
Rumah >Peranti teknologi >AI >Selepas penyulingan Whisper OpenAI, kelajuan pengecaman pertuturan telah dipertingkatkan dengan ketara: bilangan bintang melebihi 1,000 dalam dua hari
Selepas penyulingan Whisper OpenAI, kelajuan pengecaman pertuturan telah dipertingkatkan dengan ketara: bilangan bintang melebihi 1,000 dalam dua hari

- PHPzke hadapan
- 2023-11-05 11:25:061501semak imbas
Baru-baru ini, video "Taylor Swift menunjukkan bahasa Cinanya" dengan cepat menjadi popular di media sosial utama, dan kemudian video serupa seperti "Guo Degang menunjukkan bahasa Inggerisnya" muncul. Kebanyakan video ini dihasilkan oleh aplikasi kecerdasan buatan yang dipanggil "HeyGen"
Namun, berdasarkan populariti semasa HeyGen, ia mungkin mengambil masa yang lama untuk menggunakannya untuk mencipta video yang serupa. Nasib baik, ini bukan satu-satunya cara untuk membuatnya. Rakan yang memahami teknologi juga boleh mencari alternatif lain, seperti model pertuturan ke teks Whisper, terjemahan teks GPT, pengklonan suara + penjanaan audio so-vits-svc, dan penjanaan video bentuk mulut yang sepadan dengan audio GeneFace++dengdeng.
Kandungan yang ditulis semula ialah: Antaranya, Whisper ialah model pengecaman pertuturan automatik (ASR) yang dibangunkan dan sumber terbuka oleh OpenAI, yang sangat mudah digunakan. Mereka melatih Whisper pada 680,000 jam berbilang bahasa (98 bahasa) dan data seliaan berbilang tugas yang dikumpul daripada web. OpenAI percaya bahawa menggunakan set data yang begitu besar dan pelbagai boleh meningkatkan keupayaan model untuk mengenali aksen, bunyi latar belakang dan istilah teknikal. Sebagai tambahan kepada pengecaman pertuturan, Whisper juga boleh menyalin berbilang bahasa dan menterjemahkan bahasa tersebut ke dalam bahasa Inggeris. Pada masa ini, Whisper mempunyai banyak varian dan telah menjadi komponen yang diperlukan apabila membina banyak aplikasi AI
Baru-baru ini, pasukan HuggingFace mencadangkan varian baharu - Distil-Whisper. Varian ini ialah versi suling model Whisper, yang dicirikan oleh saiznya yang kecil, kelajuan pantas dan ketepatan yang sangat tinggi, menjadikannya sesuai untuk digunakan dalam persekitaran yang memerlukan kependaman rendah atau mempunyai sumber terhad. Walau bagaimanapun, tidak seperti model Whisper asal yang boleh mengendalikan berbilang bahasa, Distil-Whisper hanya boleh mengendalikan bahasa Inggeris

Pautan kertas: https://arxiv.org/pdf/2311.00430.pdf
perkataan lain, Distil-Whisper mempunyai dua versi, dengan saiz parameter 756M (distil-large-v2) dan 394M (distil-medium.en)
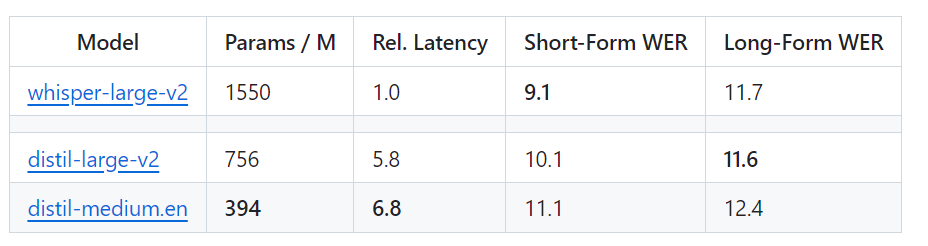 Berbanding dengan OpenAI's Whisper-large-v2, versi 756M Bilangan parameter distil-large-v2 dikurangkan lebih daripada separuh, tetapi ia mencapai pecutan 6 kali ganda, dan ketepatannya sangat hampir dengan Whisper-large-v2 Perbezaan dalam Word Error Rate (WER) bagi audio pendek ialah 1 Dalam %, lebih baik daripada Whisper-large-v2 pada audio panjang. Ini kerana melalui pemilihan dan penapisan data yang teliti, keteguhan Whisper dikekalkan dan ilusi berkurangan.
