
Rumah >Peranti teknologi >AI >Tingkatkan kecekapan kejuruteraan - penjanaan carian dipertingkat (RAG)
Tingkatkan kecekapan kejuruteraan - penjanaan carian dipertingkat (RAG)

- 王林ke hadapan
- 2023-10-14 20:17:011507semak imbas
Dengan kemunculan model bahasa berskala besar seperti GPT-3, penemuan besar telah dibuat dalam bidang pemprosesan bahasa semula jadi (NLP). Model bahasa ini mempunyai keupayaan untuk menjana teks seperti manusia dan telah digunakan secara meluas dalam pelbagai senario seperti chatbots dan terjemahan

Walau bagaimanapun, apabila ia berkaitan dengan senario aplikasi khusus dan tersuai, model bahasa besar tujuan umum Mungkin terdapat menjadi kekurangan dalam pengetahuan profesional. Penalaan halus model ini dengan korpora khusus selalunya mahal dan memakan masa. "Retrieval Enhanced Generation" (RAG) menyediakan penyelesaian teknologi baharu untuk aplikasi profesional.
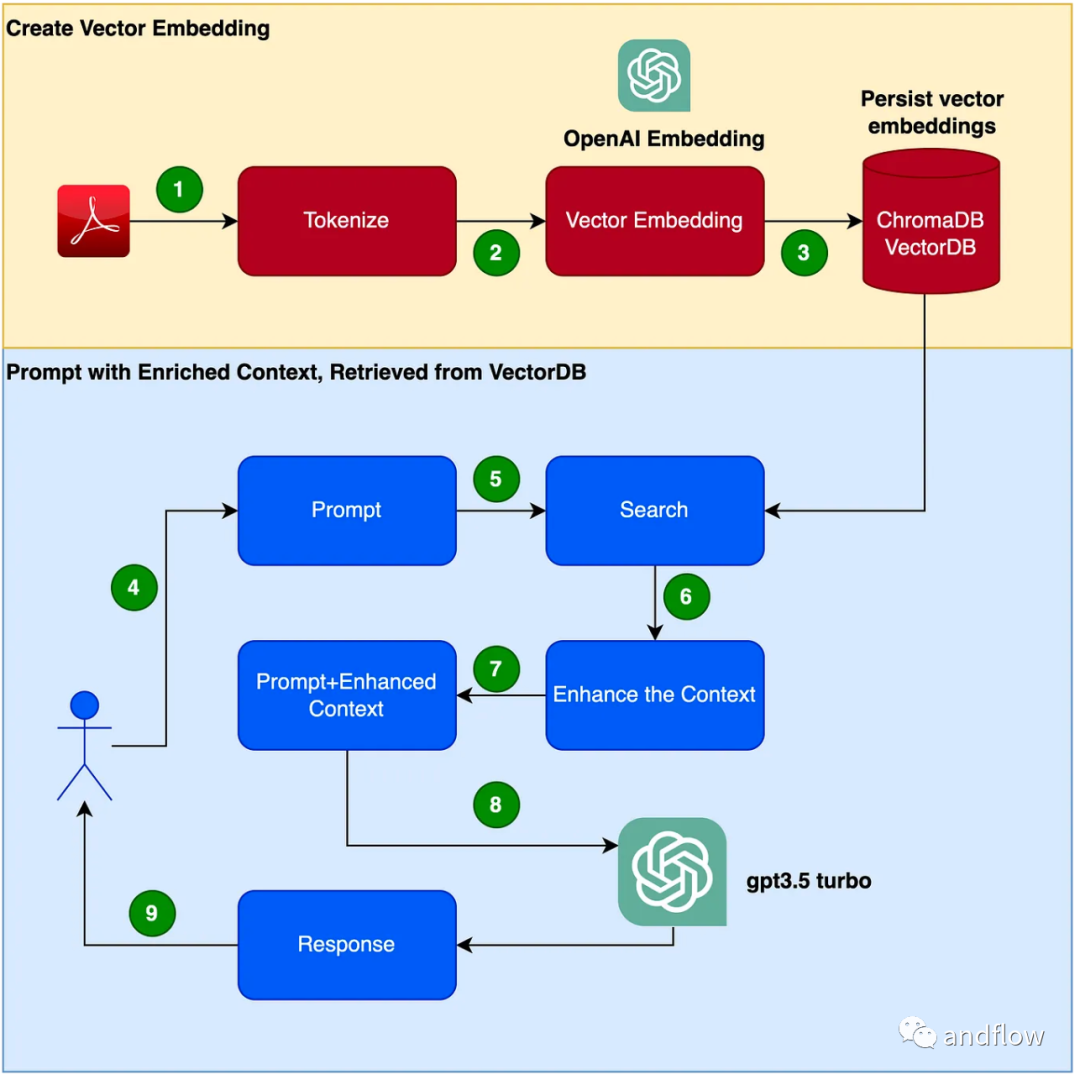
Di bawah ini kami memperkenalkan terutamanya cara RAG berfungsi, dan menggunakan contoh praktikal untuk menggunakan manual produk sebagai korpus profesional dan menggunakan GPT-3.5 Turbo sebagai model soal jawab untuk mengesahkan keberkesanannya.
