
Rumah >Peranti teknologi >AI >Persidangan EMNLP 2022 secara rasmi berakhir, kertas panjang terbaik, kertas pendek terbaik dan anugerah lain diumumkan
Persidangan EMNLP 2022 secara rasmi berakhir, kertas panjang terbaik, kertas pendek terbaik dan anugerah lain diumumkan

- PHPzke hadapan
- 2023-05-09 14:10:141525semak imbas
Baru-baru ini, EMNLP 2022, persidangan teratas dalam bidang pemprosesan bahasa semula jadi, telah diadakan di Abu Dhabi, ibu negara Emiriah Arab Bersatu.

Sebanyak 4190 kertas kerja telah diserahkan ke persidangan tahun ini, dan 829 kertas kerja akhirnya diterima (715 kertas panjang, 114 kertas keseluruhan). kadar penerimaan adalah 20%, tidak jauh berbeza dengan tahun-tahun sebelumnya.
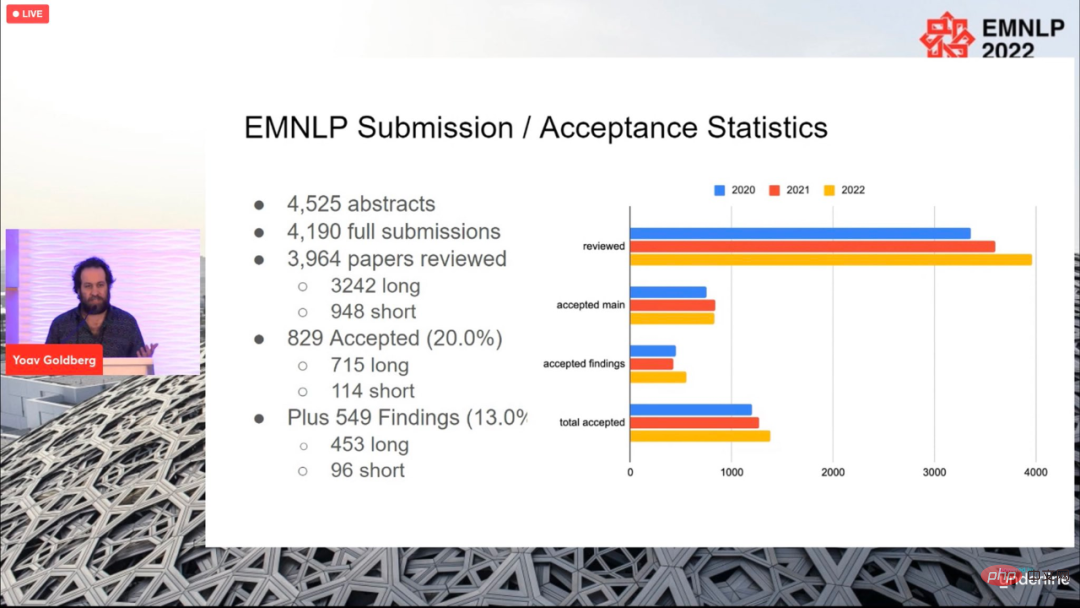
Persidangan berakhir pada 11 Disember, waktu tempatan, dan anugerah kertas untuk tahun ini turut diumumkan, termasuk Kertas Panjang Terbaik (1 kertas) , Kertas Pendek Terbaik (1 keping), Kertas Demo Terbaik (1 keping).
Kertas Panjang Terbaik