Berbanding dengan OpenAI's Whisper-large-v2, versi 756M Bilangan parameter distil-large-v2 dikurangkan lebih daripada separuh, tetapi ia mencapai pecutan 6 kali ganda, dan ketepatannya sangat hampir dengan Whisper-large-v2 Perbezaan dalam Word Error Rate (WER) bagi audio pendek ialah 1 Dalam %, lebih baik daripada Whisper-large-v2 pada audio panjang. Ini kerana melalui pemilihan dan penapisan data yang teliti, keteguhan Whisper dikekalkan dan ilusi berkurangan.

Kelajuan versi web Whisper secara intuitif dibandingkan dengan Distil-Whisper. Sumber gambar: https://twitter.com/xenovacom/status/1720460890560975103
 Jadi, walaupun baru dua tiga hari dikeluarkan, Distil-Whisper sudah melebihi seribu bintang. . ?other=arxiv:2311.00430
Jadi, walaupun baru dua tiga hari dikeluarkan, Distil-Whisper sudah melebihi seribu bintang. . ?other=arxiv:2311.00430
- Selain itu, hasil ujian menunjukkan Distil-Whisper boleh 2.5 kali lebih pantas daripada Faster-Whisper apabila memproses audio selama 150 minit
Jadi, bagaimanakah keputusan yang baik itu dicapai? Penulis kertas itu menyatakan bahawa mereka menggunakan teknologi pelabelan pseudo untuk membina set data sumber terbuka berskala besar, dan kemudian menggunakan set data ini untuk memampatkan model Whisper ke Distil-Whisper. Mereka menggunakan heuristik WER yang mudah dan hanya memilih pseudo-label berkualiti tinggi untuk latihan
