
Rumah >Peranti teknologi >AI >Apabila menyerahkan kertas kerja anda kepada Nature, tanya tentang GPT-4 dahulu! Stanford sebenarnya menguji 5,000 artikel, dan separuh daripada pendapat adalah sama dengan pengulas manusia
Apabila menyerahkan kertas kerja anda kepada Nature, tanya tentang GPT-4 dahulu! Stanford sebenarnya menguji 5,000 artikel, dan separuh daripada pendapat adalah sama dengan pengulas manusia

- PHPzke hadapan
- 2023-10-06 14:37:061761semak imbas
Adakah GPT-4 mampu semakan kertas?
Penyelidik dari Stanford dan universiti lain sebenarnya telah mengujinya.
Mereka melemparkan ribuan artikel dari persidangan teratas seperti Nature dan ICLR ke GPT-4, biarkan ia menjana pendapat ulasan (termasuk cadangan pengubahsuaian dan sebagainya) , dan kemudian membandingkannya dengan pendapat yang diberikan oleh manusia.
Selepas disiasat, kami mendapati bahawa:
Lebih daripada 50% pendapat yang dicadangkan oleh GPT-4 adalah konsisten dengan sekurang-kurangnya seorang pengulas manusia
Dan lebih daripada 82.4% daripada pengarang yang mendapati; pendapat yang diberikan oleh GPT-4 Sangat membantu
Apakah pandangan yang boleh dibawa oleh penyelidikan ini kepada kita?
Kesimpulannya ialah:
Masih tiada pengganti untuk maklum balas manusia yang berkualiti tinggi; tetapi GPT-4 boleh membantu pengarang memperbaiki draf pertama mereka sebelum semakan rakan sebaya rasmi.

saluran paip automatik menggunakan GPT-4.
Ia boleh menganalisis keseluruhan kertas dalam format PDF, mengekstrak tajuk, abstrak, rajah, tajuk jadual dan kandungan lain untuk membuat gesaandan kemudian biarkan GPT-4 memberikan ulasan ulasan. Antaranya, pendapat adalah sama dengan piawaian setiap persidangan teratas, dan termasuk empat bahagian: Kepentingan dan kebaharuan penyelidikan, serta sebab kemungkinan penerimaan atau penolakan dan cadangan penambahbaikan 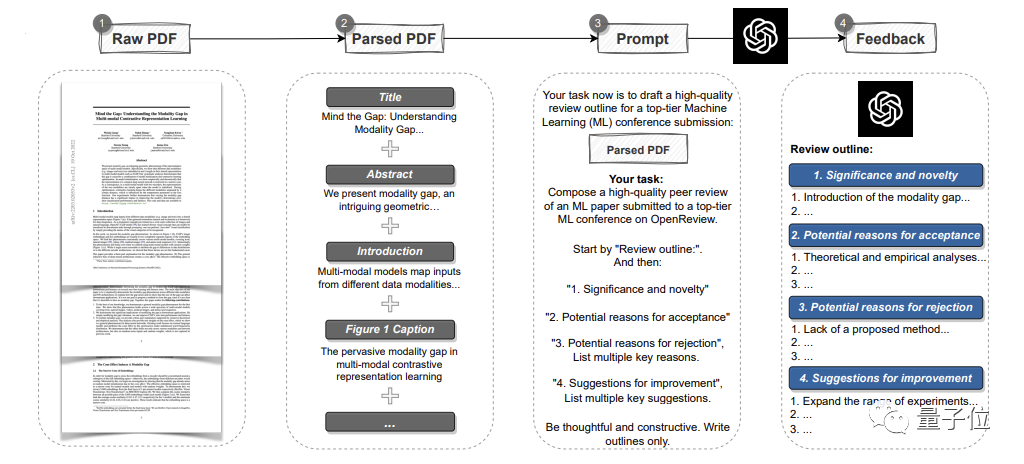
Dua aspek terungkap.
Yang pertama ialah eksperimen kuantitatif:
Baca kertas sedia ada, jana maklum balas, dan bandingkan secara sistematik dengan pendapat manusia sebenar untuk mengetahui pertindihanDi sini, pasukan mengumpul data daripada jurnal Nature utama dan sub major -jurnal 3096 artikel dipilih, 1709 artikel dipilih daripada Persidangan Pembelajaran Mesin ICLR(termasuk tahun lepas dan tahun ini) , untuk jumlah 4805 artikel.
