
Rumah >Peranti teknologi >AI >Teks panjang boleh dibaca dengan panjang tetingkap 4k Chen Danqi dan pengikutnya bekerjasama dengan Meta untuk melancarkan kaedah baharu untuk meningkatkan ingatan model besar.
Teks panjang boleh dibaca dengan panjang tetingkap 4k Chen Danqi dan pengikutnya bekerjasama dengan Meta untuk melancarkan kaedah baharu untuk meningkatkan ingatan model besar.

- 王林ke hadapan
- 2023-10-24 20:13:01811semak imbas
Model besar dengan hanya 4k panjang tetingkap masih boleh membaca bahagian besar teks!
Pencapaian terbaharu oleh seorang pelajar kedoktoran Cina di Princeton telah berjaya "menembusi" had panjang tingkap model besar.
Bukan sahaja dapat menjawab pelbagai soalan, malah keseluruhan proses pelaksanaan boleh diselesaikan sepenuhnya dengan segera, tanpa sebarang latihan tambahan #🎜🎜🎜#.

Jadi, apakah strategi ingatan pokok secara khusus, dan cara membaca dengan terhad panjang tetingkap Bagaimana dengan teks panjang?
 Satu tetingkap tidak mencukupi, hanya buka beberapa lagi
Satu tetingkap tidak mencukupi, hanya buka beberapa lagi
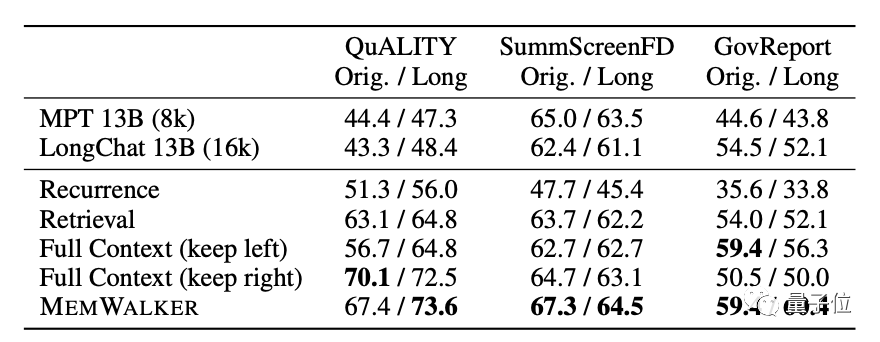
Pada model, MemWalker menggunakan Stable Beluga 2 sebagai model asas, yang diperoleh oleh Llama 2-70B selepas penalaan arahan.
Sebelum memilih model ini, pembangun membandingkan prestasinya dengan Llama 2 yang asal dan akhirnya memutuskannya.
Sama seperti nama MemWalker, proses kerjanya adalah seperti aliran memori berjalan.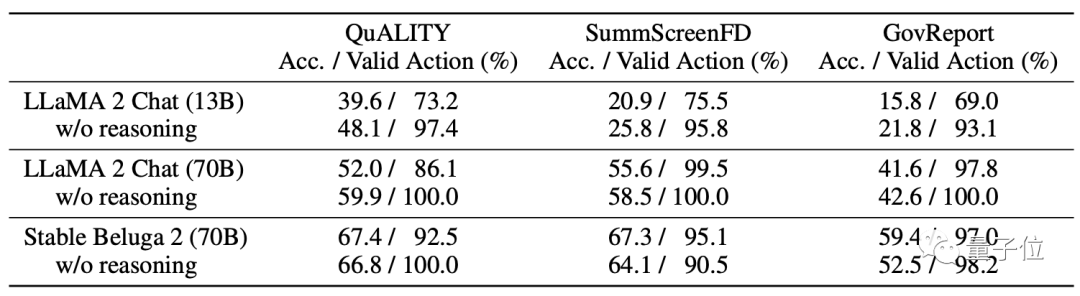 Secara khusus, ia dibahagikan secara kasar kepada dua peringkat:
Secara khusus, ia dibahagikan secara kasar kepada dua peringkat:
dan
Navigasi retrieval.
