
Rumah >Peranti teknologi >AI >Panjang konteks LLaMA2 melonjak kepada 1 juta token, dengan hanya satu hiperparameter perlu dilaraskan.
Panjang konteks LLaMA2 melonjak kepada 1 juta token, dengan hanya satu hiperparameter perlu dilaraskan.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-10-21 14:25:01843semak imbas
Dengan hanya beberapa tweak, saiz konteks sokongan model besar boleh dilanjutkan daripada 16,000 token kepada 1 juta? !
Masih on LLaMA 2 yang hanya mempunyai 7 bilion parameter.
Anda mesti tahu bahawa Claude 2 dan GPT-4 yang popular pada masa ini menyokong panjang konteks hanya 100,000 dan 32,000 Di luar julat ini, model besar akan mula bercakap kosong dan tidak dapat mengingati sesuatu.
Kini, kajian baharu dari Universiti Fudan dan Makmal Kepintaran Buatan Shanghai bukan sahaja menemui cara untuk meningkatkan panjang tetingkap konteks untuk satu siri model besar, tetapi juga menemui peraturan.

Mengikut peraturan ini, hanya perlu melaraskan 1 hiperparameter, boleh memastikan kesan output sambil meningkatkan prestasi ekstrapolasi model besar secara stabil.
Ekstrapolasi merujuk kepada perubahan dalam prestasi output apabila panjang input model besar melebihi panjang teks pra-latihan. Jika keupayaan ekstrapolasi tidak baik, apabila panjang input melebihi panjang teks pra-latihan, model besar akan "bercakap bukan-bukan".
Jadi, apakah sebenarnya ia boleh meningkatkan keupayaan ekstrapolasi model besar, dan bagaimana ia melakukannya?
"Mekanisme" untuk meningkatkan keupayaan ekstrapolasi model besar
Kaedah meningkatkan keupayaan ekstrapolasi model besar ini berkaitan dengan modul yang dipanggil Pengekodan Kedudukan dalam seni bina Transformer.
Malah, modul mekanisme perhatian mudah (Perhatian) tidak dapat membezakan token dalam kedudukan yang berbeza Sebagai contoh, "Saya makan epal" dan "epal makan saya" tidak mempunyai perbezaan di matanya.
Oleh itu, pengekodan kedudukan perlu ditambah untuk membolehkannya memahami maklumat susunan perkataan dan benar-benar memahami maksud sesuatu ayat.
Kaedah pengekodan kedudukan Transformer semasa termasuk pengekodan kedudukan mutlak (mengintegrasikan maklumat kedudukan ke dalam input), pengekodan kedudukan relatif (menulis maklumat kedudukan ke dalam pengiraan skor perhatian) dan pengekodan kedudukan putaran. Antaranya, yang paling popular ialah pengekodan kedudukan putaran, iaitu RoPE.
RoPE mencapai kesan pengekodan kedudukan relatif melalui pengekodan kedudukan mutlak, tetapi berbanding dengan pengekodan kedudukan relatif, ia boleh meningkatkan potensi ekstrapolasi model besar dengan lebih baik.
Cara untuk merangsang lagi keupayaan ekstrapolasi model besar menggunakan pengekodan kedudukan RoPE juga telah menjadi hala tuju baharu dalam banyak kajian terkini.
Kajian ini terbahagi terutamanya kepada dua sekolah utama: menghadkan perhatian dan melaraskan sudut putaran.
Penyelidikan perwakilan tentang mengehadkan perhatian termasuk ALiBi, xPos, BCA, dsb. StreamingLLM baru-baru ini dicadangkan oleh MIT boleh membenarkan model besar mencapai panjang input tak terhingga (tetapi tidak meningkatkan panjang tetingkap konteks), yang tergolong dalam jenis penyelidikan ke arah ini.
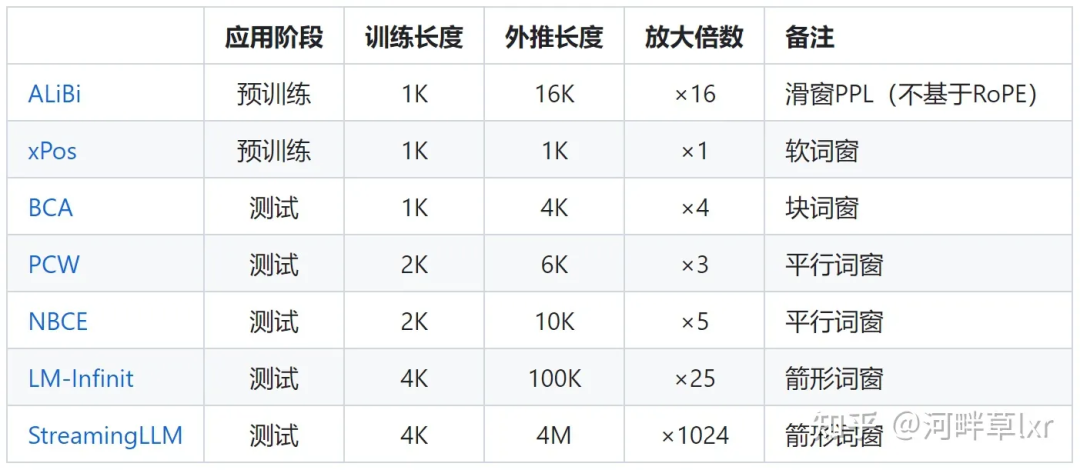
△Pengarang sumber imej
mempunyai lebih banyak kerja yang perlu dilakukan untuk melaraskan sudut putaran Perwakilan biasa seperti interpolasi linear, Zirafah, Kod LLaMA, LLaMA2 Panjang, dll. semuanya tergolong dalam jenis penyelidikan ini. .