Kes: Bangunkan chatbot yang mampu menjawab soalan berkaitan produk tertentu. Perniagaan ini mempunyai manual pengguna yang unik
Pengenalan kepada RAG
RAG menyediakan penyelesaian yang berkesan untuk soalan dan jawapan khusus domain. Ia terutamanya menukar pengetahuan industri kepada vektor untuk penyimpanan dan pengambilan, menggabungkan hasil carian dengan soalan pengguna untuk membentuk maklumat segera, dan akhirnya menggunakan model besar untuk menjana jawapan yang sesuai. Dengan menggabungkan mekanisme perolehan semula dan model bahasa, responsif model dipertingkatkan dengan sangat baik
Langkah-langkah untuk mencipta program chatbot adalah seperti berikut:
- Baca PDF (fail PDF manual pengguna) dan tandakannya menggunakan chunk_size untuk 1000 token .
- Buat vektor (anda boleh menggunakan OpenAI EmbeddingsAPI untuk mencipta vektor).
- Simpan vektor dalam perpustakaan vektor tempatan. Kami akan menggunakan ChromaDB sebagai pangkalan data vektor (pangkalan data vektor juga boleh digantikan dengan Pinecone atau produk lain).
- Pengguna menyiarkan petua dengan pertanyaan/pertanyaan.
- Dapatkan data konteks pengetahuan daripada pangkalan data vektor berdasarkan soalan pengguna. Data konteks pengetahuan ini akan digunakan bersama-sama dengan kata-kata kiu dalam langkah-langkah seterusnya untuk meningkatkan kata-kata kiu, sering dirujuk sebagai pengayaan kontekstual.
- Kata gesaan yang mengandungi soalan pengguna dihantar ke LLM bersama-sama dengan pengetahuan kontekstual yang dipertingkatkan
- Jawapan LLM berdasarkan konteks ini.
Pembangunan tangan
(1) Sediakan persekitaran maya Python Sediakan persekitaran maya untuk sandbox Python kami untuk mengelakkan sebarang versi atau konflik pergantungan. Jalankan arahan berikut untuk mencipta persekitaran maya Python baharu.
需要重写的内容是:pip安装virtualenv,python3 -m venv ./venv,source venv/bin/activate
Kandungan yang perlu ditulis semula ialah: (2) Jana kunci OpenAI
Menggunakan GPT memerlukan kunci OpenAI untuk akses
Kandungan yang perlu ditulis semula ialah: (3) Pasang perpustakaan bergantung
Pelbagai kebergantungan diperlukan oleh pemasang. Termasuk perpustakaan berikut:
- lanchain: rangka kerja untuk membangunkan aplikasi LLM.
- chromaDB: Ini ialah VectorDB untuk pembenaman vektor berterusan.
- tidak berstruktur: digunakan untuk pramemproses dokumen Word/PDF.
- tiktoken: Rangka kerja Tokenizer
- pypdf: Rangka kerja untuk membaca dan memproses dokumen PDF.
- openai: Akses rangka kerja OpenAI.
pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openai
Buat pembolehubah persekitaran untuk menyimpan kunci OpenAI.
export OPENAI_API_KEY=<openai-key></openai-key>
(4) Tukar fail PDF manual pengguna kepada vektor dan simpan dalam ChromaDB
Import semua perpustakaan dan fungsi bergantung yang perlu anda gunakan
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChain
untuk membaca PDF, tokenize dokumen dan pisahkan dokumen .