Antaranya, kertas kerja Alam melibatkan sebanyak 8,745 ulasan ulasan manusia melibatkan 6,506 ulasan.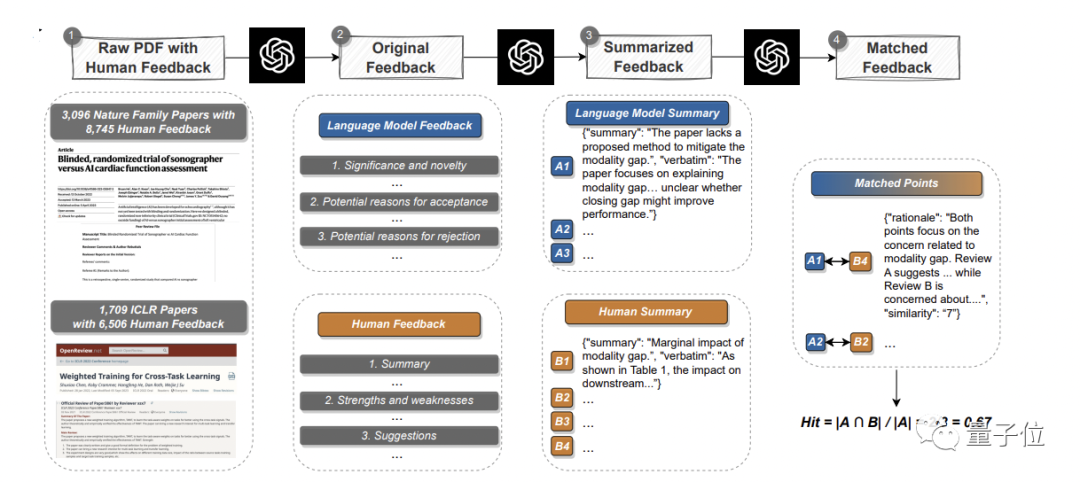
1. Pendapat GPT-4 secara ketara bertindih dengan pendapat sebenar pengulas manusia
Secara keseluruhan, dalam kertas kerja Alam, 57.55% daripada pendapat GPT-4 adalah konsisten dengan sekurang-kurangnya seorang pengulas manusia ; ICLR, angka ini setinggi 77.18%.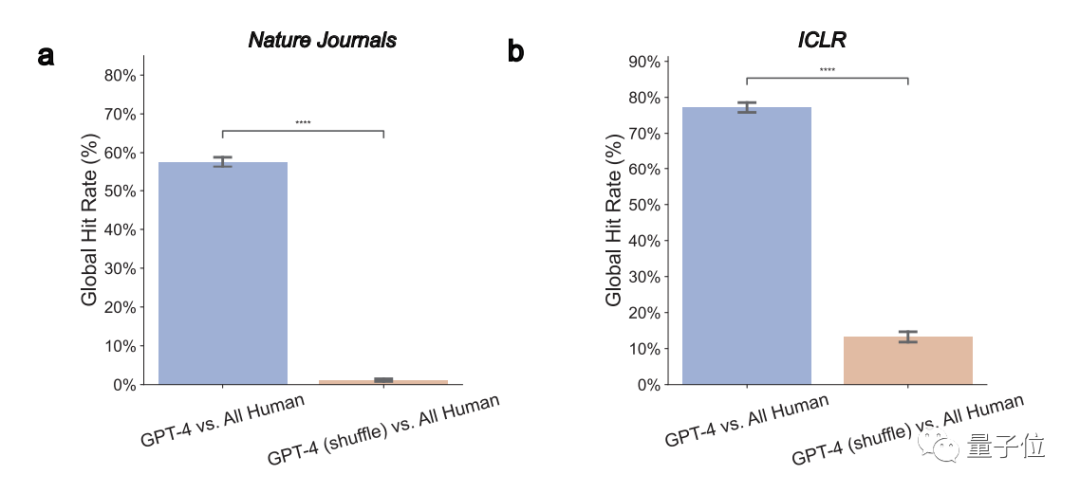
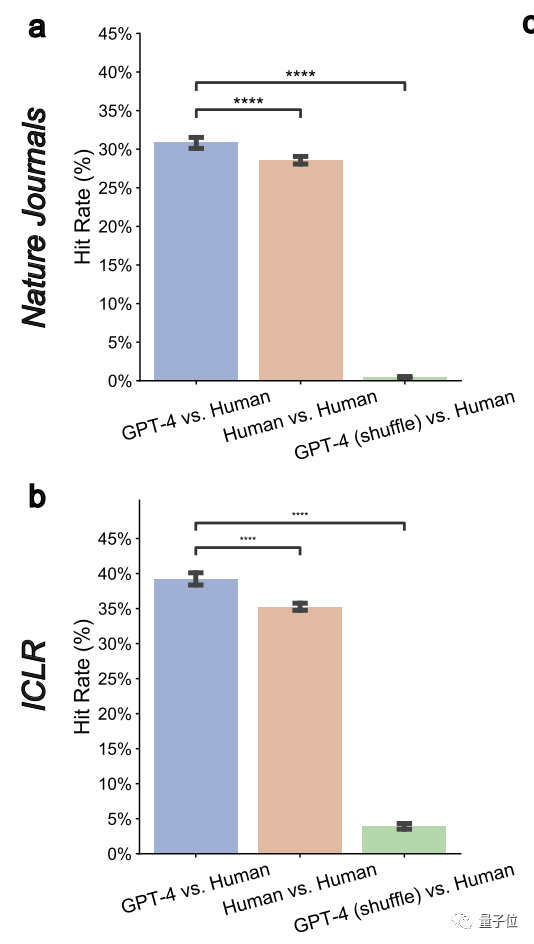
Untuk kertas dengan gred yang lebih lemah, kadar pertindihan antara GPT-4 dan penyemak manusia dijangka meningkat. Daripada semasa lebih daripada 30%, ia boleh ditingkatkan kepada hampir 50%
Ini menunjukkan bahawa GPT-4 mempunyai keupayaan diskriminasi yang tinggi dan boleh mengenal pasti kertas yang tidak berkualitiPenulis juga menyatakan bahawa mereka yang memerlukan pengubahsuaian yang lebih besar. Bertuah kerana kertas yang diterima, semua orang boleh mencuba cadangan semakan yang diberikan oleh GPT-4 sebelum menyerahkannya secara rasmi. . Di sini, pengarang mengukur metrik "kadar pertindihan berpasangan" dan mendapati ia telah dikurangkan dengan ketara kepada 0.43% dan 3.91% pada kedua-dua Nature dan ICLR. Ini menunjukkan bahawa GPT-4 mempunyai matlamat tertentu3 Ia boleh mencapai persetujuan dengan pendapat manusia tentang isu-isu utama dan universal