Hiperparameter ini betul-betul "suis"  ditemui oleh Kod LLaMA dan LLaMA2 Long dan kajian lain -
ditemui oleh Kod LLaMA dan LLaMA2 Long dan kajian lain -
pangkal sudut putaran 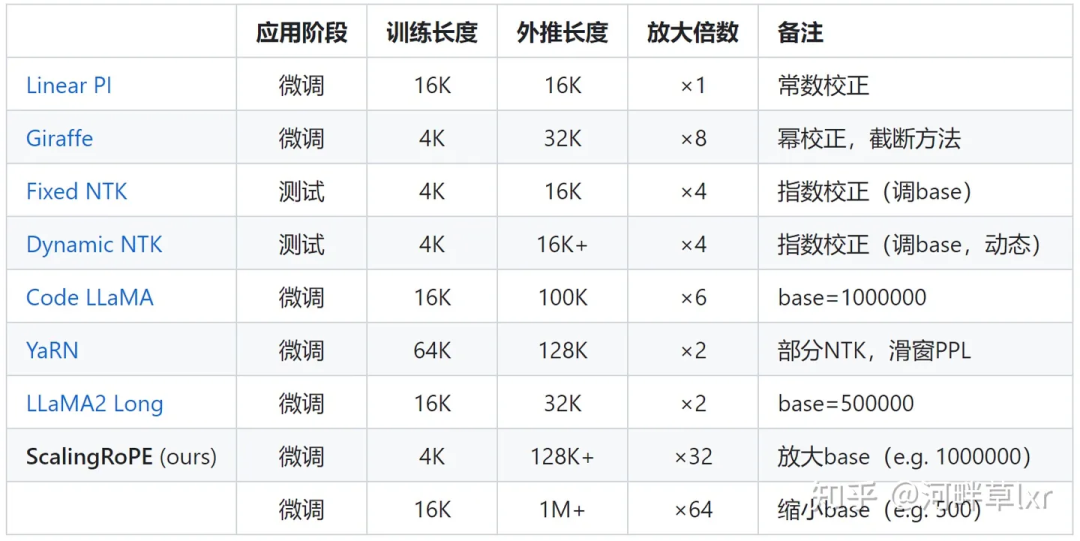 ditemui oleh Kod LLaMA dan LLaMA2 Long dan kajian lain -
ditemui oleh Kod LLaMA dan LLaMA2 Long dan kajian lain - (tapak). Hanya memperhalusinya untuk memastikan prestasi ekstrapolasi yang lebih baik bagi model besar.
Tetapi sama ada Kod LLaMA atau LLaMA2 Long, mereka hanya diperhalusi pada asas tertentu dan tempoh latihan berterusan untuk meningkatkan keupayaan ekstrapolasi mereka. Bolehkah kami mencari peraturan untuk memastikan
semuamodel besar yang menggunakan pengekodan kedudukan RoPE dapat meningkatkan prestasi ekstrapolasi secara stabil? Kuasai peraturan ini, konteksnya mudah 100w+
Penyelidik dari Universiti Fudan dan Institut Penyelidikan AI Shanghai menjalankan eksperimen tentang masalah ini.
Mereka mula-mula menganalisis beberapa parameter yang mempengaruhi keupayaan ekstrapolasi RoPE, dan mencadangkan konsep yang dipanggil
Dimensi Kritikal(Dimensi Kritikal Kemudian berdasarkan konsep ini, mereka meringkaskan satu set Undang-undang Penskalaan Penskalaan RoPE bagi Ekstrapolasi berasaskan RoPE).
Hanya gunakanundang
ini untuk memastikan mana-mana model besar berdasarkan pengekodan kedudukan RoPE boleh meningkatkan keupayaan ekstrapolasi. Mari kita lihat dahulu apakah dimensi kritikal itu.Daripada definisi, ia berkaitan dengan Ttrain panjang teks pra-latihan, bilangan dimensi kepala perhatian diri d dan parameter lain Kaedah pengiraan khusus adalah seperti berikut:

Antaranya, 10000 ialah "nilai awal" hiperparameter dan tapak sudut putaran.
