

 Peranti teknologiAIPerbincangan mendalam tentang aplikasi algoritma persepsi gabungan pelbagai mod dalam pemanduan autonomi
Peranti teknologiAIPerbincangan mendalam tentang aplikasi algoritma persepsi gabungan pelbagai mod dalam pemanduan autonomiPerbincangan mendalam tentang aplikasi algoritma persepsi gabungan pelbagai mod dalam pemanduan autonomi

Sila hubungi sumber untuk mendapatkan kebenaran mencetak semula artikel ini Artikel ini diterbitkan oleh akaun awam Autonomous Driving Heart
1 Pengenalan
Gabungan penderia berbilang modal bermaksud pelengkap maklumat, kestabilan dan keselamatan, yang mempunyai panjang lebar. menjadi kunci kepada automatik Bahagian penting dalam persepsi pemanduan. Walau bagaimanapun, penggunaan maklumat yang tidak mencukupi, hingar dalam data asal dan salah jajaran antara pelbagai penderia (seperti penyegerakan cap masa yang tidak disegerakkan) semuanya telah mengakibatkan prestasi gabungan terhad. Makalah ini secara menyeluruh meninjau algoritma persepsi pemanduan autonomi pelbagai mod sedia ada termasuk LiDAR dan kamera, memfokuskan pada pengesanan sasaran dan segmentasi semantik, serta menganalisis lebih daripada 50 dokumen. Berbeza daripada kaedah pengelasan tradisional algoritma gabungan, kertas ini mengklasifikasikan bidang ini kepada dua kategori utama dan empat subkategori berdasarkan peringkat gabungan yang berbeza. Di samping itu, artikel ini menganalisis masalah sedia ada dalam bidang semasa dan menyediakan rujukan untuk hala tuju penyelidikan masa hadapan.
2 Mengapa multimodaliti diperlukan?
Ini kerana algoritma persepsi mod tunggal mempunyai kelemahan yang wujud. Sebagai contoh, lidar biasanya dipasang lebih tinggi daripada kamera Dalam senario pemanduan kehidupan sebenar yang kompleks, objek mungkin disekat dalam kamera pandangan hadapan Dalam kes ini, adalah mungkin untuk menggunakan lidar untuk menangkap sasaran yang hilang. Walau bagaimanapun, disebabkan oleh batasan struktur mekanikal, LiDAR mempunyai resolusi yang berbeza pada jarak yang berbeza dan mudah dipengaruhi oleh cuaca yang sangat teruk, seperti hujan lebat. Walaupun kedua-dua penderia boleh berfungsi dengan baik apabila digunakan secara bersendirian, dari perspektif masa hadapan, maklumat pelengkap LiDAR dan kamera akan menjadikan pemanduan autonomi lebih selamat pada tahap persepsi.
Baru-baru ini, algoritma persepsi pelbagai mod pemanduan autonomi telah mencapai kemajuan yang besar. Kemajuan ini termasuk perwakilan ciri rentas modal, penderia modal yang lebih dipercayai dan algoritma serta teknik gabungan berbilang modal yang lebih kompleks dan stabil. Walau bagaimanapun, hanya beberapa ulasan [15, 81] menumpukan pada metodologi itu sendiri gabungan multimodal, dan kebanyakan kesusasteraan diklasifikasikan mengikut