
Rumah >Peranti teknologi >AI >DeepMind: Siapa kata rangkaian convolutional lebih rendah daripada ViT?
DeepMind: Siapa kata rangkaian convolutional lebih rendah daripada ViT?

- PHPzke hadapan
- 2023-11-02 09:13:011003semak imbas
Kertas kerja ini menilai NFNets berskala dan mencabar idea bahawa ConvNets berprestasi lebih teruk daripada ViT dalam masalah berskala besar
Kejayaan awal pembelajaran mendalam boleh dikaitkan dengan penggunaan rangkaian saraf konvolusional (ConvNet). membangun. ConvNets telah mendominasi penanda aras penglihatan komputer selama hampir sedekad. Walau bagaimanapun, dalam beberapa tahun kebelakangan ini, mereka telah semakin digantikan oleh ViT (Pengubah Penglihatan).
Ramai orang percaya bahawa ConvNets berprestasi baik pada set data kecil atau sederhana, tetapi tidak dapat bersaing dengan ViT pada set data bersaiz rangkaian yang lebih besar.
Sementara itu, komuniti CV telah beralih daripada menilai prestasi rangkaian yang dimulakan secara rawak pada set data tertentu (seperti ImageNet) kepada menilai prestasi rangkaian yang telah dilatih pada set data umum yang besar yang dikumpulkan daripada rangkaian. Ini membawa kepada soalan penting: adakah Vision Transformers mengatasi prestasi seni bina ConvNets yang telah terlatih pada belanjawan pengiraan yang serupa?
Dalam artikel ini, penyelidik dari Google DeepMind mengkaji masalah ini. Dengan pra-melatih berbilang model NFNet pada set data JFT-4B dengan skala berbeza, mereka mencapai prestasi yang serupa dengan ViT pada ImageNet

Alamat pautan kertas: https://arxiv.org/pdf/ 2310.16764.pdf
The penyelidikan dalam kertas ini membincangkan belanjawan pengkomputeran pra-latihan antara 0.4k dan 110k jam pengkomputeran teras TPU-v4, dan menggunakan peningkatan kedalaman dan lebar keluarga model NFNet untuk menjalankan satu siri latihan rangkaian. Penyelidikan mendapati bahawa terdapat undang-undang penskalaan log log antara kerugian yang ditahan dan belanjawan pengkomputeran
Sebagai contoh, artikel ini akan berdasarkan JFT-4B, di mana jam teras TPU-v4 (jam teras) bermula daripada 0.4 k adalah dilanjutkan kepada 110k dan NFNet telah dilatih terlebih dahulu. Selepas penalaan halus, model terbesar mencapai ketepatan 90.4% pada ImageNet Top-1, bersaing dengan model ViT pra-latihan di bawah bajet pengiraan yang sama
Boleh dikatakan bahawa kertas kerja ini dengan menilai NFNets berskala, Mencabar pandangan bahawa ConvNets berprestasi lebih teruk daripada ViT pada set data berskala besar. Tambahan pula, berdasarkan data dan pengiraan yang mencukupi, ConvNets kekal berdaya saing, dan reka bentuk model serta sumber adalah lebih penting daripada seni bina.
Selepas melihat penyelidikan ini, pemenang Anugerah Turing Yann LeCun berkata: "Pada jumlah pengiraan tertentu, ViT dan ConvNets adalah setara secara pengiraan. Walaupun ViT telah mencapai kejayaan yang mengagumkan dalam penglihatan komputer , tetapi pada pendapat saya, tiada bukti kukuh bahawa ViT yang telah dilatih lebih baik daripada ConvNets yang telah dilatih apabila dinilai secara adil.” Walau bagaimanapun, beberapa netizen mengulas mengenai LeCun bahawa beliau percaya bahawa dalam banyak kes, penggunaan ViT dalam model modal mungkin masih memberikan kelebihan dalam penyelidikan
Mari kita lihat kandungan khusus kertas itu.
