
Rumah >Peranti teknologi >AI >Lebih baik daripada Transformer, BERT dan GPT tanpa Perhatian dan MLP sebenarnya lebih kuat.
Lebih baik daripada Transformer, BERT dan GPT tanpa Perhatian dan MLP sebenarnya lebih kuat.

- WBOYke hadapan
- 2023-10-30 14:33:04743semak imbas
Daripada model bahasa seperti BERT, GPT dan Flan-T5 kepada model imej seperti SAM dan Stable Diffusion, Transformer sedang menyapu dunia dengan pantas, tetapi orang ramai tidak boleh tidak bertanya: Adakah Transformer satu-satunya pilihan?
Pasukan penyelidik dari Stanford University dan State University of New York di Buffalo bukan sahaja memberikan jawapan negatif kepada soalan ini, tetapi juga mencadangkan teknologi alternatif baharu: Monarch Mixer. Baru-baru ini, pasukan itu menerbitkan kertas kerja yang berkaitan dan beberapa model pusat pemeriksaan serta kod latihan di arXiv. Ngomong-ngomong, kertas ini telah dipilih untuk NeurIPS 2023 dan layak untuk Persembahan Lisan.

Pautan kertas: https://arxiv.org/abs/2310.12109
Alamat kod pada GitHub ialah: https://github.com/HazyResearch/m2 remove this method Perhatian kos tinggi dan MLP dalam Transformer digantikan dengan matriks Monarch ekspresif, membolehkan ia mencapai prestasi yang lebih baik pada kos yang lebih rendah dalam eksperimen bahasa dan imej.
Ini bukan kali pertama Universiti Stanford mencadangkan teknologi alternatif kepada Transformer. Pada bulan Jun tahun ini, satu lagi pasukan dari sekolah itu turut mencadangkan teknologi yang dipanggil Backpack Sila rujuk artikel Heart of Machine "Model Alternatif Transformer Latihan Stanford: 170 Juta Parameter, Debiased, Boleh dikawal dan Sangat Boleh Ditafsirkan." Sudah tentu, untuk teknologi ini mencapai kejayaan sebenar, mereka perlu diuji lebih lanjut oleh komuniti penyelidik dan bertukar menjadi produk yang praktikal dan berguna di tangan pembangun aplikasi
Mari kita lihat pengenalan kepada Monarch Mixer dan beberapa eksperimen dalam keputusan kertas ini.
Pengenalan Kertas
Dalam bidang pemprosesan bahasa semula jadi dan penglihatan komputer, model pembelajaran mesin telah dapat mengendalikan urutan yang lebih panjang dan perwakilan dimensi yang lebih tinggi, sekali gus menyokong konteks yang lebih panjang dan kualiti yang lebih tinggi. Walau bagaimanapun, kerumitan masa dan ruang seni bina sedia ada mempamerkan corak pertumbuhan kuadratik dalam panjang jujukan dan/atau dimensi model, yang mengehadkan panjang konteks dan meningkatkan kos penskalaan. Contohnya, perhatian dan MLP dalam skala Transformer secara kuadratik dengan panjang jujukan dan dimensi model.
Sebagai tindak balas kepada masalah ini, pasukan penyelidik dari Universiti Stanford dan Universiti Negeri New York di Buffalo ini mendakwa telah menemui seni bina berprestasi tinggi yang kerumitannya berkembang secara subkuadrat dengan panjang jujukan dan dimensi model ( sub-kuadrat).
Kajian mereka diilhamkan oleh MLP-mixer dan ConvMixer. Kedua-dua kajian ini mendapati bahawa: Banyak model pembelajaran mesin menggabungkan maklumat sepanjang jujukan dan dimensi model sebagai paksi, dan selalunya beroperasi pada kedua-dua paksi menggunakan operator tunggal
mencari ekspresif, sub-kuadrat dan perkakasan Operator pencampuran yang cekap adalah sukar. untuk melaksanakan. Contohnya, MLP dalam MLP-mixer dan convolutions dalam ConvMixer kedua-duanya agak ekspresif, tetapi kedua-duanya berskala kuadratik dengan dimensi input. Beberapa kajian baru-baru ini telah mencadangkan beberapa kaedah hibrid jujukan sub-kuadrat ini menggunakan konvolusi yang lebih panjang atau model ruang keadaan, dan semuanya menggunakan FFT Walau bagaimanapun, penggunaan FLOP model ini adalah sangat rendah masih pengembangan kedua. Pada masa yang sama, terdapat beberapa kemajuan yang menjanjikan pada lapisan MLP padat yang jarang tanpa menjejaskan kualiti, tetapi sesetengah model sebenarnya mungkin lebih perlahan daripada model padat disebabkan penggunaan perkakasan yang lebih rendah.