Apabila membina pepohon ingatan, teks panjang akan dibahagikan kepada beberapa segmen kecil (seg1-6) 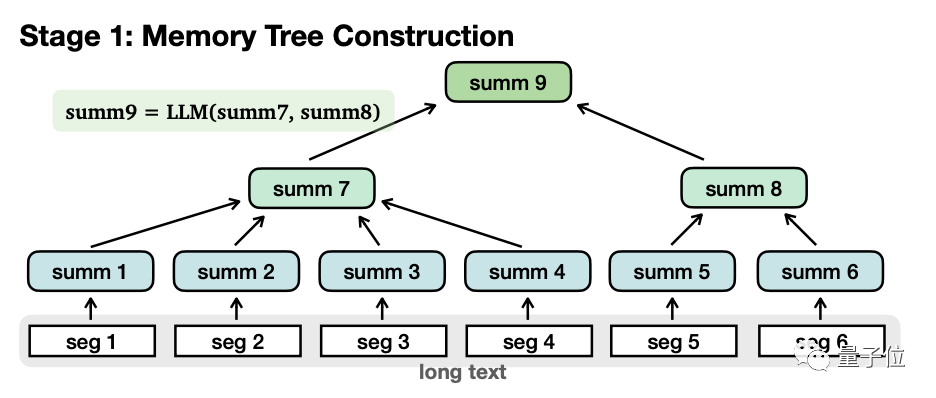 , dan terdiri daripada Model besar meringkaskan setiap perenggan secara berasingan, dan mendapat "
, dan terdiri daripada Model besar meringkaskan setiap perenggan secara berasingan, dan mendapat "
nod daun" (nod daun, summ1-6) #🎜🎜 Apabila membahagikan, semakin panjang panjang setiap segmen, semakin sedikit tahap yang akan ada, yang kondusif untuk mendapatkan semula berikutnya, tetapi terlalu lama itu sendiri akan membawa kepada penurunan ketepatan, jadi pertimbangan menyeluruh adalah diperlukan untuk menentukan panjang setiap segmen. Penulis percaya bahawa panjang munasabah setiap perenggan ialah 500-2000 token, dan yang digunakan dalam eksperimen ialah 1000 token.
Kemudian, model secara rekursif meringkaskan kandungan nod daun ini sekali lagi untuk membentuk "
non-leaf nodes 🎜#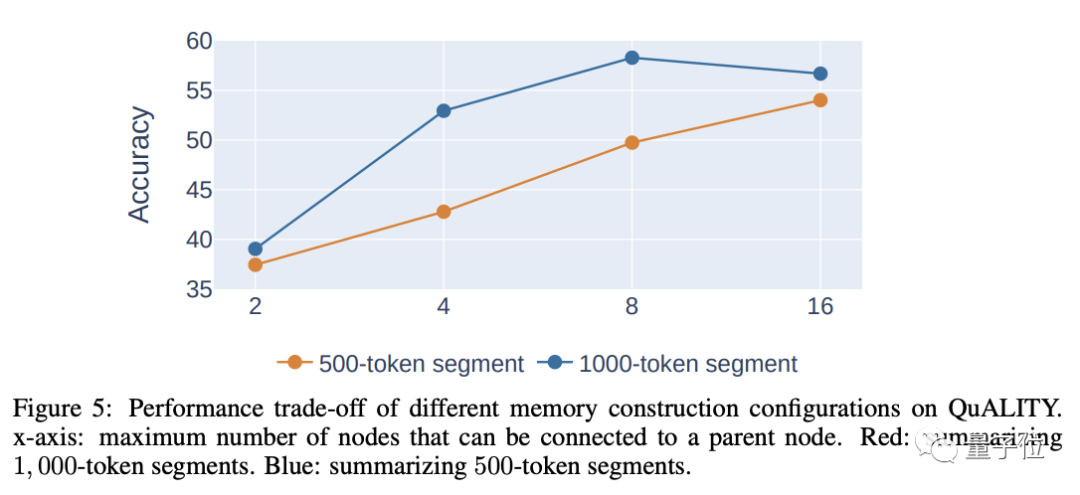 ”
”
. Satu lagi perbezaan antara keduanya ialah nod daun mengandungi maklumat asal , manakala nod bukan daun hanya mempunyai maklumat sekunder diringkaskan oleh .
Secara fungsional, nod bukan daun digunakan untuk menavigasi dan mencari nod daun di mana jawapan terletak, manakala nod daun digunakan untuk membuat kesimpulan jawapan. Nod bukan daun boleh mempunyai pelbagai peringkat, dan model secara beransur-ansur diringkaskan sehingga "nod akar" diperoleh untuk membentuk struktur pokok yang lengkap. Selepas pepohon ingatan ditubuhkan, anda boleh memasuki peringkat pencarian navigasi untuk menjana jawapan.
Dalam proses ini, model bermula dari nod akar dan membaca kandungan nod anak peringkat pertamasatu demi satu. Kemudian fikirkan sama ada untuk memasuki nod ini atau kembali.