 NFNet pra-latihan mengikut undang-undang penskalaan
NFNet pra-latihan mengikut undang-undang penskalaanSeperti yang ditunjukkan dalam Rajah 2, kehilangan pengesahan adalah berkaitan secara linear dengan belanjawan pengiraan model terlatih, selaras dengan undang-undang pengembangan log-log yang diperhatikan apabila menggunakan Transformer untuk pemodelan bahasa. Apabila belanjawan pengiraan meningkat, saiz model optimum dan belanjawan zaman optimum (mencapai kehilangan pengesahan terendah) juga meningkat
Dalam carta di bawah, kita boleh melihat tiga model merentas julat belanjawan zaman Kadar pembelajaran terbaik yang diperhatikan ( iaitu, satu yang meminimumkan kehilangan pengesahan). Para penyelidik mendapati bahawa untuk belanjawan zaman yang lebih rendah, keluarga model NFNet semuanya menunjukkan kadar pembelajaran optimum yang sama, sekitar 1.6. Walau bagaimanapun, kadar pembelajaran optimum berkurangan apabila belanjawan zaman meningkat, dan berkurangan lebih cepat untuk model yang lebih besar. Para penyelidik mengatakan bahawa boleh diandaikan bahawa kadar pembelajaran optimum menurun secara perlahan dan monoton dengan peningkatan saiz model dan belanjawan zaman, jadi kadar pembelajaran boleh diselaraskan dengan berkesan antara percubaan

Apa yang perlu ditulis semula ialah: Perlu diingatkan bahawa beberapa model pra-latihan dalam Rajah 2 tidak menunjukkan prestasi seperti yang diharapkan. Pasukan penyelidik percaya bahawa sebab bagi situasi ini ialah jika larian latihan didahulukan/dimulakan semula, proses pemuatan data tidak dapat menjamin bahawa setiap sampel latihan boleh diambil sampel sekali dalam setiap zaman. Jika larian latihan dimulakan semula beberapa kali, ini mungkin menyebabkan beberapa sampel latihan kurang sampel
NFNet vs ViT
Eksperimen pada ImageNet menunjukkan bahawa NFNet dan Vision Transformer yang ditala halus menunjukkan prestasi yang setanding
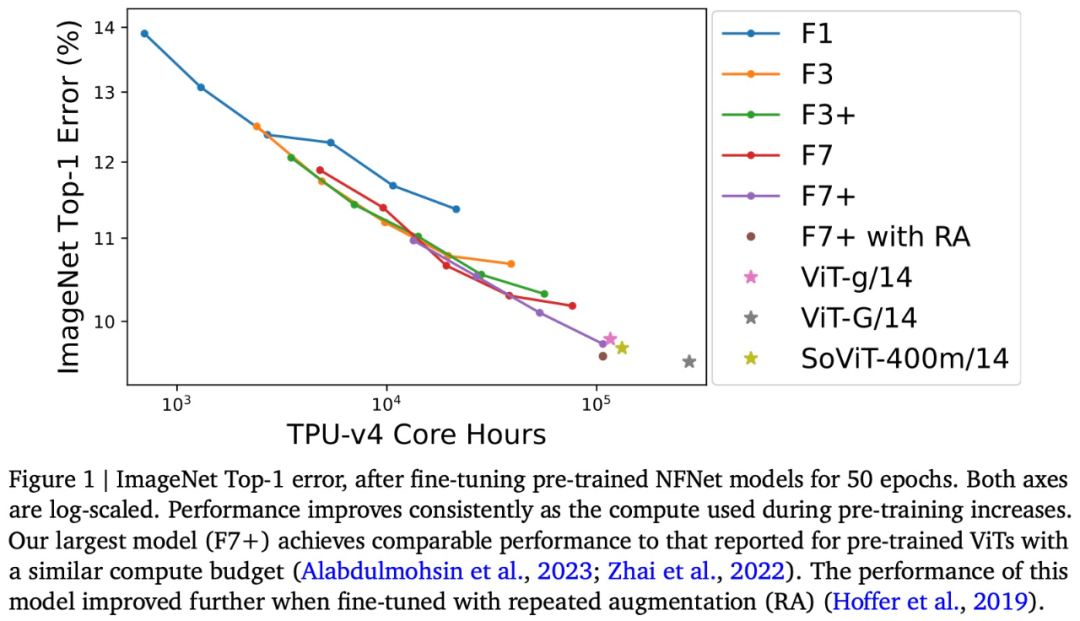
Secara khusus-Menyatakan kajian ini menala NFNet pra-latihan pada ImageNet dan memplot hubungan antara pengiraan pra-latihan dan ralat Top-1, seperti yang ditunjukkan dalam Rajah 1 di atas.
