasan kaedah ini.
Bidang sumber rendah
Lebih banyak penyelidikan tentang model pra-latihan
Atas ialah kandungan terperinci Penambahan Data Kod dalam Pembelajaran Mendalam: Kajian 89 Penyelidikan dalam 5 Tahun. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!