
Rumah >Peranti teknologi >AI >Dengan hampir separuh parameter, prestasinya hampir dengan Google Minerva, satu lagi model matematik besar ialah sumber terbuka
Dengan hampir separuh parameter, prestasinya hampir dengan Google Minerva, satu lagi model matematik besar ialah sumber terbuka

- PHPzke hadapan
- 2023-10-21 14:13:011298semak imbas
Kini, model bahasa yang dilatih pada pelbagai data campuran teks akan menunjukkan pemahaman bahasa yang sangat umum dan keupayaan penjanaan dan boleh digunakan sebagai model asas untuk menyesuaikan diri dengan pelbagai aplikasi. Aplikasi seperti dialog terbuka atau penjejakan arahan memerlukan prestasi seimbang merentasi keseluruhan pengedaran teks semula jadi dan oleh itu memilih model tujuan umum.
Tetapi jika anda ingin memaksimumkan prestasi dalam domain tertentu (seperti perubatan, kewangan atau sains), model bahasa khusus domain mungkin memberikan keupayaan yang lebih baik pada kos pengiraan tertentu, atau pada kos yang lebih tinggi kos pengiraan menyediakan tahap keupayaan tertentu.
Penyelidik dari Princeton University, EleutherAI dan yang lain telah melatih model bahasa khusus domain untuk menyelesaikan masalah matematik. Mereka percaya bahawa: pertama, menyelesaikan masalah matematik memerlukan padanan corak dengan sejumlah besar pengetahuan sedia ada profesional, jadi ia adalah persekitaran yang ideal untuk latihan penyesuaian domain kedua, penaakulan matematik itu sendiri adalah tugas utama AI; penaakulan matematik yang kukuh Model bahasa ialah huluan bagi banyak topik penyelidikan, seperti pemodelan ganjaran, pembelajaran peneguhan inferens dan penaakulan algoritma.
Oleh itu, mereka mencadangkan kaedah untuk menyesuaikan model bahasa kepada matematik melalui pra-latihan berterusan Proof-Pile-2. Proof-Pile-2 ialah gabungan teks dan kod berkaitan matematik. Menggunakan pendekatan ini pada Kod Llama menghasilkan LLEMMA: model bahasa asas untuk 7B dan 34B, dengan keupayaan matematik yang sangat dipertingkatkan.

Alamat kertas: https://arxiv.org/pdf/2310.10631.pdf
Alamat projek: https://github.com/EleutherAi Prestasi Matematik 4 pukulan 7B jauh melebihi prestasi Google Minerva 8B dan prestasi LLEMMA 34B adalah hampir dengan prestasi Minerva 62B dengan hampir separuh parameter.
 Secara khusus, sumbangan artikel ini adalah seperti berikut:
Secara khusus, sumbangan artikel ini adalah seperti berikut:
1 Melatih dan mengeluarkan model LLEMMA: model bahasa 7B dan 34B khusus untuk matematik. Model LLEMMA ialah model terkini dalam model asas yang dikeluarkan secara umum di MATH.
- 2. AlgebraicStack yang dikeluarkan, set data yang mengandungi token kod 11B yang khusus berkaitan dengan matematik.
- 3. Menunjukkan bahawa LLEMMA mampu menyelesaikan masalah matematik menggunakan alat pengiraan, iaitu penterjemah Python dan prover teorem formal.
- 4. Tidak seperti model bahasa matematik sebelumnya (seperti Minerva), model LLEMMA bersifat terbuka. Para penyelidik membuat data latihan dan kod tersedia kepada orang ramai. Ini menjadikan LLEMMA sebagai platform untuk penyelidikan masa depan dalam penaakulan matematik.
- Gambaran Keseluruhan Kaedah
LLEMMA ialah model bahasa 70B dan 34B yang digunakan khusus dalam matematik. Ia diperoleh dengan meneruskan pra-latihan kod Llama pada Proof-Pile-2.
 DATA: Proof-Pile-2
DATA: Proof-Pile-2
Para penyelidik mencipta Proof-Pile-Pile-2, yang mengandungi data Proof-Pile-2, yang mengandungi data saintifik 55, yang mengandungi Proof-Pile-2, yang mengandungi data saintifik A55 kod matematik. Tarikh akhir pengetahuan untuk Proof-Pile-2 ialah April 2023, kecuali untuk subset proofsteps Lean.