Ketepatan ImageNet Top-1 terus bertambah baik apabila belanjawan meningkat. Antaranya, model pra-latihan paling mahal ialah NFNet-F7+, yang telah dilatih selama 8 zaman, dan mempunyai ketepatan 90.3% dalam ImageNet Top-1. Pralatihan dan penalaan halus memerlukan kira-kira 110k jam teras TPU-v4 dan 1.6k jam teras TPU-v4. Tambahan pula, jika teknik peningkatan berulang tambahan diperkenalkan semasa penalaan halus, ketepatan Top-1 sebanyak 90.4% boleh dicapai. NFNet mendapat manfaat besar daripada pra-latihan berskala besar
Walaupun terdapat perbezaan yang jelas antara kedua-dua seni bina model NFNet dan ViT, prestasi NFNet pra-latihan dan ViT pra-latihan adalah setanding. Contohnya, selepas pra-latihan JFT-3B dengan jam teras TPU-v3 210k, ViT-g/14 mencapai ketepatan Top-1 sebanyak 90.2% pada ImageNet sambil melakukan lebih daripada 500k TPU-v3 pada JFT-3B Selepas waktu teras daripada pra-latihan, ViT-G/14 mencapai ketepatan Top-1 sebanyak 90.45%
Artikel ini menilai kelajuan pra-latihan model ini pada TPU-v4 dan menganggarkan bahawa ViT-g/14 memerlukan teras TPU-v4 120k jam untuk pra-latihan, manakala ViTG/14 akan memerlukan 280k jam teras TPU-v4, dan SoViT-400m/14 akan memerlukan 130k jam teras TPU-v4. Kertas ini menggunakan anggaran ini untuk membandingkan kecekapan pralatihan ViT dan NFNet dalam Rajah 1. Kajian itu menyatakan bahawa NFNet dioptimumkan untuk TPU-v4 dan berprestasi buruk apabila dinilai pada peranti lain.
Akhirnya, kertas kerja ini menyatakan bahawa pusat pemeriksaan pra-latihan mencapai kehilangan pengesahan terendah pada JFT-4B, tetapi tidak selalu mencapai ketepatan Top-1 tertinggi pada ImageNet selepas penalaan halus. Khususnya, kertas kerja ini mendapati bahawa di bawah belanjawan pengiraan pra-latihan tetap, mekanisme penalaan halus cenderung untuk memilih model yang lebih besar sedikit dan belanjawan zaman yang lebih kecil. Secara intuitif, model yang lebih besar mempunyai kapasiti yang lebih besar dan oleh itu lebih mampu menyesuaikan diri dengan tugasan baharu. Dalam sesetengah kes, kadar pembelajaran yang lebih besar sedikit (semasa pra-latihan) juga boleh membawa kepada prestasi yang lebih baik selepas penalaan halus
Atas ialah kandungan terperinci DeepMind: Siapa kata rangkaian convolutional lebih rendah daripada ViT?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 什么是ps工程文件
- Ajar anda langkah demi langkah cara membuat projek maven dalam vscode (gabungan grafik dan teks)
- Belajar seperti bayi, model baharu DeepMind mempelajari peraturan dunia fizikal dalam masa 28 jam
- Google sangat bimbang bahawa ia menyokong DeepMind! 70 bilion parameter Sparrow hard ChatGTP
- Siapa yang telah menerbitkan penyelidikan AI yang paling berpengaruh? Google jauh ke hadapan, dan kadar penukaran pencapaian OpenAI mengatasi DeepMind