
Rumah >Peranti teknologi >AI >Cipta saluran data pembelajaran mendalam yang cekap dengan Ray
Cipta saluran data pembelajaran mendalam yang cekap dengan Ray

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-11-02 20:17:15867semak imbas
GPU yang diperlukan untuk latihan model pembelajaran mendalam adalah berkuasa tetapi mahal. Untuk menggunakan GPU sepenuhnya, pembangun memerlukan saluran pemindahan data yang cekap yang boleh memindahkan data dengan cepat ke GPU apabila ia bersedia untuk mengira langkah latihan seterusnya. Menggunakan Ray boleh meningkatkan kecekapan saluran penghantaran data dengan ketara
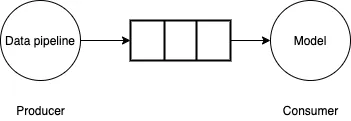
1 Struktur saluran paip data latihan
Pertama, mari kita lihat pseudokod latihan model
for step in range(num_steps):sample, target = next(dataset) # 步骤1train_step(sample, target) # 步骤2
Dalam langkah 1, dapatkan sampel dan label bagi kumpulan mini seterusnya. Dalam langkah 2, ia dihantar ke fungsi train_step, yang menyalinnya ke GPU, melakukan hantaran ke hadapan dan ke belakang untuk mengira kehilangan dan kecerunan serta mengemas kini berat pengoptimum.
Sila ketahui lebih lanjut tentang langkah 1. Apabila set data terlalu besar untuk dimuatkan dalam memori, langkah 1 akan mengambil kumpulan mini seterusnya daripada cakera atau rangkaian. Di samping itu, langkah 1 juga termasuk sejumlah prapemprosesan tertentu. Data input mesti ditukar kepada tensor berangka atau koleksi tensor sebelum disalurkan kepada model. Dalam sesetengah kes, transformasi lain juga dilakukan pada tensor sebelum dihantar kepada model, seperti normalisasi, putaran di sekeliling paksi, shuffling rawak, dsb.
Jika aliran kerja dilaksanakan mengikut urutan, iaitu, langkah 1 ialah dilakukan dahulu , dan kemudian laksanakan langkah 2, maka model akan sentiasa menunggu untuk input, output dan operasi prapemprosesan kumpulan data seterusnya. GPU tidak akan digunakan dengan cekap, ia akan terbiar semasa memuatkan kumpulan mini data seterusnya.
Untuk menyelesaikan masalah ini, saluran paip data boleh dilihat sebagai masalah pengeluar-pengguna. Saluran paip data menjana kumpulan kecil data dan menulisnya ke penimbal terhad. Model/GPU menggunakan kumpulan mini data daripada penimbal, melakukan pengiraan ke hadapan/terbalik dan mengemas kini berat model. Jika saluran paip data boleh menjana kumpulan kecil data secepat model/GPU menggunakannya, proses latihan akan menjadi sangat cekap.
 Pictures
Pictures
2. Tensorflow tf.data API
Tensorflow tf.data API menyediakan set ciri yang kaya yang boleh digunakan untuk mencipta saluran data dengan cekap, menggunakan benang latar untuk mendapatkan kumpulan kecil data, supaya model tidak perlu menunggu. Pra-mengambil data tidak mencukupi Jika menjana kumpulan kecil data adalah lebih perlahan daripada GPU boleh menggunakan data, maka anda perlu menggunakan penyejajaran untuk mempercepatkan bacaan dan transformasi data. Untuk tujuan ini, Tensorflow menyediakan fungsi interleave untuk memanfaatkan berbilang thread untuk membaca data secara selari dan fungsi pemetaan selari untuk menggunakan berbilang thread untuk mengubah kumpulan kecil data.
Memandangkan API ini berdasarkan berbilang benang, ia mungkin dihadkan oleh Python Global Interpreter Lock (GIL). GIL Python mengehadkan bytecode kepada hanya satu utas yang berjalan pada satu masa. Jika anda menggunakan kod TensorFlow tulen dalam saluran paip anda, anda biasanya tidak mengalami had ini kerana enjin pelaksanaan teras TensorFlow berfungsi di luar skop GIL. Walau bagaimanapun, jika pustaka pihak ketiga yang digunakan tidak membatalkan sekatan GIL atau menggunakan Python untuk melakukan sejumlah besar pengiraan, maka bergantung pada multi-benang untuk menyelaraskan saluran paip adalah tidak boleh dilaksanakan
3 saluran paip
Pertimbangkan fungsi penjana berikut, yang Fungsi ini mensimulasikan pemuatan dan melakukan beberapa pengiraan untuk menjana kumpulan mini sampel data dan label.