peraturan pengelasan tradisional, iaitu pra-gabungan, dalam (ciri) gabungan dan pasca-gabungan, dan terutamanya. memfokuskan pada Peringkat gabungan ciri dalam algoritma, sama ada tahap data, tahap ciri atau tahap cadangan. Terdapat dua masalah dengan peraturan pengelasan ini: pertama, perwakilan ciri setiap tahap tidak ditakrifkan dengan jelas kedua, ia merawat dua cabang lidar dan kamera dari perspektif simetri, sekali gus mengaburkan hubungan antara gabungan ciri dan gabungan ciri dalam Cawangan LiDAR Kes gabungan ciri peringkat data dalam cawangan kamera. Ringkasnya, walaupun kaedah klasifikasi tradisional adalah intuitif, ia tidak lagi sesuai untuk pembangunan algoritma gabungan pelbagai mod semasa, yang pada tahap tertentu menghalang penyelidik daripada menjalankan penyelidikan dan analisis dari perspektif sistem
3 tugas dan awam pertandingan
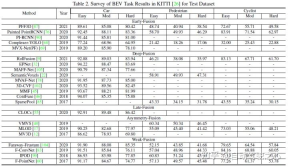
Tugas persepsi biasa termasuk pengesanan sasaran, pembahagian semantik, penyiapan kedalaman dan ramalan, dsb. Artikel ini memfokuskan pada pengesanan dan pembahagian, seperti pengesanan halangan, lampu isyarat, tanda lalu lintas dan pembahagian garis lorong dan ruang bebas. Tugas persepsi pemanduan autonomi ditunjukkan dalam rajah berikut:

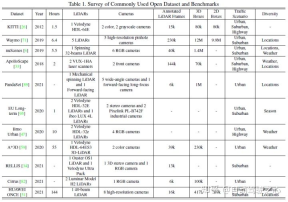
Set data awam biasa terutamanya termasuk KITTI, Waymo dan nuScenes Angka berikut meringkaskan set data berkaitan persepsi pemanduan autonomi dan ciri-cirinya
. Kaedah fusion
Multimodal fusion tidak dapat dipisahkan daripada bentuk ekspresi data Perwakilan data cawangan imej adalah agak mudah, secara amnya merujuk kepada format RGB atau imej skala kelabu Walau bagaimanapun, cawangan lidar mempunyai pergantungan yang tinggi pada format data, dan format data yang berbeza diperolehi Reka bentuk model hiliran yang berbeza sama sekali dicadangkan, yang secara ringkasnya merangkumi tiga arah umum: perwakilan awan titik berdasarkan titik, pemetaan berasaskan voxel dan dua dimensi.
- Kaedah klasifikasi tradisional membahagikan gabungan pelbagai mod kepada tiga jenis berikut:
- Pra-gabungan (gabungan peringkat data) merujuk kepada gabungan langsung data sensor mentah dari modaliti yang berbeza melalui penjajaran ruang.
- Penyatuan mendalam (gabungan peringkat ciri) merujuk kepada gabungan data rentas modal dalam ruang ciri melalui lata atau pendaraban unsur.
5 Gabungan kuat
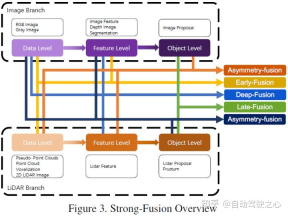
Mengikut peringkat gabungan berbeza yang diwakili oleh data lidar dan kamera, artikel ini membahagikan gabungan kuat kepada: pelakuran hadapan, pelakuran dalam, pelakuran asimetri dan selepas gabungan. Seperti yang ditunjukkan dalam rajah di atas, dapat dilihat bahawa setiap submodul gabungan kuat sangat bergantung pada awan titik lidar dan bukannya data kamera.