Berdasarkan inspirasi ini, pasukan penyelidik mencadangkan Monarch Mixer (M2), yang menggunakan matriks berstruktur sub-kuadrat ekspresif: Matriks Monarch
Matriks Monarch ialah matriks struktur transformasi Fourier pantas (FFT) umum , penyelidikan menunjukkan bahawa ia mengandungi pelbagai transformasi linear, seperti transformasi Hadamard, matriks Toplitz, matriks dan konvolusi AFDF, dsb. Matriks ini boleh diparameterkan dengan hasil darab matriks pepenjuru blok Parameter ini dipanggil faktor Monarch dan berkaitan dengan permutasi interleaving Pengiraannya adalah subkuadrat: jika bilangan faktor ditetapkan kepada p , maka apabila panjang input ialah N. kerumitan pengiraan ialah
, supaya kerumitan pengiraan boleh berada di antara O (N log N) apabila p = log N dan
apabila p = 2.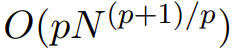 M2 menggunakan matriks Monarch untuk menggabungkan maklumat sepanjang jujukan dan paksi dimensi model. Pendekatan ini bukan sahaja mudah dilaksanakan, ia juga cekap perkakasan: Faktor Raja pepenjuru yang disekat boleh dikira dengan cekap menggunakan perkakasan moden yang menyokong GEMM (Algoritma Pendaraban Matriks Umum).
M2 menggunakan matriks Monarch untuk menggabungkan maklumat sepanjang jujukan dan paksi dimensi model. Pendekatan ini bukan sahaja mudah dilaksanakan, ia juga cekap perkakasan: Faktor Raja pepenjuru yang disekat boleh dikira dengan cekap menggunakan perkakasan moden yang menyokong GEMM (Algoritma Pendaraban Matriks Umum).
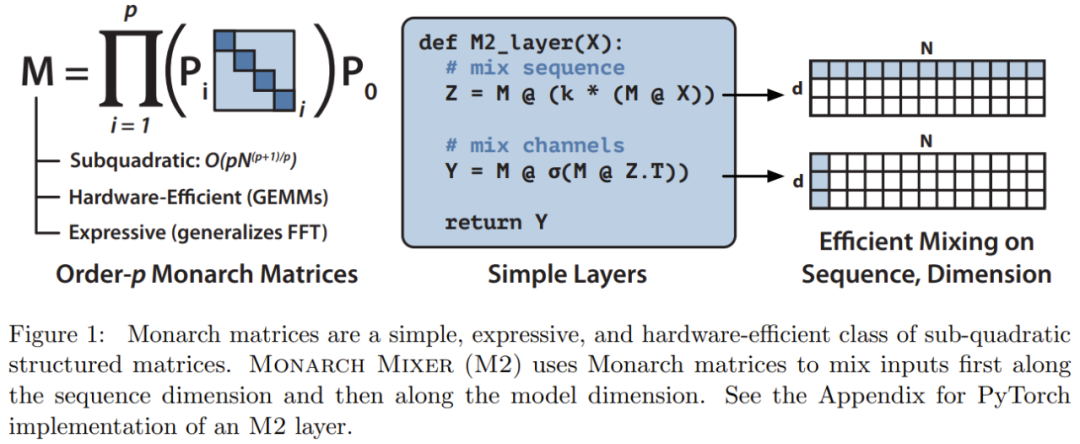
Pasukan penyelidik melaksanakan lapisan M2 dalam kurang daripada 40 baris dengan menulis kod menggunakan PyTorch, dan hanya bergantung pada pendaraban matriks, transpos, bentuk semula dan produk bijak unsur (lihat pseudokod di tengah-tengah Rajah 1). Untuk saiz input 64k, kod ini mencapai penggunaan FLOP sebanyak 25.6% pada GPU A100. Pada seni bina yang lebih baharu seperti RTX 4090, pelaksanaan CUDA yang ringkas mampu mencapai 41.4% penggunaan FLOP untuk saiz input yang sama 🎜#Untuk penerangan matematik dan analisis teori Monarch Mixer, sila rujuk kertas asal.