Secara umumnya, komen yang muncul paling awal dan disebut oleh berbilang pengulas selalunya mewakili masalah penting dan biasa
Di sini, pasukan juga mendapati bahawa LLM lebih berkemungkinan untuk mengenal pasti isu biasa yang diiktiraf sebulat suara oleh berbilang masalah atau kelemahan
GPT-4 berprestasi baik secara keseluruhan
4 Pendapat yang diberikan oleh GPT-4 menekankan beberapa aspek yang berbeza dengan manusia
Kajian mendapati kekerapan GPT-4 mengulas maksud kajian itu sendiri adalah manusia. 7.27 kali lebih berkemungkinan daripada manusia untuk mengulas tentang kebaharuan penyelidikan.
Kedua-dua GPT-4 dan manusia sering mengesyorkan percubaan tambahan, tetapi manusia lebih menumpukan pada eksperimen ablasi, dan GPT-4 mengesyorkan mencubanya pada lebih banyak set data.
Pengarang menyatakan bahawa penemuan ini menunjukkan bahawa GPT-4 dan penyemak manusia memberikan penekanan yang berbeza pada pelbagai aspek, dan kerjasama antara kedua-duanya mungkin membawa potensi kelebihan.
Di luar eksperimen kuantitatif ialah penyelidikan pengguna.
Seramai 308 penyelidik dalam bidang AI dan biologi pengiraan daripada institusi berbeza telah mengambil bahagian dalam kajian ini. Mereka memuat naik kertas kerja mereka ke GPT-4 untuk semakan
Pasukan penyelidik mengumpul maklum balas sebenar mereka tentang ulasan semakan GPT-4.