Pra-gabungan
Berbeza daripada definisi gabungan peringkat data tradisional, iaitu kaedah yang secara langsung menggabungkan setiap data modaliti melalui penjajaran dan unjuran ruang pada tahap data asal, gabungan awal menggabungkan data LiDAR dan data LiDAR di tahap data Data kamera tahap data atau tahap ciri. Contoh gabungan awal boleh menjadi model dalam Rajah 4. Kandungan yang ditulis semula: Berbeza daripada definisi gabungan peringkat data tradisional, iaitu kaedah untuk menggabungkan secara langsung setiap data modaliti melalui penjajaran ruang dan unjuran pada tahap data asal. Gabungan awal merujuk kepada gabungan data LiDAR dan data kamera atau data peringkat ciri pada peringkat data. Model dalam Rajah 4 ialah contoh pelakuran awal
Berbeza daripada pra-gabungan yang ditakrifkan oleh kaedah pengelasan tradisional, pra-gabungan yang ditakrifkan dalam artikel ini merujuk kepada kaedah menggabungkan secara langsung setiap data modal melalui penjajaran ruang dan unjuran pada tahap data asal. Pada peringkat data, ia merujuk kepada gabungan data lidar, dan pada tahap data atau tahap ciri, data imej adalah seperti berikut:
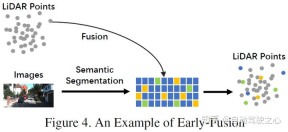
Dalam LiDAR. cawangan, awan titik mempunyai banyak kaedah ekspresi, seperti peta pantulan dan imej bersuara Pengukuran, pandangan hadapan/pandangan jarak/pandangan BEV dan awan titik pseudo, dsb. Walaupun data ini mempunyai ciri intrinsik yang berbeza dalam rangkaian tulang belakang yang berbeza, kecuali awan titik pseudo [79], kebanyakan data dijana melalui pemprosesan peraturan tertentu. Di samping itu, berbanding dengan pembenaman ruang ciri, data LiDAR ini sangat boleh ditafsirkan dan boleh divisualisasikan secara langsung Dalam cabang imej, definisi peringkat data dalam erti kata yang ketat merujuk kepada imej RGB atau skala kelabu, tetapi Takrifan ini tidak mempunyai kesejagatan dan rasional. Oleh itu, kertas kerja ini memperluaskan definisi peringkat data bagi data imej dalam peringkat pra-gabungan untuk memasukkan data peringkat data dan peringkat ciri. Perlu dinyatakan bahawa artikel ini juga menganggap hasil ramalan pembahagian semantik sebagai jenis pra-gabungan (tahap ciri imej Di satu pihak, ia berguna untuk pengesanan sasaran 3D, dan sebaliknya, ia adalah kerana). daripada "tahap sasaran" pembahagian semantik Ciri adalah berbeza daripada cadangan peringkat sasaran akhir bagi keseluruhan tugasan
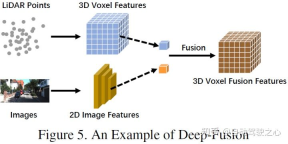
Penyatuan DalamPenyatuan dalam, juga dipanggil gabungan peringkat ciri, merujuk kepada gabungan pelbagai modal. data pada tahap ciri cawangan lidar, tetapi bukan data dalam gabungan cawangan imej pada tahap set dan ciri. Sebagai contoh, beberapa kaedah menggunakan pengangkatan ciri untuk mendapatkan perwakilan pembenaman awan titik LiDAR dan imej masing-masing, dan menggabungkan ciri dua modaliti melalui satu siri modul hiliran. Walau bagaimanapun, tidak seperti gabungan kuat yang lain, gabungan dalam kadangkala menggabungkan ciri secara berlata, yang kedua-duanya mengeksploitasi maklumat semantik mentah dan peringkat tinggi. Gambarajah skematik adalah seperti berikut:
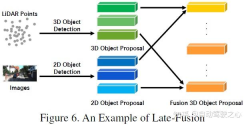
Post-fusion, yang juga boleh dipanggil target-level fusion, merujuk kepada gabungan hasil ramalan (atau cadangan) pelbagai modaliti. Sebagai contoh, beberapa kaedah pasca gabungan menggunakan output awan titik LiDAR dan imej untuk gabungan [55]. Format data cadangan untuk kedua-dua cawangan hendaklah konsisten dengan keputusan akhir, tetapi mungkin terdapat perbezaan dalam kualiti, kuantiti dan ketepatan. Selepas gabungan boleh dilihat sebagai kaedah penyepaduan untuk pengoptimuman maklumat berbilang mod bagi cadangan akhir Gambarajah skematik adalah seperti berikut:
Jenis gabungan kuat yang terakhir ialah gabungan asimetrik, yang mana merujuk kepada Ia adalah untuk menggabungkan maklumat peringkat sasaran satu cawangan dengan maklumat peringkat data atau peringkat ciri cawangan lain. Tiga kaedah gabungan di atas merawat setiap cabang pelbagai modaliti secara sama rata, manakala gabungan asimetri menekankan bahawa sekurang-kurangnya satu cabang adalah dominan, dan cawangan lain menyediakan maklumat tambahan untuk meramalkan hasil akhir. Rajah di bawah ialah gambarajah skema pelakuran asimetri Dalam peringkat cadangan, pelakuran asimetri hanya mempunyai cadangan satu cabang, dan kemudian gabungan adalah cadangan semua cawangan.