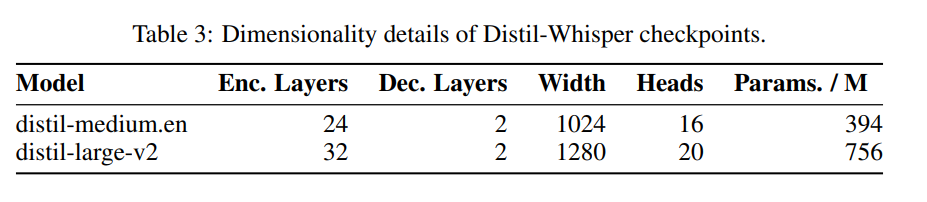
Berikut ialah penulisan semula kandungan asal: Seni bina Distil-Whisper ditunjukkan dalam Rajah 1 di bawah. Para penyelidik memulakan model pelajar dengan menyalin keseluruhan pengekod daripada model guru dan membekukannya semasa latihan. Mereka menyalin lapisan penyahkod pertama dan terakhir daripada model Whisper-medium.en dan Whisper-large-v2 OpenAI, dan memperoleh 2 pusat pemeriksaan penyahkod selepas penyulingan, dinamakan distil-medium.en dan Butiran dimensi model yang diperoleh melalui penyulingan penyulingan. large-v2
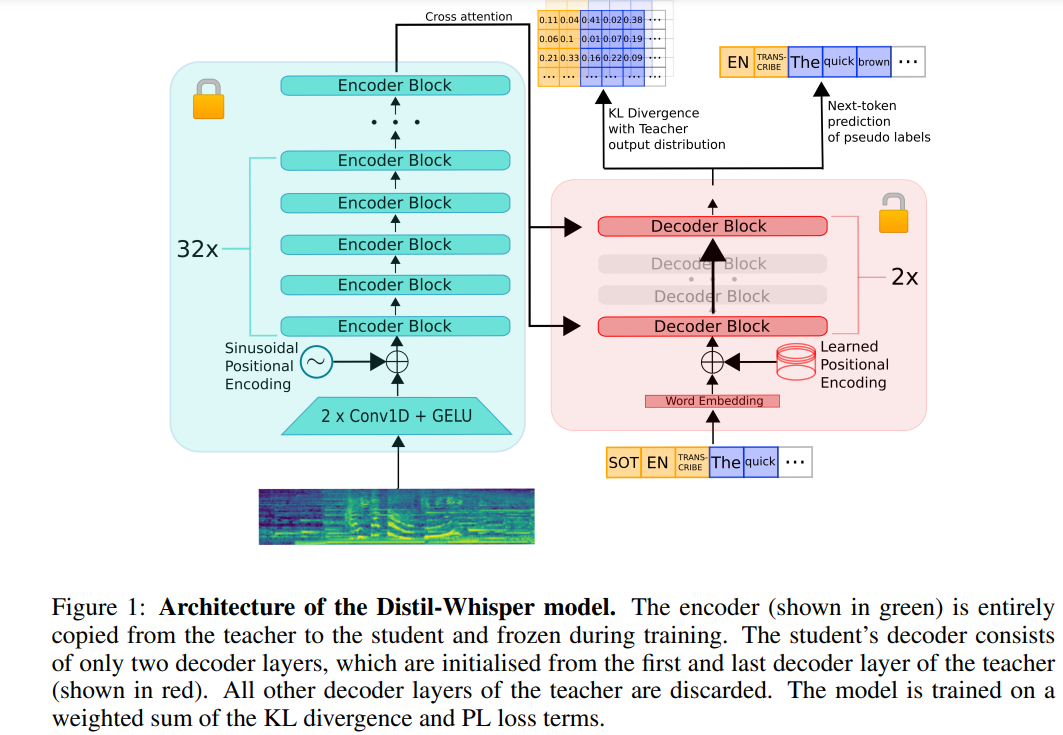
ditunjukkan dalam Jadual 3.
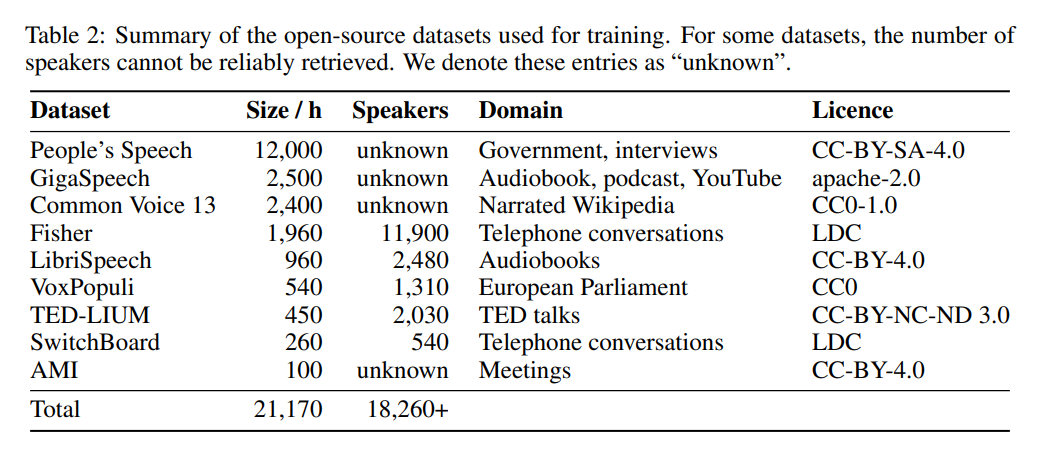
Dari segi data, model ini telah dilatih selama 22,000 jam pada 9 set data sumber terbuka yang berbeza (lihat Jadual 2). Tag pseudo dihasilkan oleh Whisper. Perlu diingat bahawa mereka menggunakan penapis WER dan hanya teg dengan skor WER lebih daripada 10% dikekalkan. Penulis mengatakan ini adalah kunci untuk mengekalkan prestasi!
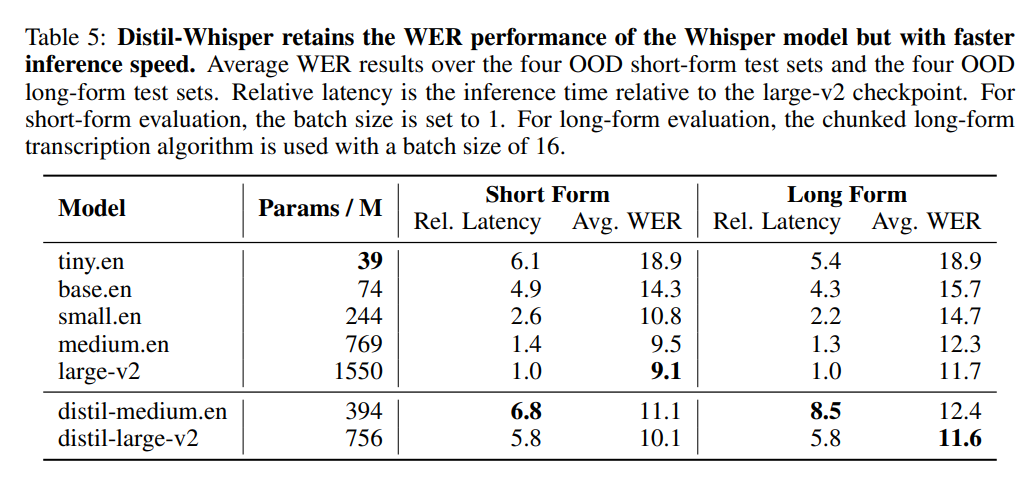
Jadual 5 di bawah menunjukkan keputusan prestasi utama Distil-Whisper.