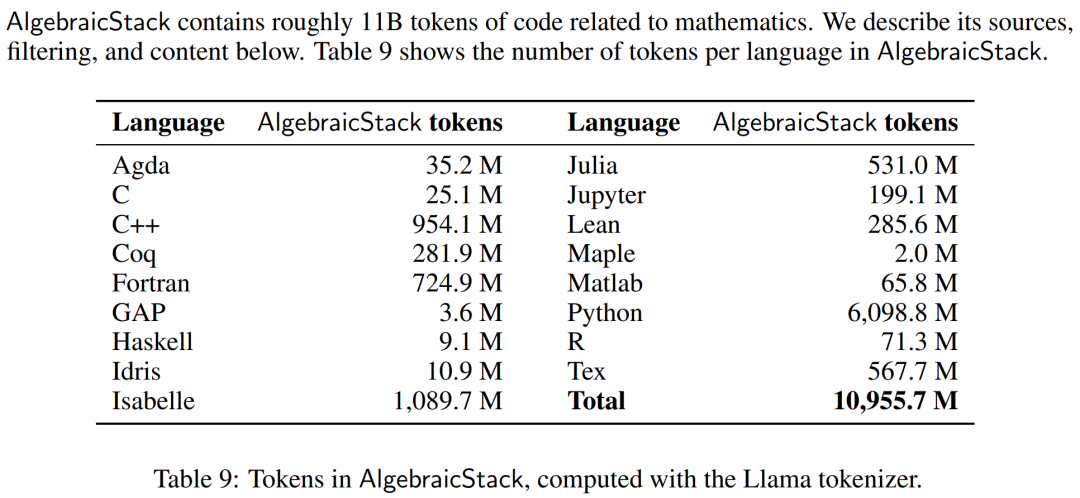
Para penyelidik menggunakan OpenWebMath, set data token 15B yang terdiri daripada halaman web berkualiti tinggi, ditapis untuk kandungan matematik. OpenWebMath menapis halaman web CommonCrawl berdasarkan kata kunci berkaitan matematik dan markah matematik berasaskan pengelas, mengekalkan pemformatan matematik (cth., LATEX, AsciiMath), dan termasuk penapis kualiti tambahan (cth., plexity, domain, length) dan hampir-duplikasi. Selain itu, penyelidik juga menggunakan subset ArXiv bagi RedPajama, yang merupakan paparan terbuka set data latihan LLaMA. Subset ArXiv mengandungi 29B ketulan. Campuran latihan terdiri daripada sejumlah kecil data domain umum dan bertindak sebagai penyelaras. Memandangkan set data pra-latihan untuk LLaMA 2 belum lagi tersedia secara terbuka, penyelidik menggunakan Pile sebagai set data latihan alternatif. Model dan latihan Setiap model dimulakan daripada Kod Llama, yang seterusnya dimulakan daripada Llama 2, menggunakan struktur pengubah dekonder sahaja, dengan token kod 500B Diperbuat daripada latihan. Para penyelidik terus melatih model Code Llama pada Proof-Pile-2 menggunakan objektif pemodelan bahasa autoregresif standard. Di sini, model LLEMMA 7B mempunyai token 200B dan model LLEMMA 34B mempunyai token 50B. Para penyelidik menggunakan perpustakaan GPT-NeoX untuk melatih dua model di atas dengan ketepatan campuran bfloat16 pada 256 A100 40GB GPU. Mereka menggunakan selari tensor dengan saiz dunia 2 untuk LLEMMA-7B dan selari tensor dengan saiz dunia 8 untuk 34B, serta keadaan pengoptimum serpihan Peringkat ZeRO 1 merentas replika selari data. Flash Attention 2 juga digunakan untuk meningkatkan daya pengeluaran dan seterusnya mengurangkan keperluan memori. LLEMMA 7B telah dilatih untuk 42,000 langkah, dengan saiz kelompok global sebanyak 4 juta token dan panjang konteks sebanyak 4096 token. Ini bersamaan dengan 23,000 A100 jam. Kadar pembelajaran meningkat sehingga 1·10^−4 selepas 500 langkah dan kemudian pereputan kosinus kepada 1/30 daripada kadar pembelajaran maksimum selepas 48,000 langkah. LLEMMA 34B telah dilatih untuk 12,000 langkah, saiz kelompok global juga ialah 4 juta token, dan panjang konteks ialah 4096. Ini bersamaan dengan 47,000 A100 jam. Kadar pembelajaran menjadi panas sehingga 5·10^−5 selepas 500 langkah, dan kemudian mereput kepada 1/30 daripada kadar pembelajaran puncak. Di bahagian eksperimen, penyelidik bertujuan untuk menilai sama ada LLEMMA boleh digunakan sebagai model asas untuk teks matematik. Mereka menggunakan penilaian beberapa pukulan untuk membandingkan model LLEMMA dan menumpukan terutamanya pada model SOTA yang tidak diperhalusi pada sampel tugasan matematik yang diselia. Para penyelidik mula-mula menggunakan penaakulan rantaian pemikiran dan kaedah undian majoriti untuk menilai keupayaan LLEMMA untuk menyelesaikan masalah matematik. Penanda aras penilaian termasuk MATH