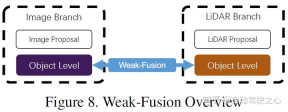
6 Perbezaan antara pelakuran lemah
dan pelakuran kuat ialah kaedah pelakuran lemah tidak secara langsung menggabungkan data, ciri atau sasaran daripada cawangan pelbagai mod, tetapi memproses data dalam bentuk lain. Rajah di bawah menunjukkan rangka kerja asas algoritma pelakuran lemah. Kaedah berdasarkan gabungan lemah biasanya menggunakan kaedah berasaskan peraturan tertentu untuk menggunakan data daripada satu modaliti sebagai isyarat penyeliaan untuk membimbing interaksi modaliti yang lain. Sebagai contoh, cadangan 2D daripada CNN dalam cawangan imej mungkin menyebabkan pemangkasan dalam awan titik LiDAR asal dan gabungan yang lemah secara langsung memasukkan awan titik LiDAR asal ke dalam tulang belakang LiDAR untuk mengeluarkan cadangan akhir.
7 Kaedah gabungan yang lain
Terdapat juga beberapa karya yang tidak tergolong dalam mana-mana paradigma di atas kerana menggunakan pelbagai kaedah gabungan dalam rangka reka bentuk model, seperti [39] yang menggabungkan deep gabungan dan pasca-pemprosesan Fusion,[77] menggabungkan pra-gabungan. Kaedah ini bukan kaedah utama reka bentuk algoritma gabungan, dan artikel ini disatukan ke dalam kaedah gabungan lain.
8 Peluang gabungan pelbagai mod
Dalam beberapa tahun kebelakangan ini, kaedah gabungan pelbagai mod untuk tugas persepsi pemanduan autonomi telah mencapai kemajuan pesat, daripada perwakilan ciri yang lebih maju kepada model pembelajaran mendalam yang lebih kompleks. Walau bagaimanapun, masih terdapat beberapa isu tertunggak yang perlu diselesaikan Artikel ini meringkaskan beberapa kemungkinan arah penambahbaikan pada masa hadapan seperti berikut.
Kaedah gabungan yang lebih maju
Model gabungan semasa mempunyai masalah dengan salah jajaran dan kehilangan maklumat [13, 67, 98]. Selain itu, operasi gabungan rata juga menghalang peningkatan selanjutnya dalam prestasi tugasan persepsi. Ringkasannya adalah seperti berikut:
- Dislokasi dan kehilangan maklumat: Perbezaan dalaman dan luaran antara kamera dan LiDAR adalah sangat besar, dan data kedua-dua mod perlu diselaraskan. Kaedah cantuman depan dan cantuman dalam tradisional menggunakan maklumat penentukuran untuk menayangkan semua titik LiDAR terus ke dalam sistem koordinat kamera dan sebaliknya. Walau bagaimanapun, disebabkan oleh lokasi pemasangan dan hingar penderia, penjajaran piksel demi piksel ini tidak cukup tepat. Oleh itu, sesetengah karya menggunakan maklumat sekeliling untuk menambahnya bagi memperoleh prestasi yang lebih baik. Di samping itu, beberapa maklumat lain hilang semasa proses penukaran ruang input dan ciri. Biasanya, unjuran operasi pengurangan dimensi tidak dapat dielakkan membawa kepada sejumlah besar kehilangan maklumat, seperti kehilangan maklumat ketinggian dalam memetakan awan titik LiDAR 3D kepada imej BEV 2D. Oleh itu, anda boleh mempertimbangkan untuk memetakan data berbilang modal ke ruang dimensi tinggi lain yang direka bentuk untuk gabungan, supaya dapat menggunakan data asal dengan berkesan dan mengurangkan kehilangan maklumat.