Pasukan penyelidik membandingkan kedua-dua model, Monarch Mixer dan The Transformer, terutamanya untuk situasi di mana Transformer mendominasi tiga tugas utama dikaji. Tiga tugas tersebut ialah: tugasan pemodelan bahasa topeng bukan sebab-sebab gaya BERT, tugasan pengelasan imej gaya ViT dan tugasan model bahasa sebab-akibat gaya GPT
Pada setiap tugasan, keputusan eksperimen menunjukkan bahawa kaedah yang baru dicadangkan boleh mencapai tahap yang setanding dengan Transformer tanpa menggunakan perhatian dan MLP. Mereka juga menilai kelajuan kaedah baharu berbanding model garis dasar Transformer yang berkuasa dalam tetapan BERT Pemodelan bahasa Acausal perlu ditulis semula
Untuk perlu menulis semula tugas pemodelan bahasa bukan sebab, pasukan membina seni bina berasaskan M2: M2-BERT. M2-BERT boleh menggantikan secara langsung model bahasa gaya BERT, dan BERT ialah aplikasi utama seni bina Transformer. Untuk latihan M2-BERT, pemodelan bahasa bertopeng pada C4 digunakan, dan tokenizer adalah bert-base-uncased.
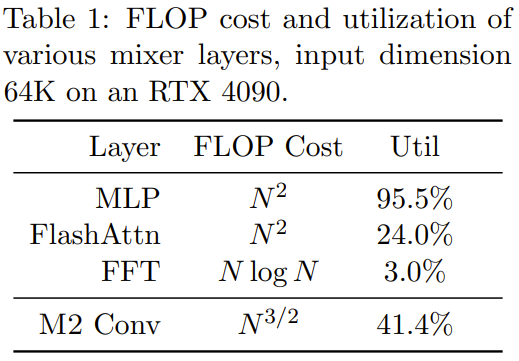
M2-BERT adalah berdasarkan tulang belakang Transformer, tetapi lapisan M2 menggantikan lapisan perhatian dan MLP, seperti yang ditunjukkan dalam Rajah 3 # 🎜🎜#
Dalam pengadun jujukan, perhatian digantikan dengan lilitan berpagar dua arah dengan lilitan baki (lihat sebelah kiri Rajah 3). Untuk memulihkan lilitan, pasukan menetapkan matriks Monarch kepada DFT dan matriks DFT songsang. Mereka juga menambah lilitan mendalam selepas langkah unjuran.
Dalam pengadun dimensi, dua matriks tumpat MLP digantikan dengan matriks pepenjuru blok terpelajar (tertib matriks Monarch ialah 1, b= 4)
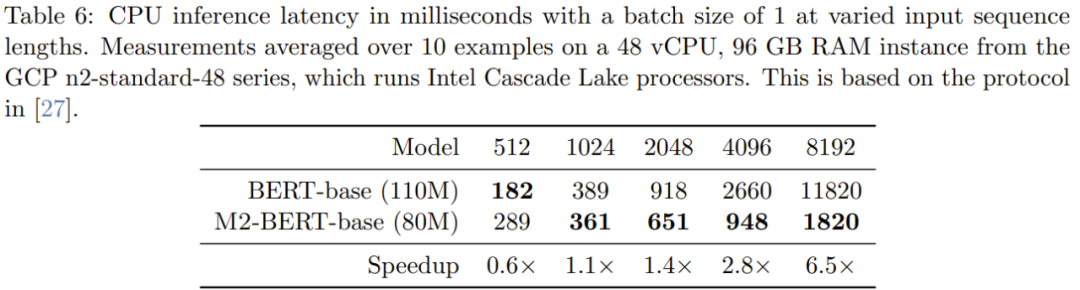
Pengkaji menjalankan pra-latihan dan memperoleh sejumlah 4 model M2-BERT: dua daripadanya bersaiz M2-BERT dengan saiz 80M dan 110M masing-masing model asas, dan dua lagi adalah model besar M2-BERT dengan saiz masing-masing 260M dan 341M. Model-model ini bersamaan dengan BERT-base dan BERT-large masing-masing Prestasi model BERT-large. 