Penulis mendapati bahawa sama ada tapak dibesarkan atau dikurangkan, keupayaan ekstrapolasi model besar berdasarkan RoPE boleh dipertingkatkan pada akhirnya, sebaliknya, apabila asas sudut putaran ialah 10000, keupayaan ekstrapolasi model besar adalah yang paling teruk.
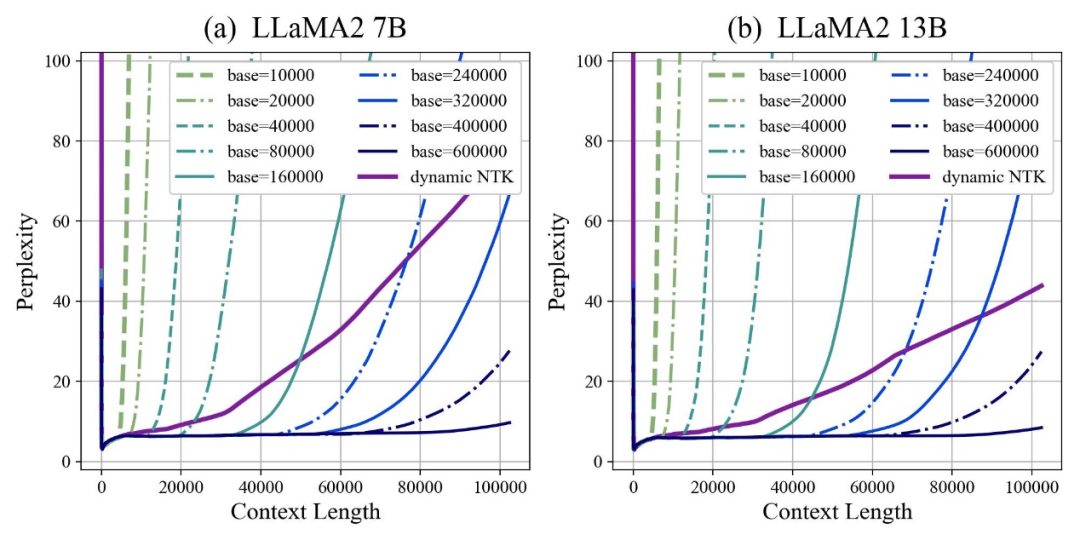
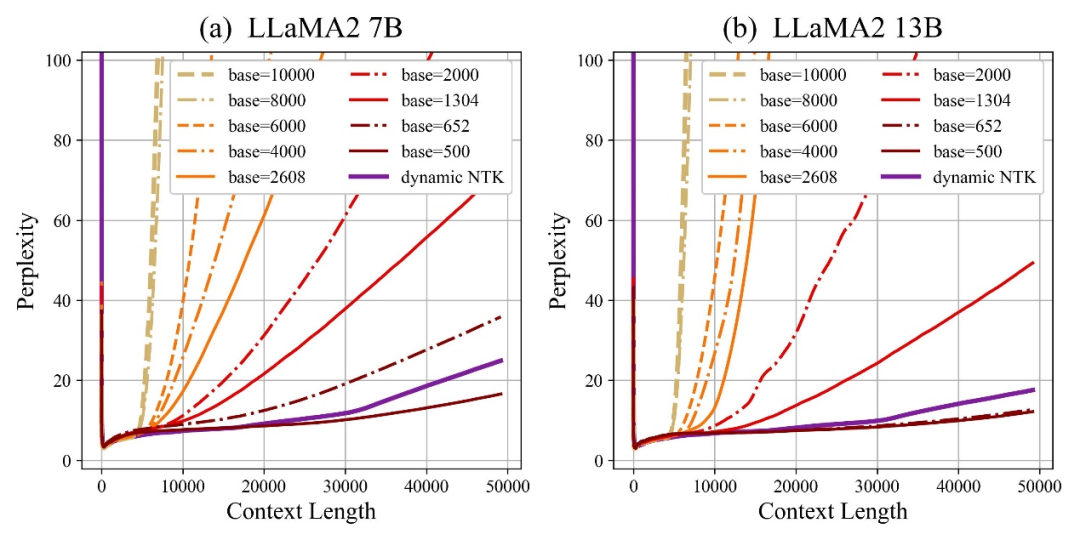
Makalah ini percaya bahawa asas sudut putaran yang lebih kecil boleh membolehkan maklumat kedudukan dilihat dalam lebih banyak dimensi asas sudut putaran, lebih lama maklumat kedudukan boleh dinyatakan.