dan GSM8k. Kemudian terokai penggunaan alat beberapa pukulan dan pembuktian teorem. Akhirnya, kesan memori dan percampuran data dikaji. Selesaikan masalah matematik menggunakan Chains of Thoughts (CoT) Tugas ini termasuk menjana jawapan tekstual bebas kepada soalan yang diwakili dalam LATEX atau bahasa semula jadi tanpa memerlukan alat luaran. Penanda aras penilaian yang digunakan oleh penyelidik termasuk MATH, GSM8k, OCWCourses, SAT dan MMLU-STEM. Hasilnya ditunjukkan dalam Jadual 1 di bawah pra-latihan berterusan LLEMMA pada korpus Proof-Pile-2 telah meningkatkan prestasi beberapa sampel pada 5 penanda aras matematik Antaranya, LLEMMA 34B telah meningkat sebanyak 20 mata pada GSM8k daripada mata peratusan Kod Llama, 13 mata peratusan lebih tinggi daripada Kod Llama pada MATH. Pada masa yang sama LLEMMA 7B mengatasi prestasi model Minerva proprietari. Oleh itu, penyelidik membuat kesimpulan bahawa pra-latihan berterusan pada Proof-Pile-2 dapat membantu meningkatkan keupayaan model pra-latihan untuk menyelesaikan masalah matematik. Gunakan alatan untuk menyelesaikan masalah matematik Tugas ini termasuk menggunakan alat pengiraan untuk menyelesaikan masalah. Penanda aras penilaian yang digunakan oleh penyelidik termasuk MATH+Python dan GSM8k+Python. Keputusan ditunjukkan dalam Jadual 3 di bawah, LLEMMA mengatasi Kod Llama pada kedua-dua tugas. Prestasi pada MATH dan GSM8k menggunakan kedua-dua alatan juga lebih baik daripada tanpa alatan. Matematik Formal #🎜🎜 #Proof-Pile-2 set data AlgebraicStack memegang 1.5 bilion token data matematik formal, termasuk bukti rasmi yang diekstrak daripada Lean dan Isabelle. Walaupun kajian penuh matematik formal berada di luar skop artikel ini, kami menilai prestasi beberapa pukulan LLEMMA pada dua tugasan berikut. Tidak rasmi kepada tugas pembuktian rasmi, iaitu, diberi tugas pembuktian rasmi Dalam kes proposisi LATEX tidak rasmi dan bukti LATEX tidak rasmi, hasilkan bukti rasmi ) untuk membuktikan proposisi formal. Keputusan ditunjukkan dalam Jadual 4 di bawah pra-latihan berterusan LLEMMA pada Proof-Pile-2 meningkatkan prestasi beberapa sampel pada dua tugas pembuktian teorem formal. Kesan pencampuran data #🎜🎜 model latihan bahasa , pendekatan yang biasa adalah untuk upsample subset berkualiti tinggi data latihan berdasarkan berat campuran. Para penyelidik memilih pemberat adunan dengan melakukan latihan singkat pada beberapa pemberat adunan yang dipilih dengan teliti. Pemberat pencampuran kemudiannya dipilih yang meminimumkan kebingungan pada set teks yang dipegang berkualiti tinggi (di sini set latihan MATH telah digunakan).
Untuk butiran teknikal dan keputusan penilaian, sila rujuk kepada kertas asal . Hasil penilaian




Atas ialah kandungan terperinci Dengan hampir separuh parameter, prestasinya hampir dengan Google Minerva, satu lagi model matematik besar ialah sumber terbuka. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!