Kertas: Penaakulan Visual Abstrak dengan Bentuk Tangram
- Pengarang: Anya Ji, Noriyuki Kojima, Noah Rush, Alane Suhr, Wai Keen Vong, Robert D. Hawkins, Yoav Artzi
- Institusi: Kang Nair Universiti, Universiti New York, Institut Allen, Universiti Princeton
- Pautan kertas: https://arxiv.org/pdf/2211.16492.pdf
Abstrak kertas: Dalam kertas kerja ini, penyelidik memperkenalkan "KiloGram", pengguna Perpustakaan sumber untuk mengkaji abstrak penaakulan visual pada manusia dan mesin. KiloGram menambah baik sumber sedia ada dalam dua cara. Pertama, penyelidik menyusun dan mendigitalkan 1,016 bentuk, mencipta koleksi yang dua urutan magnitud lebih besar daripada yang digunakan dalam kerja sedia ada. Koleksi ini sangat meningkatkan liputan keseluruhan julat variasi penamaan, memberikan perspektif yang lebih komprehensif tentang tingkah laku penamaan manusia. Kedua, koleksi itu menganggap setiap tangram bukan sebagai satu bentuk keseluruhan, tetapi sebagai bentuk vektor yang terdiri daripada kepingan teka-teki asal. Penguraian ini membolehkan penaakulan tentang bentuk keseluruhan dan bahagiannya. Para penyelidik menggunakan koleksi grafik teka-teki jigsaw digital baharu ini untuk mengumpul sejumlah besar data penerangan tekstual, mencerminkan kepelbagaian tingkah laku penamaan yang tinggi.
Para penyelidik menggunakan sumber ramai untuk melanjutkan proses anotasi, mengumpulkan berbilang anotasi untuk setiap bentuk untuk mewakili pengedaran anotasi yang ditimbulkannya dan bukannya satu sampel. Sebanyak 13,404 anotasi telah dikumpulkan, setiap satu menerangkan objek lengkap dan bahagiannya yang dibahagikan.
Potensi KiloGram adalah luas. Kami menggunakan sumber ini untuk menilai keupayaan penaakulan visual abstrak model multimodal terkini dan memerhatikan pemberat pra-latihan mempamerkan keupayaan penaakulan abstrak terhad yang bertambah baik dengan penalaan halus. Mereka juga mendapati bahawa huraian eksplisit memudahkan penaakulan abstrak oleh kedua-dua manusia dan model, terutamanya apabila bersama-sama mengekod bahasa dan input visual.
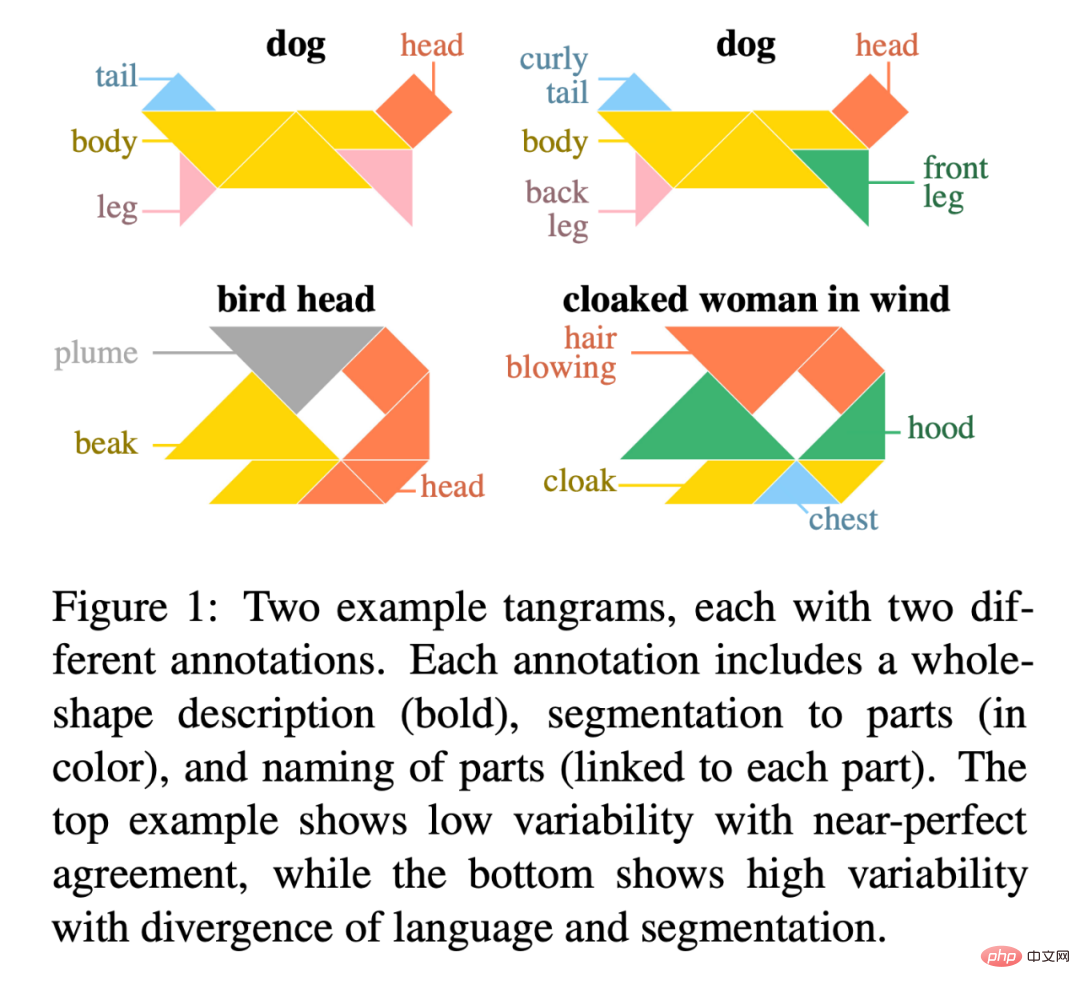
Rajah 1 ialah contoh dua tangram, setiap satu dengan dua anotasi berbeza. Setiap anotasi termasuk perihalan keseluruhan bentuk (dalam huruf tebal), pembahagian bahagian (berwarna), dan nama untuk setiap bahagian (disambungkan kepada setiap bahagian). Contoh atas menunjukkan kebolehubahan yang rendah untuk persetujuan yang hampir sempurna, manakala contoh yang lebih rendah menunjukkan kebolehubahan yang tinggi untuk perbezaan bahasa dan pembahagian.
Alamat KiloGram: https://lil.nlp .cornell.edu/kilogram
Pencalonan kertas panjang terbaik untuk persidangan ini dimenangi oleh dua penyelidik, Kayo Yin dan Graham Neubig.
Kertas: Mentafsir Model Bahasa dengan Penjelasan Kontrastif
- Pengarang: Kayo Yin, Graham Neubig
Ringkasan kertas: Kaedah kebolehtafsiran model sering digunakan untuk menerangkan keputusan model NLP pada tugasan seperti klasifikasi teks ruang keluaran tugasan ini agak kecil. Walau bagaimanapun, apabila digunakan pada penjanaan bahasa, ruang output selalunya terdiri daripada puluhan ribu token, dan kaedah ini tidak dapat memberikan penjelasan bermaklumat. Model bahasa mesti mempertimbangkan pelbagai ciri untuk meramalkan token, seperti bahagian pertuturan, nombor, kala atau semantiknya. Oleh kerana kaedah penerangan sedia ada menggabungkan bukti untuk semua ciri ini ke dalam satu penjelasan, ini kurang dapat ditafsirkan kepada pemahaman manusia.
Untuk membezakan antara keputusan yang berbeza dalam pemodelan bahasa, penyelidik telah meneroka model bahasa yang memfokuskan pada penjelasan kontrastif. Mereka mencari token input yang menonjol dan menerangkan sebab model itu meramalkan satu token tetapi bukan token lain. Penyelidikan menunjukkan bahawa penjelasan kontrastif adalah jauh lebih baik daripada penjelasan bukan kontrastif dalam mengesahkan fenomena tatabahasa utama, dan ia meningkatkan kebolehsimulasi model kontrastif dengan ketara untuk pemerhati manusia. Para penyelidik juga mengenal pasti kumpulan keputusan yang berbeza yang mana model itu menggunakan bukti yang serupa dan dapat menerangkan token input yang model digunakan dalam pelbagai keputusan penjanaan bahasa.
Alamat kod: https://github.com/kayoyin/interpret-lm
Kertas Pendek Terbaik