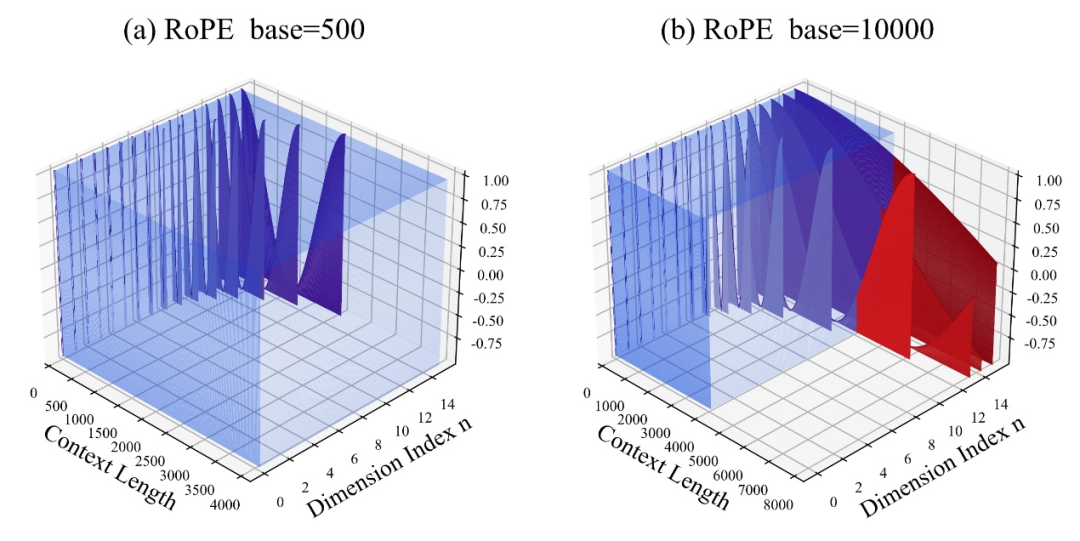
Dalam kes ini, apabila menghadapi korpus latihan berterusan dengan panjang yang berbeza, berapa banyak asas sudut putaran perlu dikurangkan dan dibesarkan untuk memastikan maksimum Adakah keupayaan ekstrapolasi model telah dimaksimumkan?
Kertas memberikan peraturan penskalaan untuk ekstrapolasi RoPE lanjutan, yang berkaitan dengan parameter seperti dimensi kritikal, panjang teks latihan berterusan dan panjang teks pra-latihan model besar:
#🎜🎜 ## 🎜🎜# Berdasarkan peraturan ini, prestasi ekstrapolasi model besar boleh dikira terus berdasarkan pra-latihan yang berbeza dan panjang teks latihan berterusan Dengan kata lain, panjang konteks yang disokong oleh model besar diramalkan.
Berdasarkan peraturan ini, prestasi ekstrapolasi model besar boleh dikira terus berdasarkan pra-latihan yang berbeza dan panjang teks latihan berterusan Dengan kata lain, panjang konteks yang disokong oleh model besar diramalkan.
Sebaliknya, menggunakan peraturan ini, anda boleh dengan cepat menyimpulkan cara terbaik melaraskan asas sudut putaran, dengan itu meningkatkan prestasi ekstrapolasi model besar.
Penulis menguji siri tugasan ini dan mendapati bahawa pada masa ini memasukkan 100,000, 500,000 atau 1 juta panjang token boleh menjamin bahawa ekstrapolasi boleh dicapai tanpa sekatan perhatian tambahan.
Pada masa yang sama, usaha untuk meningkatkan keupayaan ekstrapolasi model besar, termasuk Kod LLaMA dan LLaMA2 Long, telah membuktikan bahawa peraturan ini sememangnya munasabah dan berkesan.
Dengan cara ini, anda hanya perlu "melaraskan parameter" mengikut peraturan ini, dan anda boleh mengembangkan panjang tetingkap konteks model besar dengan mudah berdasarkan RoPE dan meningkatkan keupayaan ekstrapolasi.
Liu Xiaoran, pengarang pertama kertas itu, berkata bahawa penyelidikan ini masih menambah baik kesan tugasan hiliran dengan menambah baik korpus latihan yang berterusan Setelah selesai, kod dan model akan menjadi sumber terbuka nantikan~
# 🎜🎜#Alamat kertas:
https://arxiv.org/abs/2310.05209#🎜🎜 #
# 🎜🎜#Repositori Github:
https://github.com/OpenLMLab/scaling-rope#🎜🎜 🎜🎜##🎜🎜 #thesisanalyticsblog:
https://zhuanlan.zhihu.com/p/66007##3229🎜🎜🎜🎜
Atas ialah kandungan terperinci Panjang konteks LLaMA2 melonjak kepada 1 juta token, dengan hanya satu hiperparameter perlu dilaraskan.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!