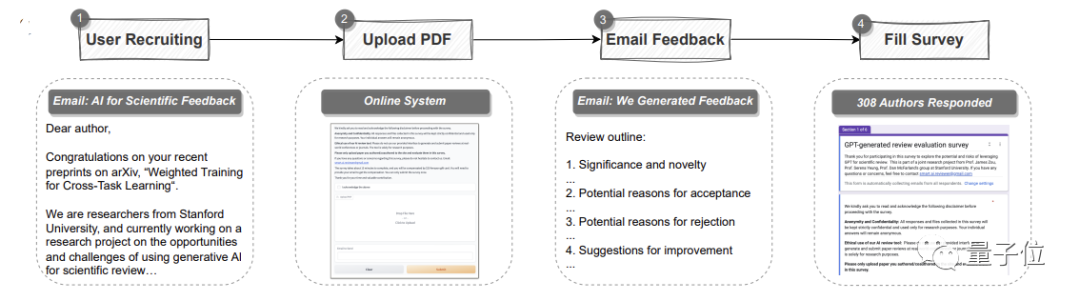
Secara keseluruhannya, lebih separuh (57.4%)daripada peserta percaya maklum balas yang dijana oleh GPT-4 sangat membantu termasuk memberi beberapa point yang tidak terfikir oleh manusia.
Dan 82.4% daripada mereka yang ditinjau mendapati ia lebih bermanfaat daripada sekurang-kurangnya beberapa maklum balas pengulas manusia.
Selain itu, lebih separuh (50.5%) menyatakan kesanggupan mereka untuk terus menggunakan model besar seperti GPT-4 untuk menambah baik kertas kerja.
Salah seorang daripada mereka berkata bahawa hanya mengambil masa 5 minit untuk GPT-4 untuk memberikan hasil maklum balas ini sangat pantas dan sangat membantu penyelidik untuk memperbaiki kertas kerja mereka.
Sudah tentu, penulis menekankan:
Keupayaan GPT-4 juga mempunyai beberapa batasan
Yang paling jelas ialah ia lebih menumpukan pada "susun atur keseluruhan" dan tidak mempunyai cadangan yang mendalam dalam bidang teknikal seperti seni bina model) .
Jadi, seperti yang dinyatakan oleh kesimpulan akhir pengarang:
Maklum balas berkualiti tinggi daripada pengulas manusia adalah sangat penting sebelum semakan rasmi, tetapi kita boleh menguji perairan terlebih dahulu untuk membuat perincian seperti eksperimen dan pembinaan yang mungkin. peninggalan
Sudah tentu, mereka juga mengingatkan:
Dalam semakan rasmi, penyemak masih harus mengambil bahagian secara bebas dan tidak bergantung pada mana-mana LLM.
Semua pengarang adalah Cina
Kajian ini Terdapat tiga pengarang, kesemuanya adalah Cina, dan semuanya berasal dari Pusat Pengajian Sains Komputer di Universiti Stanford.

Mereka ialah:
- Liang Weixin, pelajar kedoktoran di sekolah dan ahli Makmal AI Stanford (SAIL) . Beliau memegang ijazah sarjana dalam kejuruteraan elektrik dari Universiti Stanford dan ijazah sarjana muda dalam sains komputer dari Universiti Zhejiang.
- Yuhui Zhang, juga seorang pelajar kedoktoran, menyelidik tentang sistem AI berbilang modal. Lulus dari Universiti Tsinghua dengan ijazah sarjana muda dan dari Stanford dengan ijazah sarjana.
- Cao Hancheng ialah calon kedoktoran tahun kelima di sekolah itu, dalam jurusan sains pengurusan dan kejuruteraan Beliau juga telah menyertai kumpulan NLP dan HCI di Universiti Stanford. Sebelum ini berkelulusan dari Jabatan Kejuruteraan Elektronik Universiti Tsinghua dengan ijazah sarjana muda.
Pautan kertas: https://arxiv.org/abs/2310.01783
Atas ialah kandungan terperinci Apabila menyerahkan kertas kerja anda kepada Nature, tanya tentang GPT-4 dahulu! Stanford sebenarnya menguji 5,000 artikel, dan separuh daripada pendapat adalah sama dengan pengulas manusia. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- ai怎么转ps
- ai无法实时上色原因
- c源程序中main函数的位置是什么?
- NUS dan Byte bekerjasama merentas industri untuk mencapai latihan 72 kali lebih pantas melalui pengoptimuman model, dan memenangi Kertas Cemerlang AAAI2023.
- Persidangan EMNLP 2022 secara rasmi berakhir, kertas panjang terbaik, kertas pendek terbaik dan anugerah lain diumumkan