Seperti yang dapat dilihat dari jadual, pada penanda aras GLUE, prestasi M2-BERT-base adalah setanding dengan BERT -base, manakala mempunyai 27% lebih sedikit parameter apabila bilangan parameter antara kedua-duanya adalah sama, M2-BERT-base mengalahkan BERT-base sebanyak 1.3 mata. Begitu juga, M2-BERT-large, yang mempunyai 24% lebih sedikit parameter, berprestasi sama baik dengan BERT-large, manakala dengan bilangan parameter yang sama, M2-BERT-large mempunyai kelebihan 0.7 mata.
Jadual 5 menunjukkan daya pemprosesan hadapan model yang setara dengan model asas BERT. Dilaporkan ialah bilangan token yang diproses setiap milisaat pada GPU A100-40GB, yang boleh mencerminkan masa inferens 🎜🎜#Ia boleh dilihat bahawa daya pemprosesan M2-BERT-base malah melebihi yang sangat tinggi. model BERT yang dioptimumkan; berbanding dengan pelaksanaan HuggingFace standard pada panjang jujukan 4k, M2-BERT- Daya tampung asas boleh mencapai 9.1 kali!
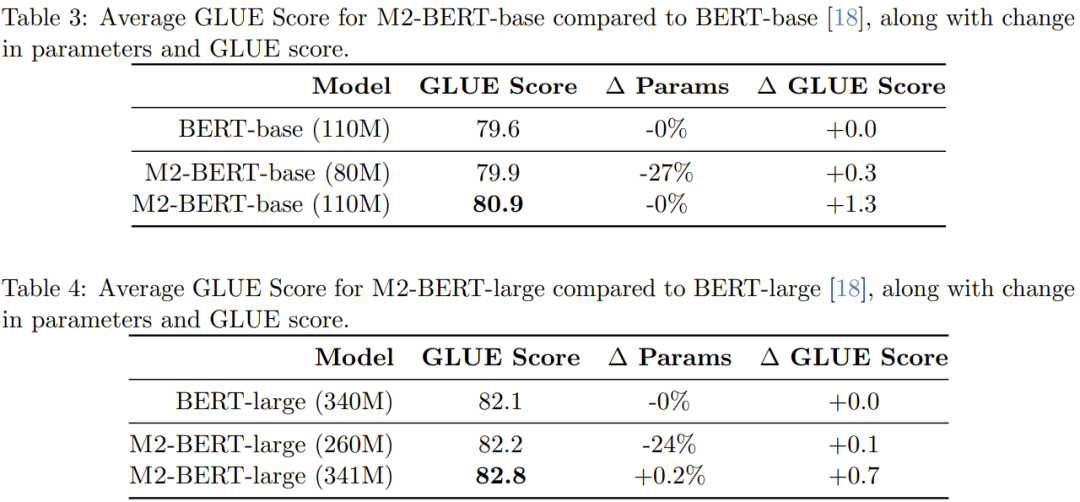 Jadual 6 memberikan masa inferens CPU M2-BERT-base (80M) dan BERT-base - Ini keputusan diperoleh dengan menjalankan kedua-dua model ini secara langsung menggunakan pelaksanaan PyTorch
Jadual 6 memberikan masa inferens CPU M2-BERT-base (80M) dan BERT-base - Ini keputusan diperoleh dengan menjalankan kedua-dua model ini secara langsung menggunakan pelaksanaan PyTorch
Apabila urutan pendek, kesan lokaliti data masih menguasai pengurangan FLOP, dan operasi seperti penjanaan penapis (tidak tersedia dalam BERT) adalah lebih mahal. Apabila panjang jujukan melebihi 1K, kelebihan pecutan M2-BERT-base secara beransur-ansur meningkat Apabila panjang jujukan mencapai 8K, kelebihan kelajuan boleh mencapai 6.5 kali.
Klasifikasi Imej
Untuk mengesahkan sama ada kelebihan kaedah baharu dalam domain imej adalah sama seperti dalam domain bahasa, pasukan juga menilai prestasi M2 pada tugas klasifikasi imej, yang berasaskan pada pembinaan bukan sebab-sebab Jadual 7 menunjukkan prestasi Monarch Mixer, ViT-b, HyenaViT-b dan ViT-b-Monarch (menggantikan modul MLP dalam ViT-b standard dengan matriks Monarch) pada Prestasi ImageNet-1k.