- Operasi gabungan yang lebih munasabah: Banyak kaedah semasa menggunakan lata atau pendaraban unsur untuk pelakuran. Operasi mudah ini mungkin gagal untuk menggabungkan data dengan pengedaran yang berbeza secara meluas, menjadikannya sukar untuk menyesuaikan anjing merah semantik antara kedua-dua modaliti. Sesetengah kerja cuba menggunakan struktur lata yang lebih kompleks untuk menggabungkan data dan meningkatkan prestasi. Dalam penyelidikan masa depan, mekanisme seperti pemetaan bilinear boleh mengintegrasikan ciri dengan ciri yang berbeza dan juga merupakan arah yang boleh dipertimbangkan.
Penggunaan maklumat berbilang sumber
Imej bingkai tunggal yang berpandangan ke hadapan ialah senario biasa untuk tugas persepsi pemanduan autonomi. Walau bagaimanapun, kebanyakan rangka kerja hanya boleh menggunakan maklumat terhad dan tidak mereka bentuk tugas tambahan secara terperinci untuk memudahkan pemahaman senario pemanduan. Ringkasannya adalah seperti berikut:
- Gunakan lebih banyak maklumat berpotensi: Kaedah sedia ada kekurangan penggunaan maklumat yang berkesan daripada pelbagai dimensi dan sumber. Kebanyakan tertumpu pada data berbilang modal bingkai tunggal dalam paparan hadapan. Ini mengakibatkan data bermakna lain kurang digunakan, seperti maklumat konteks semantik, ruang dan adegan. Sesetengah kerja cuba menggunakan hasil pembahagian semantik untuk membantu tugasan, manakala model lain berpotensi mengeksploitasi ciri lapisan perantaraan tulang belakang CNN. Dalam senario pemanduan autonomi, banyak tugas hiliran dengan maklumat semantik eksplisit boleh meningkatkan prestasi pengesanan objek dengan banyak, seperti pengesanan garisan lorong, lampu isyarat dan tanda lalu lintas. Penyelidikan masa depan boleh menggabungkan tugas hiliran untuk bersama-sama membina rangka kerja pemahaman semantik yang lengkap untuk pemandangan bandar untuk meningkatkan prestasi persepsi. Tambahan pula, [63] menggabungkan maklumat antara bingkai untuk meningkatkan prestasi. Maklumat siri masa mengandungi isyarat pemantauan bersiri, yang boleh memberikan hasil yang lebih stabil berbanding kaedah bingkai tunggal. Oleh itu, kerja masa depan boleh mempertimbangkan untuk mengeksploitasi maklumat temporal, kontekstual dan ruang dengan lebih mendalam untuk mencapai kejayaan prestasi.
- Pembelajaran perwakilan seliaan sendiri: Isyarat seliaan bersama secara semula jadi wujud dalam data rentas modal yang disampel dari adegan dunia sebenar yang sama tetapi dari sudut yang berbeza. Walau bagaimanapun, disebabkan oleh kekurangan pemahaman yang mendalam tentang data, kaedah semasa tidak dapat melombong perkaitan antara pelbagai modaliti. Penyelidikan masa depan boleh menumpukan pada cara menggunakan data berbilang modal untuk pembelajaran penyeliaan kendiri, termasuk pra-latihan, penalaan halus atau pembelajaran kontrastif. Melalui mekanisme tercanggih ini, algoritma gabungan akan memperdalam pemahaman model yang lebih mendalam tentang data sambil mencapai prestasi yang lebih baik.
Isu Penderia Inherent
Adegan dunia sebenar dan ketinggian penderia boleh menjejaskan bias dan peleraian domain. Kekurangan ini akan menghalang latihan berskala besar dan operasi masa nyata model pembelajaran mendalam pemanduan autonomi
- Bidang domain: Dalam senario persepsi pemanduan autonomi, data mentah yang diekstrak oleh penderia berbeza disertakan dengan ciri berkaitan domain yang teruk. Kamera yang berbeza mempunyai sifat optik yang berbeza, dan LiDAR boleh berbeza daripada struktur mekanikal kepada keadaan pepejal. Lebih-lebih lagi, data itu sendiri akan mempunyai bias domain, seperti cuaca, musim atau lokasi geografi, walaupun ia ditangkap oleh penderia yang sama. Ini menyebabkan generalisasi model pengesanan terjejas dan tidak dapat menyesuaikan diri dengan senario baharu dengan berkesan. Kelemahan sedemikian menghalang pengumpulan set data berskala besar dan kebolehgunaan semula data latihan asal. Oleh itu, masa depan boleh menumpukan pada mencari kaedah untuk menghapuskan bias domain dan menyepadukan sumber data yang berbeza secara adaptif.
- Konflik Penyelesaian: Penderia yang berbeza biasanya mempunyai resolusi yang berbeza. Sebagai contoh, ketumpatan ruang LiDAR jauh lebih rendah daripada imej. Tidak kira kaedah unjuran yang digunakan, kehilangan maklumat akan berlaku kerana hubungan yang sepadan tidak dapat ditemui. Ini mungkin mengakibatkan model dikuasai oleh data satu modaliti tertentu, sama ada disebabkan resolusi vektor ciri yang berbeza atau ketidakseimbangan dalam maklumat mentah. Oleh itu, kerja masa hadapan boleh meneroka sistem perwakilan data baharu yang serasi dengan penderia resolusi spatial yang berbeza.
9 Rujukan
[1] https://zhuanlan.zhihu.com/p/470588787
[2] Gabungan Penderia Berbilang Modal untuk Persepsi Pemanduan Auto: Satu Tinjauan
 Pautan Origina
Pautan Origina
: https ://mp.weixin.qq.com/s/usAQRL18vww9YwMXRvEwLw
Atas ialah kandungan terperinci Perbincangan mendalam tentang aplikasi algoritma persepsi gabungan pelbagai mod dalam pemanduan autonomi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Cara Membina Pembantu AI Peribadi Anda Dengan Huggingface SmollmApr 18, 2025 am 11:52 AM
Cara Membina Pembantu AI Peribadi Anda Dengan Huggingface SmollmApr 18, 2025 am 11:52 AMMemanfaatkan kuasa AI di peranti: Membina CLI Chatbot Peribadi Pada masa lalu, konsep pembantu AI peribadi kelihatan seperti fiksyen sains. Bayangkan Alex, seorang peminat teknologi, bermimpi seorang sahabat AI yang pintar, yang tidak bergantung
 AI untuk Kesihatan Mental dianalisis dengan penuh perhatian melalui inisiatif baru yang menarik di Stanford UniversityApr 18, 2025 am 11:49 AM
AI untuk Kesihatan Mental dianalisis dengan penuh perhatian melalui inisiatif baru yang menarik di Stanford UniversityApr 18, 2025 am 11:49 AMPelancaran AI4MH mereka berlaku pada 15 April, 2025, dan Luminary Dr. Tom Insel, M.D., pakar psikiatri yang terkenal dan pakar neurosains, berkhidmat sebagai penceramah kick-off. Dr. Insel terkenal dengan kerja cemerlangnya dalam penyelidikan kesihatan mental dan techno
 Kelas Draf WNBA 2025 memasuki liga yang semakin meningkat dan melawan gangguan dalam talianApr 18, 2025 am 11:44 AM
Kelas Draf WNBA 2025 memasuki liga yang semakin meningkat dan melawan gangguan dalam talianApr 18, 2025 am 11:44 AM"Kami mahu memastikan bahawa WNBA kekal sebagai ruang di mana semua orang, pemain, peminat dan rakan kongsi korporat, berasa selamat, dihargai dan diberi kuasa," kata Engelbert, menangani apa yang telah menjadi salah satu cabaran sukan wanita yang paling merosakkan. Anno
 Panduan Komprehensif untuk Struktur Data Terbina Python - Analytics VidhyaApr 18, 2025 am 11:43 AM
Panduan Komprehensif untuk Struktur Data Terbina Python - Analytics VidhyaApr 18, 2025 am 11:43 AMPengenalan Python cemerlang sebagai bahasa pengaturcaraan, terutamanya dalam sains data dan AI generatif. Manipulasi data yang cekap (penyimpanan, pengurusan, dan akses) adalah penting apabila berurusan dengan dataset yang besar. Kami pernah meliputi nombor dan st
 Tayangan pertama dari model baru Openai berbanding dengan alternatifApr 18, 2025 am 11:41 AM
Tayangan pertama dari model baru Openai berbanding dengan alternatifApr 18, 2025 am 11:41 AMSebelum menyelam, kaveat penting: Prestasi AI adalah spesifik yang tidak ditentukan dan sangat digunakan. Dalam istilah yang lebih mudah, perbatuan anda mungkin berbeza -beza. Jangan ambil artikel ini (atau lain -lain) sebagai perkataan akhir -sebaliknya, uji model ini pada senario anda sendiri
 AI Portfolio | Bagaimana untuk membina portfolio untuk kerjaya AI?Apr 18, 2025 am 11:40 AM
AI Portfolio | Bagaimana untuk membina portfolio untuk kerjaya AI?Apr 18, 2025 am 11:40 AMMembina portfolio AI/ML yang menonjol: Panduan untuk Pemula dan Profesional Mewujudkan portfolio yang menarik adalah penting untuk mendapatkan peranan dalam kecerdasan buatan (AI) dan pembelajaran mesin (ML). Panduan ini memberi nasihat untuk membina portfolio
 AI AI apa yang boleh dimaksudkan untuk operasi keselamatanApr 18, 2025 am 11:36 AM
AI AI apa yang boleh dimaksudkan untuk operasi keselamatanApr 18, 2025 am 11:36 AMHasilnya? Pembakaran, ketidakcekapan, dan jurang yang melebar antara pengesanan dan tindakan. Tak satu pun dari ini harus datang sebagai kejutan kepada sesiapa yang bekerja dalam keselamatan siber. Janji Agentic AI telah muncul sebagai titik perubahan yang berpotensi. Kelas baru ini
 Google Versus Openai: AI berjuang untuk pelajarApr 18, 2025 am 11:31 AM
Google Versus Openai: AI berjuang untuk pelajarApr 18, 2025 am 11:31 AMImpak segera berbanding perkongsian jangka panjang? Dua minggu yang lalu Openai melangkah ke hadapan dengan tawaran jangka pendek yang kuat, memberikan akses kepada pelajar A.S. dan Kanada.


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

DVWA
Damn Vulnerable Web App (DVWA) ialah aplikasi web PHP/MySQL yang sangat terdedah. Matlamat utamanya adalah untuk menjadi bantuan bagi profesional keselamatan untuk menguji kemahiran dan alatan mereka dalam persekitaran undang-undang, untuk membantu pembangun web lebih memahami proses mengamankan aplikasi web, dan untuk membantu guru/pelajar mengajar/belajar dalam persekitaran bilik darjah Aplikasi web keselamatan. Matlamat DVWA adalah untuk mempraktikkan beberapa kelemahan web yang paling biasa melalui antara muka yang mudah dan mudah, dengan pelbagai tahap kesukaran. Sila ambil perhatian bahawa perisian ini

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

SublimeText3 versi Inggeris
Disyorkan: Versi Win, menyokong gesaan kod!

ZendStudio 13.5.1 Mac
Persekitaran pembangunan bersepadu PHP yang berkuasa

PhpStorm versi Mac
Alat pembangunan bersepadu PHP profesional terkini (2018.2.1).