def data_generator():for _ in range(10):# 模拟获取# 从磁盘/网络time.sleep(0.5)# 模拟计算for _ in range(10000):passyield (np.random.random((4, 1000000, 3)).astype(np.float32), np.random.random((4, 1)).astype(np.float32))
Seterusnya, gunakan penjana dalam saluran paip latihan palsu dan ukur purata masa yang diperlukan untuk menjana kumpulan mini data.
generator_dataset = tf.data.Dataset.from_generator(data_generator,output_types=(tf.float64, tf.float64),output_shapes=((4, 1000000, 3), (4, 1))).prefetch(tf.data.experimental.AUTOTUNE)st = time.perf_counter()times = []for _ in generator_dataset:en = time.perf_counter()times.append(en - st)# 模拟训练步骤time.sleep(0.1)st = time.perf_counter()print(np.mean(times))
Diperhatikan bahawa purata masa yang diambil adalah sekitar 0.57 saat (diukur pada komputer riba Mac dengan pemproses Intel Core i7). Jika ini adalah gelung latihan sebenar, penggunaan GPU akan menjadi agak rendah, ia hanya akan menghabiskan 0.1 saat melakukan pengiraan dan kemudian melahu selama 0.57 saat menunggu kumpulan data seterusnya.
Untuk mempercepatkan pemuatan data, anda boleh menggunakan penjana berbilang proses.
from multiprocessing import Queue, cpu_count, Processdef mp_data_generator():def producer(q):for _ in range(10):# 模拟获取# 从磁盘/网络time.sleep(0.5)# 模拟计算for _ in range(10000000):passq.put((np.random.random((4, 1000000, 3)).astype(np.float32),np.random.random((4, 1)).astype(np.float32)))q.put("DONE")queue = Queue(cpu_count()*2)num_parallel_processes = cpu_count()producers = []for _ in range(num_parallel_processes):p = Process(target=producer, args=(queue,))p.start()producers.append(p)done_counts = 0while done_counts <p>Kini, jika kita mengukur masa yang dihabiskan untuk menunggu kumpulan mini data seterusnya, kita mendapat masa purata 0.08 saat. Itu hampir 7x kelajuan, tetapi idealnya mahu kali ini hampir kepada 0. </p><p>Jika anda menganalisisnya, anda boleh mendapati bahawa banyak masa dihabiskan untuk menyediakan penyahserialisasian data. Dalam penjana berbilang proses, proses pengeluar mengembalikan tatasusunan NumPy yang besar, yang perlu disediakan dan kemudian dinyahsiri dalam proses utama. Jadi bagaimana untuk meningkatkan kecekapan apabila menghantar tatasusunan besar antara proses? </p><h2>4 Gunakan Ray untuk menyelaraskan saluran paip data</h2><p>Di sinilah Ray memainkan peranan. Ray ialah rangka kerja untuk menjalankan pengkomputeran teragih dalam Python. Ia datang dengan stor objek memori kongsi untuk memindahkan objek dengan cekap antara proses yang berbeza. Khususnya, tatasusunan Numpy dalam stor objek boleh dikongsi antara pekerja pada nod yang sama tanpa sebarang pensirilan dan penyahsirilan. Ray juga memudahkan untuk menskalakan pemuatan data merentas berbilang mesin dan menggunakan Apache Arrow untuk mensiri dan menyahsiri tatasusunan besar dengan cekap. </p><p>Ray datang dengan fungsi utiliti from_iterators yang boleh mencipta iterator selari, dan pembangun boleh menggunakannya untuk membalut fungsi penjana data_generator. </p><pre class="brush:php;toolbar:false">import raydef ray_generator():num_parallel_processes = cpu_count()return ray.util.iter.from_iterators([data_generator]*num_parallel_processes).gather_async()Menggunakan ray_generator, masa yang dihabiskan untuk menunggu kumpulan mini data seterusnya diukur menjadi 0.02 saat, iaitu 4 kali lebih pantas daripada menggunakan pemprosesan berbilang proses.
Atas ialah kandungan terperinci Cipta saluran data pembelajaran mendalam yang cekap dengan Ray. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!