Kertas: Pembelajaran Perwakilan Pengarang Terkawal Topik
- Pengarang: Jitkapat Sawatphol, Nonthakit Chaiwong , Can Udomcharoenchaikit, Sarana Nutanong
- Institusi: VISTEC Institute of Science and Technology, Thailand
Abstrak :Dalam kajian ini, penyelidik mencadangkan Regularisasi Perwakilan Pengarang, rangka kerja penyulingan yang boleh meningkatkan prestasi merentas topik dan juga boleh mengendalikan pengarang yang tidak kelihatan. Pendekatan ini boleh digunakan pada mana-mana model perwakilan pengarang. Keputusan eksperimen menunjukkan bahawa dalam tetapan merentas topik, prestasi 4/6 dipertingkatkan. Pada masa yang sama, analisis penyelidik menunjukkan bahawa dalam set data dengan sejumlah besar topik, serpihan latihan yang ditetapkan merentas topik mempunyai masalah kebocoran maklumat topik, sekali gus melemahkan keupayaan mereka untuk menilai atribut merentas topik.
Kertas Demo Terbaik

Kertas: Menilai & Penilaian di Hab: Amalan Terbaik yang Lebih Baik untuk Pengukuran Data dan Model
- Pengarang: Leandro von Werra, Lewis Tunstall, Abhishek Thakur, Alexandra Sasha Luccioni, dll.
- Institusi: Muka Memeluk
- Pautan kertas: https://arxiv.org/pdf/2210.01970.pdf
Ringkasan kertas: Penilaian ialah bahagian penting dalam pembelajaran mesin (ML), dan penyelidikan ini memperkenalkan Evaluate and Evaluation on Hub - satu set alatan yang membantu dengan Alat penilaian untuk model dan set data dalam ML. Evaluate ialah perpustakaan untuk membandingkan model dan set data yang berbeza, menyokong pelbagai metrik. Pustaka Evaluate direka bentuk untuk menyokong kebolehulangan penilaian, mendokumentasikan proses penilaian dan mengembangkan skop penilaian untuk merangkumi lebih banyak aspek prestasi model. Ia termasuk lebih daripada 50 pelaksanaan spesifikasi yang cekap untuk pelbagai domain dan senario, dokumentasi interaktif dan keupayaan untuk berkongsi hasil pelaksanaan dan penilaian dengan mudah.
Alamat projek: https://github.com/huggingface/evaluate
Selain itu, pengkaji turut melancarkan Evaluation on the Hub, platform itu membolehkan penilaian berskala besar ke atas lebih 75,000 model dan 11,000 set data pada Hugging Face Hub secara percuma dengan mengklik butang.
Atas ialah kandungan terperinci Persidangan EMNLP 2022 secara rasmi berakhir, kertas panjang terbaik, kertas pendek terbaik dan anugerah lain diumumkan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI