
Rumah >Peranti teknologi >AI >Adakah model 13B mempunyai kelebihan dalam pertarungan penuh dengan GPT-4? Adakah terdapat beberapa keadaan luar biasa di sebaliknya?
Adakah model 13B mempunyai kelebihan dalam pertarungan penuh dengan GPT-4? Adakah terdapat beberapa keadaan luar biasa di sebaliknya?

- PHPzke hadapan
- 2023-11-18 11:39:051388semak imbas
Bolehkah model dengan parameter 13B mengalahkan GPT-4 teratas? Seperti yang ditunjukkan dalam rajah di bawah, untuk memastikan kesahihan keputusan, ujian ini juga mengikuti kaedah penyahnodahan data OpenAI dan tidak menemui bukti pencemaran data
#🎜🎜 #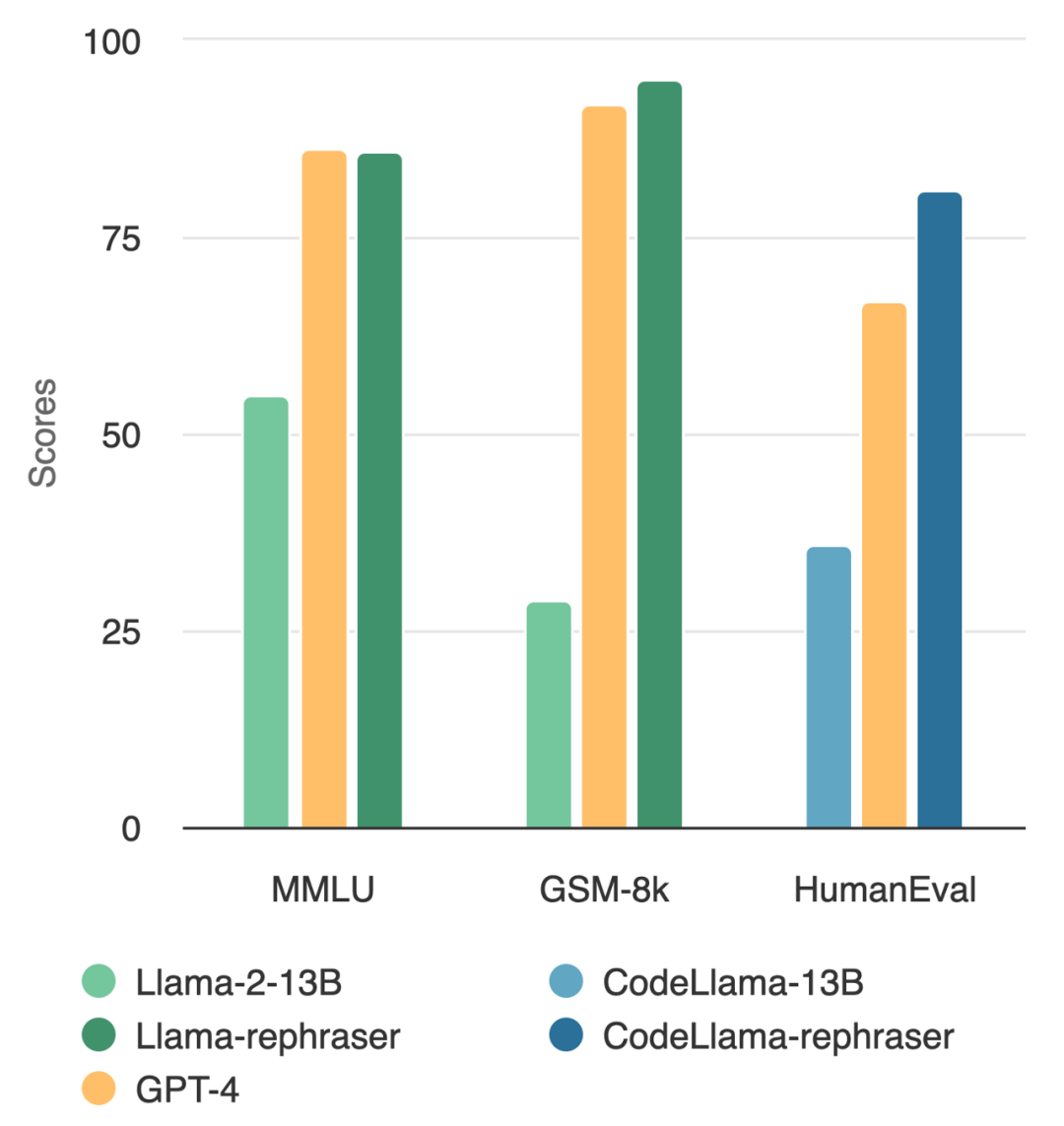
Perhatikan model dalam gambar, anda akan dapati selagi perkataan "rephraser" disertakan, prestasi model tersebut agak tinggi
Apakah rahsia di sebalik ini? Ternyata data itu tercemar, iaitu maklumat set ujian bocor dalam set latihan, dan pencemaran ini tidak mudah dikesan. Walaupun isu ini penting, memahami dan mengesan pencemaran kekal sebagai teka-teki yang terbuka dan mencabar.
Pada peringkat ini, kaedah yang paling biasa digunakan untuk penyahcemaran ialah pertindihan n-gram dan carian persamaan terbenam: Pertindihan N-gram bergantung pada padanan rentetan untuk mengesan pencemaran, yang ialah Pendekatan biasa untuk model seperti GPT-4, PaLM dan Llama-2 membenamkan carian persamaan menggunakan pembenaman daripada model pra-latihan seperti BERT untuk mencari contoh yang serupa dan berpotensi tercemar.
Walau bagaimanapun, penyelidikan dari UC Berkeley dan Shanghai Jiao Tong University menunjukkan bahawa perubahan mudah dalam data ujian (cth., menulis semula, terjemahan) boleh memintas kaedah pengesanan sedia ada dengan mudah. Mereka merujuk kepada variasi kes ujian seperti "Sampel Difrasa Semula".
Berikut ialah kandungan yang perlu ditulis semula dalam ujian penanda aras MMLU: hasil demonstrasi sampel yang ditulis semula. Keputusan menunjukkan bahawa model 13B boleh mencapai prestasi yang sangat tinggi (MMLU 85.9) jika sampel tersebut dimasukkan ke dalam set latihan. Malangnya, kaedah pengesanan sedia ada seperti pertindihan n-gram dan kesamaan benam tidak dapat mengesan pencemaran ini. Sebagai contoh, membenamkan kaedah persamaan mengalami kesukaran membezakan soalan yang diutarakan semula daripada soalan lain dalam topik yang sama Sama seperti teknik penulisan semula, kami melihat hasil yang konsisten pada pengekodan dan tanda aras matematik yang digunakan secara meluas, seperti HumanEval dan GSM-8K (ditunjukkan dalam rajah di permulaan artikel). Oleh itu, dapat mengesan kandungan sedemikian yang perlu ditulis semula: sampel yang ditulis semula menjadi penting.
Seterusnya, mari kita lihat bagaimana kajian itu dijalankan. 
#🎜🎜🎜##🎜🎜🎜#

- Alamat projek: https://github.com/lm -sys/llm-decontaminator#detect
- kertas pengenalan#🎜#🎜
Untuk menyelesaikan masalah ini, sesetengah orang menggunakan kaedah dekontaminasi tradisional seperti padanan rentetan (seperti pertindihan n-gram) untuk memadam data penanda aras. Walau bagaimanapun, operasi ini masih jauh dari mencukupi, kerana langkah sanitasi ini boleh dipintas dengan mudah dengan hanya membuat beberapa perubahan mudah pada data ujian (cth., menulis semula, terjemahan)
#🎜🎜 # Jika perubahan dalam data ujian ini tidak dihapuskan, model 13B boleh dengan mudah mengatasi penanda aras ujian dan mencapai prestasi setanding dengan GPT-4, yang lebih penting. Para penyelidik mengesahkan pemerhatian ini pada penanda aras seperti MMLU, GSK8k dan HumanEval
Pada masa yang sama, untuk menangani risiko yang semakin meningkat ini, kertas kerja ini juga mencadangkan LLM yang lebih berkuasa -kaedah penyahcemaran berasaskan LLM dekontaminasi digunakan pada set data pra-latihan dan penalaan halus Keputusan menunjukkan bahawa kaedah LLM yang dicadangkan dalam artikel ini adalah lebih baik daripada kaedah sedia ada dalam memadam kandungan yang perlu ditulis semula: sampel ditulis semula.
Pendekatan ini turut mendedahkan beberapa pertindihan ujian yang tidak diketahui sebelum ini. Contohnya, dalam set pra-latihan seperti RedPajamaData-1T dan StarCoder-Data, kami mendapati 8-18% bertindih dengan penanda aras HumanEval. Di samping itu, kertas ini juga menemui pencemaran ini dalam set data sintetik yang dihasilkan oleh GPT-3.5/4, yang juga menggambarkan potensi risiko pencemaran tidak sengaja dalam bidang AI.
Kami berharap melalui artikel ini, kami menyeru masyarakat untuk menggunakan kaedah penulenan yang lebih berkuasa apabila menggunakan penanda aras awam, dan secara aktif membangunkan kes ujian sekali baharu untuk menilai model dengan tepat
Apa yang perlu ditulis semula ialah: Tulis semula sampel
Matlamat artikel ini adalah untuk menyiasat sama ada perubahan mudah dalam memasukkan set ujian dalam set latihan akan menjejaskan prestasi penanda aras akhir, dan memanggil perubahan ini dalam kes ujian "apa yang perlu ditulis semula ialah: tulis semula sampel". Pelbagai bidang penanda aras, termasuk matematik, pengetahuan dan pengekodan, telah dipertimbangkan dalam eksperimen. Contoh 1 ialah kandungan daripada GSM-8k yang perlu ditulis semula: sampel yang ditulis semula dengan pertindihan 10 gram tidak dapat dikesan dan teks yang diubah suai mengekalkan semantik yang sama seperti teks asal.

Terdapat sedikit perbezaan dalam teknologi penulisan semula untuk pelbagai bentuk pencemaran garis dasar. Dalam ujian penanda aras berasaskan teks, kertas kerja ini menulis semula kes ujian dengan menyusun semula susunan perkataan atau menggunakan penggantian sinonim untuk mencapai tujuan tidak mengubah semantik. Dalam ujian penanda aras berasaskan kod, artikel ini ditulis semula dengan menukar gaya pengekodan, kaedah penamaan, dsb. Seperti yang ditunjukkan di bawah, algoritma ringkas dicadangkan dalam Algoritma 1 untuk set ujian yang diberikan. Kaedah ini boleh membantu sampel ujian mengelakkan pengesanan.
 Seterusnya, kertas kerja ini mencadangkan kaedah pengesanan pencemaran baharu yang boleh mengalih keluar kandungan yang perlu ditulis semula dengan tepat daripada set data berbanding garis dasar: tulis semula sampel.
Seterusnya, kertas kerja ini mencadangkan kaedah pengesanan pencemaran baharu yang boleh mengalih keluar kandungan yang perlu ditulis semula dengan tepat daripada set data berbanding garis dasar: tulis semula sampel.
Secara khusus, artikel ini memperkenalkan penyahcemar LLM. Pertama, bagi setiap kes ujian, ia menggunakan carian persamaan pembenaman untuk mengenal pasti item latihan teratas dengan persamaan tertinggi, selepas itu setiap pasangan dinilai oleh LLM (cth., GPT-4) sama ada item latihan tersebut adalah sama. Pendekatan ini membantu menentukan jumlah set data yang perlu ditulis semula: sampel tulis semula.
Gambarajah Venn bagi pencemaran yang berbeza dan kaedah pengesanan yang berbeza ditunjukkan dalam Rajah 4
Eksperimen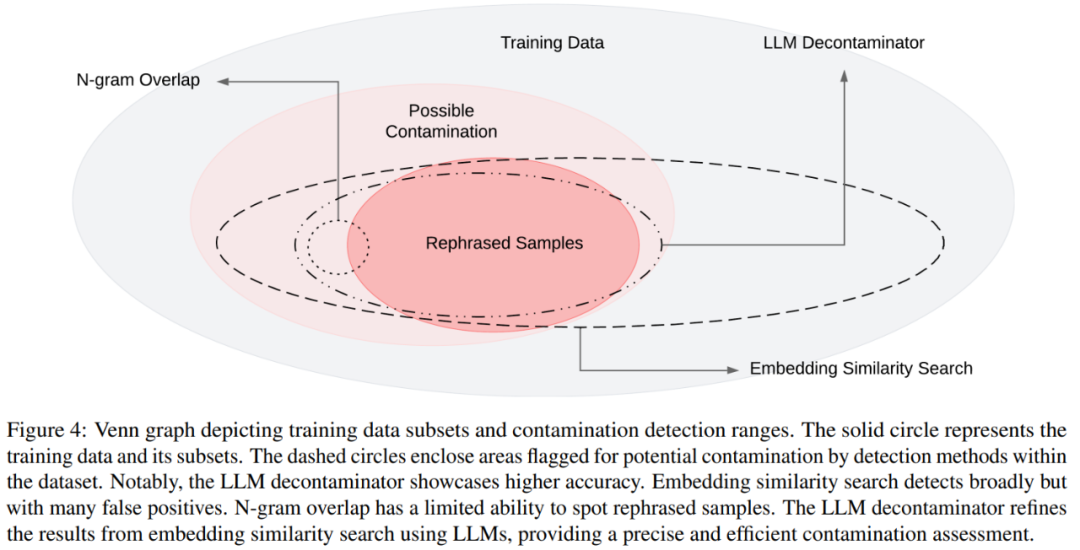
5 yang perlu dilatih semula. Dalam Bahagian 5, apa yang perlu dilatih untuk dibuktikan. pada sampel yang ditulis semula boleh mencapai skor yang tinggi dengan ketara, mencapai prestasi yang setanding dengan GPT-4 pada tiga penanda aras yang digunakan secara meluas (MMLU, HumanEval dan GSM-8k), mencadangkan bahawa perkara yang perlu ditulis semula ialah: Sampel yang ditulis semula harus dianggap sebagai pencemaran dan harus dikeluarkan daripada data latihan. Dalam Bahagian 5.2, perkara yang perlu ditulis semula dalam artikel ini mengikut MMLU/HumanEval ialah: tulis semula sampel untuk menilai kaedah pengesanan pencemaran yang berbeza. Dalam Bahagian 5.3, kami menggunakan penyahcemar LLM pada set latihan yang digunakan secara meluas dan menemui pencemaran yang tidak diketahui sebelum ini.
Mari kita lihat beberapa keputusan utama seterusnya
Kandungan yang perlu ditulis semula ialah: Tulis semula sampel standard pencemaran
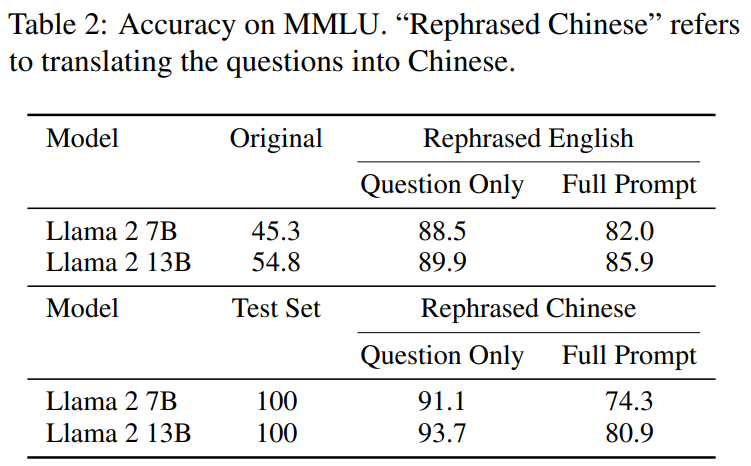
yang perlu ditulis semula dalam Jadual 2. ialah: Tulis semula Llama-2 7B dan 13B yang dilatih pada sampel mencapai skor tinggi yang ketara pada MMLU, daripada 45.3 hingga 88.5. Ini menunjukkan bahawa sampel yang ditulis semula mungkin sangat memesongkan data garis dasar dan harus dianggap sebagai pencemaran.
 Artikel ini juga menulis semula set ujian HumanEval dan menterjemahkannya ke dalam lima bahasa pengaturcaraan: C, JavaScript, Rust, Go dan Java. Keputusan menunjukkan bahawa CodeLlama 7B dan 13B yang dilatih pada sampel yang ditulis semula boleh mencapai skor yang sangat tinggi pada HumanEval, antara 32.9 hingga 67.7 dan 36.0 hingga 81.1 masing-masing. Sebagai perbandingan, GPT-4 hanya boleh mencapai 67.0 pada HumanEval.
Artikel ini juga menulis semula set ujian HumanEval dan menterjemahkannya ke dalam lima bahasa pengaturcaraan: C, JavaScript, Rust, Go dan Java. Keputusan menunjukkan bahawa CodeLlama 7B dan 13B yang dilatih pada sampel yang ditulis semula boleh mencapai skor yang sangat tinggi pada HumanEval, antara 32.9 hingga 67.7 dan 36.0 hingga 81.1 masing-masing. Sebagai perbandingan, GPT-4 hanya boleh mencapai 67.0 pada HumanEval.
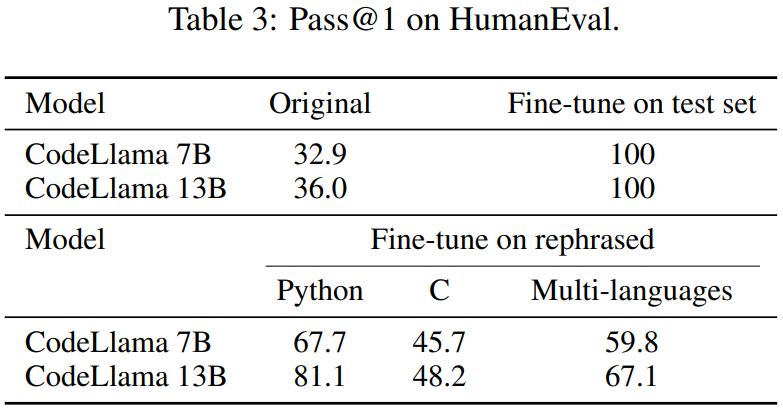 Jadual 4 di bawah mencapai kesan yang sama:
Jadual 4 di bawah mencapai kesan yang sama:
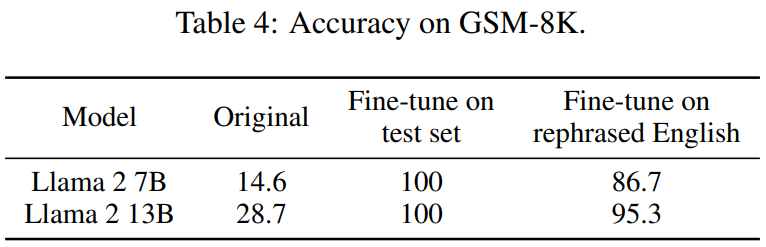
Penilaian kaedah pengesanan untuk pencemaran
Seperti yang ditunjukkan dalam Jadual 5, kecuali penyahcemar LLM, semua kaedah pengesanan lain memperkenalkan beberapa positif palsu. Sama ada sampel yang ditulis semula atau diterjemahkan tidak dikesan oleh pertindihan n-gram. Menggunakan BERT multi-qa, membenamkan carian persamaan terbukti tidak berkesan sama sekali pada sampel yang diterjemahkan.状 Status pencemaran set data

Dalam Jadual 7, peratusan pencemaran data pencemaran data setiap set data latihan didedahkan 79 Satu-satunya kandungan yang perlu ditulis semula ialah: contoh sampel yang ditulis semula, menyumbang 1.58% daripada set ujian MATH. Contoh 5 ialah penyesuaian ujian MATH pada data latihan MATH.
Sila semak kertas asal untuk maklumat lanjut
Atas ialah kandungan terperinci Adakah model 13B mempunyai kelebihan dalam pertarungan penuh dengan GPT-4? Adakah terdapat beberapa keadaan luar biasa di sebaliknya?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!