Kelebihan Monarch Mixer sangat jelas: ia hanya memerlukan separuh daripada bilangan parameter untuk mengatasi model ViT-b yang asal. Anehnya, Monarch Mixer dengan parameter yang lebih sedikit malah mampu mengungguli ResNet-152, yang direka khusus untuk tugas ImageNet 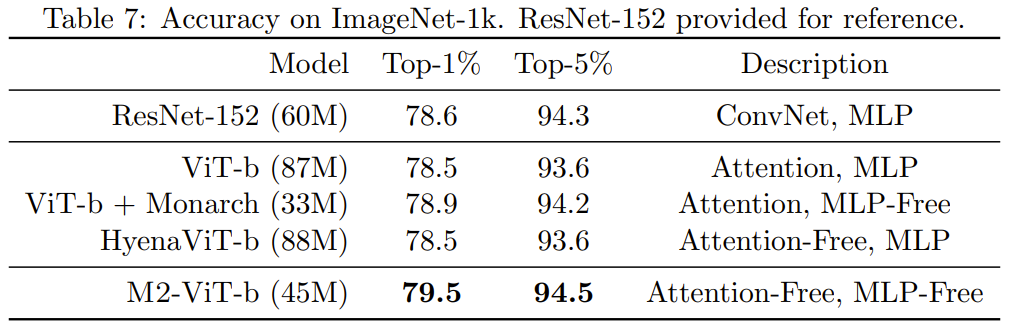
Pemodelan Bahasa Bersebab
Modul aplikasi kausal gaya Transeform yang penting. . Pasukan ini membangunkan seni bina berasaskan M2 untuk pemodelan bahasa kausal, yang dipanggil M2-GPT
Untuk pengadun jujukan, M2-GPT menggabungkan penapis konvolusi daripada Hyena, Model bahasa bebas perhatian terkini dan parameter daripada H3 dikongsi merentasi panjang. Mereka menggantikan FFT dalam seni bina ini dengan parameterisasi kausal dan mengalih keluar lapisan MLP sepenuhnya. Seni bina yang terhasil sama sekali tidak mendapat perhatian dan sama sekali tidak mempunyai MLP.
Mereka telah melatih M2-GPT pada PILE, set data standard untuk pemodelan bahasa kausal. Keputusan ditunjukkan dalam Jadual 8.
Adalah dapat dilihat bahawa walaupun model berdasarkan seni bina baharu tidak mendapat perhatian dan MLP langsung, ia masih mengatasi Transformer dan Hyena dalam indeks kebingungan yang telah dilatih. Keputusan ini mencadangkan bahawa model yang sangat berbeza daripada Transformer juga boleh mencapai prestasi cemerlang dalam pemodelan bahasa kausal. 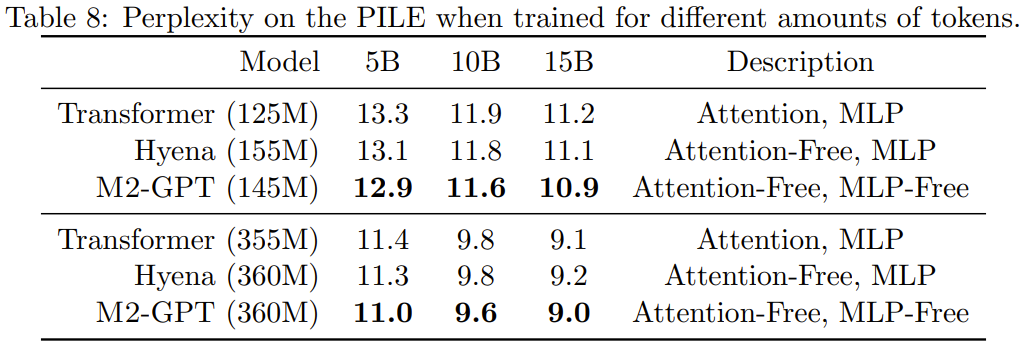
Sila rujuk kertas asal untuk kandungan yang lebih terperinci
Atas ialah kandungan terperinci Lebih baik daripada Transformer, BERT dan GPT tanpa Perhatian dan MLP sebenarnya lebih kuat.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- python ipo模型是指什么
- Hanya berlatih sekali untuk menjana adegan 3D baharu! Sejarah evolusi 'Rendering Neural Medan Cahaya' Google
- Semakan sistematik pembelajaran peneguhan mendalam pra-latihan, penyelidikan dalam talian dan luar talian sudah memadai.
- CMU bergabung tenaga dengan Adobe: Model GAN menyambut era pra-latihan, hanya memerlukan 1% sampel latihan
- Artikel pertama: Paradigma baharu untuk melatih model penghunian 3D berbilang paparan menggunakan label 2D sahaja