Selepas membuat keputusan untuk memasuki nod ini, ulangi proses sekali lagi sehingga nod daun dibaca. Jika kandungan nod daun sesuai, jawapan dijana, jika tidak, ia dikembalikan. 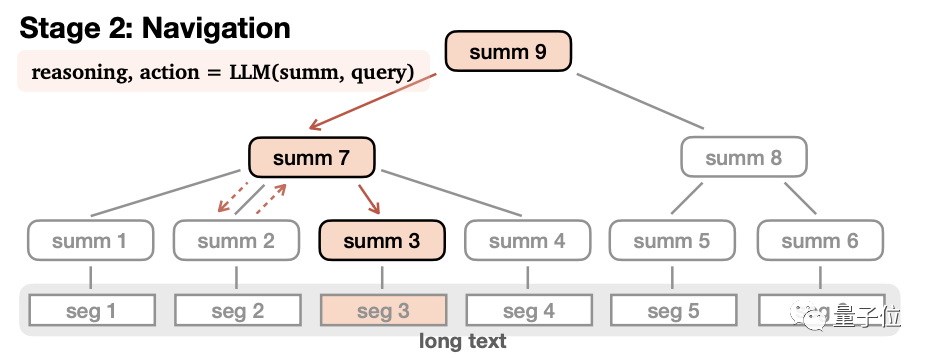
Semasa proses navigasi, jika model mendapati ia telah memasuki laluan yang salah, ia juga boleh menavigasi ke belakang.
Selain itu, MemWalker turut memperkenalkan mekanisme ingatan berfungsi untuk meningkatkan ketepatan.
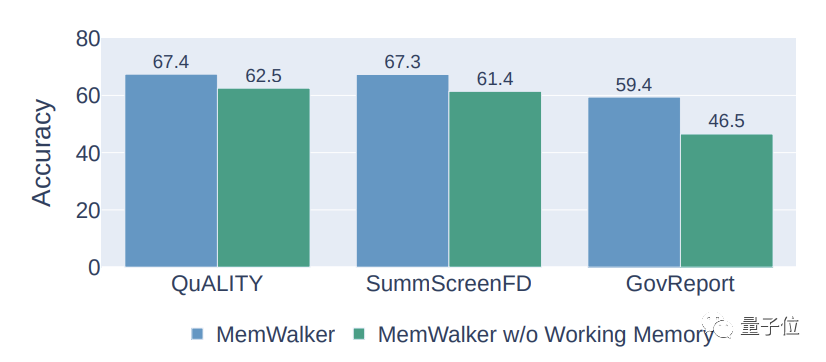
Mekanisme ini akan menambah kandungan nod yang dilawati pada konteks kandungan semasa.
Apabila model memasuki nod baharu, kandungan nod semasa akan ditambahkan pada memori.
Mekanisme ini membolehkan model menggunakan kandungan nod yang dilawati pada setiap langkah untuk mengelakkan kehilangan maklumat penting.
Keputusan eksperimen menunjukkan bahawa mekanisme memori kerja boleh meningkatkan ketepatan MemWalker sebanyak kira-kira 10%.
Selain itu, proses yang dinyatakan di atas boleh diselesaikan hanya dengan bergantung pada segera, dan tiada latihan tambahan diperlukan.

Secara teorinya, selagi kuasa pengkomputeran mencukupi, MemWalker boleh membaca teks yang tidak terhingga panjangnya.
Walau bagaimanapun, masa dan kerumitan ruang semasa membina pepohon ingatan adalah eksponen apabila panjang teks bertambah.
Mengenai pengarang
Pengarang pertama kertas kerja ialah Howard Chen, pelajar kedoktoran Cina di Makmal NLP Universiti Princeton.
Alumnus Kelas Tsinghua Yao Chen Danqi ialah mentor Howard, dan laporan akademiknya tentang ACL tahun ini juga berkaitan dengan carian.
Keputusan ini telah disempurnakan oleh Howard semasa latihan di Meta Tiga orang sarjana, Ramakanth Pasunuru, Jason Weston dan Asli Celikyilmaz dari Makmal Meta AI turut mengambil bahagian dalam projek ini.
Alamat kertas: https://arxiv.org/abs/2310.05029
Atas ialah kandungan terperinci Teks panjang boleh dibaca dengan panjang tetingkap 4k Chen Danqi dan pengikutnya bekerjasama dengan Meta untuk melancarkan kaedah baharu untuk meningkatkan ingatan model besar.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- C语言在main中调用函数时找不到标识符
- ai文件可用什么软件打开和编辑
- Laksanakan latihan kelebihan dengan memori kurang daripada 256KB dan kosnya kurang daripada seperseribu PyTorch
- Semakan sistematik pembelajaran peneguhan mendalam pra-latihan, penyelidikan dalam talian dan luar talian sudah memadai.
- Latihan tersuai bagi model pembelajaran mendalam menggunakan teknik pembelajaran pemindahan