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)
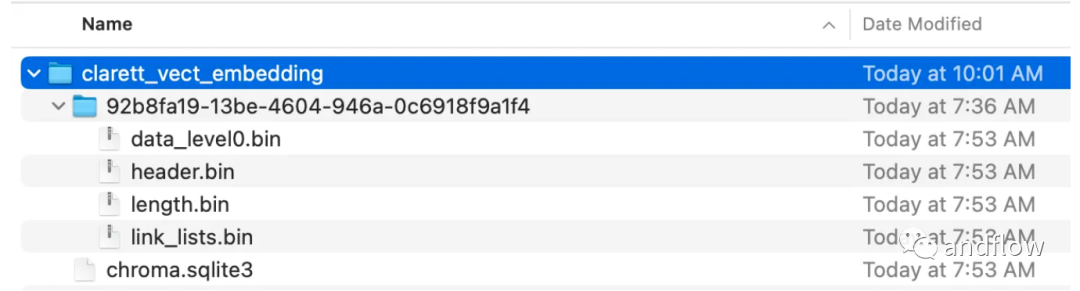
Buat koleksi kroma dan direktori setempat untuk menyimpan data kroma. Kemudian, buat vektor (benam) dan simpan dalam ChromaDB.
collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData,embeddings,collection_name=collection_name,persist_directory=persist_directory)vectDB.persist()
Selepas melaksanakan kod ini, anda sepatutnya melihat folder yang telah dibuat untuk menyimpan vektor.
Selepas pembenaman vektor disimpan dalam ChromaDB, anda boleh menggunakan ConversationalRetrievalChain API dalam LangChain untuk memulakan komponen sejarah sembang
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm(OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)
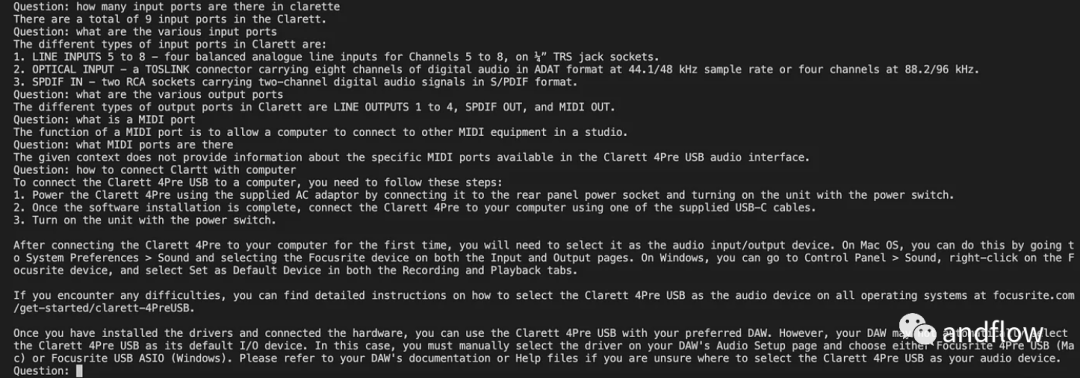
Selepas memulakan langchan, kami boleh menggunakannya untuk bersembang/Q A. Dalam kod di bawah, soalan yang dimasukkan oleh pengguna diterima, dan selepas pengguna memasukkan 'selesai', soalan itu diserahkan kepada LLM untuk mendapatkan balasan dan mencetaknya.
chat_history = []qry = ""while qry != 'done':qry = input('Question: ')if qry != exit:response = chatQA({"question": qry, "chat_history": chat_history})print(response["answer"])

Ringkasnya
RAG menggabungkan kelebihan model bahasa seperti GPT dengan kelebihan pencarian maklumat. Dengan menggunakan maklumat konteks pengetahuan khusus untuk meningkatkan kekayaan kata-kata pantas, model bahasa dapat menjana jawapan berkaitan konteks pengetahuan yang lebih tepat. RAG menyediakan penyelesaian yang lebih cekap dan kos efektif daripada "penalaan halus", menyediakan penyelesaian interaktif yang boleh disesuaikan untuk aplikasi industri atau aplikasi perusahaan
Atas ialah kandungan terperinci Tingkatkan kecekapan kejuruteraan - penjanaan carian dipertingkat (RAG). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!