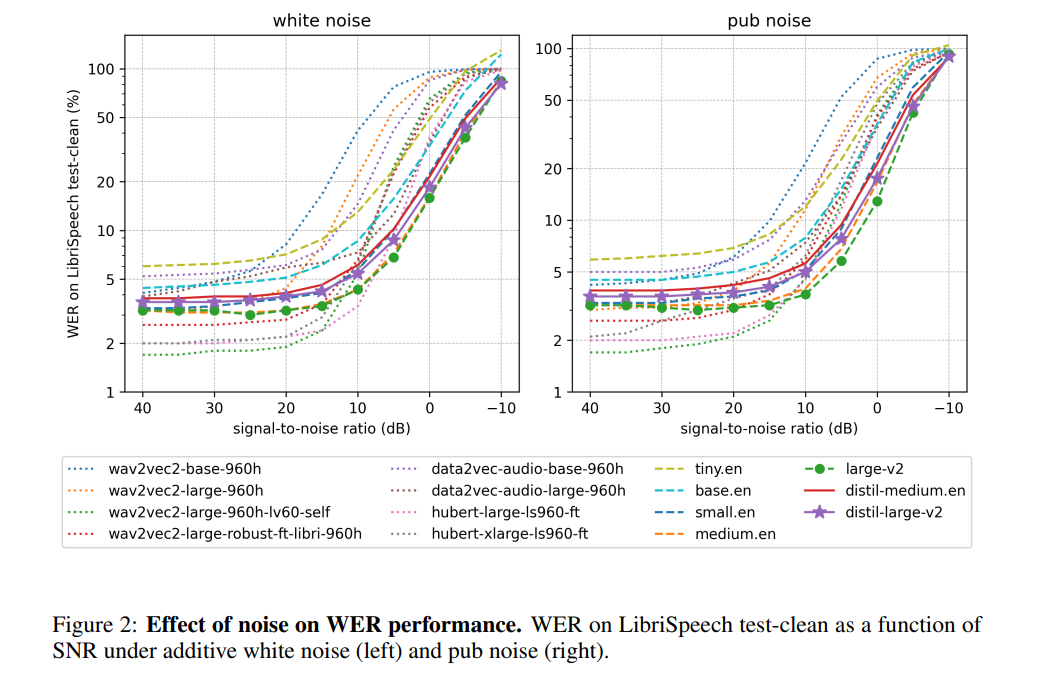
Menurut pengarang, dengan membekukan operasi pengekod, Distil-Whisper berprestasi sangat mantap terhadap bunyi. Seperti yang ditunjukkan dalam rajah di bawah, Distil-Whisper mengikuti lengkung kekukuhan yang serupa dengan Whisper dalam keadaan bising dan berprestasi lebih baik daripada model lain seperti Wav2vec2
Berbanding dengan Whisper apabila memproses fail audio yang lebih panjang , Distil-Whisper berkesan mengurangkan halusinasi. Menurut penulis, ini disebabkan terutamanya oleh penapisan WER Dengan berkongsi pengekod yang sama, Distil-Whisper boleh dipasangkan dengan Whisper untuk penyahkodan spekulatif. Ini menghasilkan kelajuan 2x dengan hanya peningkatan 8% dalam parameter sambil menghasilkan output yang sama seperti Whisper.
Sila lihat artikel asal untuk butiran lanjut.
Atas ialah kandungan terperinci Selepas penyulingan Whisper OpenAI, kelajuan pengecaman pertuturan telah dipertingkatkan dengan ketara: bilangan bintang melebihi 1,000 dalam dua hari. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!